1 步驟
kafka作為訊息佇列通常用來收集各個服務產生的資料,而下游各種資料服務訂閱消費資料,本文通過使用clickhouse 自帶的kafka 引擎,來同步消費資料,
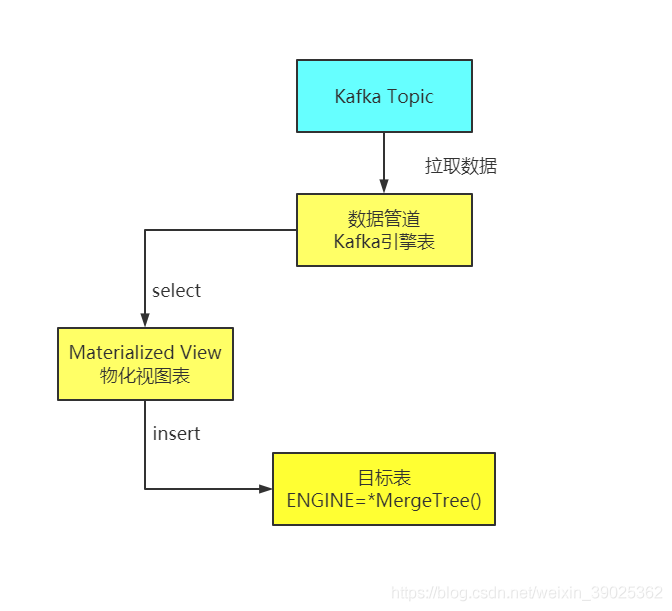
同步步驟:
- kafka中創建topic,創建消費者并消費該topic(查看消費情況)
- 建立目標表(通常是MergeTree引擎系列),用來存盤kafka中的資料;
- 建立kafka引擎表,用于接入kafka資料源;
- 創建Materialized View(物化視圖), 監聽kafka中的資料并將資料同步到clickhouse的目標表中;
同步流程圖如下:
2 創建測驗資料源
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic kafka-reader
# 創建消費者指定topic
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic kafka-reader --group kafka-reader-group
3 創建資料儲存目標表
CREATE TABLE target(
day Date,
level String,
message String
) ENGINE = SummingMergeTree(day, (day, level), 8192);
4 創建kafka消費表
1 使用kafka引擎創建queue表來連接kafka并讀取topic中的資料,該資料表訂閱了名為kafka-reader的訊息主題,且消費組的名稱為kafka-reader-group,?訊息的格式采?了JSONEachRow,
2 在此之后,查詢這張資料表就能夠看到Kafka的資料了,但是再次查詢這張便就會沒有資料了,這是因為Kafka表引擎在執?查詢之后就會洗掉表內的資料,
CREATE TABLE queue (
timestamp DateTime,
level String,
message String
)
ENGINE = Kafka
SETTINGS kafka_broker_list = '192.168.9.226:9092',
kafka_topic_list = 'kafka-reader',
kafka_row_delimiter = '\n',
kafka_group_name = 'kafka-reader-group',
kafka_format = 'JSONEachRow'
引數決議–必要引數:
- kafka_broker_list – 以逗號分隔的kafka的brokers 串列 (192.168.9.226:9092),
- kafka_topic_list – topic 串列 (kafka-reader),
- kafka_group_name – Kafka 消費組名稱 (kafka-reader-group),如果不希望訊息在集群中重復,請在每個分片中使用相同的組名,
- kafka_format – 訊息體格式,JSONEachRow也就是普通的json格式,使用與 SQL 部分的 FORMAT 函式相同表示方法,
引數決議–可選引數:
- kafka_row_delimiter - 每個訊息體之間的分隔符,
- kafka_schema – 如果決議格式需要一個 schema 時,此引數必填,例如,普羅托船長 需要 schema - 檔案路徑以及根物件 schema.capnp:Message 的名字,
- kafka_num_consumers – 單個表的消費者數量,默認值是:1,如果一個消費者的吞吐量不足,則指定更多的消費者,消費者的總數不應該超過 topic 中磁區的數量,因為每個磁區只能分配一個消費者,
5 創建Materialized View(物化視圖)傳輸資料
創建好的物化視圖,它將會在后臺收集資料,可以持續不斷地從 Kafka 收集資料并通過 SELECT 將資料轉換為所需要的格式,
CREATE MATERIALIZED VIEW consumer TO target
AS SELECT toDate(toDateTime(timestamp)) AS day, level, count() as total
FROM queue GROUP BY day, level;
6 測驗
生產者添加資料:

查詢目標表,查看消費資料
SELECT *
FROM target
┌────────day─┬─level─┬─message─┐
│ 2020-12-01 │ 11 │ 不開心 │
│ 2020-12-30 │ 13 │ 寫博客 │
│ 2020-12-31 │ 15 │ 買可樂 │
│ 2020-12-31 │ 17 │ 真好喝 │
└────────────┴───────┴─────────┘
查詢consumer物化視圖表,一般得到的資料和目標表差不多,除非實時資料很多,停止接收topic資料或更改轉換邏輯需要停用物化視圖,更改完之后再啟用物化視圖
# 停用
DETACH TABLE consumer;
# 啟用
ATTACH TABLE consumer;
總結
clickhouse消費kafka資料的程序中,通過kafka引擎表作為一個管道接收流入的資料,而物化視圖負責將kafka引擎表的資料實時同步到目標表中,我們通過不同sql陳述句封裝將kafka資料匯入到不同目標表中,這是不錯消費方式,
創作不易,喜歡的話可以點贊加關注哦!阿里嘎多民那桑!
參考文章: clickhouse官方檔案
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/242854.html
標籤:其他
上一篇:keil5 C51和MDK版本合并方法+C51庫匯入方法
下一篇:分布式云盤系統例題