微服務架構相比單體架構,服務的呼叫從同一臺機器內部的本地呼叫變成了不同機器之間的遠程方法呼叫,但是這個程序也引入了兩個不確定的因素:
- 呼叫的執行是在服務提供者一端,即使服務消費者本身是正常的,服務提供者也可能由于諸如CPU、網路I/O、磁盤、記憶體、網卡等硬體原因導致呼叫失敗,還有可能由于本身程式執行問題比如GC暫停導致呼叫失敗
- 呼叫發生在兩臺機器之間,所以要經過網路傳輸,而網路的復雜性是不可控的,網路丟包、延遲以及隨時可能發生的瞬間抖動都有可能造成呼叫失敗,
所以要針對服務呼叫失敗進行特殊處理,
超時
被微服務架構后,一次用戶呼叫可能會被拆分成多系統間的服務呼叫,任何一次服務呼叫如果發生問題都可能會導致最后用戶呼叫失敗,而且在微服務架構下,一個系統的問題會影響所有呼叫這個系統所提供服務的服務消費者,會引起服務雪崩,
所以針對服務呼叫都要設定一個超時時間,以避免依賴的服務遲遲沒有回傳呼叫結果,把服務消費者拖死,
超時時間的設定不是越短越好:
- 太短可能會導致有些服務呼叫還沒有來得及執行完就被丟棄
- 太長有可能導致服務消費者被拖垮
合適的超時時間需要根據正常情況下,服務提供者的服務水平來決定,即按照服務提供者線上真實的服務水平,取P999或者P9999的值,也就是以99.9%或者99.99%的呼叫都在多少毫秒內回傳為準,
重試
雖然設定超時時間可及時止損,但是服務呼叫結果畢竟失敗,而大部分情況下,呼叫失敗都是因為偶發的網路問題或者個別服務提供者節點有問題,若能換個節點再次訪問說不定就成功,
假如一次服務呼叫失敗的概率為1%,那么連續兩次服務呼叫失敗的概率就是0.01%,失敗率降低到原來的1%,
所以,在實際服務呼叫時,經常還要設定一個服務呼叫超時后的重試次數,
假如某個服務呼叫的超時時間設定為100ms,重試次數設定為1,那么當服務呼叫超過100ms后,服務消費者就會立即發起第二次服務呼叫,而不會再等待第一次呼叫回傳的結果了,
雙發
假如一次呼叫不成功的概率為1%,那么連續兩次呼叫都不成功的概率就是0.01%,根據這個推論,一個簡單的提高服務呼叫成功率的辦法就是每次服務消費者要發起服務呼叫的時候,都同時發起兩次服務呼叫,一方面可以提高呼叫的成功率,另一方面兩次服務呼叫哪個先回傳就采用哪次的回傳結果,平均回應時間也要比一次呼叫更快,這就是雙發,
但是這樣的話,一次呼叫會給后端服務兩倍的壓力,所要消耗的資源也是加倍的,所以一般情況下,這種“魯莽”雙發不可取,
更為聰明的雙發,即“備份請求”(Backup Requests)
服務消費者發起一次服務呼叫后,在給定的時間內如果沒有回傳請求結果,那么服務消費者就立刻發起另一次服務呼叫,
注意該設定時間通常要比超時時間短得多,比如超時時間取P999,那么備份請求時間取的可能是P99或P90,因為若在P99或者P90時間內呼叫還沒有回傳結果,那么大概率可以認為這次請求屬于慢請求,再次發起呼叫理論上回傳要更快,
在實際線上服務運行時,P999由于長尾請求時間較長的緣故,可能要遠遠大于P99和P90,
比如一個服務的P999是1s,而P99只有200ms、P90只有50ms,這樣的話,如果備份請求時間取的是P90,那么第二次請求等待的時間只有50ms,不過這里需要注意的是,備份請求要設定一個最大重試比例,以避免在服務端出現問題的時,大部分請求回應時間都會超過P90,導致請求量幾乎翻倍,給服務提供者造成更大的壓力,
經驗是這個最大重試比例可設定成15%,一方面能盡量體現備份請求的優勢,另一方面不會給服務提供者額外增加太大的壓力,
熔斷
前面講得一些手段在服務提供者偶發例外時會很有效,但若服務提供者出現故障,短時間內無法恢復時,無論是超時重試還是雙發不但不能提高服務呼叫的成功率,反而會因為重試給服務提供者帶來更大的壓力,從而加劇故障,
就需要服務消費者能夠探測到服務提供者發生故障,并短時間內停止請求,給服務提供者故障恢復的時間,待服務提供者恢復后,再繼續請求,這就好比一條電路,電流負載過高的話,保險絲就會熔斷,以防止火災的發生,所以這種手段就被叫作“熔斷”,
熔斷原理
熔斷就是把客戶端的每一次服務呼叫用斷路器封裝起來,通過斷路器來監控每一次服務呼叫,如果某一段時間內,服務呼叫失敗的次數達到一定閾值,那么斷路器就會被觸發,后續的服務呼叫就直接回傳,也就不會再向服務提供者發起請求了,
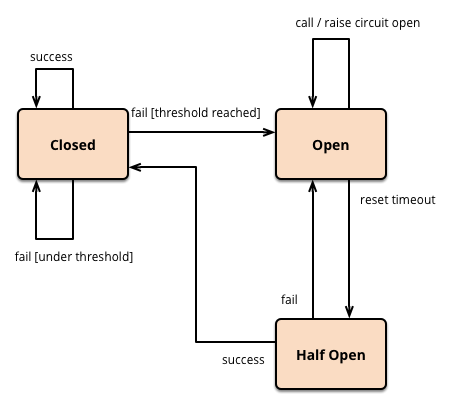
熔斷之后,一旦服務提供者恢復之后,服務呼叫如何恢復呢?這就牽扯到熔斷中斷路器的幾種狀態,
- Closed狀態:正常情況下,斷路器是處于關閉狀態的,偶發的呼叫失敗也不影響,
- Open狀態:當服務呼叫失敗次數達到一定閾值時,斷路器就會處于開啟狀態,后續的服務呼叫就直接回傳,不會向服務提供者發起請求,
- Half Open狀態:當斷路器開啟后,每隔一段時間,會進入半打開狀態,這時候會向服務提供者發起探測呼叫,以確定服務提供者是否恢復正常,如果呼叫成功了,斷路器就關閉;如果沒有成功,斷路器就繼續保持開啟狀態,并等待下一個周期重新進入半打開狀態,
關于斷路器的實作,最經典也是使用最廣泛的莫過于Netflix開源的Hystrix了,下面我來給你介紹下Hystrix是如何實作斷路器的,
Hystrix的斷路器也包含三種狀態:關閉、打開、半打開,Hystrix會把每一次服務呼叫都用HystrixCommand封裝起來,它會實時記錄每一次服務呼叫的狀態,包括成功、失敗、超時還是被執行緒拒絕,當一段時間內服務呼叫的失敗率高于設定的閾值后,Hystrix的斷路器就會進入進入打開狀態,新的服務呼叫就會直接回傳,不會向服務提供者發起呼叫,再等待設定的時間間隔后,Hystrix的斷路器又會進入半打開狀態,新的服務呼叫又可以重新發給服務提供者了;如果一段時間內服務呼叫的失敗率依然高于設定的閾值的話,斷路器會重新進入打開狀態,否則的話,斷路器會被重置為關閉狀態,
其中決定斷路器是否打開的失敗率閾值可以通過下面這個引數來設定:
HystrixCommandProperties.circuitBreakerErrorThresholdPercentage()
而決定斷路器何時進入半打開的狀態的時間間隔可以通過下面這個引數來設定:
HystrixCommandProperties.circuitBreakerSleepWindowInMilliseconds()
- 斷路器實作的關鍵就在于如何計算一段時間內服務呼叫的失敗率,那么Hystrix是如何做的呢?
滑動視窗演算法
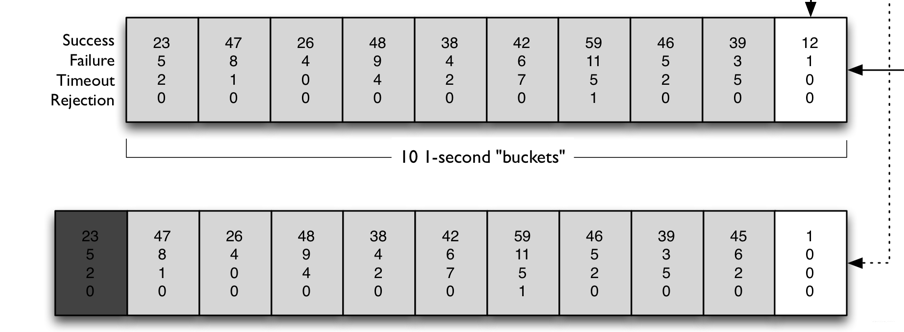
Hystrix通過滑動視窗來對資料進行統計,默認情況下,滑動視窗包含10個桶,每個桶時間寬度為1秒,每個桶內記錄了這1秒內所有服務呼叫中成功的、失敗的、超時的以及被執行緒拒絕的次數,當新的1秒到來時,滑動視窗就會往前滑動,丟棄掉最舊的1個桶,把最新1個桶包含進來,
任意時刻,Hystrix都會取滑動視窗內所有服務呼叫的失敗率作為斷路器開關狀態的判斷依據,這10個桶內記錄的所有失敗的、超時的、被執行緒拒絕的呼叫次數之和除以總的呼叫次數就是滑動視窗內所有服務的呼叫的失敗率,
總結
微服務架構下服務呼叫失敗的幾種常見手段:超時、重試、雙發以及熔斷,實際使用時,具體選擇哪種手段要根據具體業務情況來決定,
大部分的服務呼叫都需要設定超時時間以及重試次數,當然對于非冪等的也就是同一個服務呼叫重復多次回傳結果不一樣的來說,不可以重試,比如大部分上行請求都是非冪等的,至于雙發,它是在重試基礎上進行一定程度的優化,減少了超時等待的時間,對于長尾請求的場景十分有效,采用雙發策略后,服務呼叫的P999能大幅減少,經過我的實踐證明是提高服務呼叫成功率非常有效的手段,而熔斷能很好地解決依賴服務故障引起的連鎖反應,對于線上存在大規模服務呼叫的情況是必不可少的,尤其是對非關鍵路徑的呼叫,也就是說即使呼叫失敗也對最終結果影響不大的情況下,更加應該引入熔斷,
參考
- https://martinfowler.com/bliki/CircuitBreaker.html
- https://github.com/Netflix/Hystrix/wiki/How-To-Use
 CSDN認證博客專家
CSDN博客專家
慕課網認證作者
騰訊云+最佳作者
CSDN認證博客專家
CSDN博客專家
慕課網認證作者
騰訊云+最佳作者
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/243956.html
標籤:AI
上一篇:手把手教學:Nginx的安裝
下一篇:一文詳解 Nacos 高可用特性