計算機網路-網路層筆記
- 網路層只提供best effort 的服務,不能保證帶寬,時延等等
- 一些network layer包含的協議
-
routing protocols
- path selection
- RIP, OSPF, BGP
-
IP protocol
-
ICMP protocol
-
兩個network layer的主要作用:
1、forwarding(data plane)
move packets from router’s input to router’s output (在router的每內部,決定datagram從哪個output port出)
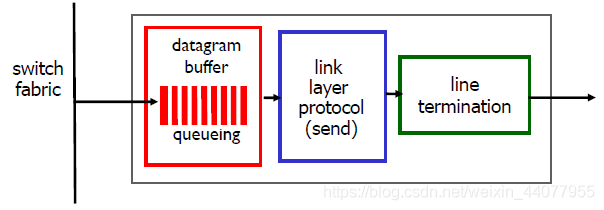
下面展示的是router input port的基本架構:
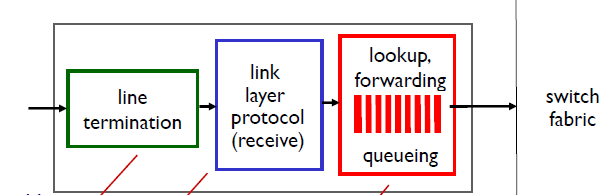
- 這里的switch fabric是交換結構的意思,可以看做是路由器中的網路
紅色框框住的部分,路由器有了header field通過轉發表(forwarding table)查找輸出埠,這部分有兩種可能的方法:1:destination-based forwarding, 2: generalized forwarding
destination-based forwarding的基本思想
假設我們有如下的forwarding table:

我們目的地中的前綴的前n位和表中的前綴進行匹配,從而選擇鏈路埠,但是我們會發現可能目的地與多個前綴相匹配,這時候就需要用到最長前綴匹配規則(longest prefix matching rule),即在該表中尋找最長的匹配項,并向與最長前綴匹配相關聯的鏈路介面轉發分組
Swtiching fabric
大致分為三種:
1.memory 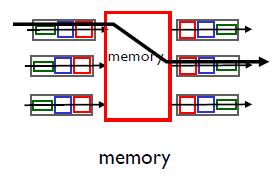
一個分組到達一個輸入埠時,該埠會先通過中斷方式向路由選擇處理器發出信號,于是,該分組從輸入埠處被復制到處理器記憶體中,路由選擇處理器則從其首部中提取目的地址,在轉發表中找出適當的輸出埠,并將該分組復制到輸出埠的快取中,(不能同時轉發兩個分組)
2.bus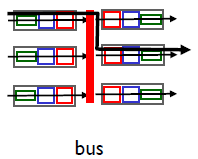
讓輸入埠為分組預先計劃一個交換機內部標簽(首部),指示本地輸出埠,使分組在總線上傳送和傳輸到輸出埠,該分組能由所有輸出埠收到,但只有與該標簽匹配的埠才能保存該分組
3.crossbar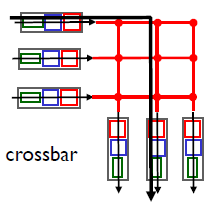
與前面兩種交換方法不同,縱橫式網路能夠并行轉發多個分組,縱橫式交換機是非阻塞的(nonblocking),即只要沒有其他分組當前被轉發到該輸出埠,轉發到輸出埠的分
組將不會被到達輸出埠的分組阻塞,
router output port 的結構和input port 的結構類似
對于包的scheduling我們有以下的幾種方式
1.FIFO(先進先出)
如果佇列排滿了怎么辦呢?
- tail drop
- priority
- random
2.priority scheduling
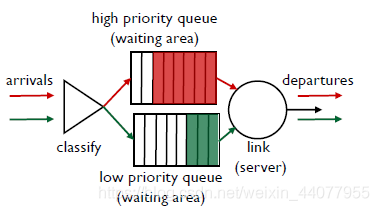
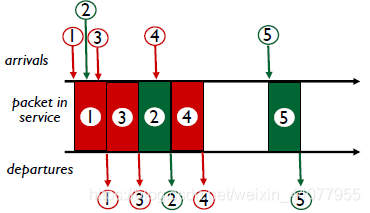
一這幅圖中的紅綠packets為例:
紅色的包的優先級比綠色的高,① ② ③首先進入服務區(在③進入的時候①還沒有被傳出完畢),在①離開時服務區中還剩②和③,③的優先級高,所以三先離開,在③完成了離開之后服務區中只剩下②,所以②開始離開,再②離開到一半的時候④進來了,但是由于②已經處于正在離開的狀態,所以即使④的優先級比②高,還是需要等待②離開之后才能繼續離開,
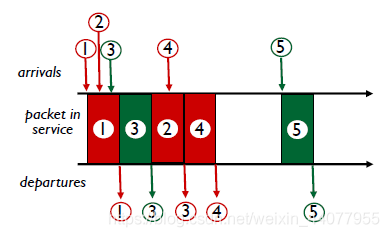
3.Round Robin(RR) scheduling
紅綠輪著來,除非兩個中哪個沒了
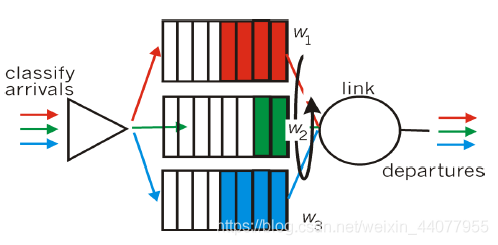
4.Weighted Fair forwarding
按比例側重的控制包的離開:
2、routing(control plane)
determine route taken by packets from source todestination(在不同的router之間)
我們使用routing protocol的目標是選出來一條好的路徑,那么什么樣的路徑算是好的呢,對于好可以有不同的定義,常見的為least “cost”, “fastest”, "least congested"
traditional routing algorithm
- per-router control
SDN
- logically centralized control
下面介紹的是兩種常見的routing的演算法
①:link state algorithm(知道global information)
Dijkstra’s algorithm:
首先是一些基本的定義
- c(x,y): link cost from node x to y; = ∞ if not direct neighbors
- D(v): current value of cost of path from source to dest. v
- p(v): predecessor node along path from source to v
- N’: set of nodes whose least cost path definitively known
待補
②:distance ve*ctor algorithm(知道decentralized information)
待補
intra-AS routing in the internet: OSPF
在實際中我們會把眾多的router,按組分到不同的 autonomous system(AS)(a.k.a. “domains”)中去,在一個AS中有兩類的router,這兩種router的區別在于和其它的AS有沒有連接,
- gateway router
- interrior router
在同一個的AS之間我們會使用intra-AS routing在不同AS里面我們會使用inter-AS routing.
- Intra-AS routing (Interior gateway protocol, IGP)
- RIP: Routing Information Protocol(基于distance vector),over udp
- OSPF: Open Sortest Path First(基于link state),是over ip的
- IS-IS: 很像OSPF
- IGRP
- Inter-AS routing (boarder gateway protocol, BGP),over TCP
同一個AS里面的router會使用相同的intra-domain protocol而不同一個AS里面可以使用不同的intra-domain protocol,在一個AS內部 gateway router的功能包括了兩種routing,
OSPF的優點:
- security
- multiple same-cost paths
- intergrated uni- and multi-cast support
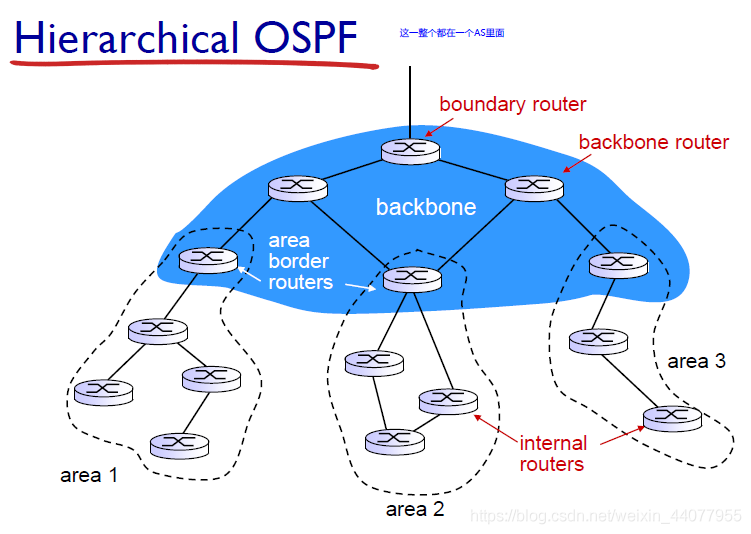
- hierarchical OSPF in large domains
在一個hierarchical的OSPF示例:
BGP
BGP分為eBGP和iBGP,eBGP是在不同的AS之間運行的,iBGP是在相同的BGP之間運行的,從一個給定的路由器到一個目的子網可能有多條路徑,這時候就需要選擇最好的路由,首先我們需要知道一些有關于BGP的術語,
Prefix (destination) + attributes = “route”,在屬性中比較重要的就是AS-PATH和NEXT HOP,AS -PATH是已經走過的AS的集合(不包括開始的AS)而NEXT HOP是AS?PATH起始的路由器介面的IP地址,
hot potato routing:
對于起始路由器而言,它并不關心inter-domain cost,他只關心怎么規劃路徑才能使得intra-domain cost最小,
協議對比:
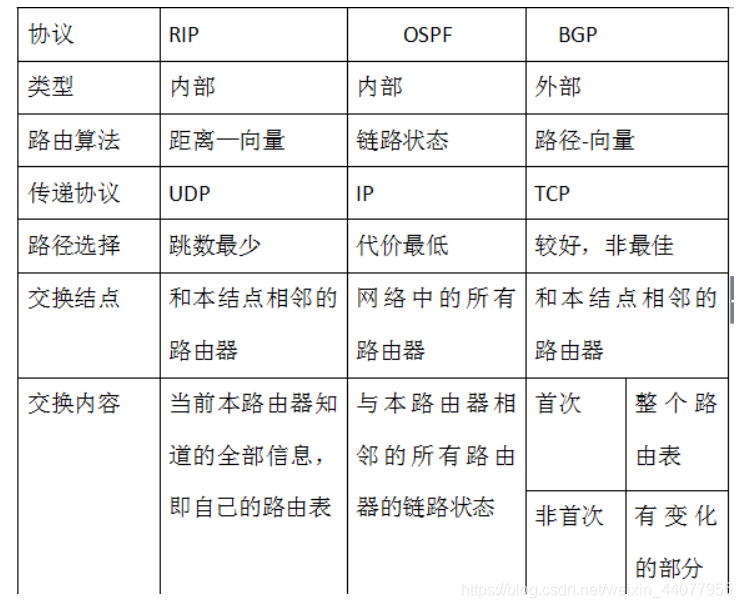
圖片來源:https://blog.csdn.net/Jungle_hello/article/details/51438886?utm_source=copy
ICMP:internet control message protocol
主機和路由器用ICMP協議來交換網路層的資訊:
- error reporting
- echo request
ICMP通常被認為是IP的一部分,但從體系結構上講它位于IP之上,因為ICMP報文是承載在IP分組中的,
traceroute(書中解釋):
Traceroute是用ICMP報文來實作的,為了判斷源和目的地之間所有路由器的名字和地址,源主機中的Traceroute向目的地主機發送一系列普通的IP資料報,這些資料報的每個攜帶了一個具有不可達UDP埠號的UDP報文段,第一個資料報的TTL為1,第二個的TTL為2,第三個的TTL為3,依次類推,該源主機也為每個資料報啟動定時器,當第□個資料報到達第〃臺路由器時,第孔臺路由器觀察到這個資料報的TTL正好過期,根據IP協議規則,路由器丟棄該資料報并發送一個ICMP告警報文給源主機(型別11編碼0),該告警報文包含了路由器的名字和它的IP地址,當該ICMP報文回傳源主機時,源主機從定時器得到往返時延,從ICMP報文中得到第n臺路由器的名字與IP地址,
SNMP:simple network management protocol
在了解SNMP**(一個應用層協議)**之前我們首先需要知道網路管理的基本框架,網路管理的基本組件如下所示
- managing server(管理服務器)
- managed device(被管設備)
- management information base(MIB)(管理資訊庫,這些資訊的值可供管理服務器所用)
- network management agent(網路管理代理)
- network management protocol
IP: Internet Protocol
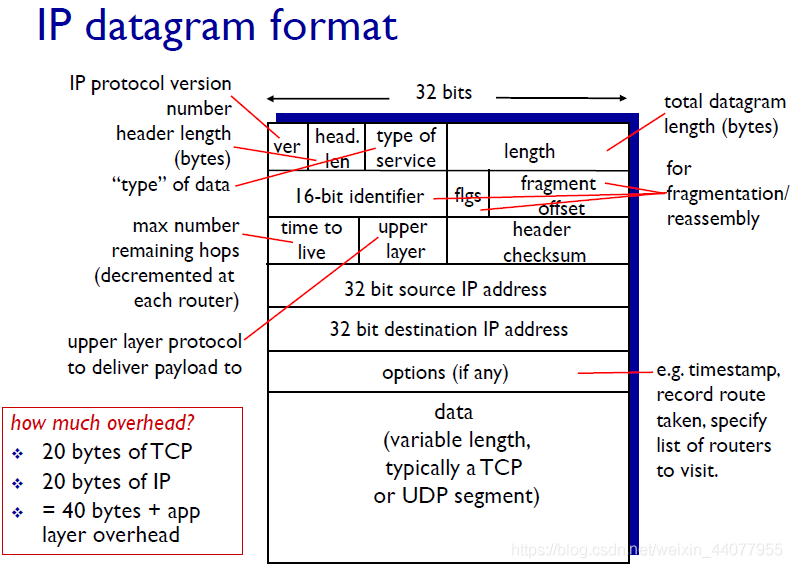

上面是一個ip協議的基本格式,有利于我們對ip協議有一些初步的認識,
IP fragmentation
MTU: max.transfer size
在實際的網路連接中,不同鏈路層協議會有不同的MTU,有時一個包的長度太長,所以需要對包進行fragmentation(分片)的操作,為堅持網路內核保持簡單的原則,IPv4的設計者決定將資料報的重新組裝作業放到端系統中,而不是放到網路路由器中,
下面是一個分片的例子:
假設MTU為1500 bytes,現在要將一個4000bytes長度的包進行分片

分片的結果如下:

首先我們要關注的是分片后包的長度,1500+1500+1040=4040,通過對比我們可以發現,分片后包的總長度比分片之前的包的長度要多出了40,這是由于之前ip只有一個head field,現在分為了三個包之后有了三個ip field,這樣使得多出了兩個head field,而一個ip的head field的長度為20 bytes,所以長度增加了20,然后我們要關注的是offset,對于分片后的第二個包,offset的值為1480/8,這是根據第一個包的data的長度除以8得來的,
IP address
IP address總共有32-bit. 例:192.168.10.1 這個ip地址中以點為劃分,將32位分成了4個八位
interface: connection between host/router and physical link
IP address assocciated with each interface
subnet!!!
對于一個ip地址,分為subnet part和host part,高位為subnet part低位為host part,subnet part 相同的interface屬于同一個子網,屬于同一個子網的interface能夠不經過路由器相互通信,那么如何界定哪些位屬于子網呢?例:192.168.10.1 /24, 在這個例子中,/24表示的是最左邊的24位元定義了子網地址,/24有時也被稱作子網掩碼,和另一種表達形式:255.255.255.0是等效的,
兩種子網掩碼形式的轉換(例):
255.255.255.0 → 11111111.11111111.11111111.00000000 對應/24
255.255.0.0 → 11111111.11111111.0.0 對應/16
255.255.128.0 → 11111111.11111111.10000000.00000000 對應/17
255.255.254.0 → 11111111.11111111.11111110.00000000 對應/23
子網聚合(aggregation)
例:
1. 172.16.129.0/24
2. 172.16.130.0/24
3. 172.16.132.0/24
4. 172.16.133.0/24
為了做子網聚合,我們首先將上述的ip地址后面不同的位元寫成二進制位元的形式
- 172.16.10000001.0
- 172.16.10000010.0
- 172.16.10000100.0
- 172.16.10000101.0
通過對比我們能夠發現高亮標出來的地方的值是相同的,所以我們設定的新的子網id就是前面的21位,新的子網的ip表示為172.16.128.0/21
CIDR: Classless InterDomain Routing(無類別域間路由選擇)
因特網的地址分配策略被稱為無類別域間路由選擇(Classless Inlerdomain Routing,CIDR),一個組織通常被分配一塊連續的地址,即具有相同前綴的一段地址,
形式為a.b.c.d/x的地址的x最高位元構成了 IP地址的網路部分,并且經常被稱為該地址的前綴(prefix),
DHCP: Dynamic Host Configuration Protocol (動態主機配置協議)
又被稱為plug-and-play protocol,是基于UDP的協議
goal:能夠使得主機能夠動態獲取ip地址
- reuse of address
host獲取DHCP 的簡單步驟:
- host broadcast DHCP discover
- DHCP server respond with DHCP offer
- host request IP address DHCP request
- DHCP server send address DHCP ack
DHCP ack中包含的資訊可以不止ip address,還可以包括

NAT: network address translation
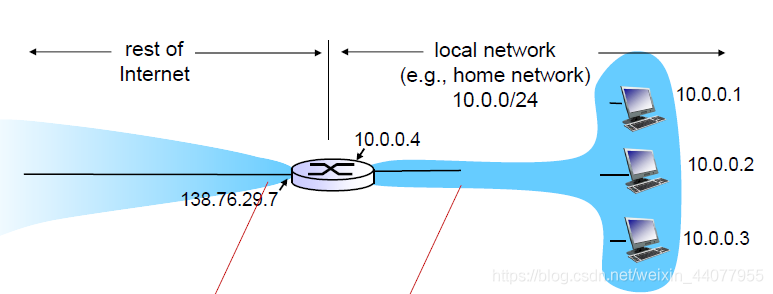
整個local network的資訊都通過138.76.29.7這一個ip地址出去,
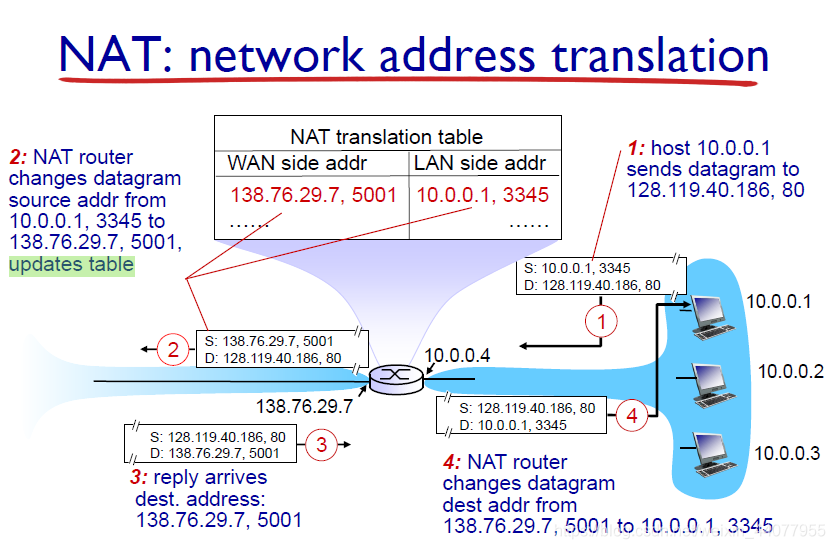
接下來的這幅圖,完美的解釋了一個使用了NAT的實體
IPV6
datagram format:
-
fixed-length 40 byte header
-
no fragmentation allowed
-
no checksum
transition from IPV4 to IPV6:
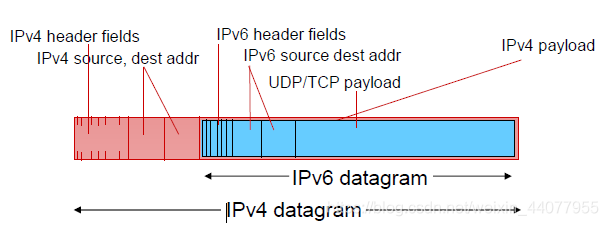
即在IPV6的外面套上IPV4的header和source, dest addr
Tunneling:
假如在一些路線中,不僅僅有IPV6的路由器,還有IPV4的路由器,我們需要用上面所講述的轉換的方法,做一個tunnelling的操作
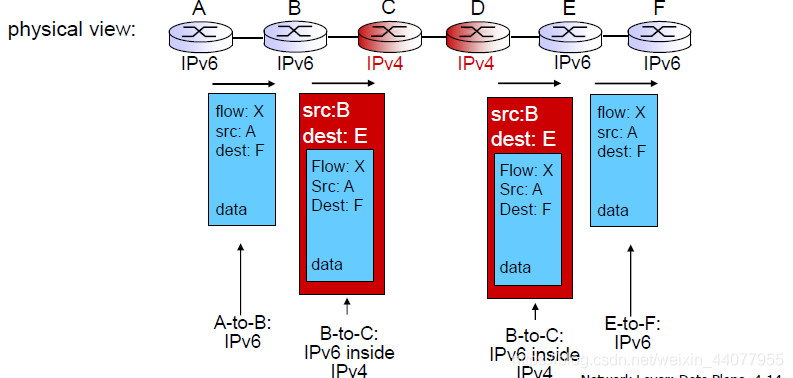
這里面比較需要注意的是src和dest在tunneling時候的變換,可以看到,在做tunneling的時候,src變成了連接第一個IPV4路由器的IPV6路由器的ip地址,而dest變成了連接最后一個IPV4路由器的IPV6路由器的地址,
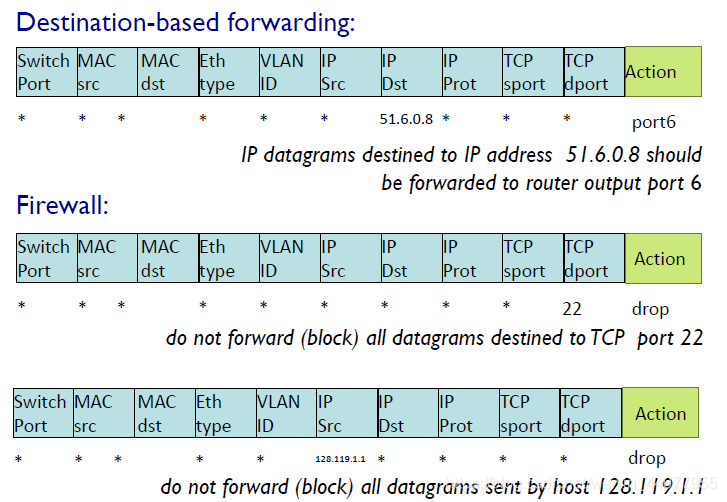
Generalized Forwarding and SDN
通用的“匹配加動作”范式,其中能夠對協議堆疊的多個首部欄位進行“匹配”,這些首部欄位是與不同層次的不同協議相關聯的
flow: defined by header fields
generalized forwarding: simple packet-handling rules
- pattern: match values in packet header fields
- actions:
drop,forward,modify,matched packet or send matched packet to controller - priority
- counters
下面是幾個flow table的示例:


- 轉載請注明出處:
https://blog.csdn.net/weixin_44077955/article/details/112004182
- 文章難免有疏漏錯誤之處,歡迎私信博主及時更正,大家共同進步😜,
Reference:
①:計算機網路-自頂向下方法
②:http://gaia.cs.umass.edu/kurose_ross/ppt.htm
③:https://blog.csdn.net/Jungle_hello/article/details/51438886?utm_source=copy
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/243574.html
標籤:其他
上一篇:Linux云計算虛擬化-使用rancher搭建k8s集群并發布電商網站
下一篇:C語言編程>第十周 ⑥ 請撰寫函式fun,其功能是計算并輸出下列多項式的值: Fn =1+1/1!+1/2!+1/3!+1/4!+…+1/m!