目錄
- 寫在前面
- matlab強化學習庫簡介
- 航天器三軸姿態穩定器介紹
- 演算法流程
- 代碼/simulink
- 結果展示與分析
- 一些心得
- 寫在最后
寫在前面
%寫在前面:
本人大四狗一名,不是計算機專業,所以這方面比較菜,最近在學習強化學習的一些演算法,python更新太快,很多一兩年前的學習資料就不太能用了,涉及到版本匹配和語法的更改等一系列問題,2020b的matlab中加入了DDPG\TD3\PPO等演算法的強化學習算例和強化學習庫,于是想用matlab來做強化學習,
由于本人是航空航天工程專業的,又和畢設有點聯系,于是想試一下用強化學習演算法學習一個姿態自穩定器,這個算例是根據matlab自帶的雙足機器人行走算例改造的,可能有的地方做的不好,如果寫的哪里不對,還請各位大佬多多指教,
matlab強化學習庫簡介
matlab在2020b中加入了幾個強化學習演算法的算例,對強化學習庫進行了完善,讓同學們可以自由使用,
matlab中的強化學習庫是一系列封裝好的函式,包括環境搭建、智能體搭建、訓練函式、各種模型引數設定等眾多函式,在matlab的官網可以查到各個函式的help,具體請各位移步:https://ww2.mathworks.cn/help/reinforcement-learning/referencelist.html?type=function
里面是matlab強化學習的各類函式介紹,
航天器三軸姿態穩定器介紹
此次算例給出的是航天器三軸姿態穩定控制器,模擬的場景是航天器三軸出現較小角度的偏差,加上航天器本身存在自轉,造成航天器滾動軸和偏航軸出現耦合,控制輸出力矩讓航天器恢復穩定狀態,
算例中用的此臺動力學方程為航天器的線性化姿態動力學方程,取自西北工業大學出版社的《航天器控制原理》,周軍撰寫的教材
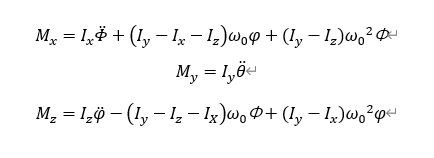
Mx,My,Mz就是三軸上的力矩,Ix,Iy,Iz就是三個慣性主軸的慣量,另外三個角度就對應滾動,俯仰,偏航的三個歐拉角,本文中采用w0為0.0011°/s,完成的是衛星對地定向,保持有效載荷對地造成的自轉速度,每個軸的初始偏差為(-4°,4°)之間,初始角速度在(-0.2,0.2)之間,單位°/s最終控制到所有軸偏差與角速度之和小于0.3,如果能一直保持小于0.8也認為不錯,
演算法流程
和matlab給出的雙足機器人行走算例流程一致,(因為就是基于此改造的),在simulink中呼叫RL Agent模塊來搭建env和agent的關系,在m檔案中呼叫train函式進行學習,我們要做的就是把程式所需要的附屬函式寫好,模塊搭好,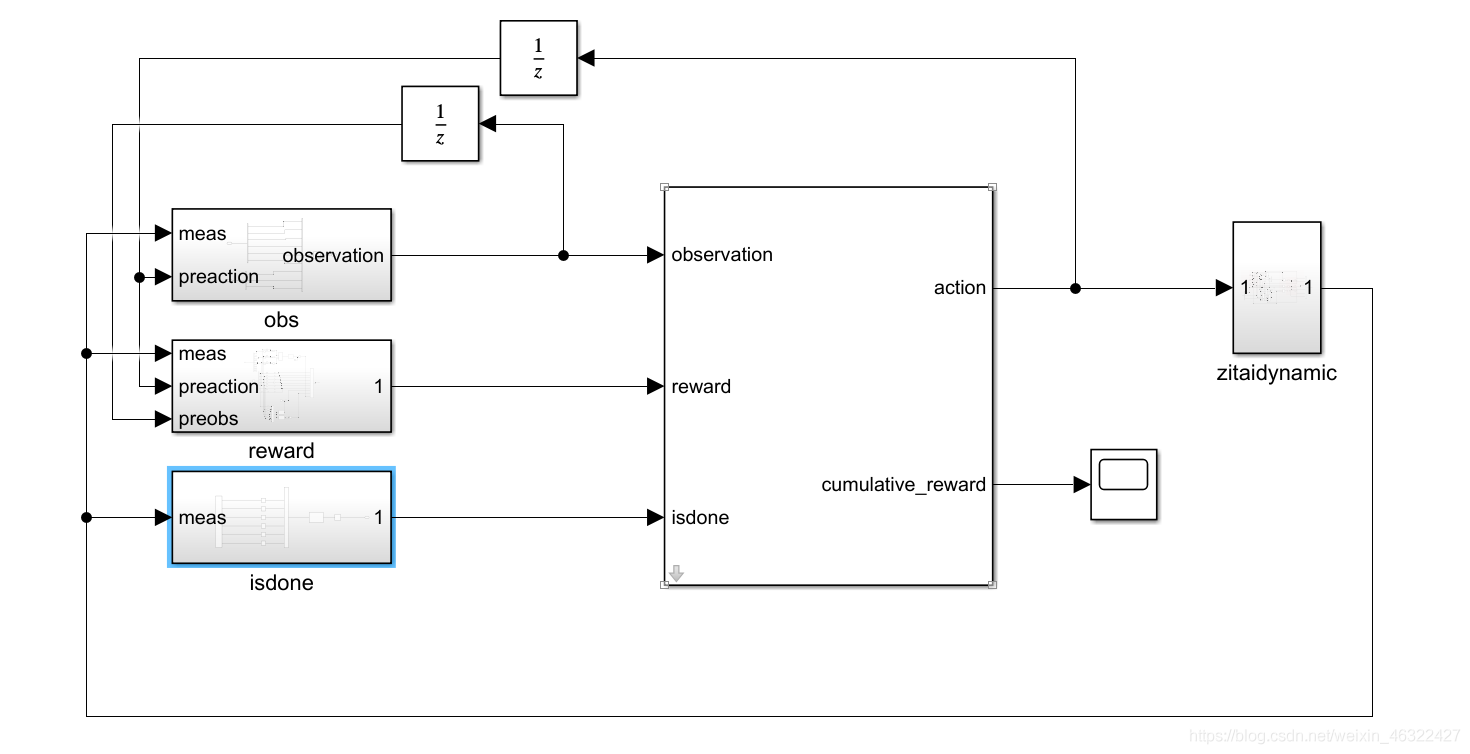
這是simulink中的整體布局,由agent根據現在的obs給出下一步的action,再有三軸姿態動力學給出積分一個步長以后的狀態,我們給出這個狀態的reward,agent再根據我們反饋的reward進行學習,在一定學習次數以后選擇reward最高的方式給出action,到這里我們的學習就算完成了,用學好的agent就可以根據環境來進行動作了,
兩個1/z模塊是延時模塊,用來找到上一時刻的動作和狀態,
代碼/simulink
在這里給出main函式和simulink中的主要模塊,
w0=0.0011;
ts=1;%積分一次的步長
tf=40;%一個周期積分時間(經驗回放一次)
ix=212;
iy=108;
iz=220;
dv=0.1;
fai=2*rand(1)-2*rand(1);
kesai=2*rand(1)-2*rand(1);
dotfai=dv*rand(1)-dv*rand(1);
dotseita=dv*rand(1)-dv*rand(1);
dotkesai=dv*rand(1)-dv*rand(1);
seita=(2*rand(1)-2*rand(1));
while 1%如果所有值得總和小于1,重新計算,直到大于等于1,
if abs(fai)+abs(kesai)+abs(dotfai)+abs(dotseita)+abs(dotkesai)+abs(seita)>1
break;
else
fai=(2*rand(1)-2*rand(1));
dotfai=dv*rand(1)-dv*rand(1);
dotseita=dv*rand(1)-dv*rand(1);
kesai=(2*rand(1)-2*rand(1));
dotkesai=dv*rand(1)-dv*rand(1);
seitai=(2*rand(1)-2*rand(1));
end
end
%進行資料的初始化,包括初始角度誤差,初始角速度誤差,慣性主軸大小和系轉角速度大小等,
mdl='zitaidynamic';
open_system(mdl)
%打開simulink中的模型,
numobs=9;
obsInfo=rlNumericSpec([numobs 1]);
obsInfo.Name='observations';
%設定obs大小并占位,
numact=3;
actInfo=rlNumericSpec([numact 1],'LowerLimit',-10,'UpperLimit',10);
actInfo.Name='torque';
%設定action大小并占位,
blk=[mdl,'/RL Agent'];
env=rlSimulinkEnv(mdl,blk,obsInfo,actInfo);
env.ResetFcn=@(in)zitairesetfcn(in);
%用simulink中的RL Agent和之前占過的地兒來創建env,
agent=createDDPGAgent(numobs,obsInfo,numact,actInfo,ts);
%采用DDPG演算法,
maxEpisodes=500;%訓練500次,太多了時間太長,耗不起,500次以后已經收斂了,
maxSteps=floor(tf/ts);%一次最多積分多少步,
trainOpts=rlTrainingOptions(...
'MaxEpisodes',maxEpisodes,...
'MaxStepsPerEpisode',maxSteps,...
'ScoreAveragingWindowLength',250,...
'Verbose',false,...
'Plots','training-progress',...
'StopTrainingCriteria','EpisodeCount',...
'StopTrainingValue',maxEpisodes,...
'SaveAgentCriteria','EpisodeCount',...
'SaveAgentValue',maxEpisodes);
trainOpts.UseParallel = 0;
trainOpts.ParallelizationOptions.Mode = 'async';
trainOpts.ParallelizationOptions.StepsUntilDataIsSent = 32;
trainOpts.ParallelizationOptions.DataToSendFromWorkers = 'Experiences';
%設定訓練的各種引數,
trainingStats = train(agent,env,trainOpts);%開始訓練,
main函式中的引數調整我在上一篇博客中寫的比較詳盡,再次就不贅述了,有興趣的朋友可以去https://blog.csdn.net/weixin_46322427/article/details/112008607看一看,能點個贊就更好了,
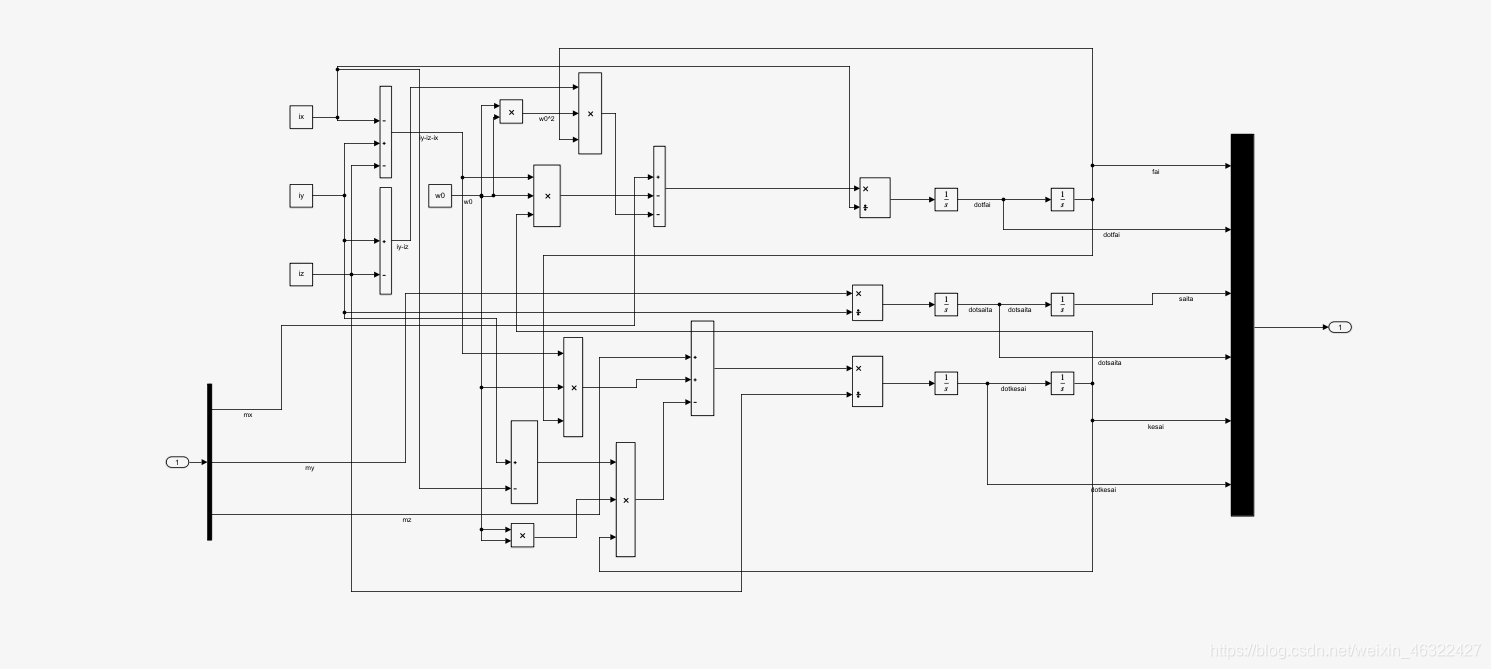
這是zitaidynamic的框圖,就是上面寫過的姿態動力學方程,由于是自己手搭的,沒有很美化hhh,最后是把三個角度和三個角速度當成輸出發了出去,
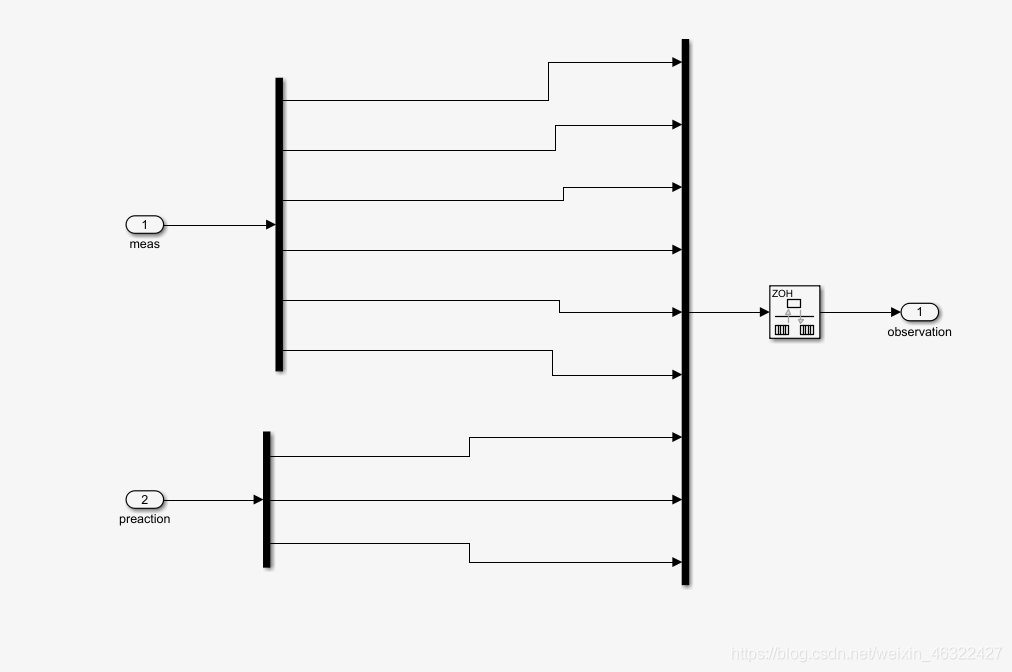 這是observation的框圖,可見是把zitaidynamic的六維輸出加上上一步驟的力矩并在一起為9維的資料當作obs,給到env中,
這是observation的框圖,可見是把zitaidynamic的六維輸出加上上一步驟的力矩并在一起為9維的資料當作obs,給到env中,
那個不太常用的模塊是積分速率轉換器,由于zitaidynamic中的積分步長是自定步長的(ode23mod)而env中的計算步長是ts,需要轉換一下,
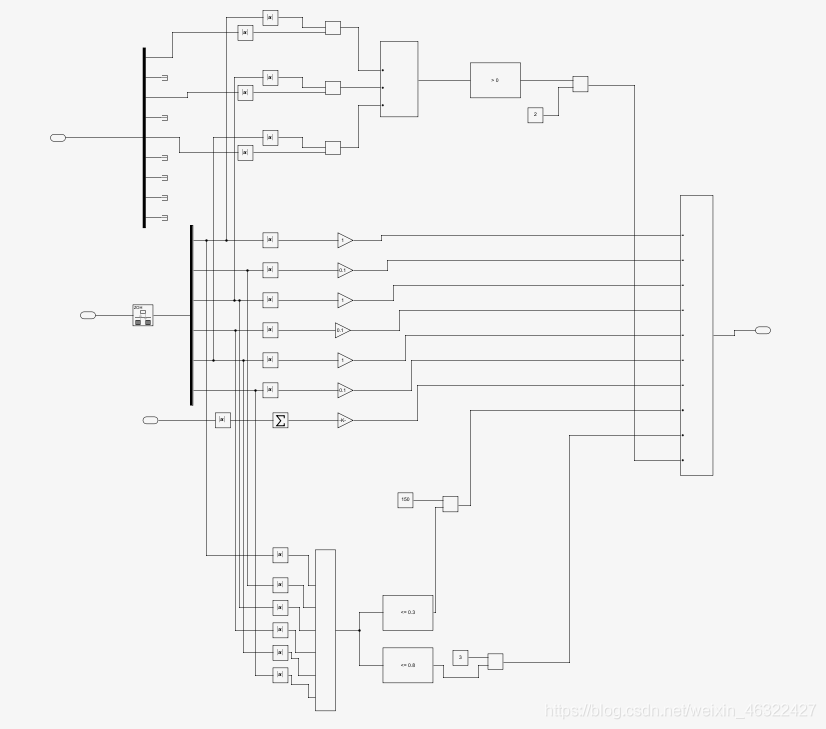 reward中的框圖就比較麻煩了,在程式除錯的程序中reward也是最麻煩的程序,讓人頭禿,我個人的一些心得會在下一個部分介紹,其實reward主要分為三部分,如下,
reward中的框圖就比較麻煩了,在程式除錯的程序中reward也是最麻煩的程序,讓人頭禿,我個人的一些心得會在下一個部分介紹,其實reward主要分為三部分,如下,
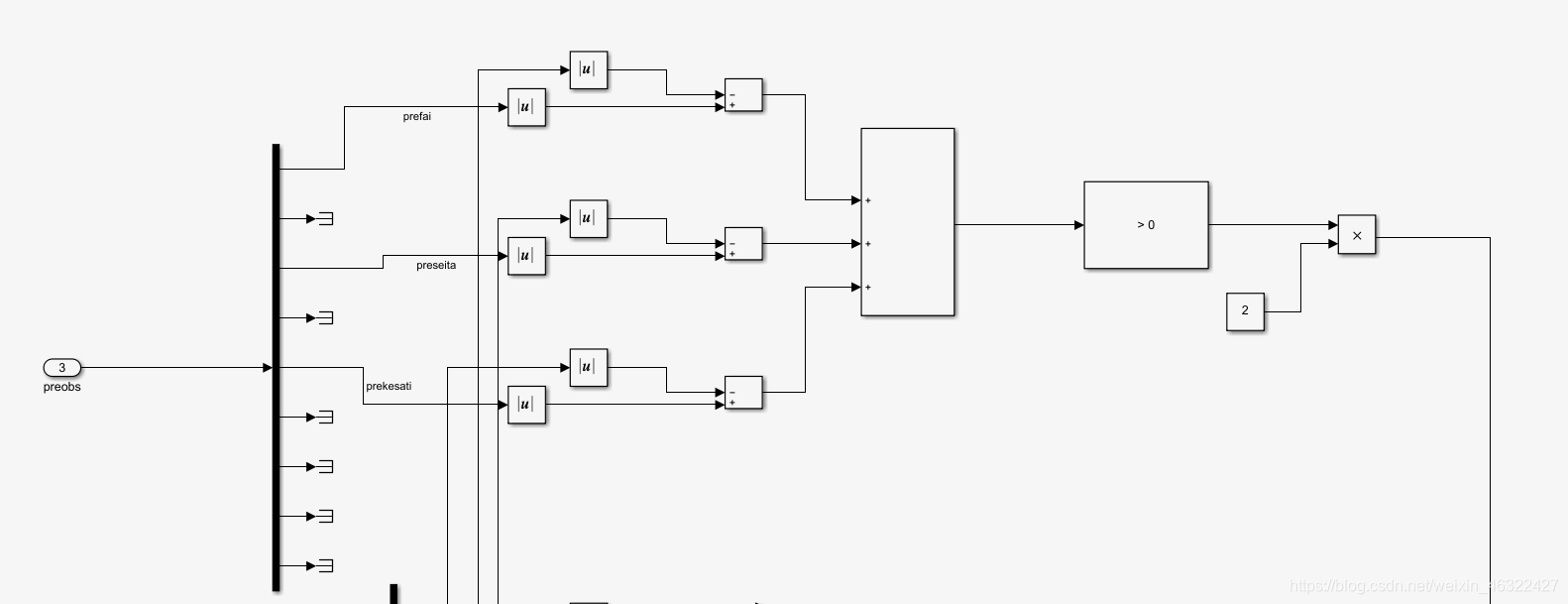 這一部分將preobs引入,是上一步的狀態量,取它的第1,3,5,是三個角度量,和現在的obs進行對比,只要這一步驟比上一步驟絕對值之和要小,就給予獎勵,這個獎勵使得程式很快就能趨向于選取讓角度減小的力矩值,不然程式自己隨機選取很可能直接發散掉,這種獎勵函式的選取一定程度上增強了穩定性,
這一部分將preobs引入,是上一步的狀態量,取它的第1,3,5,是三個角度量,和現在的obs進行對比,只要這一步驟比上一步驟絕對值之和要小,就給予獎勵,這個獎勵使得程式很快就能趨向于選取讓角度減小的力矩值,不然程式自己隨機選取很可能直接發散掉,這種獎勵函式的選取一定程度上增強了穩定性,
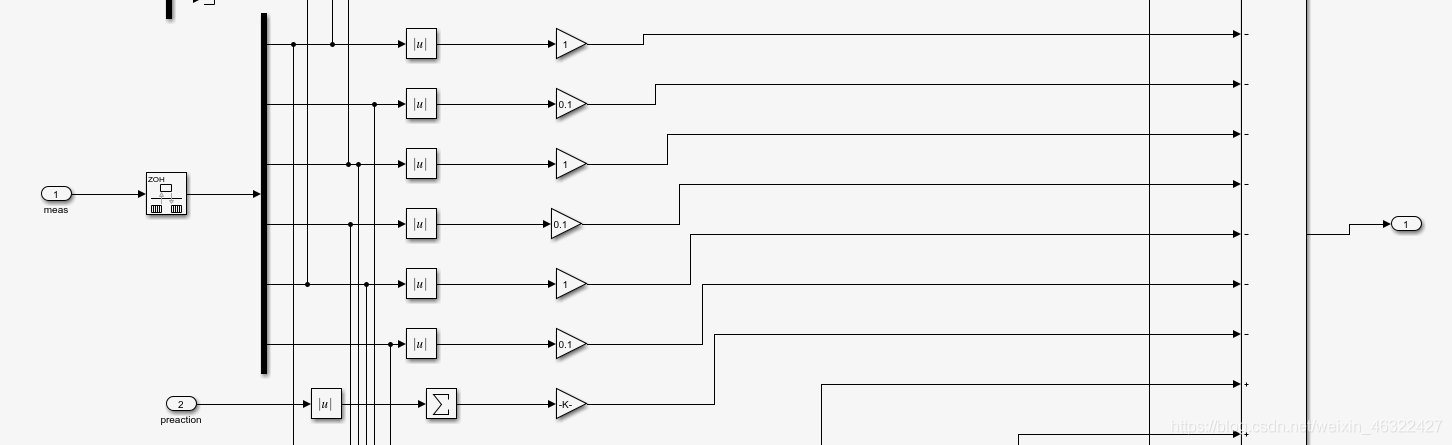
第二部分為所有的角度,角速度,力矩都是不好的,這些項都會給agent帶來負的獎勵,這激勵著agent向完全穩定方向前進,
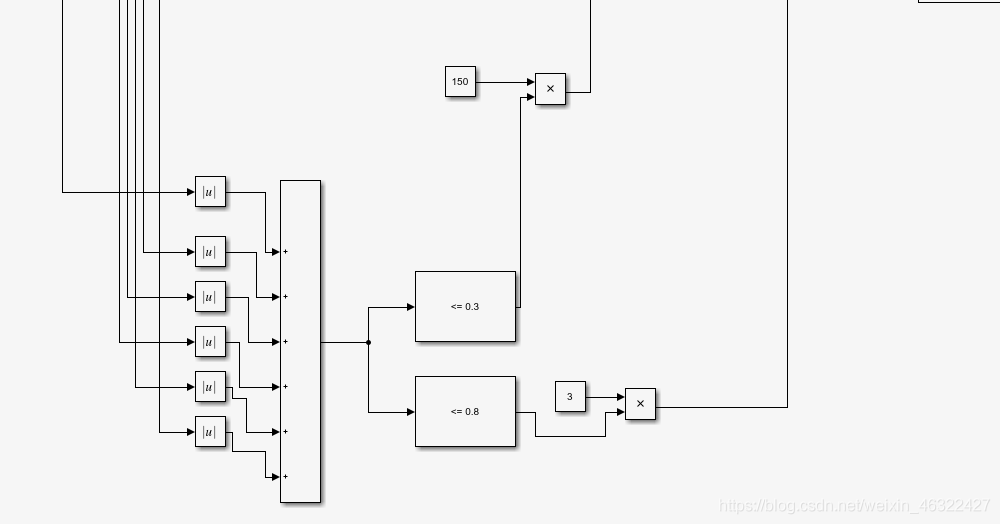 第三部分為完成任務后的獎勵,可見六個值的絕對值之和小于0.8就會給出一個獎勵,這讓agent在后期都會收斂到0.8°之內,另外,當程式六個值之和小于0等于0.3都會有一個很大的獎勵,讓agent趨向于做出這樣的動作,
第三部分為完成任務后的獎勵,可見六個值的絕對值之和小于0.8就會給出一個獎勵,這讓agent在后期都會收斂到0.8°之內,另外,當程式六個值之和小于0等于0.3都會有一個很大的獎勵,讓agent趨向于做出這樣的動作,
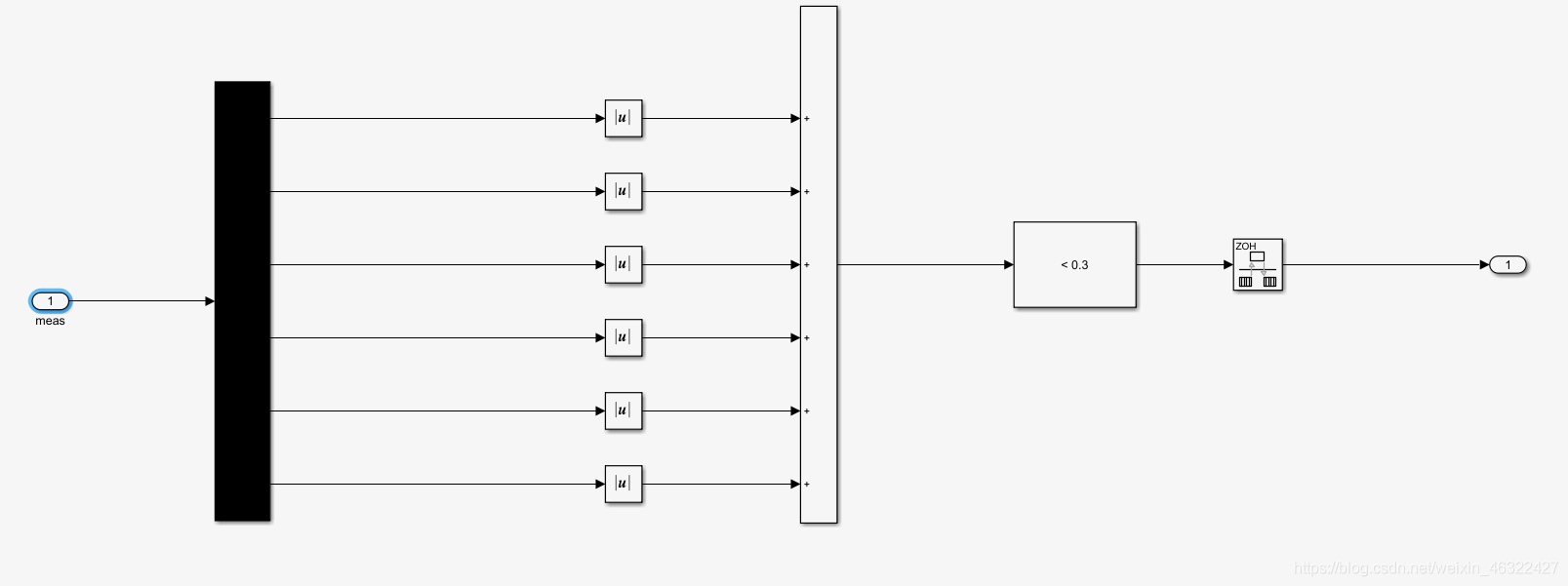
最后是isdone的搭建,如圖,只有六個值絕對值之和小于0.3才能退出回圈,這就使得agent只有超過最大時間或者完成目標兩種方式退出回圈,而只要在想錯誤的方向運動,reward就會給出負值,相當于給agent一個懲罰,所以這個操作也能加強系統穩定性,
完整代碼和simulink可以在我的資源里找哦,
結果展示與分析
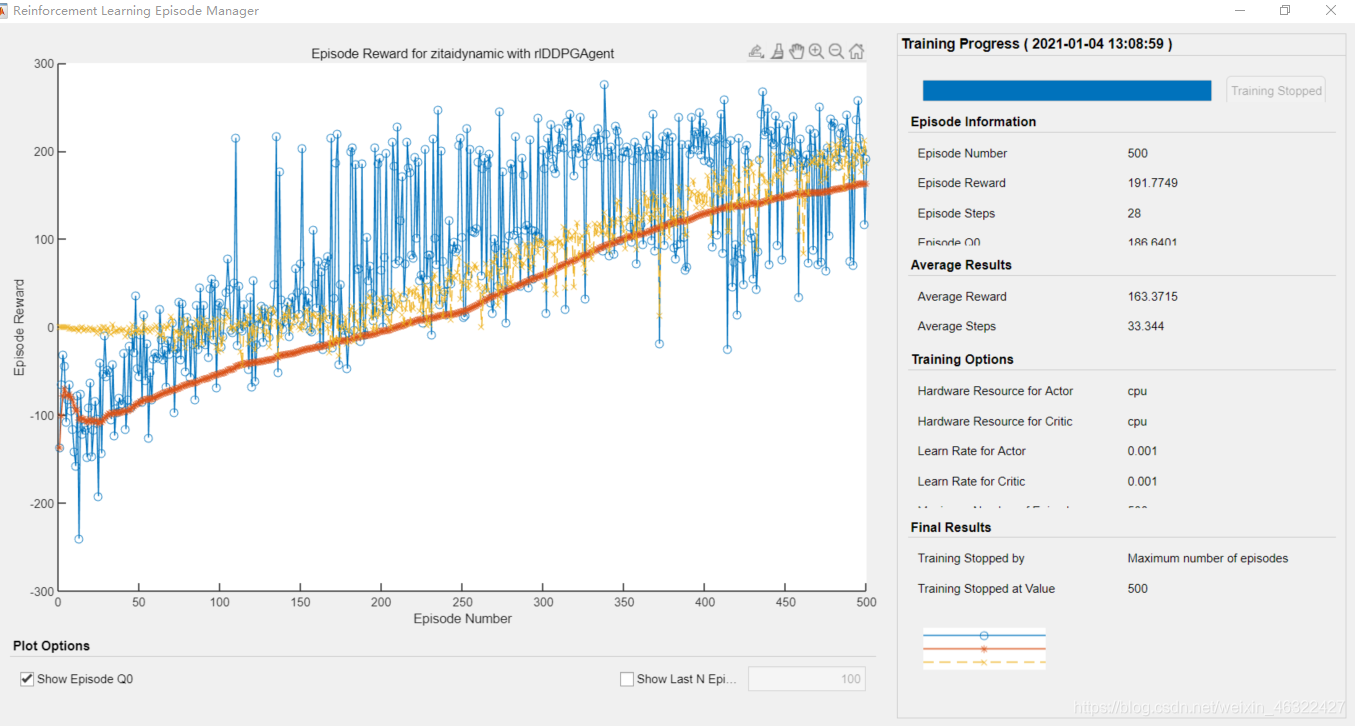 可見在100多次的學習之后,agent就可以達到0.3以內退出回圈了,可以看到,最終收斂于達到目標0.3,退出回圈,所有的學習程序分為三部分,
可見在100多次的學習之后,agent就可以達到0.3以內退出回圈了,可以看到,最終收斂于達到目標0.3,退出回圈,所有的學習程序分為三部分,
第一部分:隨機取值,一百次之前,獎勵是負的,
第二部分:開始收斂,可以達到0.8,
第三部分:可以達到0.3的推出條件,
這種遞進是在獎勵函式的撰寫時就應該想好的,不然很容易就發散掉了,
一些心得
最重要的就是獎勵函式的撰寫,這玩意弄不好,出來的錯誤奇奇怪怪的,
還有isdone也要寫好,我之前有一段時間,把isdone寫成了如果角度錯的太大也會退出,然后agent學了幾次之后,還沒有遇到正的反饋時就收斂到最快達到錯誤角度,受到最小的懲罰了,于是agent就瘋了一樣往擴大誤差的方向跑,我一度懷疑這破電腦讓我倒騰壞了,
另外,第一部分的獎勵函式很重要,不然智能體很可能找不到自動控制在0.8之內獲得獎勵的方式,由于這個問題是一個三維非線性問題,耦合在一起,如果沒有一個策略去鼓勵它做正確的動作,他還是很傻的,
不過最后出結果還是很開心的,快樂地像個兩百斤的胖子,
寫在最后
水平有限,請有幸看到的您多多指正,在作業之余,祝您早安,午安,晚安,Have a nice day,
(可能的話點個贊再走吧)
P.S.完整程式在我的資源里找,博主還會不定時更新的,喜歡的話就收藏吧,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/244783.html
標籤:AI