上一節我們詳細說明了如何為PNET生成用于訓練的人臉圖片,本節我們需要將上一節分割出的人臉圖片存盤成檔案,相關代碼如下:
import numpy as np
import cv2
from google.colab.patches import cv2_imshow
import os
#準備存盤不同訓練圖片的路徑
pos_save_dir = "/content/drive/MyDrive/my_mtcnn/12/positive"
part_save_dir = "/content/drive/MyDrive/my_mtcnn/12/part"
neg_save_dir = "/content/drive/MyDrive/my_mtcnn/12/neg"
if not os.path.exists(pos_save_dir):
os.mkdir(pos_save_dir)
if not os.path.exists(part_save_dir):
os.mkdir(part_save_dir)
if not os.path.exists(neg_save_dir):
os.mkdir(neg_save_dir)
接下來我們呼叫上一節描述的圖片切割函式,將不同類別的訓練圖片存入相應路徑:
from tqdm import tqdm
annotation_file_path = "/content/drive/MyDrive/WIDER_TRAIN_DATA/WIDER_train/wider_face_train.txt"
trainning_img_dir = "/content/drive/MyDrive/WIDER_TRAIN_DATA/WIDER_train/images/"
def save_neg_trainning_data():
with open(annotation_file_path, 'r') as f:
annotations = f.readlines() #讀取檔案中所有照片的路徑及人臉區域資訊
num = len(annotations)
print("total images:{}".format(num))
n_idx = 0
neg_annotation_path = os.path.join(neg_save_dir, "neg_12.txt")
neg_annotation_file = open(neg_annotation_path, "w")
for annotation in tqdm(annotations):
img_path, face_boxes = get_img_boxes(annotation)
img_path = os.path.join(trainning_img_dir, img_path)
img = cv2.imread(os.path.join(trainning_img_dir, img_path))
neg_boxes = create_neg_parts(img, face_boxes)
for neg_box in neg_boxes:
#注意選擇的區域坐標首先是寬,然后是高,但對圖片進行裁剪時首先是高然后是寬
cropped_img = img[neg_box[1]:neg_box[3], neg_box[0]:neg_box[2],:]
resized_img = cv2.resize(cropped_img, (12, 12), interpolation=cv2.INTER_LINEAR) #將圖片縮小為12,12
neg_trainning_file = os.path.join(neg_save_dir, "%s.jpg"%n_idx)
cv2.imwrite(neg_trainning_file, resized_img)
neg_annotation_file.write(neg_trainning_file + "0\n")
n_idx += 1
neg_overlapped_boxes = create_neg_overlapped_parts(img, face_boxes)
for neg_overlapped_box in neg_overlapped_boxes:
cropped_img = img[neg_overlapped_box[1]:neg_overlapped_box[3], neg_overlapped_box[0]:neg_overlapped_box[2],:]
resized_img = cv2.resize(cropped_img, (12, 12), interpolation=cv2.INTER_LINEAR) #將圖片縮小為12,12
neg_trainning_file = os.path.join(neg_save_dir, "%s.jpg"%n_idx)
cv2.imwrite(neg_trainning_file, resized_img)
neg_annotation_file.write(neg_trainning_file + "0\n")
n_idx += 1
save_neg_trainning_data()
from tqdm import tqdm
annotation_file_path = "/content/drive/MyDrive/WIDER_TRAIN_DATA/WIDER_train/wider_face_train.txt"
trainning_img_dir = "/content/drive/MyDrive/WIDER_TRAIN_DATA/WIDER_train/images/"
def save_part_pos_trainning_data():
with open(annotation_file_path, 'r') as f:
annotations = f.readlines() #讀取檔案中所有照片的路徑及人臉區域資訊
num = len(annotations)
part_annotation_path = os.path.join(part_save_dir, "part_12.txt")
part_annotation_file = open(part_annotation_path, "w")
pos_annotation_path = os.path.join(pos_save_dir, "pos_12.txt")
pos_annotation_file = open(pos_annotation_path, "w")
pos_idx = 0
part_idx = 0
for annotation in tqdm(annotations):
img_path, face_boxes = get_img_boxes(annotation)
img_path = os.path.join(trainning_img_dir, img_path)
img = cv2.imread(os.path.join(trainning_img_dir, img_path))
pos_boxes, pos_offset, part_boxes, part_offset = create_pos_part_box(img, face_boxes)
for i in range(len(pos_boxes)):
box = pos_boxes[i]
offset_info = pos_offset[i]
cropped_img = img[box[1]:box[3], box[0]:box[2], :]
resized_img = cv2.resize(cropped_img, (12, 12), interpolation = cv2.INTER_LINEAR)
pos_trainning_file = os.path.join(pos_save_dir, "%s.jpg"%pos_idx)
cv2.imwrite(pos_trainning_file, resized_img)
pos_annotation_file.write(pos_trainning_file + ' 1 %.2f %.2f %.2f %.2f\n'%(offset_info[0], offset_info[1], offset_info[2], offset_info[3]))
pos_idx+=1
for i in range(len(part_boxes)):
box = part_boxes[i]
cropped_img = img[box[1]:box[3], box[0]:box[2], :]
resized_img = cv2.resize(cropped_img, (12, 12), interpolation = cv2.INTER_LINEAR)
part_trainning_file = os.path.join(part_save_dir, "%s.jpg"%part_idx)
cv2.imwrite(part_trainning_file, resized_img)
part_annotation_file.write(part_trainning_file + ' -1 %.2f %.2f %.2f %.2f\n'%(offset_info[0], offset_info[1], offset_info[2], offset_info[3]))
part_idx += 1
save_part_pos_trainning_data()
這部分代碼執行時非常緩慢,總計需要兩個小時左右,讀者在運行時需要耐心等待,由于PNET在訓練時除了要判斷人臉范圍外,還需要預測五個人臉關鍵點坐標,這些關鍵點對應兩只眼睛,兩邊嘴角和中間鼻子,因此我們還需要相應的資料,這些訓練資料來自于資料集:!Deep Convolutional Network Cascade for Facial Point Detection,資料中含有大量人臉圖片,同時包含一個說明檔案,檔案中每一行描述一張圖片的資訊,其中包括圖片對應路徑,圖片中人臉的范圍以及五個關鍵點的坐標,相應資料集和對應說明檔案下載路徑為:鏈接: https://pan.baidu.com/s/1qc48io4RfXXL2hXuaeqMCg 密碼: kkkf,我們看說明檔案中的一條記錄:
lfw_5590\Aaron_Eckhart_0001.jpg 84 161 92 169 106.250000 107.750000 146.750000 112.250000 125.250000 142.750000 105.250000 157.750000 139.750000 161.750000
其中第一部分“lfw_5590\Aaron_Eckhart_0001.jpg”對應所描述的圖片路徑,第二部分“84 161 92 169”對應人臉區域,注意該區域與我們前面資料所描述的區域不一樣,其中(84, 92)對應左上角,(161, 169)對應右下角,最后10個資料對應5個關鍵點的坐標,將資料集解壓后可以使用下面代碼繪制出人臉區域和對應關鍵點:
#在呼叫后面人臉翻轉和旋轉代碼時一定要先執行這里的代碼一次
line = "lfw_5590\Aaron_Eckhart_0001.jpg 84 161 92 169 106.250000 107.750000 146.750000 112.250000 125.250000 142.750000 105.250000 157.750000 139.750000 161.750000"
components = line.split(' ')
img_path = os.path.join("/content/drive/MyDrive/WIDER_TRAIN_DATA/", components[0])
img_path = img_path.replace("\\", '/')
box = (components[1], components[2], components[3], components[4])
box = list(map(int, box))
#box = np.array(box, dtype=np.float32).reshape(-1, 4) #人臉框
landmark = np.zeros((5, 2)) #五個關鍵點,兩個眼睛,兩個嘴角,一個鼻子
for index in range(5):
rv = (float(components[5+2*index]), float(components[5+2*index + 1]))
landmark[index] = rv
img = cv2.imread(img_path)
top_left = (box[0], box[2])
bottom_right = (box[1], box[3]) #該資料集人臉框的坐標與原先資料集不一樣
img = cv2.rectangle(img, top_left, bottom_right, (255,0,0), 1)
for point in landmark:
img = cv2.circle(img, (int(point[0]), int(point[1])), radius = 1, color=(0, 0, 255), thickness = 1)
cv2_imshow(img)
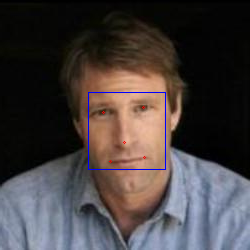
上面代碼執行后所得結果如下:

可以看到5個紅點對應的就是5個關鍵點,這里還有一點需要強調,由于關鍵點坐標是相對于當前圖片大小而言,但是為了訓練PNET,我們需要將圖片縮放為(12,12),由此關鍵點坐標將失效,解決辦法是使用關鍵點坐標的相對值,也就是將關鍵點坐標轉換為相對于人臉區域左上角坐標的偏移半分比,這樣一來即使圖片經過縮放,我們也可以通過百分比重新計算關鍵點坐標,相關轉換代碼如下:
class BBox:
def __init__(self, box):#box是人臉區域
self.left = box[0]
self.top = box[1]
self.right = box[2]
self.bottom = box[3]
self.x = box[0]
self.y = box[1]
self.w = box[2] - box[0]
self.h = box[3] - box[1]
def project(self, point):
#point對應人臉區域內的一點,要將它的絕對坐標轉換為相對于左上角的偏移比率
x = (point[0] - self.x) / self.w
y = (point[1] - self.y) / self.y
return np.asarray([x,y])
def reproject(slef, point):
#將相對偏移比率改為絕對坐標值
x = self.x + self.w * point[0]
y = self.y + self.h * point[1]
return np.assarray([x,y])
def reprojectLandmark(self, landmark):
#將特征點對應的偏移比率轉為絕對坐標值
p = np.zeros((len(landmark), 2))
for i in range(len(landmark)):
p[i] = self.reproject(landmark[i])
return p
def projectLandmark(self, landmark):
#將特征點對應的坐標值改為相對偏移比率
p = np.zeros((len(landmark), 2))
for i in range(len(landmark)):
p[i] = self.project(landmark[i])
return p
這里我們需要掌握兩個人臉影像變換函式,分別是翻轉和旋轉,其實作如下:
def flip(face , landmark): #將人臉影像翻轉
face_flipped_by_x = cv2.flip(face,1)
#翻轉后關鍵點的坐標也需要做相應變換
landmark_ = np.asarray([(1-x, y) for (x,y) in landmark])
landmark_[[0, 1]] = landmark_[[1, 0]]
landmark_[[3, 4]] = landmark_[[4,3]]
return (face_flipped_by_x, landmark_)
def rotate(img, box, landmark, alpha):#對人臉影像旋轉給定角度
center = ((box.left + box.right) / 2, (box.top + box.bottom) / 2)
rot_mat = cv2.getRotationMatrix2D(center, alpha, 1)
img_rotated_by_alpha = cv2.warpAffine(img, rot_mat, (img.shape[1], img.shape[0]))
#人臉旋轉后對關鍵點也要做相應旋轉
landmark_ = np.asarray([(rot_mat[0][0] * x + rot_mat[0][1] * y + rot_mat[0][2],
rot_mat[1][0] * x + rot_mat[1][1] * y + rot_mat[1][2]) for (x,y) in landmark])
face = img_rotated_by_alpha[box.top : box.bottom + 1, box.left:box.right+1]
return (face, landmark_)
我們呼叫這兩個函式看看它們所產生的效果,首先看看翻轉效果,在執行下面代碼前,記得一定要先執行一次上面繪制人臉的那一段代碼一次:
#運行該段代碼前需要執行前面繪制人臉和關鍵點的代碼
face_flipped, landmark_flip = flip(img, landmark)
for point in landmark_flip:
img = cv2.circle(face_flipped, (int(point[0]), int(point[1])), radius = 1, color=(0, 0, 255), thickness = 1)
cv2_imshow(img)
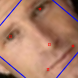
上面代碼運行后結果如下所示:
注意對比前面繪制的影像可以發現圖中人臉變得向左邊傾斜,而在翻轉前人臉是向右邊傾斜,接下來我們看看旋轉效果:
#執行這段代碼前記得運行前面繪制人臉影像的代碼
bbox = (box[0], box[2], box[1], box[3])
b_box = BBox(bbox)
face_rotated, landmark_rotated = rotate(img, b_box, landmark, 50)
for point in landmark_rotated:
img = cv2.circle(face_rotated, (int(point[0]), int(point[1])), radius = 1, color=(0, 0, 255), thickness = 1)
cv2_imshow(img)
代碼運行后效果如下:
為什么需要做這些操作呢,這些手段叫資料增強,其目的是增加圖片的多種形態,由此能訓練網路更好的識別人臉,
現在我們將前面讀取人臉區域和關鍵點坐標的代碼封裝到一個函式里:
def getDataFromTxt(txt, data_path, with_landmark = True):
with open(txt, 'r') as f:
lines = f.readlines() #讀取lwf資料集對應描述檔案中的每一行
result = []
for line in lines:
line = line.strip()
components = line.split(' ')
img_path = os.path.join(data_path, components[0]).replace("\\", '/')
box = (componets[1], componets[2], componets[3], componets[4]) #人臉區域
box = [float(_) for _ in box]
box = list(map(int, box))
if not with_landmark:
result.append((img_path, BBox(box)))
continue
landmark = np.zeros((5, 2))
for index in range(5):
rv = (float(componets[5+ 2*index]), float(componets[5 + 2*index+1]))
landmark[index] = rv
result.append((img_path, BBox(box), landmark))
return landmark
由于當前介紹的代碼已經足夠多,為了便于讀者消化,我們暫時先停止,后面我們還需要在基于現在這些代碼的基礎上對資料集的圖片進行加工處理,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/242335.html
標籤:AI
上一篇:隱藏在瀏覽器背后的“黑手”