目錄
一、Redis存盤的資料的資料結構
二、Redis中鍵和值得資料結構
1、redis鍵值的資料結構
2、hash沖突
3、rehash阻塞
4、漸進式rehash
二、壓縮串列
三、跳表
四、rdis使用建議
一、Redis存盤的資料的資料結構
我們都只到Redis常用的資料結構為String,List,Hash,Set,Sorted Set,但這只是我們在用的時候鍵值對的表現形式,他們底層真正使用的資料結構為簡單動態字串,雙向鏈表,壓縮串列,哈希表,調表和整數陣列

可以看到,String 型別的底層實作只有一種資料結構,也就是簡單動態字串,而 List、Hash、Set 和 Sorted Set 這四種資料型別,都有兩種底層實作結構,通常情況下,我們會把這四種型別稱為集合型別,它們的特點是一個鍵對應了一個集合的資料
二、Redis中鍵和值得資料結構
1、redis鍵值的資料結構
因為redis本身要求獲取速度快,那么時間復雜度肯定是O1,為了實作從鍵到值的快速訪問,Redis 使用了一個哈希表來保存所有鍵值對,資料結構如下
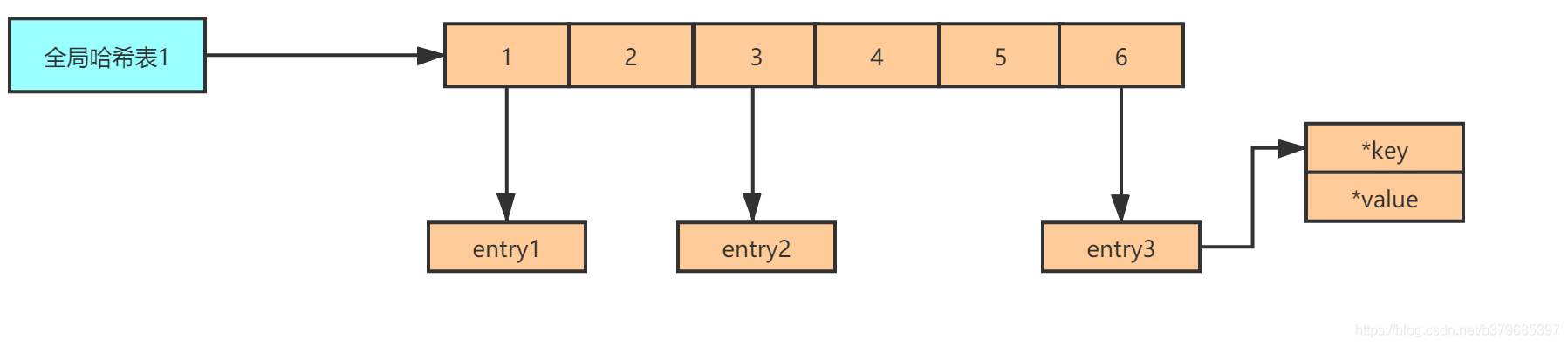
redis是由一個全域hash表存盤所有鍵和值得關系,值存的為物件的地址,
2、hash沖突
既然使用hash表,那么就肯定會有hash沖突,Redis 解決哈希沖突的方式,和JAVA中的hash表解決方式一樣,也是鏈式哈希,鏈式哈希也很容易理解,就是指同一個哈希桶中的多個元素用一個鏈表來保存,它們之間依次用指標連接,
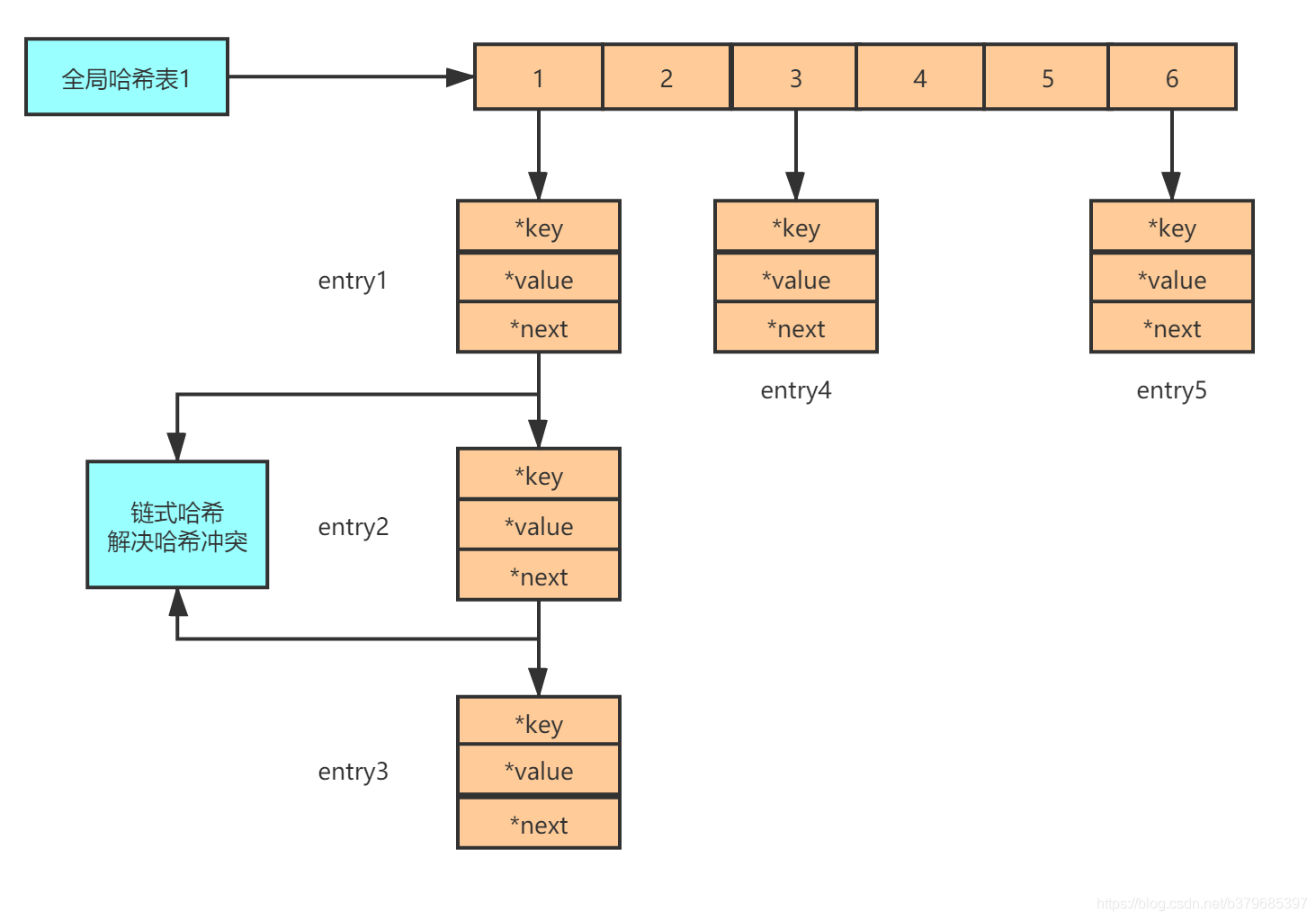
因此當Key特別大的時候,存在著鏈式查找的一個時間消耗,特別是當我們存在幾千萬key的時候,那這個時間消耗也是非常多的
3、rehash阻塞
為了解決hash沖突帶來的鏈表長度太長,因此redis引入對hash的rehash操作
rehash 也就是增加現有的哈希桶數量,讓逐漸增多的 entry 元素能在更多的桶之間分散保存,減少單個桶中的元素數量,從而減少單個桶中的沖突,
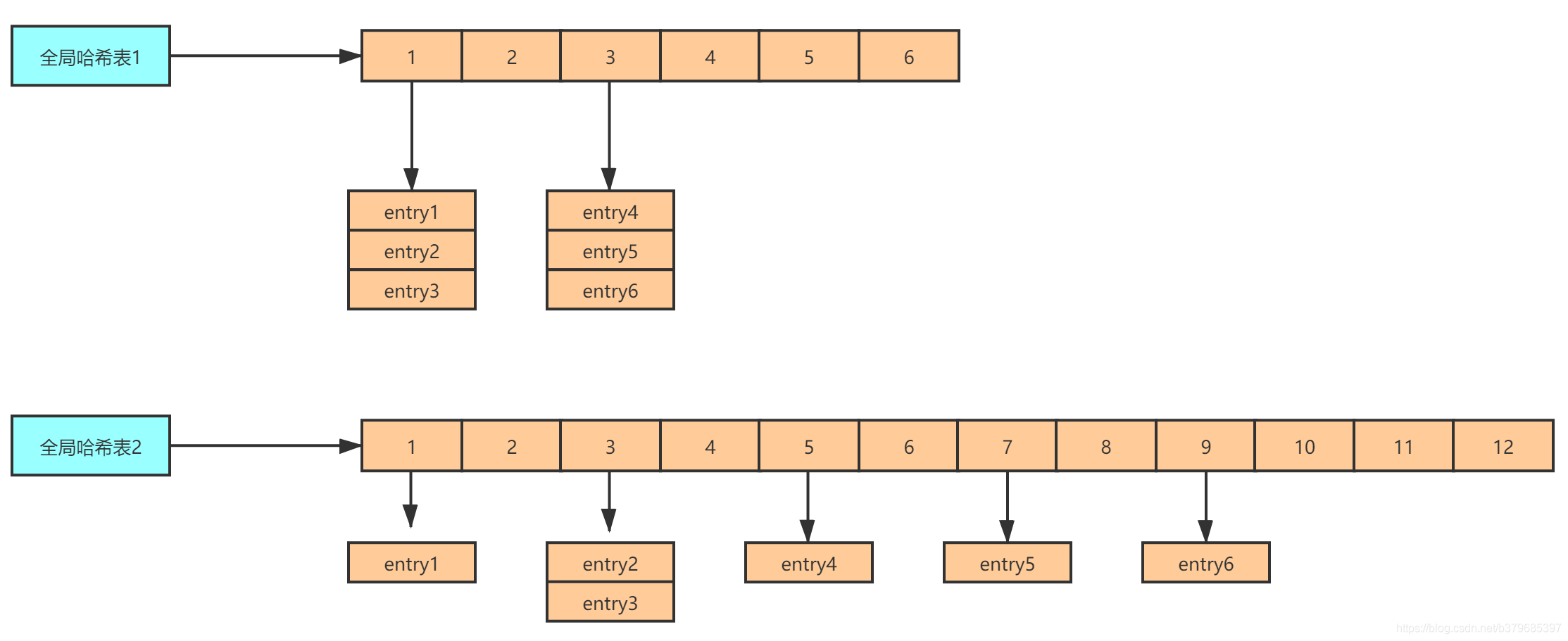
具體操作
Redis 默認使用了兩個全域哈希表:哈希表 1 和哈希表 2,一開始,當你剛插入資料時,默認使用哈希表 1,此時的哈希表 2 并沒有被分配空間,隨著資料逐步增多,Redis 開始執行 rehash,這個程序分為三步:
1、給哈希表 2 分配更大的空間,例如是當前哈希表 1 大小的兩倍;
2、把哈希表 1 中的資料重新進行打散映射到hash表2中;
3、釋放哈希表 1 的空間,
我們就可以從哈希表 1 切換到哈希表 2,用增大的哈希表 2 保存更多資料,而原來的哈希表 1 留作下一次 rehash 擴容備用
這個程序看似簡單,但是第二步涉及大量的資料拷貝,如果一次性把哈希表 1 中的資料都遷移完,會造成 Redis 執行緒阻塞,無法服務其他請求,此時,Redis 就無法快速訪問資料了,
為了避免這個問題,Redis 采用了漸進式 rehash,
4、漸進式rehash
簡單來說就是在第二步拷貝資料時,Redis 仍然正常處理客戶端請求,每處理一個請求時,從哈希表 1 中的第一個索引位置開始,順帶著將這個索引位置上的所有 entries 拷貝到哈希表 2 中;等處理下一個請求時,再順帶拷貝哈希表 1 中的下一個索引位置的 entries,如下圖所示:
這樣就巧妙地把一次性大量拷貝的開銷,分攤到了多次處理請求的程序中,避免了耗時操作,保證了資料的快速訪問,
二、壓縮串列
之前也說了,集合型別的底層資料結構主要有 5 種:整數陣列、雙向鏈表、哈希表、壓縮串列和跳表,其中,哈希表剛才已經講過,整數陣列、雙向鏈表也比較常見,那么我們具體看下壓縮串列和跳表
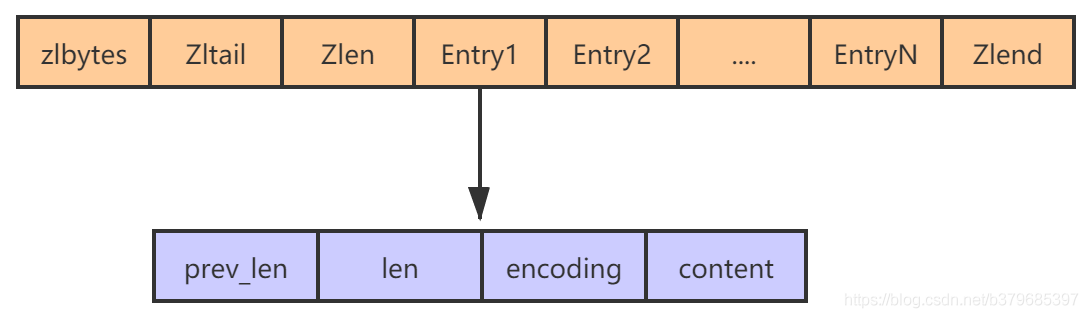
zlbytes:記錄壓縮串列占用的記憶體位元組數,對壓縮串列進行記憶體重分配或者計算zlen位置時使用,占用4個位元組
Zltail:記錄也鎖串列未節點距離壓縮串列的起始節點有多少位元組,通過這個偏移量,程式無需便利整個壓縮串列就可以確定表尾節點的位置 占用4個位元組
Zllen:記錄串列包含的節點數量,占用2個位元組
Zllend:記錄壓縮串列的末端,占用1個位元組
entry:壓縮串列保存的資料,主要有以下屬性
- prev_len,表示前一個 entry 的長度,prev_len 有兩種取值情況:1 位元組或 5 位元組,取值 1 位元組時,表示上一個 entry 的長度小于 254 位元組,雖然 1 位元組的值能表示的數值范圍是 0 到 255,但是壓縮串列中 zlend 的取值默認是 255,因此,就默認用 255 表示整個壓縮串列的結束,其他表示長度的地方就不能再用 255 這個值了,所以,當上一個 entry 長度小于 254 位元組時,prev_len 取值為 1 位元組,否則,就取值為 5 位元組,
- len:表示自身長度,4 位元組;
- encoding:表示編碼方式,1 位元組;
- content:保存實際資料,
如果我們要查找定位第一個元素和最后一個元素,可以通過表頭三個欄位的長度直接定位,復雜度是 O(1),而查找其他元素時,就沒有這么高效了,只能逐個查找,此時的復雜度就是 O(N) 了,
三、跳表
有序鏈表只能逐一查找元素,導致操作起來非常緩慢,于是就出現了跳表,具體來說,跳表在鏈表的基礎上,增加了多級索引,通過索引位置的幾個跳轉,實作資料的快速定位,
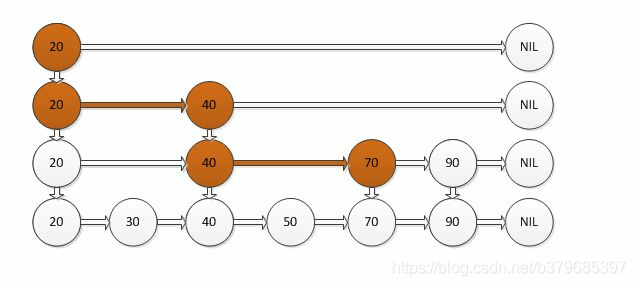
如果我們使用上圖所示的跳躍表,就可以減少查找所需時間為O(n/2),因為我們可以先通過每個節點的最上面的指標先進行查找,這樣子就能跳過一半的節點,
比如我們想查找50,首先和20比較,大于20之后,在和40進行比較,然后在和70進行比較,發現70大于50,說明查找的點在40和50之間,從這個程序中,我們可以看出,查找的時候跳過了30,
跳躍表其實也是一種通過“空間來換取時間”的一個演算法,令鏈表的每個結點不僅記錄next結點位置,還可以按照level層級分別記錄后繼第level個結點,此法使用的就是“先大步查找確定范圍,再逐漸縮小迫近”的思想進行的查找,跳躍表在演算法效率上很接近紅黑樹,
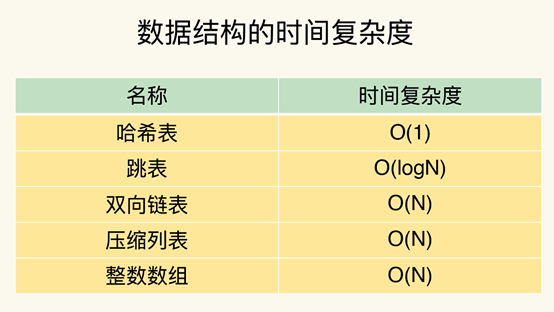
四、Redis資料結構時間復雜度
五、Redis使用建議
第一,對于單元素操作,對于redis的使用盡量使用單元素操作,這種效率一般都比較高,
第二,范圍操作,是指集合型別中的遍歷操作,可以回傳集合中的所有資料,這類操作一般都比較耗時,盡量避免
第三,統計操作,是指集合型別對集合中所有元素個數的記錄,因為這些資料結構本身記錄所有元素個數,時間復雜度為O(1)所以效率很高
第四,例外情況,是指某些資料結構的特殊記錄,例如壓縮串列和雙向鏈表都會記錄表頭和表尾的偏移量,對于頭插和尾插增刪元素可以通過偏移量直接定位,所以時間復雜度也是O(1),實作快速操
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/243287.html
標籤:其他
上一篇:Scala練習02-陣列函式解決Hive查詢問題-每個用戶截止到每月為止的最大單月訪問次數和累計到該月的總訪問次數