文章目錄
- 前言
- 一、HashMap類圖
- 二、原始碼剖析
- 1. HashMap(jdk1.7版本) - 此篇詳解
- 2. HashMap(jdk1.8版本)
- 3. ConcurrentHashMap
- ~~ 碼上福利
前言
業精于勤荒于嬉,行成于思毀于隨;
在碼農的大道上,唯有自己強才是真正的強者,求人不如求己,靜下心來,開始思考…
今天一起來聊一聊 HashMap集合,看到這里,筆者懂,大家莫慌,先來寶圖鎮樓 ~

咳咳… 對于螢屏前帥氣的猿友們來說,HashMap… 張口就來,閉眼能寫,但是呢,面試一問立馬慌,自己閱讀原始碼又隱隱覺得知其然不知其所以然;
那么…此時,筆者帥氣的臉龐似有似無洋溢起一抹微笑,畢竟是查看過原始碼的猿,就是那么的豪橫,話不多說,來吧,展示…
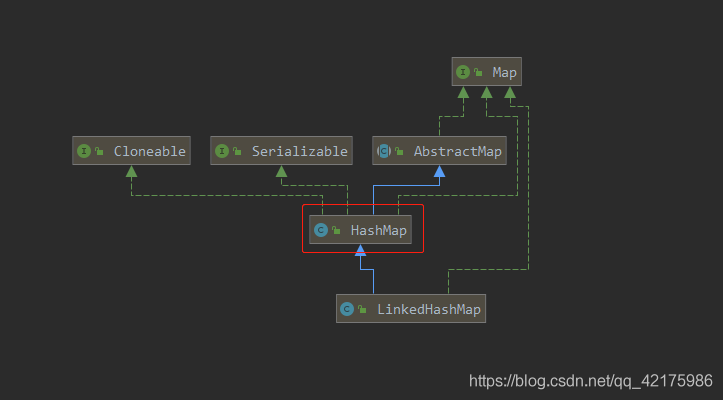
一、HashMap類圖
二、原始碼剖析
1. HashMap(jdk1.7版本) - 此篇詳解
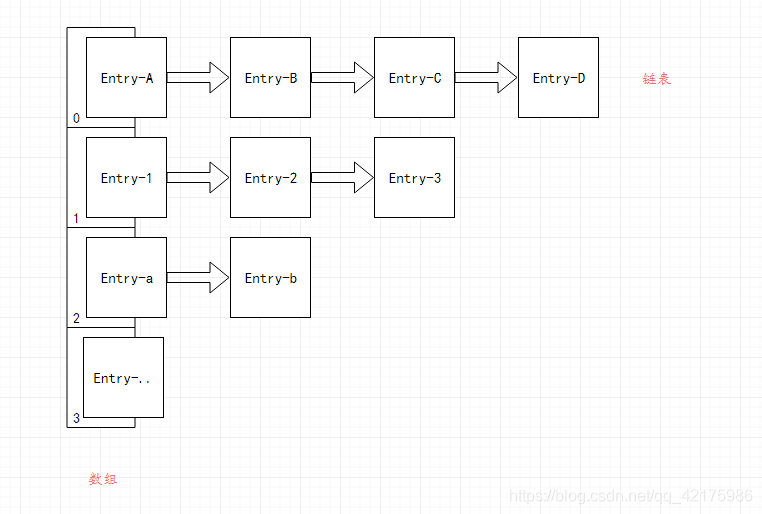
大家都知道,jdk1.7版本底層陣列+鏈表(單向鏈表),結合筆者的經驗之談,我覺得在分析HashMap集合具體操作原始碼前,有必要先了解下其底層鏈表結構,上原始碼…
- 鏈表結構 - 單向鏈表
/**
* HashMap1.7中定義- 單向鏈表
*/
static class Entry<K,V> implements Map.Entry<K,V> {
// key值
final K key;
// value值
V value;
// 下一個節點
Entry<K,V> next;
// hash值
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 重寫equals方法
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
// 重寫hashCode方法
public final int hashCode() { return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue()); }
// 重寫toString方法
public final String toString() { return getKey() + "=" + getValue(); }
// value被覆寫呼叫一次
void recordAccess(HashMap<K,V> m) { }
// todo:此此兩方法主要作用于HashMap的子類實作,eg:linkedHashMap
// 每移除一個entry就被呼叫一次
void recordRemoval(HashMap<K,V> m) { }
}
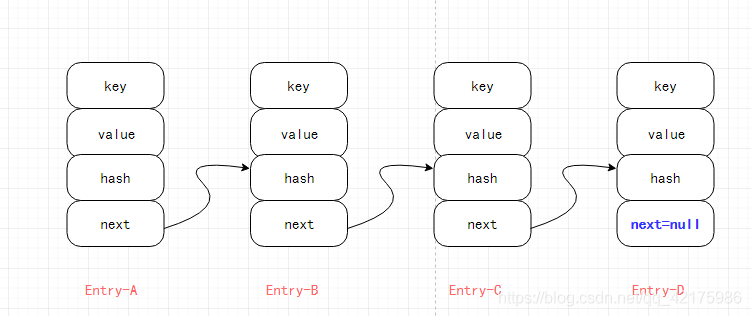
如此如此,這般這般… 然而…這就是HashMap1.7版本定義的鏈表結構之單向鏈表…
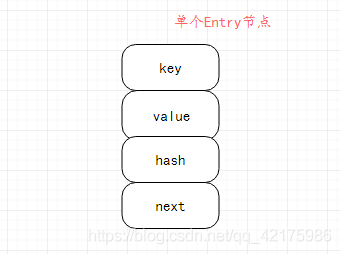
每一個Entry節點包含四個屬性:key表示當前節點key值;value表示當前節點value值,next節點表示當前節點下一個節點,如當前節點為鏈表末尾節點,則當前節點的next節點為null;hash表示當前節點key值通過演算法計算出來的hash值;
抽象圖解如下(其實筆者并不是很認同此圖能形象的代表鏈表結構,但抽象理解還是可以的):
單個Entry節點:
單向鏈表圖解:
HashMap1.7版本底層 陣列 + 單向鏈表 圖解:
- 建構式
// 陣列默認初始容量 - 16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// 加載因子 - 默認值
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 加載因子
final float loadFactor;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 擴容閾值(也表示hashMap底層陣列實際存放元素大小)
int threshold;
/**
* 無參構造
*/
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
/**
* 有參構造
* @param initialCapacity:自定義初始容量
* @param loadFactor:自定義
*/
public HashMap(int initialCapacity, float loadFactor) {
// 判斷初始容量值有效性
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
// 判斷最大初始容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 判斷加載因子有效性
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
// 設定加載因子-默認0.75
this.loadFactor = loadFactor;
// 設定擴容閾值(構造初始化為16,第一次put為12)
threshold = initialCapacity;
// 模板方法-默認無實作
init();
}
// 模板方法-設計模式:表示繼承可拓展
void init() {
}
從原始碼中可以看出,構造只為相關引數(加載因子、擴容閾值)進行初始化;
其中需注意一點,我們都知道HashMap的擴容閾值為12,但在構造初始化的時候擴容閾值為16(知識點雖小,但卻是細節);
那么此篇文章重點要來了,靜下心來,開始思考…
- put() - 添加元素方法
// 陣列默認值-空陣列
static final Entry<?,?>[] EMPTY_TABLE = {};
// 底層陣列
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
// HashMap元素個數
transient int size;
// 記錄對HashMap操作次數
transient int modCount;
transient int hashSeed = 0;
/**
* 入口
*/
public V put(K key, V value) {
// 1.第一次put元素
// 陣列為空進行引數初始化-表示第一次put元素
if (table == EMPTY_TABLE) {
// 陣列初始化/引數初始化
// 第一次put時,threshold經過構造方法賦值為16
inflateTable(threshold);
}
// 2.添加key為null的元素
if (key == null)
return putForNullKey(value);
// 3.添加key非null的元素
// 計算hash值
int hash = hash(key);
// 計算陣列對應下標值
int i = indexFor(hash, table.length);
// 遍歷陣列下標為i的鏈表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// hash沖突 && key相同
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
// 獲取遍歷節點元素值
V oldValue = e.value;
// 對value進行覆寫
e.value = value;
// value被覆寫時呼叫
e.recordAccess(this);
// 回傳舊元素值
return oldValue;
}
}
// 操作次數++
modCount++;
// 添加Entry節點
addEntry(hash, key, value, i);
return null;
}
// 陣列初始化/引數初始化
private void inflateTable(int toSize) {
// 計算初始容量
// 第一次put時,回傳值:16
int capacity = roundUpToPowerOf2(toSize);
// 計算擴容閾值:16 * 0.75 = 12
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
// 初始化長度為16的table陣列
table = new Entry[capacity];
// 此方法不影響主要功能,咱跳過此方法(有興趣的猿友們可自行研究哦~)
initHashSeedAsNeeded(capacity);
}
// 用于回傳大于等于最接近number的2的整數次冪
private static int roundUpToPowerOf2(int number) {
// 第一次put元素時: 16 >= 陣列最大容量(1 << 30) ? (1 << 30) : (16 > 1) ? Integer.highestOneBit((16-1) << 1) : 1
// Integer.highestOneBit((16-1) << 1) = Integer.highestOneBit(30) = 16
return number >= MAXIMUM_CAPACITY ? MAXIMUM_CAPACITY : (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
// 添加key為null的元素 - 可以看出key為null時,存放在陣列下標為0的位置
private V putForNullKey(V value) {
// 遍歷陣列下標為0的鏈表
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
// 獲取遍歷節點元素值
V oldValue = e.value;
// 對value進行覆寫
e.value = value;
// value被覆寫時呼叫
e.recordAccess(this);
// 回傳舊值
return oldValue;
}
}
// 操作次數++
modCount++;
// 添加Entry節點
addEntry(0, null, value, 0);
return null;
}
// 添加Entry節點
void addEntry(int hash, K key, V value, int bucketIndex) {
// map元素個數 > 擴容閾值 && 當前陣列位置對應鏈表不為空
if ((size >= threshold) && (null != table[bucketIndex])) {
// 將源陣列中的元素值散列至新陣列
resize(2 * table.length);
// 計算hash值 - 重新計算
hash = (null != key) ? hash(key) : 0;
// 計算對應新陣列下標位置
bucketIndex = indexFor(hash, table.length);
}
// 添加Eentry節點
createEntry(hash, key, value, bucketIndex);
}
// 將源陣列中的元素值散列至新陣列
void resize(int newCapacity) {
// 獲取源陣列
Entry[] oldTable = table;
// 獲取源陣列長度
int oldCapacity = oldTable.length;
// 陣列長度最大值設定
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 創建長度為源陣列長度2倍的新陣列
Entry[] newTable = new Entry[newCapacity];
// 將源陣列中的元素值散列至新陣列
transfer(newTable, initHashSeedAsNeeded(newCapacity));
// 將新陣列賦值至源陣列
table = newTable;
// 重新計算擴容閾值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
// 獲取當前Key對應hash值
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String)
return sun.misc.Hashing.stringHash32((String) k);
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
// 獲取對應陣列下標位置
static int indexFor(int h, int length) {
return h & (length-1);
}
// 添加Eentry節點
void createEntry(int hash, K key, V value, int bucketIndex) {
// 獲取陣列下標對應鏈表
Entry<K,V> e = table[bucketIndex];
// 向鏈表中添加節點
table[bucketIndex] = new Entry<>(hash, key, value, e);
// HashMap元素個數++
size++;
}
// 將源陣列中元素散列至新陣列中
void transfer(Entry[] newTable, boolean rehash) {
// 獲取新陣列長度
int newCapacity = newTable.length;
// 遍歷源陣列,將元素按照一定規則散列至新陣列
// 外回圈:遍歷陣列
for (Entry<K,V> e : table) {
// 內回圈:遍歷陣列位置對應鏈表
while(null != e) {
// 獲取當前節點下一個節點
Entry<K,V> next = e.next;
if (rehash) {
// true:重新計算hash值
e.hash = null == e.key ? 0 : hash(e.key);
}
// 獲取對應新陣列的下標值
int i = indexFor(e.hash, newCapacity);
// 下面三步一定要連起來去思考:
// **前提條件,2次回圈都作用于新陣列同一下標位置的情況:
// 第一次回圈時,newTable[i]為空,先賦值給當前遍歷節點的下個節點,再將當前遍歷節點賦值給對應新下標的新陣列,最后繼續回圈
// 第二次回圈時,newTable[i]為上次(存入同一下標位置對應新陣列的鏈表),然后賦值給當前遍歷節點的下個節點(此節點實則為上一次遍歷節點的下一個節點,
// 從這里可以看出,HashMap1.7這里用的是頭插法),再將此鏈表賦值給同一下標位置的新陣列中,最后不為空繼續回圈;
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
果不其然,相信大部分猿友硬著頭皮跟一大坨代碼硬鋼之下,還是放棄了抵抗,來到了這里看筆者結論;
此時,筆者帥氣的臉龐似有似無洋溢起一抹微笑,畢竟是查看過原始碼的猿;
其實呢,看原始碼也是有其講究的,相信細心的猿友已從筆者原始碼注釋看出些許問道,正如其所料,其實說白了,put()添加元素方法只做了三件事,下面我們拆解分析下:
- 第一次put元素(當前為第一次添加元素時):
- 計算擴容閾值:
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); // threshold = 16 * 0.75 = 12
- 初始化底層陣列:
table = new Entry[capacity]; // capacity = 16
- 添加key為null的元素:
-
遍歷陣列下標為0的鏈表:
⑴ 如判斷已存在 key=null 的節點,則覆寫其value值;
if (e.key == null) {
// 獲取遍歷節點元素值
V oldValue = e.value;
// 對value進行覆寫
e.value = value;
// value被覆寫時呼叫
e.recordAccess(this);
// 回傳舊值
return oldValue;
}
⑵ 反之,則添加節點;
// 操作次數++
modCount++;
// 添加Entry節點
addEntry(0, null, value, 0);
- 添加key非null的元素:
-
計算key鍵對應的hash值:
-
通過hash值計算對應陣列下標存放位置;
-
遍歷陣列對應下標的鏈表(步驟2計算的下標):
⑴ 如判斷hash值相等且key值相等,則覆寫其value值;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
// 獲取遍歷節點元素值
V oldValue = e.value;
// 對value進行覆寫
e.value = value;
// value被覆寫時呼叫
e.recordAccess(this);
// 回傳舊元素值
return oldValue;
}
⑵ 反之,則添加節點;
// 操作次數++
modCount++;
// 添加Entry節點
addEntry(0, null, value, 0);
不知過了許久…
此時,筆者嘴角若隱若現一絲弧度微起,原始碼么,也不過如此…
咳咳… 請原諒筆者,畢竟從小到大無如此之成就感爆棚,猝不及防下狠狠地又裝了一把…
我們言歸正傳,相信螢屏前的猿友經過筆者此分析,或多或少識訓些許原始碼知識,至于其中如何判斷key存在,如何進行value值覆寫,如何添加Entry節點,相信對于現在已然拿下put()方法框架思路的猿友來說,只是so easy的事情了,那么…此時…往上翻翻吧,趁著思路清晰,靜下心來,參考著筆者原始碼注釋,爭取拿下其方法細節…
此時此刻,螢屏前擁有盛世美顏的你,給也同樣擁有盛世美顏的暖男筆者,賞臉來個三連吧…筆者已迫不及待準備好么么噠,親在…
- get() - 獲取元素方法
/**
* 入口
*/
public V get(Object key) {
// key為空時獲取元素值
if (key == null)
return getForNullKey();
// 獲取key對應Entry鏈表
Entry<K,V> entry = getEntry(key);
// 回傳對應元素值
return null == entry ? null : entry.getValue();
}
// key為慷訓取元素值 - 可以看出key為null時,在下標為0的位置的陣列獲取
private V getForNullKey() {
// map元素個數為0時回傳 null
if (size == 0) {
return null;
}
// 獲取下標為0的鏈表
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
// 遍歷key=null,回傳對應元素值
if (e.key == null)
return e.value;
}
// 無->回傳null
return null;
}
// 獲取key對應Entry鏈表
final Entry<K,V> getEntry(Object key) {
// map元素個數為0時回傳 null
if (size == 0) {
return null;
}
// 計算hash
int hash = (key == null) ? 0 : hash(key);
// 1.計算對應陣列下標值 2.遍歷陣列位置對應鏈表
for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
// hash相等 && key相等
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
// 無->回傳null
return null;
}
相信對于螢屏前已拿下put()方法的你來說,獲取元素方法,簡直very so easy;
從原始碼中可以看出,獲取元素時做了2件事:
- 獲取 key=null 的元素:
-
遍歷陣列下標為0的鏈表:
⑴ 如判斷已存在 key=null 的節點,則回傳其value值;
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
// 遍歷key=null,回傳對應元素值
if (e.key == null)
return e.value;
}
⑵ 反之,則回傳null;
- 獲取 key非null 的元素:
-
計算key鍵對應的hash值:
-
通過hash值計算對應陣列下標存放位置;
-
遍歷陣列對應下標的鏈表(步驟2計算的下標):
⑴ 如判斷hash值相等且key值相等,則回傳其value值;
for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
// hash相等 && key相等
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
⑵ 反之,則回傳 null;
筆者:當你翻過代碼中最高的的一座山之后,剩下的只是一碼平川;
- remove() - 洗掉元素方法
/**
* 入口
*/
public V remove(Object key) {
// 獲取key對應Entry鏈表
Entry<K,V> e = removeEntryForKey(key);
// 回傳洗掉元素值
return (e == null ? null : e.value);
}
// 獲取洗掉元素對應Entry鏈表
final Entry<K,V> removeEntryForKey(Object key) {
// map元素個數為0時回傳 null
if (size == 0) {
return null;
}
// 計算hash值
int hash = (key == null) ? 0 : hash(key);
// 計算對應陣列下標位置
int i = indexFor(hash, table.length);
// 獲取陣列下標為i對應鏈表
Entry<K,V> prev = table[i];
// 鏈表第一次賦值
Entry<K,V> e = prev;
// 遍歷此鏈表
while (e != null) {
// 獲取當前節點下一個節點
Entry<K,V> next = e.next;
Object k;
// hash相等 && key相等
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) {
// 操作次數++
modCount++;
// map元素個數--
size--;
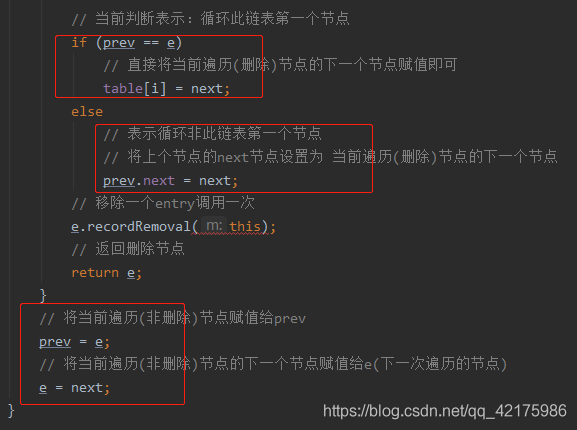
// 當前判斷表示:回圈此鏈表第一個節點
if (prev == e)
// 直接將當前遍歷(洗掉)節點的下一個節點賦值即可
table[i] = next;
else
// 表示回圈非此鏈表第一個節點
// 將上個節點的next節點設定為 當前遍歷(洗掉)節點的下一個節點
prev.next = next;
// 移除一個entry呼叫一次
e.recordRemoval(this);
// 回傳洗掉節點
return e;
}
// 將當前遍歷(非洗掉)節點賦值給prev
prev = e;
// 將當前遍歷(非洗掉)節點的下一個節點賦值給e(下一次遍歷的節點)
e = next;
}
// e!=null但無對應key -> 回傳此鏈表最后一個Entry節點
// e==null -> 回傳null
return e;
}
相信螢屏前的猿友,此時此刻正干勁十足,越挫越勇,那么… 恭黑雷(恭喜你),拿下HashMap近在咫尺;
從原始碼中可以看出,洗掉元素實則就做了一件事,修改節點之間的參考;
注意,洗掉元素中唯一比較繞的就是此代碼,結合筆者注釋,注意細節即可:
- HashMap(jdk1.7版本)總結:
- 底層為陣列 + 鏈表(單向鏈表);
- 執行緒不安全;
- 陣列初始容量為16;
- 擴容加載因子為0.75;
- 擴容閾值 a.構造之后為16,第一次put()方法后為12;
- 擴容死回圈問題 - 筆者之后會另起一篇詳解;
- 有modCount;
2. HashMap(jdk1.8版本)
面試一次問一次,HashMap是該拿下了之 HashMap1.8版本
3. ConcurrentHashMap
面試一次問一次,HashMap是該拿下了之 ConcurrentHashMap
~~ 碼上福利
大家好,我是猿醫生:
在碼農的大道上,唯有自己強才是真正的強者,求人不如求己,靜下心來,掃碼一起學習吧…

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/243269.html
標籤:其他