hi各位大佬好,我是百變大魔王探花小明哥GBM.問題來源:領導說,這里要當成嚴格冷啟動問題,不能用預熱的行為資料,看來之前的LCE是肯定不行的,目前主要解決的是item冷啟動的問題,而對這些cold item的點擊行為也是冷的用戶,臥槽,這是真的冷啊,冰冷的夢里,無法跟你相聚,
For Recommendation in Deep learning QQ Group 277356808
For Visual in deep learning QQ Group 629530787
I'm here waiting for you
不接受這個網頁的私聊/私信!!!
開始——
MF是CF中最流行的方法(效果好唄),給定一個M*N的點擊行為(user M個,item N個),首先學習到低緯的user或者item隱向量,然后采用一個評分函式生成矩陣中缺失的分數,其中稀疏性和冷啟動問題則是比較困難的,傳統的方法例如inductive learning,meta learning及HIN都不符合嚴格冷啟動,因為他們都需要user/item在測驗集中有行為,當缺乏偏好資訊,比如,當一個新的電影上映,它就是個新的(冷的)item,那么是不知道bob對它的評分的,幸運的是,item的屬性資訊,例如導演和種類,可以代表這個item,因而,當電影有同樣的屬性就可以形成圖,這樣就能傳遞鄰節點偏好資訊,比如從美隊到復仇者,但是仍舊有兩個問題擺在面前,1,如何轉化屬性表達為偏好表達;2,如何有效地聚合不同形式的屬性(文字和影像),AGNN中首先采用一個擴展的變分自編碼器(VAE)產生偏好embedding(從重構的屬性分布中),另外也設計了一個gated-gnn聚合復雜的節點embedding,這樣模型有一個跳躍能力,因為可以指定節點embedding每個維度的不同重要性,
問題定義
令,M 和N是個數,分別是用戶和item,除此之外,每個用戶和item都有一系列不同領域的屬性,每個屬性都有離散編碼,所有的屬性拼接成multi-hot屬性編碼,示例
分別是性別,年齡,職業,令R是互動矩陣(也就是行為矩陣),可以是分數或者點擊與否,這就是典型的熱啟動評分預測問題,目標是預測未知的評分,而一般的冷啟動問題是,在訓練集中沒有user或者item,而在測驗集中有互動,如下示例:
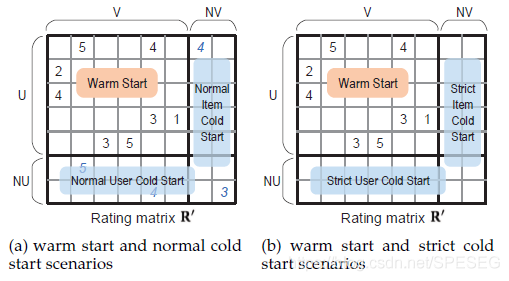
圖a和圖b不同之處是NV和NU在測驗集中無有評分(一般冷啟動的圖a有互動行為),而圖b則沒有,測驗集中也沒有互動行為,也就是預測NV或者NU的互動,
模型概覽
一個輸入層,一個互動層,一個gated-gnn層,一個預測層,gnn用來處理嚴格冷啟動中的user或item的屬性,VAE結構用來從屬性近似用戶的偏好,gnn則是用于資訊過濾或者聚合,如下所示,整體架構
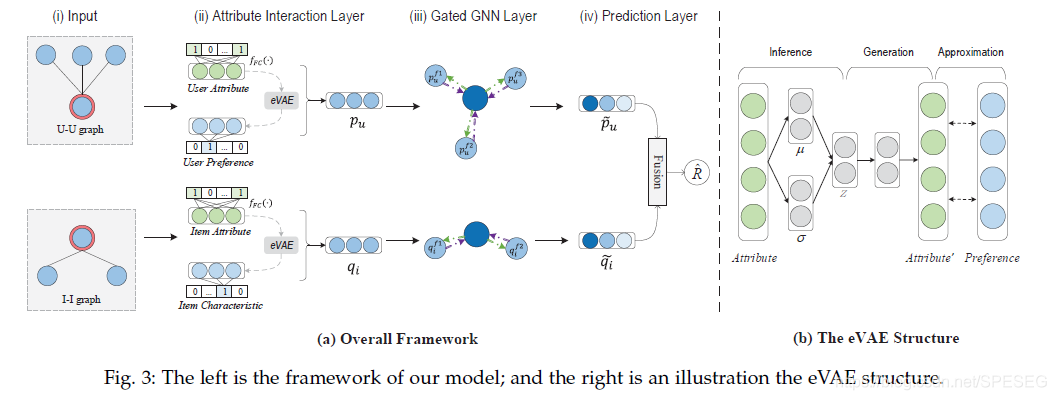
按照領導的思路,他肯定會問,U-U 圖和I-I圖是怎么構建的,臥槽,paper作者也沒給出個詳細介紹,代碼也有些繁雜,我還是提個issue吧.
模型結構
不同于兩部分的user-item 圖,模型是在現有的同樣屬性圖上,這樣使得模型能夠擺脫稀疏互動,屬性的質量是關鍵,在本文采用一個很自然的近似方法構建屬性圖,也會對比不同圖構建方法的影響,首先定義兩種近似:偏好近似,屬性近似,1)偏好近似度量兩個節點歷史偏好的相似性,如果兩個users有相似的評分記錄(或者兩個items有相同的評分表),那么他們將有一個高的偏好近似,注意,對嚴格冷啟動節點,因為沒有歷史評分,所以不能計算偏好近似,2)屬性近似度量兩個節點的屬性的相似度,如果兩個users有相似的用戶畫像(性別,職業,類別),那么他們將有高的屬性近似,近似的計算方法:
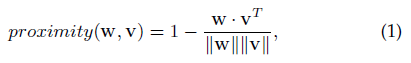
w和v是兩個節點的偏好表達或者multi-hot屬性編碼,兩種型別的近似經min-max norm后得到最終的近似,然后sum,因近似是在多種屬性上進行的,有必要保留多樣性鄰居,
大資料量下的one-hot表達維度高,而multi-hot僅僅是拼接在一起(像極了相親)而沒有考慮互動關系,互動的目的就是減少one-hot維度,為multi-hot學習到高階屬性互動,為了這個目的,首先建立一個查詢表,將節點的one-hot表達降低到dense向量,查表層對應兩個引數矩陣M,N,每個輸入編碼用戶的偏好和item的屬性,注意,
對嚴格冷啟動是無意義的,因為沒有互動訓練他們的偏好embedding,稍后再說,通過雙向互動pooling操作捕獲高階屬性互動,除此之外也有線性聯合操作,令
分別為第i和j個型別的屬性embedding向量,a是multi-hot屬性編碼,
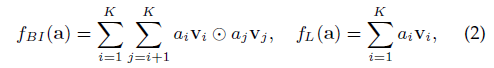
然后有一個FC,得到user或item的embedding
![]()
![]()
然后融合偏好embedding和屬性embedding得到節點embedding,這樣每個節點都有歷史偏好和本身的屬性,分號是拼接操作
![]()
對于嚴格冷啟動問題,節點沒有互動,那么就是偏好缺失問題,則直接從屬性embedding重構偏好embedding,一類用戶喜歡的item是類似的,比如,十幾歲的少年可能感興趣的是影片片,這就說明,屬性和偏好embedding不就在隱空間相近,而且有類似的分布,因此,采用VAE結構重構偏好,提出的擴展VAE如上Fig3b,有三部分,推斷,產生,近似,前兩部分是標準的VAE,第三個是擴展的,在產生部分,u給定一隱變數通過MLP生成,這部分略過(主要是 有點困了)
直接看gnn部分,a是聚合,f是過濾,給定用戶的節點u,其節點embedding為,其鄰集為Nu,節點embedding
是Nu中第i個鄰居
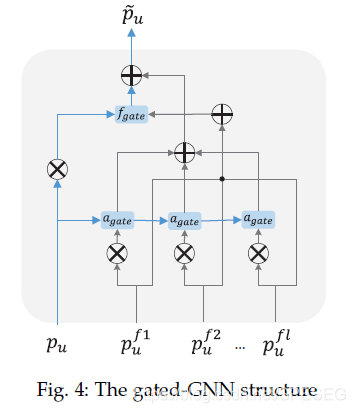
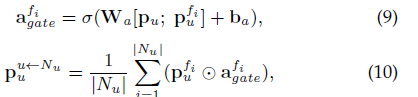
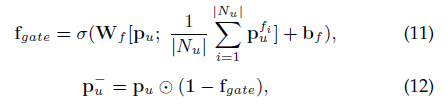
12式就是最終得到的user的embedding,同樣可以得到item的最終embedding,
預測層,有user和item的embedding,可以得到user對item的評分
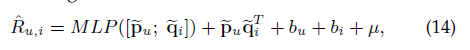
loss部分采用預測評分損失和重構損失(VAE那部分的),前者就是差的平方,評價指標是均方根誤差和MAE,1問題是我這里的都是隱式反饋,就是點擊與否,沒有評分,是不是都是換個loss就好了???不得而知啊,先看代碼吧,又是torch的,想起了蹩腳的英語,溝通就是費勁,2問題是我這里的情況是真的冷用戶啊,完全不知道他的屬性啥的(職業性別沒有的,人家一來你讓人家填這個玩意,人家都走了),這個實際應用還是有點難度啊,
代碼上面已經附過了,挖個坑,下次再填吧,不好整,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/242358.html
標籤:其他