DolphinDB提供了功能強大的記憶體計算引擎,內置時間序列函式,分布式計算以及流資料處理引擎,在眾多場景下均可高效的計算K線,本教程將介紹DolphinDB如何通過批量處理和流式處理計算K線,
- 歷史資料批量計算K線
其中可以指定K線視窗的起始時間;一天中可以存在多個交易時段,包括隔夜時段;K線視窗可重疊;使用交易量作為劃分K線視窗的維度,需要讀取的資料量特別大并且需要將結果寫入資料庫時,可使用DolphinDB內置的Map-Reduce函式并行計算,
- 流式計算K線
使用API實時接收市場資料,并使用DolphinDB內置的流資料時序計算引擎(TimeSeriesAggregator)進行實時計算得到K線資料,
1. 歷史資料K線計算
使用歷史資料計算K線,可使用DolphinDB的內置函式bar,dailyAlignedBar,或wj,
1.1 不指定K線視窗的起始時刻,根據資料自動生成K線結果
bar(X,Y)回傳X減去X除以Y的余數,一般用于將資料分組,
date = 09:32m 09:33m 09:45m 09:49m 09:56m 09:56m;
bar(date, 5);回傳以下結果:
[09:30m,09:30m,09:45m,09:45m,09:55m,09:55m]例子1:使用以下資料模擬美國股票市場:
n = 1000000
date = take(2019.11.07 2019.11.08, n)
time = (09:30:00.000 + rand(int(6.5*60*60*1000), n)).sort!()
timestamp = concatDateTime(date, time)
price = 100+cumsum(rand(0.02, n)-0.01)
volume = rand(1000, n)
symbol = rand(`AAPL`FB`AMZN`MSFT, n)
trade = table(symbol, date, time, timestamp, price, volume).sortBy!(`symbol`timestamp)
undef(`date`time`timestamp`price`volume`symbol)計算5分鐘K線:
barMinutes = 5
OHLC = select first(price) as open, max(price) as high, min(price) as low, last(price) as close, sum(volume) as volume from trade group by symbol, date, bar(time, barMinutes*60*1000) as barStart請注意,以上資料中,time列的精度為毫秒,若time列精度不是毫秒,則應當將 barMinutes*60*1000 中的數字做相應調整,
1.2 需要指定K線視窗的起始時刻
需要指定K線視窗的起始時刻,可使用dailyAlignedBar函式,該函式可處理每日多個交易時段,亦可處理隔夜時段,
請注意,使用dailyAlignedBar函式時,時間列必須含有日期資訊,包括 DATETIME, TIMESTAMP 或 NANOTIMESTAMP 這三種型別的資料,指定每個交易時段視窗起始時刻的引數 timeOffset 必須使用相應的去除日期資訊之后的 SECOND,TIME 或 NANOTIME 型別的資料,
例子2(每日一個交易時段):計算美國股票市場7分鐘K線,資料沿用例子1中的trade表,
barMinutes = 7
OHLC = select first(price) as open, max(price) as high, min(price) as low, last(price) as close, sum(volume) as volume from trade group by symbol, dailyAlignedBar(timestamp, 09:30:00.000, barMinutes*60*1000) as barStart例子3(每日兩個交易時段):中國股票市場每日有兩個交易時段,上午時段為9:30至11:30,下午時段為13:00至15:00,
使用以下資料模擬:
n = 1000000
date = take(2019.11.07 2019.11.08, n)
time = (09:30:00.000 + rand(2*60*60*1000, n/2)).sort!() join (13:00:00.000 + rand(2*60*60*1000, n/2)).sort!()
timestamp = concatDateTime(date, time)
price = 100+cumsum(rand(0.02, n)-0.01)
volume = rand(1000, n)
symbol = rand(`600519`000001`600000`601766, n)
trade = table(symbol, timestamp, price, volume).sortBy!(`symbol`timestamp)
undef(`date`time`timestamp`price`volume`symbol)計算7分鐘K線:
barMinutes = 7
sessionsStart=09:30:00.000 13:00:00.000
OHLC = select first(price) as open, max(price) as high, min(price) as low, last(price) as close, sum(volume) as volume from trade group by symbol, dailyAlignedBar(timestamp, sessionsStart, barMinutes*60*1000) as barStart例子4(每日兩個交易時段,包含隔夜時段):某些期貨每日有多個交易時段,且包括隔夜時段,本例中,第一個交易時段為8:45到下午13:45,另一個時段為隔夜時段,從下午15:00到第二天05:00,
使用以下資料模擬:
daySession = 08:45:00.000 : 13:45:00.000
nightSession = 15:00:00.000 : 05:00:00.000
n = 1000000
timestamp = rand(concatDateTime(2019.11.06, daySession[0]) .. concatDateTime(2019.11.08, nightSession[1]), n).sort!()
price = 100+cumsum(rand(0.02, n)-0.01)
volume = rand(1000, n)
symbol = rand(`A120001`A120002`A120003`A120004, n)
trade = select * from table(symbol, timestamp, price, volume) where timestamp.time() between daySession or timestamp.time()>=nightSession[0] or timestamp.time()<nightSession[1] order by symbol, timestamp
undef(`timestamp`price`volume`symbol)計算7分鐘K線:
barMinutes = 7
sessionsStart = [daySession[0], nightSession[0]]
OHLC = select first(price) as open, max(price) as high, min(price) as low, last(price) as close, sum(volume) as volume from trade group by symbol, dailyAlignedBar(timestamp, sessionsStart, barMinutes*60*1000) as barStart1.3 重疊K線視窗:使用wj函式
以上例子中,K線視窗均不重疊,若要計算重疊K線視窗,可以使用wj函式,使用wj函式,可對左表中的時間列,指定相對時間范圍,在右表中進行計算,
例子5 (每日兩個交易時段,重疊的K線視窗):模擬中國股票市場資料,每5分鐘計算30分鐘K線,
n = 1000000
sampleDate = 2019.11.07
symbols = `600519`000001`600000`601766
trade = table(take(sampleDate, n) as date,
(09:30:00.000 + rand(7200000, n/2)).sort!() join (13:00:00.000 + rand(7200000, n/2)).sort!() as time,
rand(symbols, n) as symbol,
100+cumsum(rand(0.02, n)-0.01) as price,
rand(1000, n) as volume)首先根據時間來生成視窗,并且用cross join來生成股票和交易視窗的組合,
barWindows = table(symbols as symbol).cj(table((09:30:00.000 + 0..23 * 300000).join(13:00:00.000 + 0..23 * 300000) as time))然后使用wj函式計算重疊視窗的K線資料:
OHLC = wj(barWindows, trade, 0:(30*60*1000),
<[first(price) as open, max(price) as high, min(price) as low, last(price) as close, sum(volume) as volume]>, `symbol`time)1.4 使用交易量劃分K線視窗
上面的例子我們均使用時間作為劃分K線視窗的維度,在實踐中,也可以使用其他維度作為劃分K線視窗的依據,譬如用累計的交易量來計算K線,
例子6 (每日兩個交易時段,使用累計的交易量計算K線):模擬中國股票市場資料,交易量每增加10000計算K線,
n = 1000000
sampleDate = 2019.11.07
symbols = `600519`000001`600000`601766
trade = table(take(sampleDate, n) as date,
(09:30:00.000 + rand(7200000, n/2)).sort!() join (13:00:00.000 + rand(7200000, n/2)).sort!() as time,
rand(symbols, n) as symbol,
100+cumsum(rand(0.02, n)-0.01) as price,
rand(1000, n) as volume)
volThreshold = 10000
select first(time) as barStart, first(price) as open, max(price) as high, min(price) as low, last(price) as close
from (select symbol, price, cumsum(volume) as cumvol from trade context by symbol)
group by symbol, bar(cumvol, volThreshold) as volBar代碼采用了嵌套查詢的方法,子查詢為每個股票生成累計的交易量cumvol,然后在主查詢中根據累計的交易量用bar函式生成視窗,
1.5 使用MapReduce函式加速
若需從資料庫中提取較大量級的歷史資料,計算K線,然后存入資料庫,可使用DolphinDB內置的Map-Reduce函式mr進行資料的并行讀取與計算,這種方法可以顯著提高速度,
本例使用美國股票市場精確到納秒的交易資料,原始資料存于"dfs://TAQ"資料庫的"trades"表中,"dfs://TAQ"資料庫采用復合磁區:基于交易日期Date的值磁區與基于股票代碼Symbol的范圍磁區,
(1) 將存于磁盤的原始資料表的元資料載入記憶體:
login(`admin, `123456)
db = database("dfs://TAQ")
trades = db.loadTable("trades")(2) 在磁盤上創建一個空的資料表,以存放計算結果,以下代碼建立一個模板表(model),并根據此模板表的schema在資料庫"dfs://TAQ"中創建一個空的 OHLC 表以存放K線計算結果:
model=select top 1 Symbol, Date, Time.second() as bar, PRICE as open, PRICE as high, PRICE as low, PRICE as close, SIZE as volume from trades where Date=2007.08.01, Symbol=`EBAY
if(existsTable("dfs://TAQ", "OHLC"))
db.dropTable("OHLC")
db.createPartitionedTable(model, `OHLC, `Date`Symbol)(3) 使用mr函式計算K線資料,并將結果寫入 OHLC 表中:
def calcOHLC(inputTable){
tmp=select first(PRICE) as open, max(PRICE) as high, min(PRICE) as low, last(PRICE) as close, sum(SIZE) as volume from inputTable where Time.second() between 09:30:00 : 15:59:59 group by Symbol, Date, 09:30:00+bar(Time.second()-09:30:00, 5*60) as bar
loadTable("dfs://TAQ", `OHLC).append!(tmp)
return tmp.size()
}
ds = sqlDS(<select Symbol, Date, Time, PRICE, SIZE from trades where Date between 2007.08.01 : 2019.08.01>)
mr(ds, calcOHLC, +)在以上代碼中,ds是函式sqlDS生成的一系列資料源,每個資料源代表從一個資料磁區中提取的資料;自定義函式calcOHLC為Map-Reduce演算法中的map函式,對每個資料源計算K線資料,并將結果寫入資料庫,回傳寫入資料庫的K線資料的行數;"+"是Map-Reduce演算法中的reduce函式,將所有map函式的結果,亦即寫入資料庫的K線資料的行數相加,回傳寫入資料庫的K線資料總數,
2. 實時K線計算
DolphinDB database 中計算實時K線的流程如下圖所示:
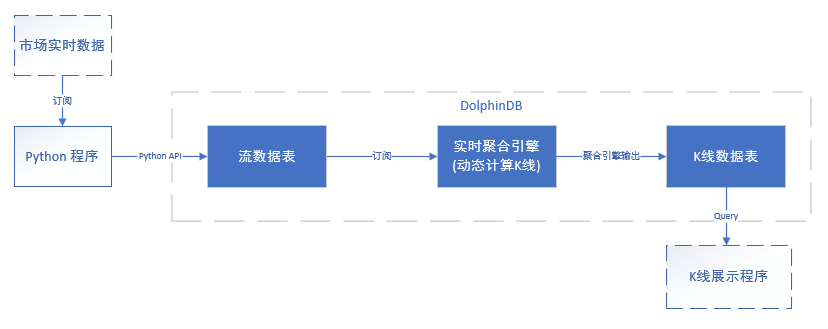
DolphinDB中計算實時K線流程圖
實時資料供應商一般會提供基于Python、Java或其他常用語言的API的資料訂閱服務,本例中使用Python來模擬接收市場資料,通過DolphinDB Python API寫入流資料表中,DolphinDB的流資料時序聚合引擎(TimeSeriesAggregator)可以對實時資料按照指定的頻率與移動視窗計算K線,
本例使用的模擬實時資料源為文本檔案trades.csv,該檔案包含以下4列(一同給出一行樣本資料):
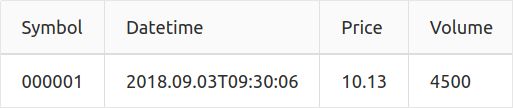
以下三小節介紹實時K線計算的三個步驟:
2.1 使用 Python 接收實時資料,并寫入DolphinDB流資料表
- DolphinDB 中建立流資料表
share streamTable(100:0, `Symbol`Datetime`Price`Volume,[SYMBOL,DATETIME,DOUBLE,INT]) as Trade- Python程式從資料源 trades.csv 檔案中讀取資料寫入DolphinDB,
實時資料中Datetime的資料精度是秒,由于pandas DataFrame中僅能使用DateTime[64]即nanatimestamp型別,所以下列代碼在寫入前有一個資料型別轉換的程序,這個程序也適用于大多數資料需要清洗和轉換的場景,
import dolphindb as ddb
import pandas as pd
import numpy as np
csv_file = "trades.csv"
csv_data = pd.read_csv(csv_file, dtype={'Symbol':str} )
csv_df = pd.DataFrame(csv_data)
s = ddb.session();
s.connect("127.0.0.1",8848,"admin","123456")
#上傳DataFrame到DolphinDB,并對Datetime欄位做型別轉換
s.upload({"tmpData":csv_df})
s.run("data = select Symbol, datetime(Datetime) as Datetime, Price, Volume from tmpData")
s.run("tableInsert(Trade,data)")2.2 實時計算K線
本例中使用時序聚合引擎createTimeSeriesAggregator函式實時計算K線資料,并將計算結果輸出到流資料表OHLC中,
實時計算K線資料,根據應用場景不同,可以分為以下2種情況:
- 僅在每次時間視窗結束時觸發計算
- 時間視窗完全不重合,例如每隔5分鐘計算過去5分鐘的K線資料
- 時間視窗部分重合,例如每隔1分鐘計算過去5分鐘的K線資料
- 在每個時間視窗結束時觸發計算,同時在每個時間視窗內資料也會按照一定頻率更新
例如每隔1分鐘計算過去1分鐘的K線資料,但最近1分鐘的K線不希望等到視窗結束后再計算,希望每隔1秒鐘更新一次
下面針對上述的幾種情況分別介紹如何使用createTimeSeriesAggregator函式實時計算K線資料,請根據實際需要選擇相應場景創建時間序列聚合引擎,
2.2.1 僅在每次時間視窗結束時觸發計算
僅在每次時間視窗結束時觸發計算的情況下,又可以分為時間視窗完全不重合和部分重合兩種場景,這兩種情況可通過設定createTimeSeriesAggregator函式的windowSize引數和step引數以實作,下面具體說明,
首先定義輸出表:
share streamTable(100:0, `datetime`symbol`open`high`low`close`volume,[DATETIME, SYMBOL, DOUBLE,DOUBLE,DOUBLE,DOUBLE,LONG]) as OHLC然后根據使用場景不同,選擇以下任意一種場景創建時間序列聚合引擎,
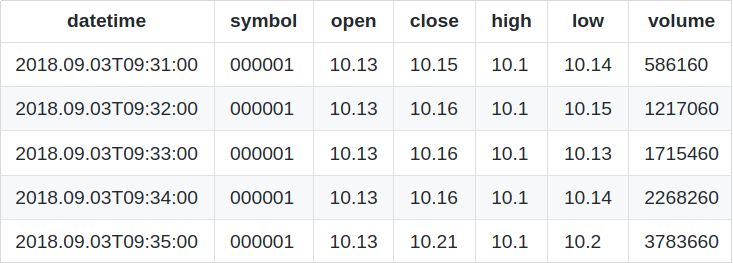
場景一:每隔5分鐘計算一次過去5分鐘的K線資料,使用以下腳本定義時序聚合引擎,其中,windowSize引數取值與step引數取值相等
tsAggrKline = createTimeSeriesAggregator(name="aggr_kline", windowSize=300, step=300, metrics=<[first(Price),max(Price),min(Price),last(Price),sum(volume)]>, dummyTable=Trade, outputTable=OHLC, timeColumn=`Datetime, keyColumn=`Symbol)場景二:每隔1分鐘計算過去5分鐘的K線資料,可以使用以下腳本定義時序聚合引擎,其中,windowSize引數取值是step引數取值的倍數
tsAggrKline = createTimeSeriesAggregator(name="aggr_kline", windowSize=300, step=60, metrics=<[first(Price),max(Price),min(Price),last(Price),sum(volume)]>, dummyTable=Trade, outputTable=OHLC, timeColumn=`Datetime, keyColumn=`Symbol)最后,定義流資料訂閱,若此時流資料表Trade中已經有實時資料寫入,那么實時資料會馬上被訂閱并注入聚合引擎:
subscribeTable(tableName="Trade", actionName="act_tsaggr", offset=0, handler=append!{tsAggrKline}, msgAsTable=true)場景一的輸出表前5行資料:
2.2.2 在每個時間視窗結束觸發計算,同時按照一定頻率更新計算結果
以視窗時間1分鐘計算vwap價格為例,10:00更新了聚合結果以后,那么下一次更新至少要等到10:01,按照計算規則,這一分鐘內即使發生了很多交易,也不會觸發任何計算,這在很多金融交易場景中是無法接受的,希望以更高的頻率更新資訊,為此引入了時序聚合引擎的updateTime引數,
updateTime引數表示計算的時間間隔,如果沒有指定updateTime,只有在每個時間視窗結束時,時間序列聚合引擎才會觸發一次計算,但如果指定了updateTime,在以下3種情況下都會觸發計算:
- 在每個時間視窗結束時,時間序列聚合引擎會觸發一次計算
- 每過updateTime個時間單位,時間序列聚合引擎都會觸發一次計算
- 如果資料進入后超過2*updateTime個時間單位(如果2*updateTime不足2秒,則設定為2秒),當前視窗中仍有未計算的資料,時間序列聚合引擎會觸發一次計算
這樣就能保證時序聚合引擎能在每個時間視窗結束觸發計算,同時在每個時間視窗內部也會按照一定頻率觸發計算,
需要說明的是,時序聚合引擎要求在使用updateTime引數時,必須使用keyedTable作為輸出表,具體原因如下:
- 若將普通的table或streamTable作為輸出表
table與streamTable不會對重復的資料進行寫入限制,因此在資料滿足觸發updateTime的條件而還未滿足觸發step的條件時,時序聚合引擎會不斷向輸出表添加同一個time的計算結果,最終得到的輸出表就會有大量時間相同的記錄,這個結果就沒有意義, - 若將keyedStreamTable作為輸出表
keyedStreamTable不允許更新歷史記錄,也不允許往表中添加key值相同的記錄,往表中添加新記錄時,系統會自動檢查新記錄的主鍵值,如果新紀錄的主鍵值與已有記錄的主鍵值重復時,新紀錄不會被寫入,在本場景下表現的結果是,在資料還沒有滿足觸發step的條件,但滿足觸發updateTime的條件時,時序聚合引擎將最近視窗的計算結果寫入到輸出表,卻因為時間相同而被禁止寫入,updateTIme引數同樣失去了意義, - 使用keyedTable作為輸出表
keyedTable允許更新,往表中添加新記錄時,系統會自動檢查新記錄的主鍵值,如果新紀錄的主鍵值與已有記錄的主鍵值重復時,會更新表中對應的記錄,在本場景下表現的結果是,同一個時間計算結果可能會發生更新,在資料還沒有滿足觸發step的條件,但滿足觸發updateTime的條件時,計算結果會被修改為根據最近視窗內的資料進行計算的結果,而不是向輸出表中添加一條新的記錄,直到資料滿足觸發step的條件時,才會向輸出表中添加新的記錄,而這個結果才是我們預期想要達到的效果,因此時序聚合引擎要求在使用updateTime引數時,必須使用keyedTable作為輸出表,
例如,要計算視窗為1分鐘的K線,但最近1分鐘的K線不希望等到視窗結束后再計算,希望每隔1秒鐘都更新一次近1分鐘的K線資料,我們可以通過如下步驟實作這個場景,
首先,我們需要創建一個keyedTable作為輸出表,并將時間列和股票代碼列作為主鍵,當有新的資料注入輸出表時,如果新紀錄的時間在表中已存在,會更新表中對應時間的記錄,這樣就能保證每次查詢時每個時刻的資料是最新的,
share keyedTable(`datetime`Symbol, 100:0, `datetime`Symbol`open`high`low`close`volume,[DATETIME,SYMBOL,DOUBLE,DOUBLE,DOUBLE,DOUBLE,LONG]) as OHLC請注意:在使用時序聚合引擎時將 keyedTable作為輸出表,若時序聚合引擎指定了keyColumn引數,那么kyedTable需要同時將時間相關列和keyColumn列作為主鍵,
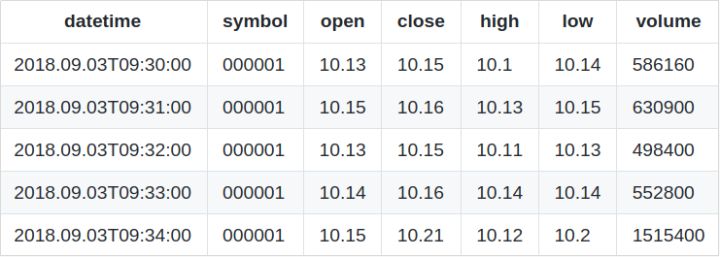
每隔1分鐘計算一次過去1分鐘的K線資料,并且每隔1秒鐘都更新一次近1分鐘的K線資料,可以使用以下腳本定義時序聚合引擎,其中,windowSize引數取值與step引數取值相等,并指定updateTime引數取值為1秒鐘,即每隔1秒種更新最近1分鐘的資料,下例中的useWindowStartTime引數則用于指定輸出表中的時間為資料視窗的起始時間,
tsAggrKline = createTimeSeriesAggregator(name="aggr_kline", windowSize=60, step=60, metrics=<[first(Price),max(Price),min(Price),last(Price),sum(volume)]>, dummyTable=Trade, outputTable=OHLC, timeColumn=`Datetime, keyColumn=`Symbol,updateTime=1, useWindowStartTime=true)請注意,在使用時間序列聚合引擎時,windowSize必須是step的整數倍,并且step必須是updateTime的整數倍,
最后,定義流資料訂閱,若此時流資料表Trade中已經有實時資料寫入,那么實時資料會馬上被訂閱并注入聚合引擎:
subscribeTable(tableName="Trade", actionName="act_tsaggr", offset=0, handler=append!{tsAggrKline}, msgAsTable=true)輸出表的前5行資料:
2.3 在Python中展示K線資料
在本例中,聚合引擎的輸出表也定義為流資料表,客戶端可以通過Python API訂閱輸出表,并將計算結果展現到Python終端,
以下代碼使用Python API訂閱實時聚合計算的輸出結果表OHLC,并將結果通過print函式列印出來,
import dolphindb as ddb
import pandas as pd
import numpy as np
#設定本地埠20001用于訂閱流資料
s.enableStreaming(20001)
def handler(lst):
print(lst)
# 訂閱DolphinDB(本機8848埠)上的OHLC流資料表
s.subscribe("127.0.0.1", 8848, handler, "OHLC")也可通過Grafana等可視化系統來連接DolphinDB database,對輸出表進行查詢并將結果以圖表方式展現,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/243958.html
標籤:AI
上一篇:一文詳解 Nacos 高可用特性
下一篇:奶爸日記19 - 湖邊蘆葦