推薦系統的分類方式有很多種,在不同的資料中也給出了不同的分類方式,
我們可以獲得的資料總體來說有三種:用戶的資訊,物品的資訊,和用戶的行為資訊,按斬訓得資料的不同也可以將推薦系統分為三種:(1).基于人口統計學的推薦,(2).基于內容的推薦,(3).基于協同過濾的推薦,
基于人口統計學的推薦
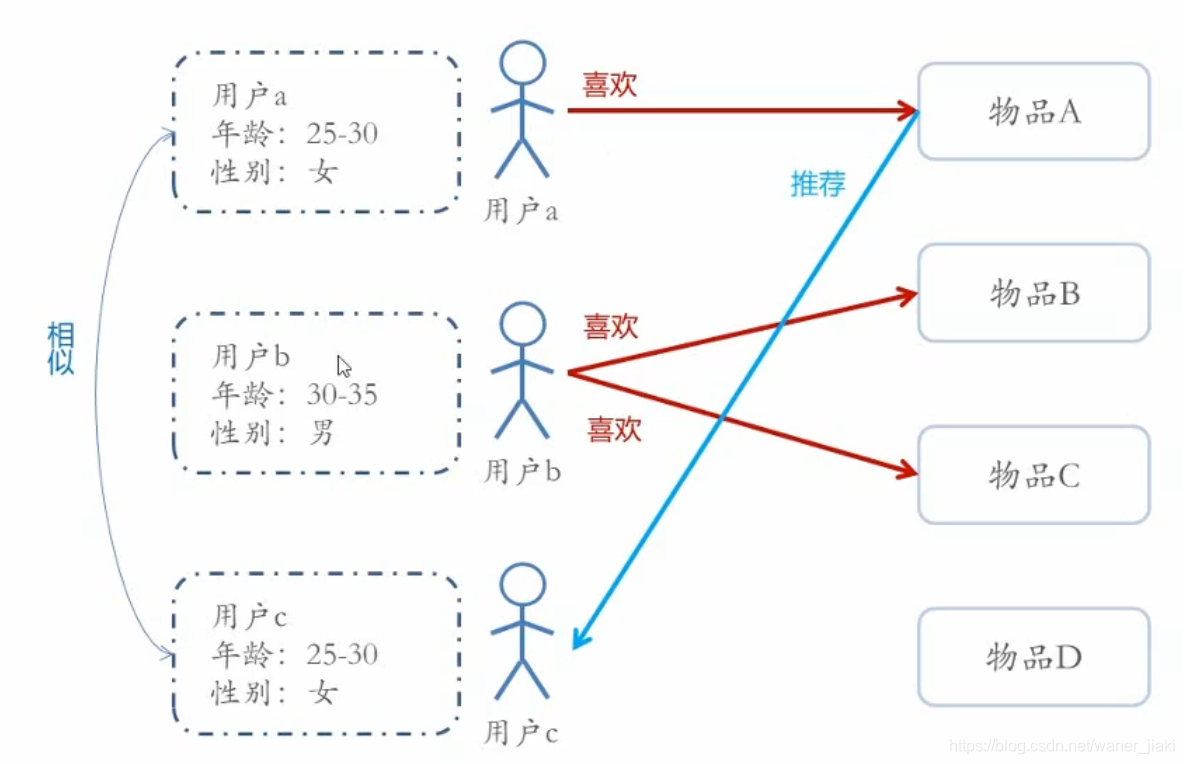 當我們拿到用戶的一些標簽資訊時,我們可以采用基于人口統計學的推薦,根據用戶的特征可以找到與目標用戶相似的用戶,再根據相似用戶的喜好對目標用戶進行推薦,
當我們拿到用戶的一些標簽資訊時,我們可以采用基于人口統計學的推薦,根據用戶的特征可以找到與目標用戶相似的用戶,再根據相似用戶的喜好對目標用戶進行推薦,
·基于人口統計學的推薦機制(Demographic-based Recommendation)是一種最易于實作的推薦方法,它只是簡單的根據系統用戶的基本資訊發現用戶的相關程度,然后將相似用戶喜愛的其他物品推薦給當前用戶
·對于沒有明確含義的用戶資訊(比如登錄時間、地域等背景關系資訊),可以通過聚類等手段,給用戶打上分類標簽
·對于特定標簽的用戶,又可以根據預設的規則(知識)或者模型,推薦出對應的物品,
用戶資訊標簽化的程序一般被稱為用戶畫像,
基于內容的推薦演算法
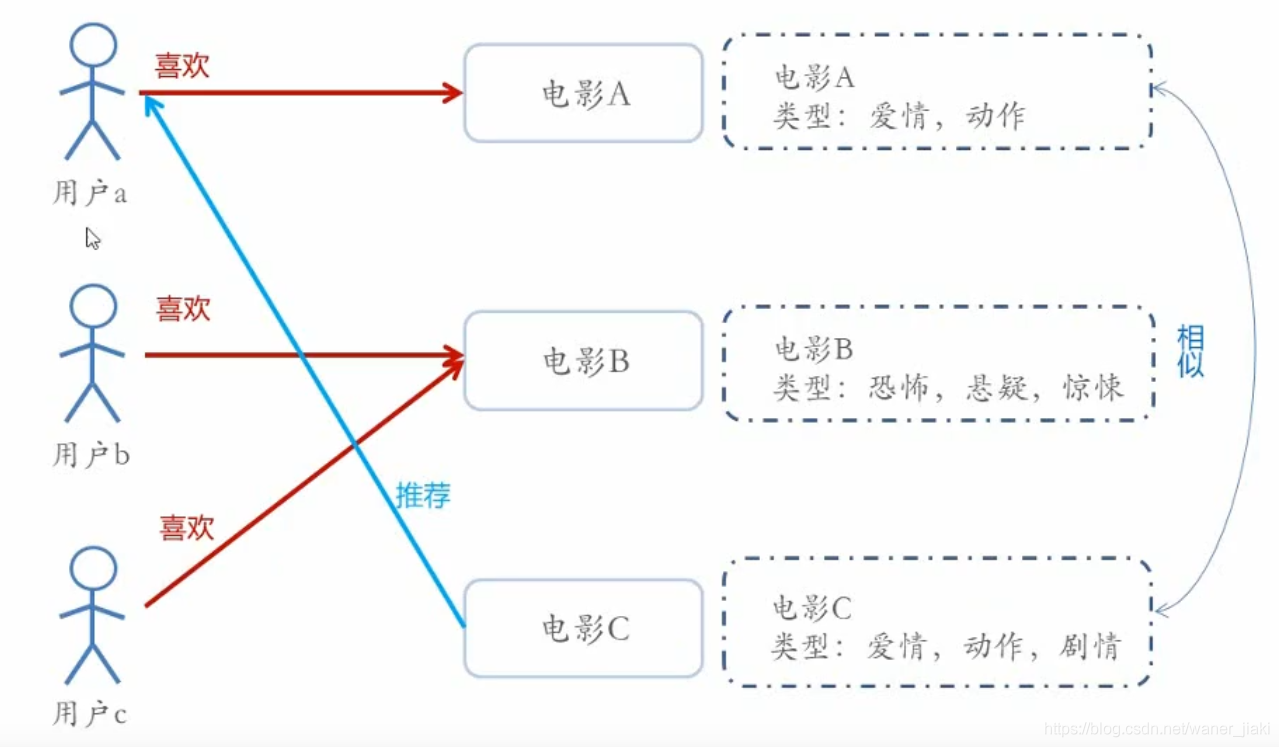 當拿到物品的基本資訊時,可以計算物品的相似度來進行推薦,
當拿到物品的基本資訊時,可以計算物品的相似度來進行推薦,
. Content-based Recommendations (CB)根據推薦物品或內容的元資料,發現物品的相關性,再基于用戶過去的喜好記錄,為用戶推薦相似的物品,·通過抽取物品內在或者外在的特征值,實作相似度計算,
-比如一個電影,有導演、演員、用戶標簽UGC、用戶評論、時長、風格等等,都可以算是特
征,
·將用戶(user)個人資訊的特征(基于喜好記錄或是預設興趣標簽),和物品(item)的特征相匹配,就能得到用戶對物品感興趣的程度
-在一些電影、音樂、圖書的社交網站有很成功的應用,有些網站還請專業的人員對物品進行基
因編碼/打標簽(PGC),
相似度計算
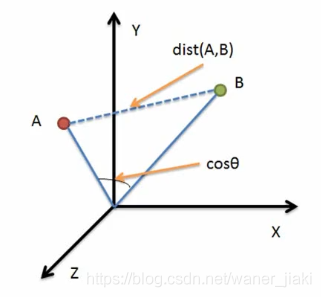
相似度的評判,可以用距離表示,而一般更常用的是"余弦相似度,
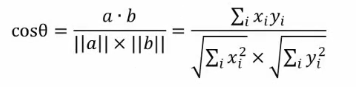
余弦相似度可以看作是衡量倆個向量的夾角大小,夾角越小,余弦相似度越大,兩個向量的相似程度越大,
特征提取
對于物品的特征提取——打標簽(tag)
-專家標簽(PGC)
-用戶自定義標簽(UGC)
-降維分析資料,提取隱語意標簽(LFM)
對于文本資訊的特征提取———關鍵詞
-分詞、語意處理和情感分析(NLP)
-潛在語意分析(LSA)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/241981.html
標籤:其他
下一篇:2020/12/28 “fatal: Could not read from remote repository.”的解決方案(碼云 gitee)