目錄
- 1,什么是cell ?為什么有cell ?
- 2,cell的兩種架構模式及作業原理
- 3 , Cell v2實作的原理
1,什么是cell ?為什么有cell ?
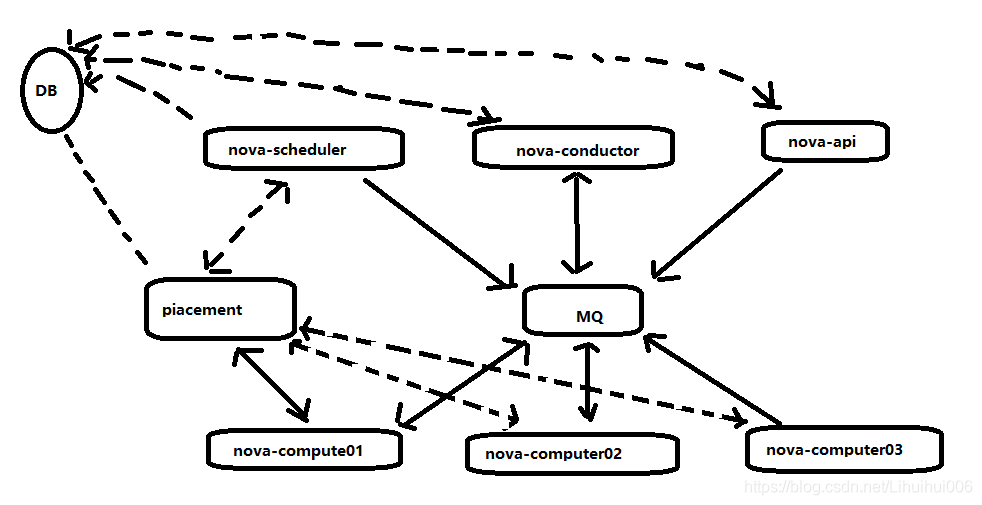
- 當openstack nova 集群的規模變大時,所有的 Nova Compute節點全部連接到同一個 MQ,在有大量定時任務通過 MQ 上報給Nova-Conductor服務的情況下,資料庫和訊息佇列服務就會出現瓶頸,而此時nova為提高水平擴展及分布式,大規模的部署能力,同時又不增加資料庫和訊息中間件的復雜度,引入了Cell概念,
如下圖大量資料上報給DB資料庫:
-
如何理解cell? cell可以看做是一個單元,為支持更大規模的部署,openstack將大的nova集群分成小的單元,每個單元都有自己的訊息佇列和資料庫,可以解決規模曾大時候引起的瓶頸問題,在cell中,keystone, neutron,cinder,glance等資源是共享的,
還有一個就是API節點上的資料庫
- nova-api資料庫中存放全域資訊,這些全域資料表是從nova庫遷移過來的,如flavor(實體模型) ,instance groups (實體組), quota(配額)
- nova-cell0資料庫的模式與nova一樣,主要的作用就是當實體調度失敗時,實體的資訊將不屬于任何一個cell ,因而存放到nova_cell0中,所以說cell0是存放資料調度失敗的資料用來集中管理,
2,cell的兩種架構模式及作業原理
單cell部署 架構模式:
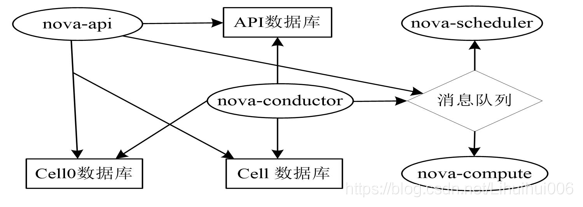
多cell部署 架構模式:
下圖整個有三部分組成,cell0, , cell1. cell2 位于最上層的cell0,也就是api-cell, 而下層的cell1與cell2則是平行對等的關系,他們之間無互動,相互獨立,還可以繼續增加cell3,cell4 , 而上層的api cell主要包括了
Nova API, Nova Scheduler, Nova Conductor 這3個 Nova 服務 ,同時在 API Cell 中還需要 MQ 提供組件內的通信服務,API Cell 中的 DB 包含兩個資料庫,分別是 api資料庫 和 cell資料庫,api 資料庫保存了全域資料,比如 flavor 資訊,此外 api 資料庫中還有一部分表是用于 placement 服務的;而 cell資料庫則是用于保存創建失敗且還沒有確定位于哪個 cell 的虛機資料,比如當虛擬機調度失敗時,該虛擬機資料就會被保存到cell資料庫中,也就是cell0資料庫中,
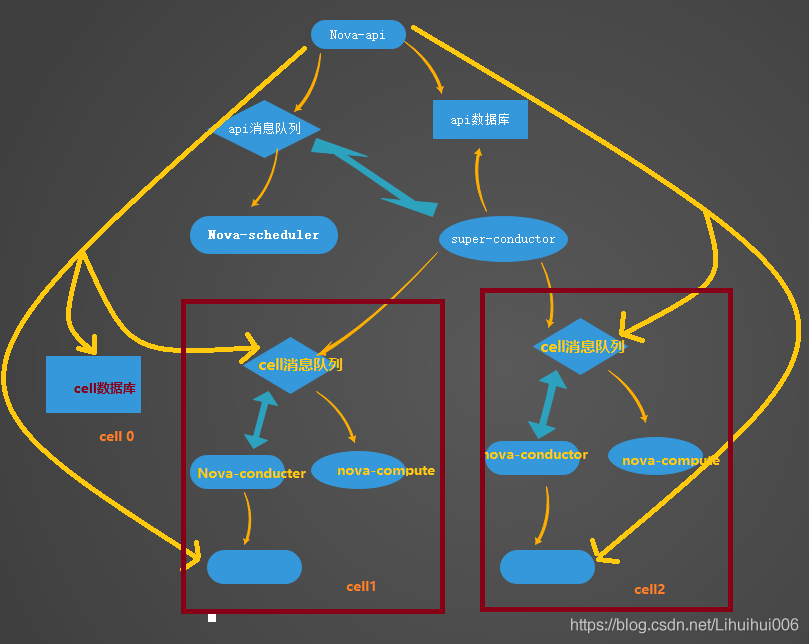
在每個 Cell 中,都有自己獨立使用的資料庫、訊息佇列和 Nova Conductor 服務,當前 Cell 中的所有計算節點,全部將資料發送到當前 Cell 中的訊息佇列,由 Nova Conductor 服務獲取后,保存至當前 Cell 的 Nova 資料庫中,整個程序都不會涉及到 API Cell 中的訊息佇列,因此通過對計算節點進行 Cell 劃分,可以有效降低 API Cell 中訊息佇列和資料庫的壓力,假如一個 MQ 能支持200個計算節點,則在劃分 Cell 以后,每個 Cell 都可以支持200個計算節點,有 N 個 Cell 就可以支持 N X 200 個計算節點,因此可以極大提升單個 OpenStack 的集群管理規模,
3 , Cell v2實作的原理
在大致了解了 Cell V2 架構的基本組成后,接下來介紹一下在 Nova 組件中,究竟是如何實作 Cell 劃分的,多 Cell 的實作涉及 nova_api 資料庫中的3個表,分別是 cell_mappings, host_mappings, instance_mappings 表,這3個表之間的關系如下圖所示:
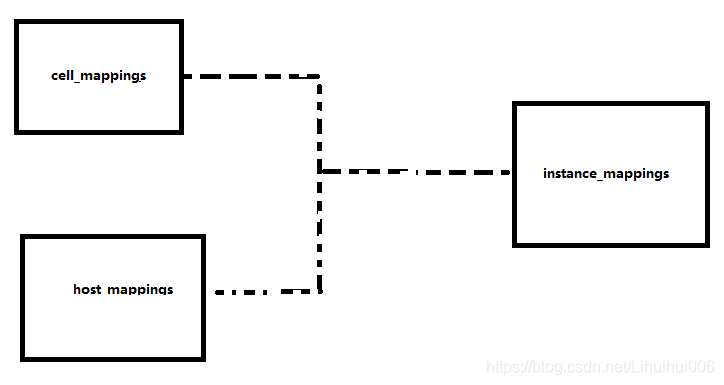
cell_mappings 表記錄了每個 Cell 的名字和其訊息佇列連接地址與資料庫連接地址,通過該表中記錄的資訊,API Cell 中的 Nova API 服務和 Nova Conductor 服務就知道該如何連接到 Cell 中的訊息佇列和資料庫了,并進一步將訊息發送到 Cell 中的訊息佇列,或者直接訪問 Cell 中的 Nova 資料庫,
在 host_mappings 表記錄了計算節點和 Cell 之間的對應關系,而instance_mappings 表則記錄了 instance 和 Cell 之間的對應關系,通過這兩個表的映射關系,API Cell 中的服務就可以輕易知道計算節點或者虛擬機所處的 Cell,并通過 cell_mappings 資料表中提供的鏈接對其進行操作,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/243546.html
標籤:其他
上一篇:Python爬蟲學習(一)