【編者按】2015 年 AlphaGo 出道一年,就戰勝法國二段職業棋手樊麾,2016 年 3 月以 4:1 戰勝韓國國手李世石九段,3 月 14 日,韓國棋院表示 AlphaGo 實力不遜于李世石九段,授予 Alphago 韓國棋院名譽九段證書,AlphaGo 一戰成名,要知道,多少棋手宵衣旰食也到不了九段,同年 12 月,強化版 AlphaGo 化名“Master”,在非正式網路快棋對戰測驗當中取得 60 戰全勝,2017 年 5 月,與中國棋手柯潔九段對戰,全取三分,虐哭柯潔,而且由于此次使用 Google 的 TPU,使得計算資源只有對戰李世石時候的十分之一,要知道,柯潔可不是旁人,是當時世界第一,年紀輕輕,已經手握多項含金量高比賽的冠軍,代表人類最高水平的棋手都無能為力,可見 AlphaGo 真的不是尋常之輩, 賽后,中國圍棋協會也授予了 AlphaGo 職業圍棋九段的稱號,棋圣聶衛平更是盛贊 AlphaGo 的水平相當于職業圍棋二十段,賽后,DeepMInd 團隊宣布 AlphaGo 退役,但相關研究不會停止,

作者 | 八寶粥
出品 CSDN(id:CSDNnews)
DeepMind 團隊為 AlphaGo 各個版本起了不同名字, 歷數幾代分別稱為 AlphaGo 樊、AlphaGo李、AlphaGo Master,后來還推出了 AlphaGo Zero 和 Alpha Zero 等版本, AlphaGo Zero 及此后版本沒有用到人類資料,通過和自己對戰,訓練三天即可實作極高勝率,在那之后,AlphaGo 團隊獨孤求敗,淡出江湖,
此后, DeepMind 在蛋白質折疊等方面也做出 AlphaFold 等令人矚目的成就,
誰能想到,僅僅淡出了兩年,DeepMInd 團隊帶著 AlphaGo 的后輩——— MuZero 新重出江湖,MuZero 通過自我比賽以及和 AlphaZero 進行比賽,利用多項常規和殘局訓練,實作了演算法的升級突破,相關研究成果論文今年 12 月在國際頂級期刊 Nature 上發出(2019年,該文章在預印本平臺發布),如果此前 AlphaGo 版本是靠著機器學習和算力的一力降十會的話,此次的新演算法就是雙手互搏,無師自通,不光如此,MuZero 的 “魔爪”從圍棋伸向了各個領域,包括國際象棋、日本的將棋和 Atari 電子游戲,你冬練三九夏練三伏,別人一出世就自帶超強自學能力,而且人家全家輸的次數屈指可數,還都是輸給自己人,你說這比賽讓人怎么打?
平心而論,再早之前 “深藍”就已經深深傷過棋手們的心,各類智力比賽和游戲當中,圍棋可以說是難度非常高的了,本以為圍棋 324 格棋盤生出千萬般變化能夠守住人類的陣地,結果 AlphaGo 虐哭柯潔, Alpha Zero 還說 “我能自己學”,MuZero 說 “我能自己學,還不需要規則”,就像 AI 世界里的葉問,一個馬步攤手,豪氣發問:“我要打十個,還有誰?”
如果這次真的有人能上來對陣三招五式的話,可能也只有 AI 本身能對抗 AI了, 或者像網友戲謔的那樣,“不讓他聯網”、“拔他電源”,,,,那么 MuZero 到底是哪路神仙呢? 我們一起來看一下:
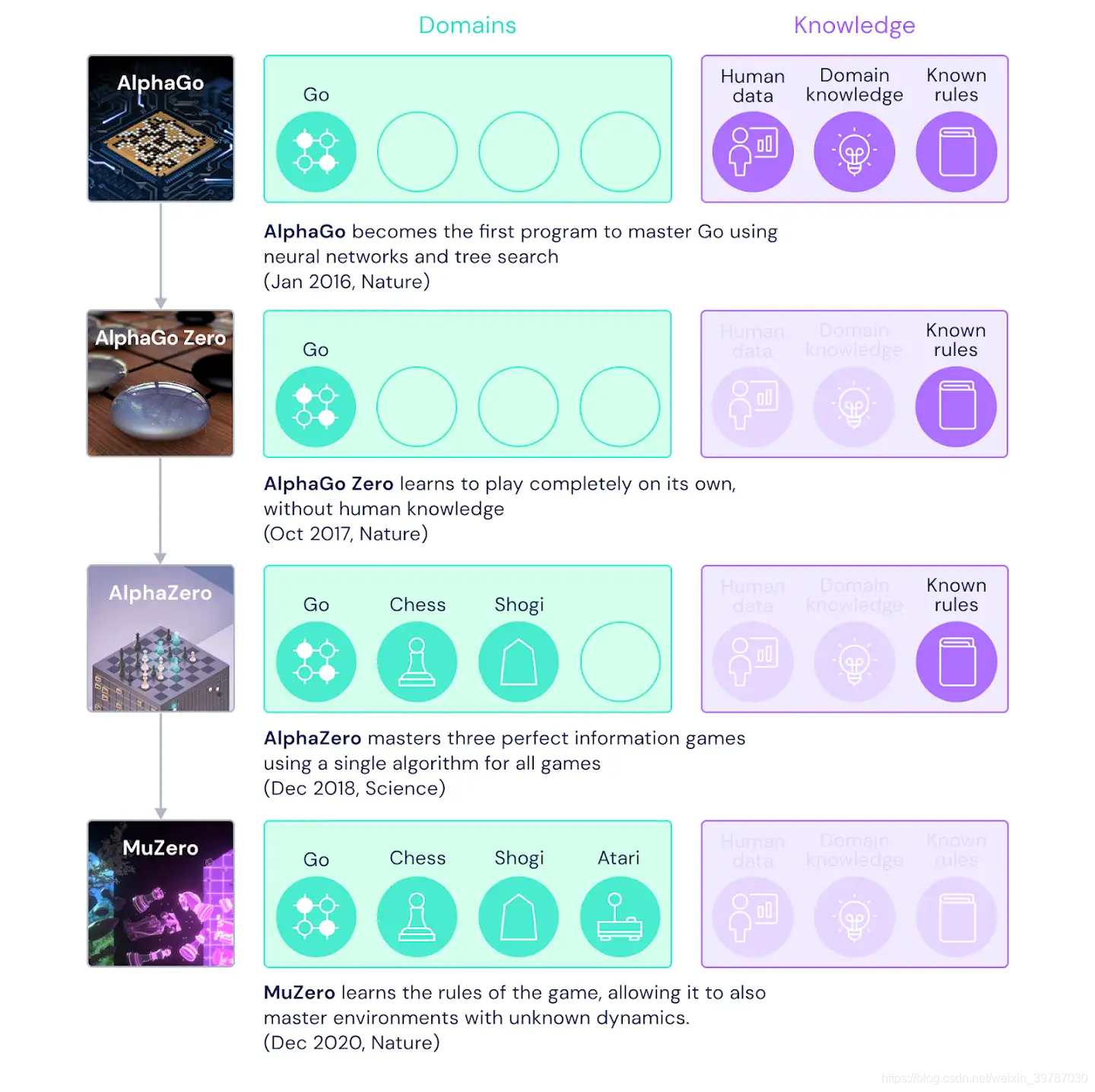
從上圖可以看出,隨著技術的進化,需要的知識庫(規則)逐漸減少,到 MuZero 直接沒有了,而應用的領域卻逐漸增加, 從圍棋、將棋擴展到 Atari 游戲,
文章表示,MuZero 和此前的 Alpha Zero 代碼相似,但是 MuZero 無法訪問規則集合,而是將該規則替換成了搜索樹狀態神經網路,研究人員主要通過以下方法應對 AI 的挑戰,超前搜索和基于模型的計劃,超前搜索已經在國際象棋、撲克等景點游戲當中取得成功,但是依賴于游戲規則,這樣的話,對于復雜世界和混亂的現實問題就沒有辦法,因為它們無法提煉成簡化的規則;基于模型的系統旨在學習環境動力學的精確模型, 然后以此進行規劃和學習,不過對于視覺豐富的環境當中依然沒有競爭力,比如游戲 Atari 當中,最好的結果其實來自于無模型系統,
MuZero 使用另外的方法來克服此前方法的局限性, 它不是對整個環境建模,而是對代理的決策環境或者關鍵方面進行建模,DeepMInd 表示:畢竟,了解雨傘會使您保持干燥比對空氣中雨滴進行建模更有用,
具體而言, MuZero 對三個元素進行建模,分別是值、策略、獎勵, 分別衡量了:當前位置好壞程度、最優策略以及上一步好壞的衡量, 通過蒙特卡羅搜索樹,配合動力學函式和預測函式,考慮下一步的動作序列,同時利用了和環境互動時候收集的經驗來訓練神經網路,在每一步當中保存之前的資訊,這個似乎是一種無監督學習內的強化學習,其實它也不能說完全 “無規則”,它唯一的規則其實是我們在下棋當中常說的“走一步、看三步”,不管是什么游戲,它都給自己一個這樣的規則,MuZero 就可以反復發使用學習的模型來改進計劃,而不需要從環境當中重新收集資料,
從專案主要開發者 Julian Schrittwieser 的博客當中,我們還發現了一些有意思的內容
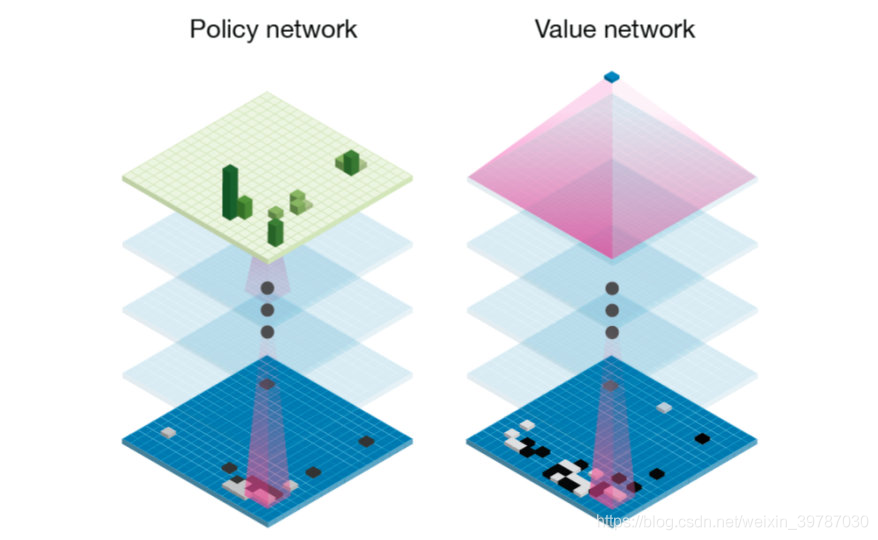
對于作者而言,這些也僅僅都是 “統計”而已,它是從 AlphaGo 和 Alpha Zero 當中集成的策略網路和價值網路,每一個網路都已經非常強大了,考慮策略網路,就能對于下一步有良好的預判,考慮價值網路,就能選擇價值最高的行動,結合兩者,當然就更完美了,
ps. 講點你不知道的東西~
為什么給它取名叫 MuZero 呢?
很大程度上來自于日語發音,開發者 Julian 覺得這個和日語夢、以及無 的發音相似(為什么不去學中文啊大哥!);另外他認為這個發音和希臘字母 μ 也很像,Zero 和此前一樣,表示沒有用到人類的資料,所以這個演算法可以讀作“木Zero”、"繆Zero"~不過開發者自己的發音是“繆Zero”,
這位小哥也很有意思,來自奧地利,對各種語言都很感興趣,當然也包括一些開發語言,而且努力學日語中~
如果你對 MuZero 感興趣, 不妨可以看看小哥博客里面推薦的文章 ,教你怎么利用 Python 搭建自己的 MuZero AI ,說不定也能用 AI 打敗誰(比如街邊下棋的大爺),
從 AlphaGo 震驚圍棋江湖以來,越來越多的 “唯人能贏”的游戲開始被 AI 染指,如果此前《星際爭霸II》當中戰勝人類選手還是算力的取勝,MuZero 雙掌互搏就能增長內力、左腳踩右腳就能騰云這次真的是一次巨大的沖擊,歡迎下方留言,下一個被 AI 虐哭的會是誰呢?
【參考資料】:
1.DeepMind 官方網站
2.論文鏈接
3.2019年預印版論文下載地址
4.開發者 Julian 的個人博客
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/242328.html
標籤:AI