文章目錄
- 缺失資料
- 一、缺失值的統計和洗掉
- 1. 缺失資訊的統計
- 2. 缺失資訊的洗掉
- 二、缺失值的填充和插值
- 1. 利用fillna進行填充
- 練一練
- 2. 插值函式
- 擴充知識
- 三、Nullable型別
- 1. 缺失記號及其缺陷
- 2. Nullable型別的性質
- 3. 缺失資料的計算和分組
- 四、練習
- Ex1:缺失值與類別的相關性檢驗
- Ex2:用回歸模型解決分類問題
缺失資料
在資料處理程序種我們經常會遇到缺失資料如NaN或None這樣的值,我們一般會對這些資料單獨處理,洗掉或者修改或者忽略等,下面分不同情況討論下如何處理缺失資料,
下面操作以此表格為基礎,表格如下
df = pd.read_csv('data/learn_pandas.csv',
usecols = ['Grade', 'Name', 'Gender', 'Height',
'Weight', 'Transfer'])
df.head()
| Grade | Name | Gender | Height | Weight | Transfer | |
|---|---|---|---|---|---|---|
| 0 | Freshman | Gaopeng Yang | Female | 158.9 | 46 | N |
| 1 | Freshman | Changqiang You | Male | 166.5 | 70 | N |
| 2 | Senior | Mei Sun | Male | 188.9 | 89 | N |
| 3 | Sophomore | Xiaojuan Sun | Female | nan | 41 | N |
| 4 | Sophomore | Gaojuan You | Male | 174 | 74 | N |
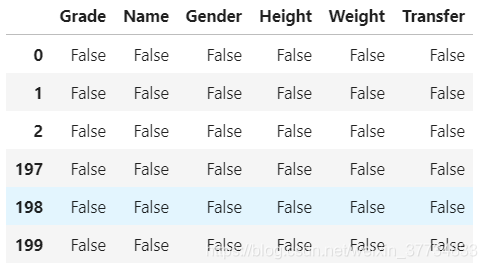
看下前三個和最后三個的空值情況,都不為空,
pd.concat([df.isna().head(3),df.isna().tail(3)])
一、缺失值的統計和洗掉
1. 缺失資訊的統計
缺失資料可以使用 isna 或 isnull (兩個函式沒有區別)來查看每個單元格是否缺失,結合sum()和mean()可以查看某缺失值數量及占比情況:
print(df.isna().sum())
print(df.isna().mean())
空值數量
| 0 | |
|---|---|
| Grade | 0 |
| Name | 0 |
| Gender | 0 |
| Height | 17 |
| Weight | 11 |
| Transfer | 12 |
空值占比情況
| 0 | |
|---|---|
| Grade | 0 |
| Name | 0 |
| Gender | 0 |
| Height | 0.085 |
| Weight | 0.055 |
| Transfer | 0.06 |
如果想要查看某一列缺失或者非缺失的行,可以利用 Series 上的 isna 或者 notna 進行布爾索引,例如,查看身高缺失的行:
df[df.Height.isna()].head()
| Grade | Name | Gender | Height | Weight | Transfer | |
|---|---|---|---|---|---|---|
| 3 | Sophomore | Xiaojuan Sun | Female | nan | 41 | N |
| 12 | Senior | Peng You | Female | nan | 48 | nan |
| 26 | Junior | Yanli You | Female | nan | 48 | N |
| 36 | Freshman | Xiaojuan Qin | Male | nan | 79 | Y |
| 60 | Freshman | Yanpeng Lv | Male | nan | 65 | N |
列印一下df.Height.isna()看看上面df傳入的是什么
df.Height.isna()
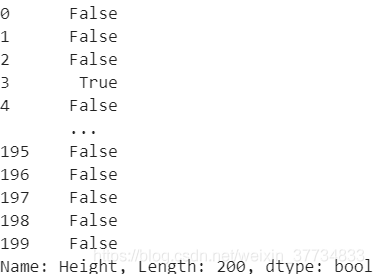
可以看到本質傳入的是一個bool型的Series,篩選出非空的資料(索引為Ture),那么我們試一下傳入一個bool型的list是不是一樣的效果,
test1=[True for i in range(1,len(df))]
test1.append(False)
df[test1].tail()
| Grade | Name | Gender | Height | Weight | Transfer | |
|---|---|---|---|---|---|---|
| 194 | Senior | Yanmei Qian | Female | 160.3 | 49 | nan |
| 195 | Junior | Xiaojuan Sun | Female | 153.9 | 46 | N |
| 196 | Senior | Li Zhao | Female | 160.9 | 50 | N |
| 197 | Senior | Chengqiang Chu | Female | 153.9 | 45 | N |
| 198 | Senior | Chengmei Shen | Male | 175.3 | 71 | N |
可以看到效果完全一致,我們傳入了一個長度和df相同的bool型list,除最后一共元素為False外全為True,成功過濾掉最后一行,
如果想要同時對幾個列,檢索出全部為缺失或者至少有一個缺失或者沒有缺失的行,可以使用 isna, notna 和 any, all 的組合,例如,對身高、體重和轉系情況這3列分別進行這三種情況的檢索:
sub_set = df[['Height', 'Weight', 'Transfer']]
df[sub_set.isna().all(1)]# 全部缺失
df[sub_set.isna().any(1)].head() # 至少有一個缺失
df[sub_set.notna().all(1)].head() # 沒有缺失
all的作用是判斷指定軸的所有元素是否都為真,回傳bool型的Series,any是只要有真就回傳True.
全部缺失情況
| Grade | Name | Gender | Height | Weight | Transfer | |
|---|---|---|---|---|---|---|
| 102 | Junior | Chengli Zhao | Male | nan | nan | nan |
至少有一個缺失
| Grade | Name | Gender | Height | Weight | Transfer | |
|---|---|---|---|---|---|---|
| 3 | Sophomore | Xiaojuan Sun | Female | nan | 41 | N |
| 9 | Junior | Juan Xu | Female | 164.8 | nan | N |
| 12 | Senior | Peng You | Female | nan | 48 | nan |
| 21 | Senior | Xiaopeng Shen | Male | 166 | 62 | nan |
| 26 | Junior | Yanli You | Female | nan | 48 | N |
沒有缺失
| Grade | Name | Gender | Height | Weight | Transfer | |
|---|---|---|---|---|---|---|
| 0 | Freshman | Gaopeng Yang | Female | 158.9 | 46 | N |
| 1 | Freshman | Changqiang You | Male | 166.5 | 70 | N |
| 2 | Senior | Mei Sun | Male | 188.9 | 89 | N |
| 4 | Sophomore | Gaojuan You | Male | 174 | 74 | N |
| 5 | Freshman | Xiaoli Qian | Female | 158 | 51 | N |
2. 缺失資訊的洗掉
資料處理中經常需要根據缺失值的大小、比例或其他特征來進行行樣本或列特征的洗掉, pandas 中提供了 dropna 函式來進行操作,
dropna 的主要引數為軸方向 axis (默認為0,即洗掉行)、洗掉方式 how 、洗掉的非缺失值個數閾值 thresh—threshold閾值的簡寫 ( 非缺失值 沒有達到這個數量的相應維度會被洗掉)、備選的洗掉子集 subset ,其中 how 主要有 any 和 all 兩種引數可以選擇,
例如,洗掉身高體重至少有一個缺失的行:
res=df.dropna(axis=0,subset =['Height','Weight'],how='any')
res.shape
輸出為(174, 6),刪掉了26行資料,
例如,洗掉超過15個缺失值的列:
res=df.dropna(axis=1,thresh=df.shape[0]-15)
res.shape
輸出(200, 5) 身高被洗掉,
當然,不用 dropna 同樣是可行的,例如上述的兩個操作,也可以使用布爾索引來完成:
res1 = df.loc[df[['Height', 'Weight']].notna().all(1)]
res2 = df.loc[:, ~(df.isna().sum()>15)]
二、缺失值的填充和插值
1. 利用fillna進行填充
在 fillna 中有三個引數是常用的: value, method, limit ,其中, value 為填充值,可以是標量,也可以是索引到元素的字典映射; method 為填充方法,有用前面的元素填充 ffill 和用后面的元素填充 bfill 兩種型別, limit 引數表示連續缺失值的最大填充次數,
s = pd.Series([np.nan, 1, np.nan, np.nan, 2, np.nan],
list('aaabcd'))
s.fillna(method='ffill', limit=1) # 用前面的值向后填充
s.ffill(limit=1) # 和上面的等價
s.fillna(s.mean())
注意含有缺失值的列中,計算均值時缺失值是不計算的,如果希望含有缺失值的行都不計入計算程序,可以事先采用上面提到的統計和洗掉操作進行預處理,如果希望計入計算,可以使用對應規則對缺失值填充,
有時為了更加合理地填充,需要先進行分組后再操作,例如,根據年級進行身高的均值填充:
df.Height=df.groupby('Grade')['Height'].transform(
lambda x: x.fillna(x.mean()))
df=df.round({'Height':2})
df.head(5)
| Grade | Name | Gender | Height | Weight | Transfer | |
|---|---|---|---|---|---|---|
| 0 | Freshman | Gaopeng Yang | Female | 158.9 | 46 | N |
| 1 | Freshman | Changqiang You | Male | 166.5 | 70 | N |
| 2 | Senior | Mei Sun | Male | 188.9 | 89 | N |
| 3 | Sophomore | Xiaojuan Sun | Female | 163.08 | 41 | N |
| 4 | Sophomore | Gaojuan You | Male | 174 | 74 | N |
使用上述操作,對不同年級學生的缺失值用相應年級非缺失值均值進行填充,
練一練
對一個序列以如下規則填充缺失值:如果單獨出現的缺失值,就用前后均值填充,如果連續出現的缺失值就不填充,即序列[1, NaN, 3, NaN, NaN]填充后為[1, 2, 3, NaN, NaN],請利用 fillna 函式實作,(提示:利用 limit 引數)
實作方法:想了好久腦殼疼,剛開始還想到了之前的滑窗和今天學到的結合,復習了一下滑窗發現好像沒用,后面想到可以利用兩次fillna,一次向前,一次向后,然后取均值的方法得到結果,試驗了下果然可行,
測驗的例子如下:
s = pd.Series([1,np.nan, 3, np.nan,np.nan, 4],
list('aabcdd'))
s
| 0 | |
|---|---|
| a | 1 |
| a | nan |
| b | 3 |
| c | nan |
| d | nan |
| d | 4 |
實作方法:
s1 = s.fillna(method='ffill',limit=1)
s2 = s.fillna(method='backfill',limit=1)
s=(s1+s2)/2
s
| 0 | |
|---|---|
| a | 1 |
| a | 2 |
| b | 3 |
| c | nan |
| d | nan |
| d | 4 |
2. 插值函式
在關于 interpolate 函式的 檔案 描述中,列舉了許多插值法,包括了大量 Scipy 中的方法,由于很多插值方法涉及到比較復雜的數學知識,因此這里只討論比較常用且簡單的三類情況,即線性插值、最近鄰插值和索引插值,
對于 interpolate 而言,除了插值方法(默認為 linear 線性插值)之外,有與 fillna 類似的兩個常用引數,一個是控制方向的 limit_direction ,另一個是控制最大連續缺失值插值個數的 limit ,其中,限制插值的方向默認為 forward ,這與 fillna 的 method 中的 ffill 是類似的,若想要后向限制插值或者雙向限制插值可以指定為 backward 或 both ,
擴充知識
這里看得不是很明白,啥是線性插值啊?去找了英文檔案看了,
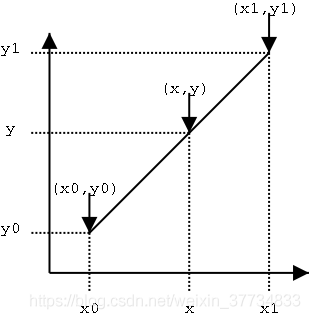
所謂線性插值是一種針對一維資料的插值方法,它根據一維資料序列中需要插值的點的左右鄰近兩個資料點來進行數值的估計,當然了它不是求這兩個點資料大小的平均值(當然也有求平均值的情況),而是根據到這兩個點的距離來分配它們的比重的,
圖片比較容易看懂,
公式:
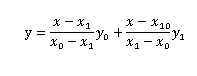
因為需要插入的位置前后都有資料才方便插,所以對于插入位置左右只有一個資料的情況(比如上面代碼的例子),就根據插入方向向前/后復制,
線性插值的例子:
s = pd.Series([np.nan, np.nan, 1,
np.nan, np.nan, np.nan,
2, np.nan, np.nan])
s.values
# 輸出為array([nan, nan, 1., nan, nan, nan, 2., nan, nan])
例如,在默認線性插值法下分別進行 backward 和雙向限制插值,同時限制最大連續條數為1:
res = s.interpolate(limit_direction='backward', limit=1)
res.values
#輸出為array([ nan, 1. , 1. , nan, nan, 1.75, 2. , nan, nan])
res = s.interpolate(limit_direction='both', limit=1)
res.values
#輸出為array([ nan, 1. , 1. , 1.25, nan, 1.75, 2. , 2. , nan])
第二種常見的插值是最近鄰插補,即缺失值的元素和離它最近的非缺失值元素一樣:
s.interpolate('nearest').values
# 輸出為array([nan, nan, 1., 1., 1., 2., 2., nan, nan])
這種只在兩端非缺失的位置插,距離兩端位置一樣情況按前一個復制插,
最后來介紹索引插值,即根據索引大小進行線性插值,例如,構造不等間距的索引進行演示:
In [33]: s = pd.Series([0,np.nan,10],index=[0,1,10])
In [34]: s
Out[34]:
0 0.0
1 NaN
10 10.0
dtype: float64
In [35]: s.interpolate() # 默認的線性插值,等價于計算中點的值
Out[35]:
0 0.0
1 5.0
10 10.0
dtype: float64
In [36]: s.interpolate(method='index') # 和索引有關的線性插值,計算相應索引大小對應的值
Out[36]:
0 0.0
1 1.0
10 10.0
dtype: float64
同時,這種方法對于時間戳索引也是可以使用的,有關時間序列的其他話題會在第十章進行討論,這里舉一個簡單的例子:
In [37]: s = pd.Series([0,np.nan,10],
....: index=pd.to_datetime(['20200101',
....: '20200102',
....: '20200111']))
....:
In [38]: s
Out[38]:
2020-01-01 0.0
2020-01-02 NaN
2020-01-11 10.0
dtype: float64
In [39]: s.interpolate()
Out[39]:
2020-01-01 0.0
2020-01-02 5.0
2020-01-11 10.0
dtype: float64
In [40]: s.interpolate(method='index')
Out[40]:
2020-01-01 0.0
2020-01-02 1.0
2020-01-11 10.0
dtype: float64
三、Nullable型別
1. 缺失記號及其缺陷
在 python 中的缺失值用 None 表示,該元素除了等于自己本身之外,與其他任何元素不相等:
In [41]: None == None
Out[41]: True
In [42]: None == False
Out[42]: False
In [43]: None == []
Out[43]: False
In [44]: None == ''
Out[44]: False
在 numpy 中利用 np.nan 來表示缺失值,該元素除了不和其他任何元素相等之外,和自身的比較結果也回傳 False :
In [45]: np.nan == np.nan
Out[45]: False
In [46]: np.nan == None
Out[46]: False
In [47]: np.nan == False
Out[47]: False
值得注意的是,雖然在對缺失序列或表格的元素進行比較操作的時候, np.nan 的對應位置會回傳 False ,但是在使用 equals 函式進行兩張表或兩個序列的相同性檢驗時,會自動跳過兩側表都是缺失值的位置,直接回傳 True :
s1 = pd.Series([1, np.nan])
s2 = pd.Series([1, 2])
s3 = pd.Series([1, np.nan])
print(s1 == 1)
print(s1 == s3)
print(s1.equals(s3))
前兩個都輸出如下
0 True
1 False
dtype: bool
第三個輸出為True
在時間序列的物件中, pandas 利用 pd.NaT 來指代缺失值,它的作用和 np.nan 是一致的(時間序列的物件和構造將在第十章討論):
In [54]: pd.to_timedelta(['30s', np.nan]) # Timedelta中的NaT
Out[54]: TimedeltaIndex(['0 days 00:00:30', NaT], dtype='timedelta64[ns]', freq=None)
In [55]: pd.to_datetime(['20200101', np.nan]) # Datetime中的NaT
Out[55]: DatetimeIndex(['2020-01-01', 'NaT'], dtype='datetime64[ns]', freq=None)
那么為什么要引入 pd.NaT 來表示時間物件中的缺失呢?仍然以 np.nan 的形式存放會有什么問題?在 pandas 中可以看到 object 型別的物件,而 object 是一種混雜物件型別,如果出現了多個型別的元素同時存盤在 Series 中,它的型別就會變成 object ,例如,同時存放整數和字串的串列:
pd.Series([1, 'two']).dtype
dtype(‘O’)
NaT 問題的根源來自于 np.nan 的本身是一種浮點型別,而如果浮點和時間型別混合存盤,如果不設計新的內置缺失型別來處理,就會變成含糊不清的 object 型別,這顯然是不希望看到的,
In [57]: type(np.nan)
Out[57]: float
同時,由于 np.nan 的浮點性質,如果在一個整數的 Series 中出現缺失,那么其型別會轉變為 float64 ;而如果在一個布爾型別的序列中出現缺失,那么其型別就會轉為 object 而不是 bool :
In [58]: pd.Series([1, np.nan]).dtype
Out[58]: dtype('float64')
In [59]: pd.Series([True, False, np.nan]).dtype
Out[59]: dtype('O')
因此,在進入 1.0.0 版本后, pandas 嘗試設計了一種新的缺失型別 pd.NA 以及三種 Nullable 序列型別來應對這些缺陷,它們分別是 Int, boolean 和 string ,
2. Nullable型別的性質
從字面意義上看 Nullable 就是可空的,言下之意就是序列型別不受缺失值的影響,例如,在上述三個 Nullable 型別中存盤缺失值,都會轉為 pandas 內置的 pd.NA :
In [60]: pd.Series([np.nan, 1], dtype = 'Int64') # "i"是大寫的
Out[60]:
0 <NA>
1 1
dtype: Int64
In [61]: pd.Series([np.nan, True], dtype = 'boolean')
Out[61]:
0 <NA>
1 True
dtype: boolean
In [62]: pd.Series([np.nan, 'my_str'], dtype = 'string')
Out[62]:
0 <NA>
1 my_str
dtype: string
在 Int 的序列中,回傳的結果會盡可能地成為 Nullable 的型別,操作的時候缺失值保持不變,
對于 boolean 型別的序列而言,其和 bool 序列的行為主要有兩點區別:
第一點是帶有缺失的布爾串列無法進行索引器中的選擇,而 boolean 會把缺失值看作 False :
s = pd.Series(['a', 'b'])
s_boolean = pd.Series([True, np.nan],dtype='boolean')
#s_boolean 不指定型別下面的索引會報錯
s[s_boolean]
第二點是在進行邏輯運算時, bool 型別在缺失處回傳的永遠是 False ,而 boolean 會根據邏輯運算是否能確定唯一結果來回傳相應的值,那什么叫能否確定唯一結果呢?舉個簡單例子: True | pd.NA 中無論缺失值為什么值,必然回傳 True ; False | pd.NA 中的結果會根據缺失值取值的不同而變化,此時回傳 pd.NA ; False & pd.NA 中無論缺失值為什么值,必然回傳 False ,
In [70]: s_boolean & True
Out[70]:
0 True
1 <NA>
dtype: boolean
In [71]: s_boolean | True
Out[71]:
0 True
1 True
dtype: boolean
In [72]: ~s_boolean # 取反操作同樣是無法唯一地判斷缺失結果
Out[72]:
0 False
1 <NA>
dtype: boolean
關于 string 型別的具體性質將在下一章文本資料中進行討論,
一般在實際資料處理時,可以在資料集讀入后,先通過 convert_dtypes 轉為 Nullable 型別:
df = pd.read_csv('data/learn_pandas.csv')
df = df.convert_dtypes()
df.dtypes
| 0 | |
|---|---|
| School | string |
| Grade | string |
| Name | string |
| Gender | string |
| Height | float64 |
| Weight | Int64 |
| Transfer | string |
| Test_Number | Int64 |
| Test_Date | string |
| Time_Record | string |
3. 缺失資料的計算和分組
當呼叫函式 sum, prob 使用加法和乘法的時候,缺失資料等價于被分別視作0和1,即不改變原來的計算結果,
當使用累計函式時,會自動跳過缺失值所處的位置,
下面是奇奇怪怪的比較結果:
In [80]: np.nan == 0
Out[80]: False
In [81]: pd.NA == 0
Out[81]: <NA>
In [82]: np.nan > 0
Out[82]: False
In [83]: pd.NA > 0
Out[83]: <NA>
In [84]: np.nan + 1
Out[84]: nan
In [85]: np.log(np.nan)
Out[85]: nan
In [86]: np.add(np.nan, 1)
Out[86]: nan
In [87]: np.nan ** 0
Out[87]: 1.0
In [88]: pd.NA ** 0
Out[88]: 1
In [89]: 1 ** np.nan
Out[89]: 1.0
In [90]: 1 ** pd.NA
Out[90]: 1
對于一些函式而言,缺失可以作為一個類別處理,例如在 groupby, get_dummies 中可以設定相應的引數來進行增加缺失類別:
df_nan = pd.DataFrame({'category':['a','a','b',np.nan,np.nan],
'value':[1,3,5,7,9]})
df_nan
| category | value | |
|---|---|---|
| 0 | a | 1 |
| 1 | a | 3 |
| 2 | b | 5 |
| 3 | nan | 7 |
| 4 | nan | 9 |
df_nan.groupby('category',
dropna=False)['value'].mean()
| category | value |
|---|---|
| a | 2 |
| b | 5 |
| nan | 8 |
pd.get_dummies(df_nan.category, dummy_na=True)
| a | b | nan | |
|---|---|---|---|
| 0 | 1 | 0 | 0 |
| 1 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 |
| 3 | 0 | 0 | 1 |
| 4 | 0 | 0 | 1 |
四、練習
Ex1:缺失值與類別的相關性檢驗
在資料處理中,含有過多缺失值的列往往會被洗掉,除非缺失情況與標簽強相關,下面有一份關于二分類問題的資料集,其中 X_1, X_2 為特征變數, y 為二分類標簽,
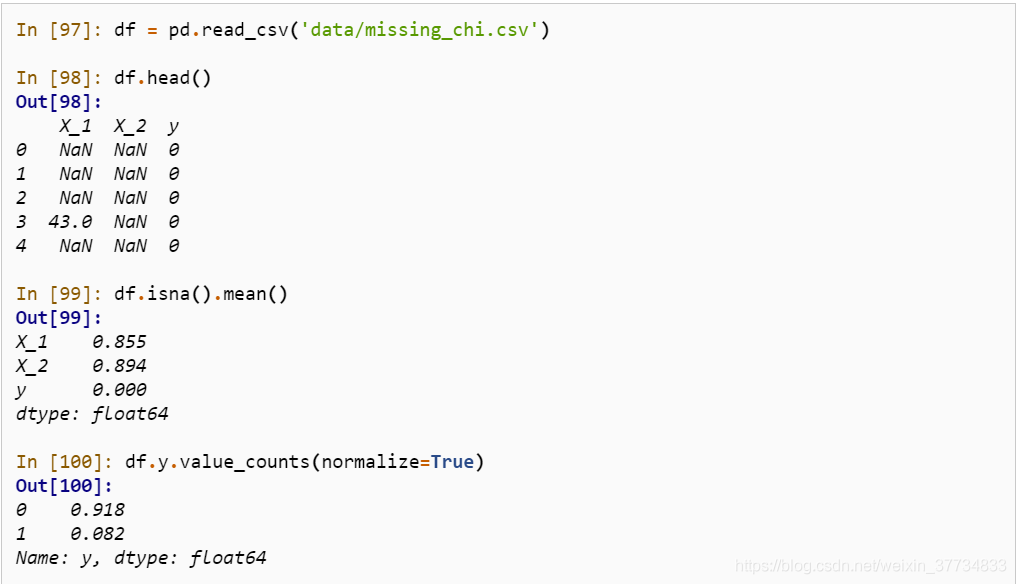
事實上,有時缺失值出現或者不出現本身就是一種特征,并且在一些場合下可能與標簽的正負是相關的,關于缺失出現與否和標簽的正負性,在統計學中可以利用卡方檢驗來斷言它們是否存在相關性,按照特征缺失的正例、特征缺失的負例、特征不缺失的正例、特征不缺失的負例,可以分為四種情況,設它們分別對應的樣例數為 n11,n10,n01,n00 ,假若它們是不相關的,那么特征缺失中正例的理論值,就應該接近于特征缺失總數 × 總體正例的比例,即:
E
11
=
n
11
≈
(
n
11
+
n
10
)
×
n
11
+
n
01
n
11
+
n
10
+
n
01
+
n
00
=
F
11
E_{11} = n_{11} \approx (n_{11}+n_{10})\times\frac{n_{11}+n_{01}}{n_{11}+n_{10}+n_{01}+n_{00}} = F_{11}
E11?=n11?≈(n11?+n10?)×n11?+n10?+n01?+n00?n11?+n01??=F11?
其他的三種情況同理,現將實際值和理論值分別記作
E
i
j
,
F
i
j
E_{ij}, F_{ij}
Eij?,Fij?,那么希望下面的統計量越小越好,即代表實際值接近不相關情況的理論值:
S
=
∑
i
∈
{
0
,
1
}
∑
j
∈
{
0
,
1
}
(
E
i
j
?
F
i
j
)
2
F
i
j
S = \sum_{i\in \{0,1\}}\sum_{j\in \{0,1\}} \frac{(E_{ij}-F_{ij})^2}{F_{ij}}
S=i∈{0,1}∑?j∈{0,1}∑?Fij?(Eij??Fij?)2?
可以證明上面的統計量近似服從自由度為 1 的卡方分布,即
S
~
?
χ
2
(
1
)
S\overset{\cdot}{\sim} \chi^2(1)
S~?χ2(1),因此,可通過計算
P
(
χ
2
(
1
)
>
S
)
P(\chi^2(1)>S)
P(χ2(1)>S) 的概率來進行相關性的判別,一般認為當此概率小于 0.05 時缺失情況與標簽正負存在相關關系,即不相關條件下的理論值與實際值相差較大,
上面所說的概率即為統計學上關于 2×2 列聯表檢驗問題的 p 值, 它可以通過 scipy.stats.chi2(S, 1) 得到,請根據上面的材料,分別對 X_1, X_2 列進行檢驗,
答案:
cat_1 = df.X_1.fillna('NaN').mask(df.X_1.notna()).fillna("NotNaN")
cat_2 = df.X_2.fillna('NaN').where(df.X_2.isna()).fillna("NotNaN")
df_1 = pd.crosstab(cat_1, df.y, margins=True)
df_2 = pd.crosstab(cat_2, df.y, margins=True)
首先將x1,x2兩列的資料根據是否缺失,將元素都換對應的NaN和NotNa,這里用了兩種方法,
然后使用了crosstab(),用于計算分組的頻率,它是一種特殊的pivot_table(),pivot_table()也可以實作crosstab()的功能,顯示y和x1,x2的情況,
def compute_S(my_df):
S = []
for i in range(2):
for j in range(2):
E = my_df.iat[i, j]
F = my_df.iat[i, 2]*my_df.iat[2, j]/my_df.iat[2,2]
S.append((E-F)**2/F)
return sum(S)
res1 = compute_S(df_1)
res2 = compute_S(df_2)
定義函式,以及計算,
from scipy.stats import chi2
chi2.sf(res1, 1)# X_1檢驗的p值 # 不能認為相關,剔除
#輸出 0.9712760884395901
chi2.sf(res2, 1)# X_2檢驗的p值 # 認為相關,保留
#輸出 7.459641265637543e-166
結果與 scipy.stats.chi2_contingency 在不使用 Yates 修正的情況下完全一致:
from scipy.stats import chi2_contingency
chi2_contingency(pd.crosstab(cat_1, df.y), correction=False)[1]
#輸出 0.9712760884395901
chi2_contingency(pd.crosstab(cat_2, df.y), correction=False)[1]
#輸出 7.459641265637543e-166
Ex2:用回歸模型解決分類問題
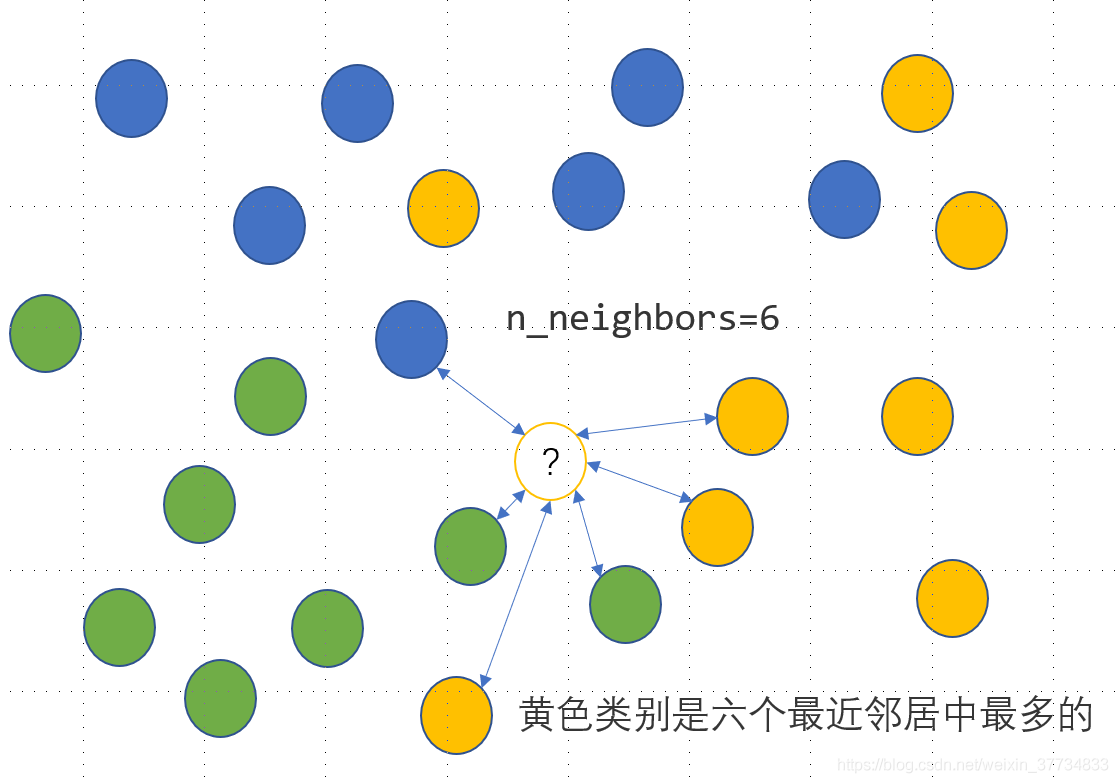
KNN 是一種監督式學習模型,既可以解決回歸問題,又可以解決分類問題,對于分類變數,利用 KNN 分類模型可以實作其缺失值的插補,思路是度量缺失樣本的特征與所有其他樣本特征的距離,當給定了模型引數 n_neighbors=n 時,計算離該樣本距離最近的 n 個樣本點中最多的那個類別,并把這個類別作為該樣本的缺失預測類別,具體如下圖所示,未知的類別被預測為黃色:
上面有色點的特征資料提供如下:
已知待預測的樣本點為 X1=0.8,X2=?0.2 ,那么預測類別可以如下寫出:
- 對于回歸問題而言,需要得到的是一個具體的數值,因此預測值由最近的 n 個樣本對應的平均值獲得,請把上面的這個分類問題轉化為回歸問題,僅使用 KNeighborsRegressor 來完成上述的 KNeighborsClassifier 功能,
思路:
首先獲得one-hot型特征向量
from sklearn.neighbors import KNeighborsRegressor
df = pd.read_excel('data/color.xlsx')
df_dummies = pd.get_dummies(df.Color)
df_dummies.head()
| Blue | Green | Yellow | |
|---|---|---|---|
| 0 | 1 | 0 | 0 |
| 1 | 1 | 0 | 0 |
| 2 | 1 | 0 | 0 |
| 3 | 1 | 0 | 0 |
| 4 | 1 | 0 | 0 |
下面構建回歸模型,將x1,x2位置作為輸入,顏色特征(藍綠黃三列)作為輸出,然后每個顏色預測一下輸入[0.8, -0.2]位置的點是該顏色的概率是多少,將預測概率最大的作為該位置最終預測顏色,
stack_list = []
for col in df_dummies.columns:
clf = KNeighborsRegressor(n_neighbors=6)
clf.fit(df.iloc[:,:2], df_dummies[col])
res = clf.predict([[0.8, -0.2]]).reshape(-1,1)
stack_list.append(res)
stack_list
# 輸出為[array([[0.16666667]]), array([[0.33333333]]), array([[0.5]])]
預測l成藍綠黃三個顏色的概率分別是16.7%,33.3%和50%,
取最大的概率作為最終預測結果,該位置最終預測為黃色,
code_res = pd.Series(np.hstack(stack_list).argmax(1))
df_dummies.columns[code_res[0]]
# 輸出為'Yellow'
- 請根據第1問中的方法,對 audit 資料集中的 Employment 變數進行缺失值插補,
思路:
from sklearn.neighbors import KNeighborsRegressor
df = pd.read_csv('data/audit.csv')
res_df = df.copy()
#將婚姻狀況、性別變成one-hot向量,和年齡、收入、時間、雇用拼接在一起
# 年齡、收入、時間這三個屬性還做了標準化處理
df = pd.concat([pd.get_dummies(df[['Marital', 'Gender']]),
df[['Age','Income','Hours']].apply(
lambda x:(x-x.min())/(x.max()-x.min())), df.Employment],1)
X_train = df[df.Employment.notna()]
X_test = df[df.Employment.isna()]
df_dummies = pd.get_dummies(X_train.Employment)
stack_list = []
for col in df_dummies.columns:
clf = KNeighborsRegressor(n_neighbors=6)
clf.fit(X_train.iloc[:,:-1], df_dummies[col])
res = clf.predict(X_test.iloc[:,:-1]).reshape(-1,1)
stack_list.append(res)
code_res = pd.Series(np.hstack(stack_list).argmax(1))
cat_res = code_res.replace(dict(zip(list(
range(df_dummies.shape[0])),df_dummies.columns)))
res_df.loc[res_df.Employment.isna(), 'Employment'] = cat_res.values
res_df.isna().sum()
#輸出為
# ID 0
# Age 0
# Employment 0
# Marital 0
# Income 0
# Gender 0
# Hours 0
# dtype: int64
這里按照提供的答案這樣寫會報錯,可以改成我上面那樣,
X_train = df.query('Employment.notna()')
X_test = df.query('Employment.isna()')
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/244246.html
標籤:其他