在前一篇文章中我介紹了如何使用 Faster-RCNN 模型實作識別人臉位置與是否戴口罩,這一篇我將介紹如何改進模型的精度,并且介紹如何支持視頻識別,過去的文章我基本上都只介紹模型的實作原理與使用例子,沒有過度追求精確率,這是為了讓讀者拋開細節理解,但實際應用機器學習的時候我們還是需要對模型作出各種修改以達到更好的結果,本篇文章就是改進物件識別模型的例子,這個例子使用的方法不一定適用于其他場景,但應該可以給你帶來一些啟發??,
首先展示下改進前后的效果:
改進前 (視頻 1)

改進后 (視頻 1)

改進前 (視頻 2)

改進后 (視頻 2)

接下來我將會介紹改進了哪些地方,并且最后會給出改進后的完整代碼,
改進內容
擴充資料集
決定機器學習訓練效果最關鍵的因素是什么,是模型嗎???并不是,比模型更關鍵的是資料集的質量??,即使模型再強大沒有足夠的資料一樣訓練不出什么成果,我們來看看前一篇使用的資料集:
https://www.kaggle.com/andrewmvd/face-mask-detection
這個資料集包含了 853 張圖片 (部分圖片沒有使用),其中各個分類的數量如下:
- 戴口罩的區域 (with_mask): 3232 個
- 不戴口罩的區域 (without_mask): 717 個
- 帶了口罩但姿勢不正確的區域 (mask_weared_incorrect): 123 個
是不是感覺比較少?如果需要自己采集資料,那么就得加班加點多采集一些??,而這次用的是現成的資料集,那么我們可以去找一找有沒有其他資料集可以一起用,還記得介紹 Fast-RCNN 的文章嗎?這篇文章用的資料集只包含了人臉區域,沒有包含是否戴口罩的標記,但仔細看資料內容會發現圖片里面的人臉都沒有戴口罩,那么我們可以把這些資料全部當成不戴口罩的區域,一共有 24533 個:
https://www.kaggle.com/vin1234/count-the-number-of-faces-present-in-an-image
加在一起以后:
- 戴口罩的區域 (with_mask): 3232 個
- 不戴口罩的區域 (without_mask): 717+24533 = 25250 個
- 帶了口罩但姿勢不正確的區域 (mask_weared_incorrect): 123 個
再仔細看一下,帶了口罩但姿勢不正確的區域的數量明顯太少了,不足以做出正確的判斷,我們可以把這些區域全部歸到戴口罩的區域里面,也就是只判斷你戴口罩,你戴的姿勢對不對老子管不著??,加在一起以后:
- 戴口罩的區域 (with_mask): 3232+123=3355 個
- 不戴口罩的區域 (without_mask): 717+24533 = 25250 個
好了,再想想有沒有辦法可以增加資料量?其實有一個非常簡單的方法,把圖片左右翻轉就可以讓資料量變成兩倍:

除了左右翻轉以外我們還可以使用旋轉圖片,擴大縮小圖片,添加噪點等方式增加資料量,左右翻轉以后的最終資料量如下,總資料量大概是原來的 14 倍??:
- 戴口罩的區域 (with_mask): (3232+123)*2=6710 個
- 不戴口罩的區域 (without_mask): (717+24533)*2 = 50500 個
讀取兩個資料集的代碼如下(最后會給出完整代碼):
# 加載圖片和圖片對應的區域與分類串列
# { (路徑, 是否左右翻轉): [ 區域與分類, 區域與分類, .. ] }
# 同一張圖片左右翻轉可以生成一個新的資料,讓資料量翻倍
box_map = defaultdict(lambda: [])
for filename in os.listdir(DATASET_1_IMAGE_DIR):
# 從第一個資料集加載
xml_path = os.path.join(DATASET_1_ANNOTATION_DIR, filename.split(".")[0] + ".xml")
if not os.path.isfile(xml_path):
continue
tree = ET.ElementTree(file=xml_path)
objects = tree.findall("object")
path = os.path.join(DATASET_1_IMAGE_DIR, filename)
for obj in objects:
class_name = obj.find("name").text
x1 = int(obj.find("bndbox/xmin").text)
x2 = int(obj.find("bndbox/xmax").text)
y1 = int(obj.find("bndbox/ymin").text)
y2 = int(obj.find("bndbox/ymax").text)
if class_name == "mask_weared_incorrect":
# 佩戴口罩不正確的樣本數量太少 (只有 123),模型無法學習,這里全合并到戴口罩的樣本
class_name = "with_mask"
box_map[(path, False)].append((x1, y1, x2-x1, y2-y1, CLASSES_MAPPING[class_name]))
box_map[(path, True)].append((x1, y1, x2-x1, y2-y1, CLASSES_MAPPING[class_name]))
df = pandas.read_csv(DATASET_2_BOX_CSV_PATH)
for row in df.values:
# 從第二個資料集加載,這個資料集只包含沒有戴口罩的圖片
filename, width, height, x1, y1, x2, y2 = row[:7]
path = os.path.join(DATASET_2_IMAGE_DIR, filename)
box_map[(path, False)].append((x1, y1, x2-x1, y2-y1, CLASSES_MAPPING["without_mask"]))
box_map[(path, True)].append((x1, y1, x2-x1, y2-y1, CLASSES_MAPPING["without_mask"]))
# 打亂資料集 (因為第二個資料集只有不戴口罩的圖片)
box_list = list(box_map.items())
random.shuffle(box_list)
print(f"found {len(box_list)} images")
翻轉圖片的代碼如下,同時會翻轉區域的 x 坐標 (圖片寬度 - 原 x 坐標 - 區域寬度):
for (image_path, flip), original_boxes_labels in box_list:
with Image.open(image_path) as img_original: # 加載原始圖片
sw, sh = img_original.size # 原始圖片大小
if flip:
img = resize_image(img_original.transpose(Image.FLIP_LEFT_RIGHT)) # 翻轉然后縮放圖片
else:
img = resize_image(img_original) # 縮放圖片
image_index = len(image_tensors) # 圖片在批次中的索引值
image_tensors.append(image_to_tensor(img)) # 添加圖片到串列
true_boxes_labels = [] # 圖片對應的真實區域與分類串列
# 添加真實區域與分類串列
for box_label in original_boxes_labels:
x, y, w, h, label = box_label
if flip: # 翻轉坐標
x = sw - x - w
資料量變多以后會需要更多的訓練時間,前一篇文章在 GTX1650 顯卡上訓練大概需要 3 小時,而這一篇則需要 15 小時左右??,
調整生成錨點的引數
我們可以讓模型更貼合資料以改進訓練效果,在前一篇文章我介紹了 Faster-RCNN 的區域生成網路會根據錨點 (Anchor) 判斷圖片中的各個部分是否包含物件:
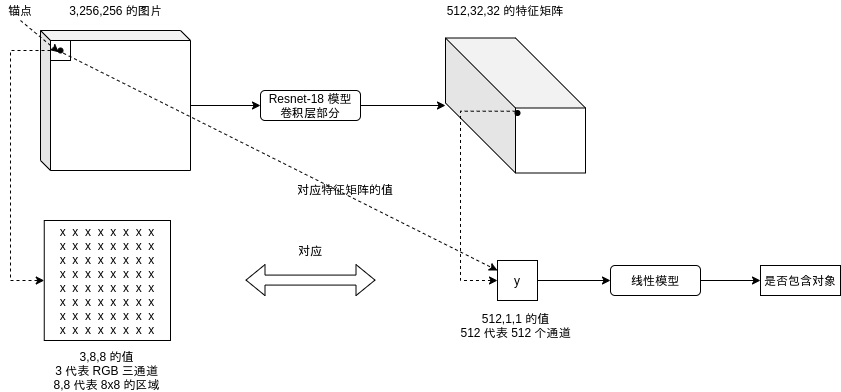
因為 CNN 模型輸出矩陣的大小是 通道數量,圖片長度/8,圖片寬度/8,也就是每個錨點對應 8x8 像素的區域,區域生成網路需要根據 8x8 像素的區域判斷這個區域是否有可能包含物件,這篇使用的代碼在處理圖片之前會先把圖片縮放到 256x192,8x8 的區域相對起來似乎過小了,我們可以把錨點區域擴大到 16x16,使得區域生成網路判斷起來有更充分的依據,擴大錨點區域同時需要修改 CNN 模型,使得輸出矩陣大小為 通道數量,圖片長度/16,圖片寬度/16,這個修改將會在后面介紹,
需要注意的是擴大錨點區域以后會減弱檢測小物件的能力,但這篇的圖片中的人臉區域基本上都在 16x16 以上,所以不會受到影響,
此外,前一篇還介紹了每個錨點都會對應多個形狀:
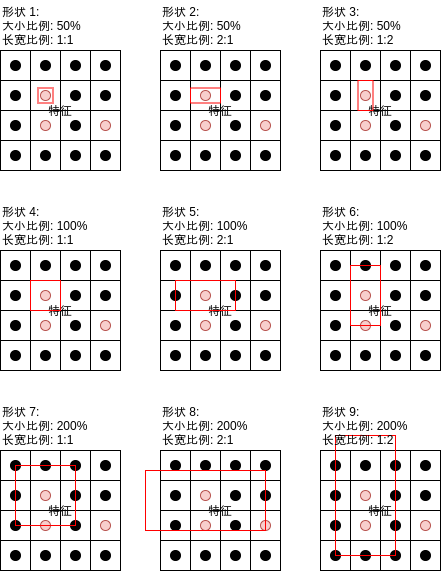
通過觀察資料我們可以發現人臉的長寬比例接近 1:1,并且我們不需要檢測人臉以外的東西,所以我們可以刪掉長寬比例 1:2 與 2:1 的形狀,減少模型的計算量,
總結起來我們可以這樣修改生成錨點的引數:
修改前
AnchorSpan = 8 # 錨點之間的距離,應該等于原有長寬 / resnet 輸出長寬
AnchorScales = (0.5, 1, 2, 3, 4, 5, 6) # 錨點對應區域的縮放比例串列
AnchorAspects = ((1, 2), (1, 1), (2, 1)) # 錨點對應區域的長寬比例串列
修改后
AnchorSpan = 16 # 錨點之間的距離,應該等于原有長寬 / resnet 輸出長寬
AnchorScales = (1, 2, 4, 6, 8) # 錨點對應區域的縮放比例串列
AnchorAspects = ((1, 1),) # 錨點對應區域的長寬比例串列
在這里我們學到了應該根據資料和檢測場景來決定錨點區域大小和長寬比例,如果需要檢測的物體相對圖片都比較大,那么就可以相應的增加錨點區域大小;如果需要檢測的物體形狀比較固定,那么就可以相應調整長寬比例,例如檢測車輛可以用 1:2,檢測行人可以用 3:1,檢測車牌可以用 1:3 等等,
修改模型
因為上面修改了錨點之間的距離從 8x8 到 16x16,我們需要把 CNN 模型輸出的矩陣大小從 通道數量,圖片長度/8,圖片寬度/8 修改到 通道數量,圖片長度/16,圖片寬度/16,這個修改非常的簡單,再加一層卷積層即可,因為這篇使用的是 Resnet 模型,這里會在后面多加一個塊,代碼如下:
修改前
self.rpn_resnet = nn.Sequential(
nn.Conv2d(3, self.previous_channels_out, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(self.previous_channels_out),
nn.ReLU(inplace=True),
self._make_layer(BasicBlock, channels_out=16, num_blocks=2, stride=1),
self._make_layer(BasicBlock, channels_out=32, num_blocks=2, stride=2),
self._make_layer(BasicBlock, channels_out=64, num_blocks=2, stride=2),
self._make_layer(BasicBlock, channels_out=128, num_blocks=2, stride=2))
修改后
self.rpn_resnet = nn.Sequential(
nn.Conv2d(3, self.previous_channels_out, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(self.previous_channels_out),
nn.ReLU(inplace=True),
self._make_layer(BasicBlock, channels_out=8, num_blocks=2, stride=1),
self._make_layer(BasicBlock, channels_out=16, num_blocks=2, stride=2),
self._make_layer(BasicBlock, channels_out=32, num_blocks=2, stride=2),
self._make_layer(BasicBlock, channels_out=64, num_blocks=2, stride=2),
self._make_layer(BasicBlock, channels_out=128, num_blocks=2, stride=2))
self.cls_resnet 也需要做出同樣的修改,
此外為了適應更多的資料量,這里還增加了根據區域截取特征后縮放到的大小:
# 根據區域截取特征后縮放到的大小
self.pooling_size = 16
這樣判斷分類的時候會使用 通道數量x16x16,即 128x16x16 的資料,需要注意的是這么做不一定有好處,判斷分類使用的資料越大就越有可能發生過擬合現象 (訓練集正確率很高但驗證集正確率卻不行,不能用于識別未知資料),實際需要根據訓練結果做出調整,
輸出分數
我們知道區域生成網路會針對各個錨點的各個形狀輸出是否可能包含物件,輸出值越接近 1 那么就越可能包含物件,越接近 0 那么就越不可能包含物件,我們可以把這個輸出值當作分數,分數越高代表區域越有可能包含物件,接下來標簽分類網路會針對區域生成網路給出的區域進行識別,每個區域的每個分類都會輸出一個值,經過 softmax 計算以后得出各個分類的概率 (加起來會等于 1),這個概率也可以拿來作為分數使用,
最終我們可以給 Faster-RCNN 輸出的各個包含物件的區域賦予一個分數:
分數 = 區域生成網路輸出值 * 最大值(softmax(標簽分類網路各個分類輸出值))
分數將會介于 0 ~ 1 之間,
原則上分數越高代表模型對這個區域越有把握,我們可以根據這個分數可以用來調整閾值,也可以根據這個分數來更高合并預測結果區域的演算法,但實際上你可能會看到分數為 1 但結果是錯誤的區域,所以只能說原則上,
回傳分數的代碼請參考后面完整代碼的 MyModel.forward 函式中關于 rpn_score 與 cls_score 的部分,
更改合并預測結果區域的演算法
還記得介紹 Fast-RCNN 的文章里面,我提到了合并結果區域的幾個方法:
- 使用最左,最右,最上,或者最下的區域
- 使用第一個區域 (區域選取演算法會按出現物件的可能性排序)
- 結合所有重合的區域 (如果區域調整效果不行,則可能出現結果區域比真實區域大很多的問題)
前一篇文章的 Faster-RCNN 模型使用了第三個方法,但上面我們輸出分數以后可以選擇第二個方法,即先按分數對區域進行排序,然后選擇重合的區域中分數最高的區域作為結果,并去除其他重合的區域,這個方法也稱作 NMS (Non Max Suppression) 法:

使用這種方法的好處是輸出的區域將會更小,看起來更精確,但如果場景是檢測障礙物那么最好還是使用第三種方法??,
合并預測結果區域的代碼如下,這里我把函式寫到 MyModel 類里面了:
# 判斷是否應該合并重疊區域的重疊率閾值
IOU_MERGE_THRESHOLD = 0.30
# 是否使用 NMS 演算法合并區域
USE_NMS_ALGORITHM = True
@staticmethod
def merge_predicted_result(cls_result):
"""合并預測結果區域"""
# 記錄重疊的結果區域, 結果是 [ [(標簽, 區域, RPN 分數, 標簽識別分數)], ... ]
final_result = []
for label, box, rpn_score, cls_score in cls_result:
for index in range(len(final_result)):
exists_results = final_result[index]
if any(calc_iou(box, r[1]) > IOU_MERGE_THRESHOLD for r in exists_results):
exists_results.append((label, box, rpn_score, cls_score))
break
else:
final_result.append([(label, box, rpn_score, cls_score)])
# 合并重疊的結果區域
# 使用 NMS 演算法: RPN 分數 * 標簽識別分數 最高的區域為結果區域
# 不使用 NMS 演算法: 使用所有區域的合并,并且選取數量最多的標簽 (投票式)
for index in range(len(final_result)):
exists_results = final_result[index]
if USE_NMS_ALGORITHM:
exists_results.sort(key=lambda r: r[2]*r[3])
final_result[index] = exists_results[-1]
else:
cls_groups = defaultdict(lambda: [])
for r in exists_results:
cls_groups[r[0]].append(r)
most_common = sorted(cls_groups.values(), key=len)[-1]
label = most_common[0][0]
box_merged = most_common[0][1]
for _, box, _, _ in most_common[1:]:
box_merged = merge_box(box_merged, box)
rpn_score_mean = sum(x for _, _, x, _ in most_common) / len(most_common)
cls_score_mean = sum(x for _, _, _, x in most_common) / len(most_common)
final_result[index] = (label, box_merged, rpn_score_mean, cls_score_mean)
return final_result
只根據標簽分類正確率判斷是否停止訓練
最后我們修改以下判斷是否停止訓練的邏輯,之前的判斷依據是 驗證集的區域生成正確率或標簽分類正確率在 20 次訓練以后沒有更新 則停止訓練,但計算標簽分類正確率的時候用的是 預測結果中區域范圍與實際范圍重疊率超過閾值并且分類一致的結果數量 / 實際范圍的總數量,也就是標簽分類正確率代表了模型可以找出百分之多少的區域并且正確判斷它們的分類,因為標簽分類正確率會基于區域生成正確率,所以我們可以只使用標簽分類正確率判斷是否停止訓練,修改以后的判斷依據為 驗證集的標簽分類正確率在 20 次訓練以后沒有更新 則停止訓練,
# 記錄最高的驗證集正確率與當時的模型狀態,判斷是否在 20 次訓練后仍然沒有重繪記錄
# 只依據標簽分類正確率判斷,因為標簽分類正確率同時基于 RPN 正確率
if validating_cls_accuracy > validating_cls_accuracy_highest:
validating_rpn_accuracy_highest = validating_rpn_accuracy
validating_rpn_accuracy_highest_epoch = epoch
validating_cls_accuracy_highest = validating_cls_accuracy
validating_cls_accuracy_highest_epoch = epoch
save_tensor(model.state_dict(), "model.pt")
print("highest cls validating accuracy updated")
elif (epoch - validating_rpn_accuracy_highest_epoch > 20 and
epoch - validating_cls_accuracy_highest_epoch > 20):
# 在 20 次訓練后仍然沒有重繪記錄,結束訓練
print("stop training because highest validating accuracy not updated in 20 epoches")
break
需要注意的是我給出的計算正確率的方法是比較簡單的,更準確的方法是計算 mAP (mean Average Precision),具體可以參考這篇文章,我給出的方法實際只相當于文章中的 Recall,
支持視頻識別
上一篇文章給出的代碼只能識別單張圖片,而物件識別的應用場景通常要求識別視頻,所以這里我再給出支持視頻識別的代碼,讀取視頻檔案 (或者攝像頭) 使用的類別庫是 opencv,針對上一篇文章的識別代碼如下 (這一篇文章的識別代碼請參考后面給出的完整代碼):
def eval_video():
"""使用訓練好的模型識別視頻"""
# 創建模型實體,加載訓練好的狀態,然后切換到驗證模式
model = MyModel().to(device)
model.load_state_dict(load_tensor("model.pt"))
model.eval()
# 詢問視頻路徑,給可能是人臉的區域添加標記并保存新視頻
import cv2
from PIL import ImageFont
font = ImageFont.truetype("FreeMonoBold.ttf", 20)
while True:
try:
video_path = input("Video path: ")
if not video_path:
continue
# 讀取輸入視頻
video = cv2.VideoCapture(video_path)
# 獲取每秒的幀數
fps = int(video.get(cv2.CAP_PROP_FPS))
# 獲取視頻長寬
size = (int(video.get(cv2.CAP_PROP_FRAME_WIDTH)), int(video.get(cv2.CAP_PROP_FRAME_HEIGHT)))
# 創建輸出視頻
video_output_path = os.path.join(
os.path.dirname(video_path),
os.path.splitext(os.path.basename(video_path))[0] + ".output.avi")
result = cv2.VideoWriter(video_output_path, cv2.VideoWriter_fourcc(*"XVID"), fps, size)
# 逐幀處理
count = 0
while(True):
ret, frame = video.read()
if not ret:
break
# opencv 使用的是 BGR, Pillow 使用的是 RGB, 需要轉換通道順序
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 構建輸入
img_original = Image.fromarray(frame_rgb) # 加載原始圖片
sw, sh = img_original.size # 原始圖片大小
img = resize_image(img_original) # 縮放圖片
img_output = img_original.copy() # 復制圖片,用于后面添加標記
tensor_in = image_to_tensor(img)
# 預測輸出
cls_result = model(tensor_in.unsqueeze(0).to(device))[-1][0] or []
# 合并重疊的結果區域, 結果是 [ [標簽串列, 合并后的區域], ... ]
final_result = []
for label, box in cls_result:
for index in range(len(final_result)):
exists_labels, exists_box = final_result[index]
if calc_iou(box, exists_box) > IOU_MERGE_THRESHOLD:
exists_labels.append(label)
final_result[index] = (exists_labels, merge_box(box, exists_box))
break
else:
final_result.append(([label], box))
# 合并標簽 (重疊區域的標簽中數量最多的分類為最終分類)
for index in range(len(final_result)):
labels, box = final_result[index]
final_label = Counter(labels).most_common(1)[0][0]
final_result[index] = (final_label, box)
# 標記在圖片上
draw = ImageDraw.Draw(img_output)
for label, box in final_result:
x, y, w, h = map_box_to_original_image(box, sw, sh)
color = "#00FF00" if CLASSES[label] == "with_mask" else "#FF0000"
draw.rectangle((x, y, x+w, y+h), outline=color, width=3)
draw.text((x, y-20), CLASSES[label], fill=color, font=font)
# 寫入幀到輸出視頻
frame_rgb_annotated = numpy.asarray(img_output)
frame_bgr_annotated = cv2.cvtColor(frame_rgb_annotated, cv2.COLOR_RGB2BGR)
result.write(frame_bgr_annotated)
count += 1
if count % fps == 0:
print(f"handled {count//fps}s")
video.release()
result.release()
cv2.destroyAllWindows()
print(f"saved to {video_output_path}")
print()
except Exception as e:
raise
print("error:", e)
有幾點需要注意的是:
- 這個例子是讀取現有的視頻檔案,如果你想從攝像頭讀取可以把
video = cv2.VideoCapture(video_path)改為video = cv2.VideoCapture(0),0 代表第一個攝像頭,1 代表第二個攝像頭,以此類推 - opencv 讀取出來的通道順序是 BGR (Blue, Green, Red),而 Pillow 使用的通道順序是 RGB (Red, Blue, Green),所以需要使用
cv2.cvtColor進行轉換 - 輸入視頻會定義每秒的幀數 (FPS),創建輸出視頻的時候需要保證 FPS 一致,否則會出現播放速度不一樣的問題
- 這里為了方便看,戴口罩的區域會使用綠色標記,而不帶口罩的區域會使用紅色標記
- Pillow 默認標記文本使用的字體是固定大小的,不支持縮放,這里我使用了
FreeMonoBold.ttf字體并指定字體大小為 20,如果你的環境沒有這個字體應該換一個名稱 (Windows 的話可以用arial.ttf)
減少視頻識別中的誤判
視頻識別有一個特性是內容通常是有連續性的,視頻中的物體通常會出現在連續的幾幀里面,利用這個特性我們可以減少視頻識別中的誤判,我們首先定義一個幀數,例如 10 幀,如果物體出現在過去 10 幀的 5 幀以上那么就判斷物體存在,這樣做可以排除模型針對某一幀忽然出現的誤判,我們還可以統計過去 10 幀里面識別出來的分類,然后選擇出現數量最多的分類,投票決定結果,
具體實作代碼如下:
@staticmethod
def fix_predicted_result_from_history(cls_result, history_results):
"""根據歷史結果減少預測結果中的誤判,適用于視頻識別,history_results 應為指定了 maxlen 的 deque"""
# 要求歷史結果中 50% 以上存在類似區域,并且選取歷史結果中最多的分類
history_results.append(cls_result)
final_result = []
if len(history_results) < history_results.maxlen:
# 歷史結果不足,不回傳任何識別結果
return final_result
for label, box, rpn_score, cls_score in cls_result:
# 查找歷史中的近似區域
similar_results = []
for history_result in history_results:
history_result = [(calc_iou(r[1], box), r) for r in history_result]
history_result.sort(key = lambda r: r[0])
if history_result and history_result[-1][0] > IOU_MERGE_THRESHOLD:
similar_results.append(history_result[-1][1])
# 判斷近似區域數量是否過半
if len(similar_results) < history_results.maxlen // 2:
continue
# 選取歷史結果中最多的分類
cls_groups = defaultdict(lambda: [])
for r in similar_results:
cls_groups[r[0]].append(r)
most_common = sorted(cls_groups.values(), key=len)[-1]
# 添加最多的分類中的最新的結果
final_result.append(most_common[-1])
return final_result
history_results 是一個指定了最大數量的佇列型別,可以用以下代碼生成:
from collections import deque
history_results = deque(maxlen = 10)
每次添加元素到 history_results 以后如果數量超出指定的最大數量則它會自動彈出最早添加的元素,
這個做法提高了視頻識別的穩定性,但同時會損失一定的實時性并且帶來一些副作用,例如 FPS 為 30 的時候,人需要在同一個位置停留 1/3 秒以后才會被識別出來,如果人一直快速走動那么就不會被識別出來,此外如果戴口罩的人把口罩脫掉,那么脫掉以后的 1/6 秒模型仍然會識別這個人戴著口罩,是使用這個做法需要根據使用場景決定,
完整代碼
好了,改進以后的完整代碼如下??:
import os
import sys
import torch
import gzip
import itertools
import random
import numpy
import math
import pandas
import json
from PIL import Image
from PIL import ImageDraw
from PIL import ImageFont
from torch import nn
from matplotlib import pyplot
from collections import defaultdict
from collections import deque
import xml.etree.cElementTree as ET
# 縮放圖片的大小
IMAGE_SIZE = (256, 192)
# 訓練使用的資料集路徑
DATASET_1_IMAGE_DIR = "./archive/images"
DATASET_1_ANNOTATION_DIR = "./archive/annotations"
DATASET_2_IMAGE_DIR = "./784145_1347673_bundle_archive/train/image_data"
DATASET_2_BOX_CSV_PATH = "./784145_1347673_bundle_archive/train/bbox_train.csv"
# 分類串列
CLASSES = [ "other", "with_mask", "without_mask" ]
CLASSES_MAPPING = { c: index for index, c in enumerate(CLASSES) }
# 判斷是否存在物件使用的區域重疊率的閾值
IOU_POSITIVE_THRESHOLD = 0.30
IOU_NEGATIVE_THRESHOLD = 0.10
# 判斷是否應該合并重疊區域的重疊率閾值
IOU_MERGE_THRESHOLD = 0.30
# 是否使用 NMS 演算法合并區域
USE_NMS_ALGORITHM = True
# 用于啟用 GPU 支持
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class BasicBlock(nn.Module):
"""ResNet 使用的基礎塊"""
expansion = 1 # 定義這個塊的實際出通道是 channels_out 的幾倍,這里的實作固定是一倍
def __init__(self, channels_in, channels_out, stride):
super().__init__()
# 生成 3x3 的卷積層
# 處理間隔 stride = 1 時,輸出的長寬會等于輸入的長寬,例如 (32-3+2)//1+1 == 32
# 處理間隔 stride = 2 時,輸出的長寬會等于輸入的長寬的一半,例如 (32-3+2)//2+1 == 16
# 此外 resnet 的 3x3 卷積層不使用偏移值 bias
self.conv1 = nn.Sequential(
nn.Conv2d(channels_in, channels_out, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(channels_out))
# 再定義一個讓輸出和輸入維度相同的 3x3 卷積層
self.conv2 = nn.Sequential(
nn.Conv2d(channels_out, channels_out, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(channels_out))
# 讓原始輸入和輸出相加的時候,需要維度一致,如果維度不一致則需要整合
self.identity = nn.Sequential()
if stride != 1 or channels_in != channels_out * self.expansion:
self.identity = nn.Sequential(
nn.Conv2d(channels_in, channels_out * self.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channels_out * self.expansion))
def forward(self, x):
# x => conv1 => relu => conv2 => + => relu
# | ^
# |==============================|
tmp = self.conv1(x)
tmp = nn.functional.relu(tmp, inplace=True)
tmp = self.conv2(tmp)
tmp += self.identity(x)
y = nn.functional.relu(tmp, inplace=True)
return y
class MyModel(nn.Module):
"""Faster-RCNN (基于 ResNet 的變種)"""
Anchors = None # 錨點串列,包含 錨點數量 * 形狀數量 的范圍
AnchorSpan = 16 # 錨點之間的距離,應該等于原有長寬 / resnet 輸出長寬
AnchorScales = (1, 2, 4, 6, 8) # 錨點對應區域的縮放比例串列
AnchorAspects = ((1, 1),) # 錨點對應區域的長寬比例串列
AnchorBoxes = len(AnchorScales) * len(AnchorAspects) # 每個錨點對應的形狀數量
def __init__(self):
super().__init__()
# 抽取圖片各個區域特征的 ResNet (除去 AvgPool 和全連接層)
# 和 Fast-RCNN 例子不同的是輸出的長寬會是原有的 1/16,后面會根據錨點與 affine_grid 截取區域
# 此外,為了可以讓模型跑在 4GB 顯存上,這里減少了模型的通道數量
# 注意:
# RPN 使用的模型和標簽分類使用的模型需要分開,否則會出現無法學習 (RPN 總是輸出負) 的問題
self.previous_channels_out = 4
self.rpn_resnet = nn.Sequential(
nn.Conv2d(3, self.previous_channels_out, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(self.previous_channels_out),
nn.ReLU(inplace=True),
self._make_layer(BasicBlock, channels_out=8, num_blocks=2, stride=1),
self._make_layer(BasicBlock, channels_out=16, num_blocks=2, stride=2),
self._make_layer(BasicBlock, channels_out=32, num_blocks=2, stride=2),
self._make_layer(BasicBlock, channels_out=64, num_blocks=2, stride=2),
self._make_layer(BasicBlock, channels_out=128, num_blocks=2, stride=2))
self.previous_channels_out = 4
self.cls_resnet = nn.Sequential(
nn.Conv2d(3, self.previous_channels_out, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(self.previous_channels_out),
nn.ReLU(inplace=True),
self._make_layer(BasicBlock, channels_out=8, num_blocks=2, stride=1),
self._make_layer(BasicBlock, channels_out=16, num_blocks=2, stride=2),
self._make_layer(BasicBlock, channels_out=32, num_blocks=2, stride=2),
self._make_layer(BasicBlock, channels_out=64, num_blocks=2, stride=2),
self._make_layer(BasicBlock, channels_out=128, num_blocks=2, stride=2))
self.features_channels = 128
# 根據區域特征生成各個錨點對應的物件可能性的模型
self.rpn_labels_model = nn.Sequential(
nn.Linear(self.features_channels, self.features_channels),
nn.ReLU(inplace=True),
nn.Dropout(0.1),
nn.Linear(self.features_channels, MyModel.AnchorBoxes*2))
# 根據區域特征生成各個錨點對應的區域偏移的模型
self.rpn_offsets_model = nn.Sequential(
nn.Linear(self.features_channels, self.features_channels),
nn.ReLU(inplace=True),
nn.Dropout(0.1),
nn.Linear(self.features_channels, MyModel.AnchorBoxes*4))
# 選取可能出現物件的區域需要的最小可能性
self.rpn_score_threshold = 0.9
# 每張圖片最多選取的區域串列
self.rpn_max_candidates = 32
# 根據區域截取特征后縮放到的大小
self.pooling_size = 16
# 根據區域特征判斷分類的模型
self.cls_labels_model = nn.Sequential(
nn.Linear(self.features_channels * (self.pooling_size ** 2), self.features_channels),
nn.ReLU(inplace=True),
nn.Dropout(0.1),
nn.Linear(self.features_channels, len(CLASSES)))
# 根據區域特征再次生成區域偏移的模型,注意區域偏移會針對各個分類分別生成
self.cls_offsets_model = nn.Sequential(
nn.Linear(self.features_channels * (self.pooling_size ** 2), self.features_channels*4),
nn.ReLU(inplace=True),
nn.Dropout(0.1),
nn.Linear(self.features_channels*4, len(CLASSES)*4))
def _make_layer(self, block_type, channels_out, num_blocks, stride):
"""創建 resnet 使用的層"""
blocks = []
# 添加第一個塊
blocks.append(block_type(self.previous_channels_out, channels_out, stride))
self.previous_channels_out = channels_out * block_type.expansion
# 添加剩余的塊,剩余的塊固定處理間隔為 1,不會改變長寬
for _ in range(num_blocks-1):
blocks.append(block_type(self.previous_channels_out, self.previous_channels_out, 1))
self.previous_channels_out *= block_type.expansion
return nn.Sequential(*blocks)
@staticmethod
def _generate_anchors():
"""根據錨點和形狀生成錨點范圍串列"""
w, h = IMAGE_SIZE
span = MyModel.AnchorSpan
anchors = []
for x in range(0, w, span):
for y in range(0, h, span):
xcenter, ycenter = x + span / 2, y + span / 2
for scale in MyModel.AnchorScales:
for ratio in MyModel.AnchorAspects:
ww = span * scale * ratio[0]
hh = span * scale * ratio[1]
xx = xcenter - ww / 2
yy = ycenter - hh / 2
xx = max(int(xx), 0)
yy = max(int(yy), 0)
ww = min(int(ww), w - xx)
hh = min(int(hh), h - yy)
anchors.append((xx, yy, ww, hh))
return anchors
@staticmethod
def _roi_crop(features, rois, pooling_size):
"""根據區域截取特征,每次只能處理單張圖片"""
width, height = IMAGE_SIZE
theta = []
results = []
for roi in rois:
x1, y1, w, h = roi
x2, y2 = x1 + w, y1 + h
theta = [[
[
(y2 - y1) / height,
0,
(y2 + y1) / height - 1
],
[
0,
(x2 - x1) / width,
(x2 + x1) / width - 1
]
]]
theta_tensor = torch.tensor(theta)
grid = nn.functional.affine_grid(
theta_tensor,
torch.Size((1, 1, pooling_size, pooling_size)),
align_corners=False).to(device)
result = nn.functional.grid_sample(
features.unsqueeze(0), grid, align_corners=False)
results.append(result)
if not results:
return None
results = torch.cat(results, dim=0)
return results
def forward(self, x):
# ***** 抽取特征部分 *****
# 分別抽取 RPN 和標簽分類使用的特征
# 維度是 B,128,W/16,H/16
rpn_features_original = self.rpn_resnet(x)
# 維度是 B*W/16*H/16,128 (把通道放在最后,用于傳給線性模型)
rpn_features = rpn_features_original.permute(0, 2, 3, 1).reshape(-1, self.features_channels)
# 維度是 B,128,W/16,H/16
cls_features = self.cls_resnet(x)
# ***** 選取區域部分 *****
# 根據區域特征生成各個錨點對應的物件可能性
# 維度是 B,W/16*H/16*AnchorBoxes,2
rpn_labels = self.rpn_labels_model(rpn_features)
rpn_labels = rpn_labels.reshape(
rpn_features_original.shape[0],
rpn_features_original.shape[2] * rpn_features_original.shape[3] * MyModel.AnchorBoxes,
2)
# 根據區域特征生成各個錨點對應的區域偏移
# 維度是 B,W/16*H/16*AnchorBoxes,4
rpn_offsets = self.rpn_offsets_model(rpn_features)
rpn_offsets = rpn_offsets.reshape(
rpn_features_original.shape[0],
rpn_features_original.shape[2] * rpn_features_original.shape[3] * MyModel.AnchorBoxes,
4)
# 選取可能出現物件的區域,并調整區域范圍
with torch.no_grad():
rpn_scores = nn.functional.softmax(rpn_labels, dim=2)[:,:,1]
# 選取可能性最高的部磁區域
rpn_top_scores = torch.topk(rpn_scores, k=self.rpn_max_candidates, dim=1)
rpn_candidates_batch = []
for x in range(0, rpn_scores.shape[0]):
rpn_candidates = []
for score, index in zip(rpn_top_scores.values[x], rpn_top_scores.indices[x]):
# 過濾可能性低于指定閾值的區域
if score.item() < self.rpn_score_threshold:
continue
anchor_box = MyModel.Anchors[index.item()]
offset = rpn_offsets[x,index.item()].tolist()
# 調整區域范圍
candidate_box = adjust_box_by_offset(anchor_box, offset)
rpn_candidates.append((candidate_box, score.item()))
rpn_candidates_batch.append(rpn_candidates)
# ***** 判斷分類部分 *****
cls_output = []
cls_result = []
for index in range(0, cls_features.shape[0]):
rois = [c[0] for c in rpn_candidates_batch[index]]
pooled = MyModel._roi_crop(cls_features[index], rois, self.pooling_size)
if pooled is None:
# 沒有找到可能包含物件的區域
cls_output.append(None)
cls_result.append(None)
continue
pooled = pooled.reshape(pooled.shape[0], -1)
labels = self.cls_labels_model(pooled)
offsets = self.cls_offsets_model(pooled)
cls_output.append((labels, offsets))
# 使用 softmax 判斷可能性最大的分類
labels_max = nn.functional.softmax(labels, dim=1).max(dim=1)
classes = labels_max.indices
classes_scores = labels_max.values
# 根據分類對應的偏移再次調整區域范圍
offsets_map = offsets.reshape(offsets.shape[0] * len(CLASSES), 4)
result = []
for box_index in range(0, classes.shape[0]):
predicted_label = classes[box_index].item()
if predicted_label == 0:
continue # 0 代表 other, 表示非物件
candidate_box = rpn_candidates_batch[index][box_index][0]
offset = offsets_map[box_index * len(CLASSES) + predicted_label].tolist()
predicted_box = adjust_box_by_offset(candidate_box, offset)
# 添加分類與最終預測區域
rpn_score = rpn_candidates_batch[index][box_index][1]
cls_score = classes_scores[box_index].item()
result.append((predicted_label, predicted_box, rpn_score, cls_score))
cls_result.append(result)
# 前面的專案用于學習,最后一項是最終輸出結果
return rpn_labels, rpn_offsets, rpn_candidates_batch, cls_output, cls_result
@staticmethod
def loss_function(predicted, actual):
"""Faster-RCNN 使用的多任務損失計算器"""
rpn_labels, rpn_offsets, rpn_candidates_batch, cls_output, _ = predicted
rpn_labels_losses = []
rpn_offsets_losses = []
cls_labels_losses = []
cls_offsets_losses = []
for batch_index in range(len(actual)):
# 計算 RPN 的損失
(true_boxes_labels,
actual_rpn_labels, actual_rpn_labels_mask,
actual_rpn_offsets, actual_rpn_offsets_mask) = actual[batch_index]
if actual_rpn_labels_mask.shape[0] > 0:
rpn_labels_losses.append(nn.functional.cross_entropy(
rpn_labels[batch_index][actual_rpn_labels_mask],
actual_rpn_labels.to(device)))
if actual_rpn_offsets_mask.shape[0] > 0:
rpn_offsets_losses.append(nn.functional.smooth_l1_loss(
rpn_offsets[batch_index][actual_rpn_offsets_mask],
actual_rpn_offsets.to(device)))
# 計算標簽分類的損失
if cls_output[batch_index] is None:
continue
cls_labels_mask = []
cls_offsets_mask = []
cls_actual_labels = []
cls_actual_offsets = []
cls_predicted_labels, cls_predicted_offsets = cls_output[batch_index]
cls_predicted_offsets_map = cls_predicted_offsets.reshape(-1, 4)
rpn_candidates = rpn_candidates_batch[batch_index]
for box_index, (candidate_box, _) in enumerate(rpn_candidates):
iou_list = [ calc_iou(candidate_box, true_box) for (_, true_box) in true_boxes_labels ]
positive_index = next((index for index, iou in enumerate(iou_list) if iou > IOU_POSITIVE_THRESHOLD), None)
is_negative = all(iou < IOU_NEGATIVE_THRESHOLD for iou in iou_list)
if positive_index is not None:
true_label, true_box = true_boxes_labels[positive_index]
cls_actual_labels.append(true_label)
cls_labels_mask.append(box_index)
# 如果區域正確,則學習真實分類對應的區域偏移
cls_actual_offsets.append(calc_box_offset(candidate_box, true_box))
cls_offsets_mask.append(box_index * len(CLASSES) + true_label)
elif is_negative:
cls_actual_labels.append(0) # 0 代表 other, 表示非物件
cls_labels_mask.append(box_index)
# 如果候選區域與真實區域的重疊率介于兩個閾值之間,則不參與學習
if cls_labels_mask:
cls_labels_losses.append(nn.functional.cross_entropy(
cls_predicted_labels[cls_labels_mask],
torch.tensor(cls_actual_labels).to(device)))
if cls_offsets_mask:
cls_offsets_losses.append(nn.functional.smooth_l1_loss(
cls_predicted_offsets_map[cls_offsets_mask],
torch.tensor(cls_actual_offsets).to(device)))
# 合并損失值
# 注意 loss 不可以使用 += 合并
loss = torch.tensor(.0, requires_grad=True)
loss = loss + torch.mean(torch.stack(rpn_labels_losses))
loss = loss + torch.mean(torch.stack(rpn_offsets_losses))
if cls_labels_losses:
loss = loss + torch.mean(torch.stack(cls_labels_losses))
if cls_offsets_losses:
loss = loss + torch.mean(torch.stack(cls_offsets_losses))
return loss
@staticmethod
def calc_accuracy(actual, predicted):
"""Faster-RCNN 使用的正確率計算器,這里只計算 RPN 與標簽分類的正確率,區域偏移不計算"""
rpn_labels, rpn_offsets, rpn_candidates_batch, cls_output, cls_result = predicted
rpn_acc = 0
cls_acc = 0
for batch_index in range(len(actual)):
# 計算 RPN 的正確率,正樣本和負樣本的正確率分別計算再平均
(true_boxes_labels,
actual_rpn_labels, actual_rpn_labels_mask,
actual_rpn_offsets, actual_rpn_offsets_mask) = actual[batch_index]
a = actual_rpn_labels.to(device)
p = torch.max(rpn_labels[batch_index][actual_rpn_labels_mask], 1).indices
rpn_acc_positive = ((a == 0) & (p == 0)).sum().item() / ((a == 0).sum().item() + 0.00001)
rpn_acc_negative = ((a == 1) & (p == 1)).sum().item() / ((a == 1).sum().item() + 0.00001)
rpn_acc += (rpn_acc_positive + rpn_acc_negative) / 2
# 計算標簽分類的正確率
# 正確率 = 有對應預測區域并且預測分類正確的真實區域數量 / 總真實區域數量
cls_correct = 0
for true_label, true_box in true_boxes_labels:
if cls_result[batch_index] is None:
continue
for predicted_label, predicted_box, _, _ in cls_result[batch_index]:
if calc_iou(predicted_box, true_box) > IOU_POSITIVE_THRESHOLD and predicted_label == true_label:
cls_correct += 1
break
cls_acc += cls_correct / len(true_boxes_labels)
rpn_acc /= len(actual)
cls_acc /= len(actual)
return rpn_acc, cls_acc
@staticmethod
def merge_predicted_result(cls_result):
"""合并預測結果區域"""
# 記錄重疊的結果區域, 結果是 [ [(標簽, 區域, RPN 分數, 標簽識別分數)], ... ]
final_result = []
for label, box, rpn_score, cls_score in cls_result:
for index in range(len(final_result)):
exists_results = final_result[index]
if any(calc_iou(box, r[1]) > IOU_MERGE_THRESHOLD for r in exists_results):
exists_results.append((label, box, rpn_score, cls_score))
break
else:
final_result.append([(label, box, rpn_score, cls_score)])
# 合并重疊的結果區域
# 使用 NMS 演算法: RPN 分數 * 標簽識別分數 最高的區域為結果區域
# 不使用 NMS 演算法: 使用所有區域的合并,并且選取數量最多的標簽 (投票式)
for index in range(len(final_result)):
exists_results = final_result[index]
if USE_NMS_ALGORITHM:
exists_results.sort(key=lambda r: r[2]*r[3])
final_result[index] = exists_results[-1]
else:
cls_groups = defaultdict(lambda: [])
for r in exists_results:
cls_groups[r[0]].append(r)
most_common = sorted(cls_groups.values(), key=len)[-1]
label = most_common[0][0]
box_merged = most_common[0][1]
for _, box, _, _ in most_common[1:]:
box_merged = merge_box(box_merged, box)
rpn_score_mean = sum(x for _, _, x, _ in most_common) / len(most_common)
cls_score_mean = sum(x for _, _, _, x in most_common) / len(most_common)
final_result[index] = (label, box_merged, rpn_score_mean, cls_score_mean)
return final_result
@staticmethod
def fix_predicted_result_from_history(cls_result, history_results):
"""根據歷史結果減少預測結果中的誤判,適用于視頻識別,history_results 應為指定了 maxlen 的 deque"""
# 要求歷史結果中 50% 以上存在類似區域,并且選取歷史結果中最多的分類
history_results.append(cls_result)
final_result = []
if len(history_results) < history_results.maxlen:
# 歷史結果不足,不回傳任何識別結果
return final_result
for label, box, rpn_score, cls_score in cls_result:
# 查找歷史中的近似區域
similar_results = []
for history_result in history_results:
history_result = [(calc_iou(r[1], box), r) for r in history_result]
history_result.sort(key = lambda r: r[0])
if history_result and history_result[-1][0] > IOU_MERGE_THRESHOLD:
similar_results.append(history_result[-1][1])
# 判斷近似區域數量是否過半
if len(similar_results) < history_results.maxlen // 2:
continue
# 選取歷史結果中最多的分類
cls_groups = defaultdict(lambda: [])
for r in similar_results:
cls_groups[r[0]].append(r)
most_common = sorted(cls_groups.values(), key=len)[-1]
# 添加最多的分類中的最新的結果
final_result.append(most_common[-1])
return final_result
MyModel.Anchors = MyModel._generate_anchors()
def save_tensor(tensor, path):
"""保存 tensor 物件到檔案"""
torch.save(tensor, gzip.GzipFile(path, "wb"))
def load_tensor(path):
"""從檔案讀取 tensor 物件"""
return torch.load(gzip.GzipFile(path, "rb"))
def calc_resize_parameters(sw, sh):
"""計算縮放圖片的引數"""
sw_new, sh_new = sw, sh
dw, dh = IMAGE_SIZE
pad_w, pad_h = 0, 0
if sw / sh < dw / dh:
sw_new = int(dw / dh * sh)
pad_w = (sw_new - sw) // 2 # 填充左右
else:
sh_new = int(dh / dw * sw)
pad_h = (sh_new - sh) // 2 # 填充上下
return sw_new, sh_new, pad_w, pad_h
def resize_image(img):
"""縮放圖片,比例不一致時填充"""
sw, sh = img.size
sw_new, sh_new, pad_w, pad_h = calc_resize_parameters(sw, sh)
img_new = Image.new("RGB", (sw_new, sh_new))
img_new.paste(img, (pad_w, pad_h))
img_new = img_new.resize(IMAGE_SIZE)
return img_new
def image_to_tensor(img):
"""轉換圖片物件到 tensor 物件"""
arr = numpy.asarray(img)
t = torch.from_numpy(arr)
t = t.transpose(0, 2) # 轉換維度 H,W,C 到 C,W,H
t = t / 255.0 # 正規化數值使得范圍在 0 ~ 1
return t
def map_box_to_resized_image(box, sw, sh):
"""把原始區域轉換到縮放后的圖片對應的區域"""
x, y, w, h = box
sw_new, sh_new, pad_w, pad_h = calc_resize_parameters(sw, sh)
scale = IMAGE_SIZE[0] / sw_new
x = int((x + pad_w) * scale)
y = int((y + pad_h) * scale)
w = int(w * scale)
h = int(h * scale)
if x + w > IMAGE_SIZE[0] or y + h > IMAGE_SIZE[1] or w == 0 or h == 0:
return 0, 0, 0, 0
return x, y, w, h
def map_box_to_original_image(box, sw, sh):
"""把縮放后圖片對應的區域轉換到縮放前的原始區域"""
x, y, w, h = box
sw_new, sh_new, pad_w, pad_h = calc_resize_parameters(sw, sh)
scale = IMAGE_SIZE[0] / sw_new
x = int(x / scale - pad_w)
y = int(y / scale - pad_h)
w = int(w / scale)
h = int(h / scale)
if x + w > sw or y + h > sh or x < 0 or y < 0 or w == 0 or h == 0:
return 0, 0, 0, 0
return x, y, w, h
def calc_iou(rect1, rect2):
"""計算兩個區域重疊部分 / 合并部分的比率 (intersection over union)"""
x1, y1, w1, h1 = rect1
x2, y2, w2, h2 = rect2
xi = max(x1, x2)
yi = max(y1, y2)
wi = min(x1+w1, x2+w2) - xi
hi = min(y1+h1, y2+h2) - yi
if wi > 0 and hi > 0: # 有重疊部分
area_overlap = wi*hi
area_all = w1*h1 + w2*h2 - area_overlap
iou = area_overlap / area_all
else: # 沒有重疊部分
iou = 0
return iou
def calc_box_offset(candidate_box, true_box):
"""計算候選區域與實際區域的偏移值"""
# 這里計算出來的偏移值基于比例,而不受具體位置和大小影響
# w h 使用 log 是為了減少過大的值的影響
x1, y1, w1, h1 = candidate_box
x2, y2, w2, h2 = true_box
x_offset = (x2 - x1) / w1
y_offset = (y2 - y1) / h1
w_offset = math.log(w2 / w1)
h_offset = math.log(h2 / h1)
return (x_offset, y_offset, w_offset, h_offset)
def adjust_box_by_offset(candidate_box, offset):
"""根據偏移值調整候選區域"""
# exp 需要限制值小于 log(16),如果值過大可能會引發 OverflowError
x1, y1, w1, h1 = candidate_box
x_offset, y_offset, w_offset, h_offset = offset
x2 = min(IMAGE_SIZE[0]-1, max(0, w1 * x_offset + x1))
y2 = min(IMAGE_SIZE[1]-1, max(0, h1 * y_offset + y1))
w2 = min(IMAGE_SIZE[0]-x2, max(1, math.exp(min(w_offset, 2.78)) * w1))
h2 = min(IMAGE_SIZE[1]-y2, max(1, math.exp(min(h_offset, 2.78)) * h1))
return (x2, y2, w2, h2)
def merge_box(box_a, box_b):
"""合并兩個區域"""
x1, y1, w1, h1 = box_a
x2, y2, w2, h2 = box_b
x = min(x1, x2)
y = min(y1, y2)
w = max(x1 + w1, x2 + w2) - x
h = max(y1 + h1, y2 + h2) - y
return (x, y, w, h)
def prepare_save_batch(batch, image_tensors, image_boxes_labels):
"""準備訓練 - 保存單個批次的資料"""
# 按索引值串列生成輸入和輸出 tensor 物件的函式
def split_dataset(indices):
image_in = []
boxes_labels_out = {}
for new_image_index, original_image_index in enumerate(indices.tolist()):
image_in.append(image_tensors[original_image_index])
boxes_labels_out[new_image_index] = image_boxes_labels[original_image_index]
tensor_image_in = torch.stack(image_in) # 維度: B,C,W,H
return tensor_image_in, boxes_labels_out
# 切分訓練集 (80%),驗證集 (10%) 和測驗集 (10%)
random_indices = torch.randperm(len(image_tensors))
training_indices = random_indices[:int(len(random_indices)*0.8)]
validating_indices = random_indices[int(len(random_indices)*0.8):int(len(random_indices)*0.9):]
testing_indices = random_indices[int(len(random_indices)*0.9):]
training_set = split_dataset(training_indices)
validating_set = split_dataset(validating_indices)
testing_set = split_dataset(testing_indices)
# 保存到硬碟
save_tensor(training_set, f"data/training_set.{batch}.pt")
save_tensor(validating_set, f"data/validating_set.{batch}.pt")
save_tensor(testing_set, f"data/testing_set.{batch}.pt")
print(f"batch {batch} saved")
def prepare():
"""準備訓練"""
# 資料集轉換到 tensor 以后會保存在 data 檔案夾下
if not os.path.isdir("data"):
os.makedirs("data")
# 加載圖片和圖片對應的區域與分類串列
# { (路徑, 是否左右翻轉): [ 區域與分類, 區域與分類, .. ] }
# 同一張圖片左右翻轉可以生成一個新的資料,讓資料量翻倍
box_map = defaultdict(lambda: [])
for filename in os.listdir(DATASET_1_IMAGE_DIR):
# 從第一個資料集加載
xml_path = os.path.join(DATASET_1_ANNOTATION_DIR, filename.split(".")[0] + ".xml")
if not os.path.isfile(xml_path):
continue
tree = ET.ElementTree(file=xml_path)
objects = tree.findall("object")
path = os.path.join(DATASET_1_IMAGE_DIR, filename)
for obj in objects:
class_name = obj.find("name").text
x1 = int(obj.find("bndbox/xmin").text)
x2 = int(obj.find("bndbox/xmax").text)
y1 = int(obj.find("bndbox/ymin").text)
y2 = int(obj.find("bndbox/ymax").text)
if class_name == "mask_weared_incorrect":
# 佩戴口罩不正確的樣本數量太少 (只有 123),模型無法學習,這里全合并到戴口罩的樣本
class_name = "with_mask"
box_map[(path, False)].append((x1, y1, x2-x1, y2-y1, CLASSES_MAPPING[class_name]))
box_map[(path, True)].append((x1, y1, x2-x1, y2-y1, CLASSES_MAPPING[class_name]))
df = pandas.read_csv(DATASET_2_BOX_CSV_PATH)
for row in df.values:
# 從第二個資料集加載,這個資料集只包含沒有帶口罩的圖片
filename, width, height, x1, y1, x2, y2 = row[:7]
path = os.path.join(DATASET_2_IMAGE_DIR, filename)
box_map[(path, False)].append((x1, y1, x2-x1, y2-y1, CLASSES_MAPPING["without_mask"]))
box_map[(path, True)].append((x1, y1, x2-x1, y2-y1, CLASSES_MAPPING["without_mask"]))
# 打亂資料集 (因為第二個資料集只有不戴口罩的圖片)
box_list = list(box_map.items())
random.shuffle(box_list)
print(f"found {len(box_list)} images")
# 保存圖片和圖片對應的分類與區域串列
batch_size = 20
batch = 0
image_tensors = [] # 圖片串列
image_boxes_labels = {} # 圖片對應的真實區域與分類串列,和候選區域與區域偏移
for (image_path, flip), original_boxes_labels in box_list:
with Image.open(image_path) as img_original: # 加載原始圖片
sw, sh = img_original.size # 原始圖片大小
if flip:
img = resize_image(img_original.transpose(Image.FLIP_LEFT_RIGHT)) # 翻轉然后縮放圖片
else:
img = resize_image(img_original) # 縮放圖片
image_index = len(image_tensors) # 圖片在批次中的索引值
image_tensors.append(image_to_tensor(img)) # 添加圖片到串列
true_boxes_labels = [] # 圖片對應的真實區域與分類串列
# 添加真實區域與分類串列
for box_label in original_boxes_labels:
x, y, w, h, label = box_label
if flip: # 翻轉坐標
x = sw - x - w
x, y, w, h = map_box_to_resized_image((x, y, w, h), sw, sh) # 縮放實際區域
if w < 20 or h < 20:
continue # 縮放后區域過小
# 檢查計算是否有問題
# child_img = img.copy().crop((x, y, x+w, y+h))
# child_img.save(f"{os.path.basename(image_path)}_{x}_{y}_{w}_{h}_{label}.png")
true_boxes_labels.append((label, (x, y, w, h)))
# 如果圖片中的所有區域都過小則跳過
if not true_boxes_labels:
image_tensors.pop()
image_index = len(image_tensors)
continue
# 根據錨點串列尋找候選區域,并計算區域偏移
actual_rpn_labels = []
actual_rpn_labels_mask = []
actual_rpn_offsets = []
actual_rpn_offsets_mask = []
positive_index_set = set()
for index, anchor_box in enumerate(MyModel.Anchors):
# 如果候選區域和任意一個實際區域重疊率大于閾值,則認為是正樣本
# 如果候選區域和所有實際區域重疊率都小于閾值,則認為是負樣本
# 重疊率介于兩個閾值之間的區域不參與學習
iou_list = [ calc_iou(anchor_box, true_box) for (_, true_box) in true_boxes_labels ]
positive_index = next((index for index, iou in enumerate(iou_list) if iou > IOU_POSITIVE_THRESHOLD), None)
is_negative = all(iou < IOU_NEGATIVE_THRESHOLD for iou in iou_list)
if positive_index is not None:
positive_index_set.add(positive_index)
actual_rpn_labels.append(1)
actual_rpn_labels_mask.append(index)
# 只有包含物件的區域參需要調整偏移
true_box = true_boxes_labels[positive_index][1]
actual_rpn_offsets.append(calc_box_offset(anchor_box, true_box))
actual_rpn_offsets_mask.append(index)
elif is_negative:
actual_rpn_labels.append(0)
actual_rpn_labels_mask.append(index)
# 輸出找不到候選區域的真實區域,調整錨點生成引數時使用
for index in range(len(true_boxes_labels)):
if index not in positive_index_set:
print("no candidate box found for:", true_boxes_labels[index][1])
# 如果一個候選區域都找不到則跳過
if not positive_index_set:
image_tensors.pop()
image_index = len(image_tensors)
continue
image_boxes_labels[image_index] = (
true_boxes_labels,
torch.tensor(actual_rpn_labels, dtype=torch.long),
torch.tensor(actual_rpn_labels_mask, dtype=torch.long),
torch.tensor(actual_rpn_offsets, dtype=torch.float),
torch.tensor(actual_rpn_offsets_mask, dtype=torch.long))
# 保存批次
if len(image_tensors) >= batch_size:
prepare_save_batch(batch, image_tensors, image_boxes_labels)
image_tensors.clear()
image_boxes_labels.clear()
batch += 1
# 保存剩余的批次
if len(image_tensors) > 10:
prepare_save_batch(batch, image_tensors, image_boxes_labels)
def train():
"""開始訓練"""
# 創建模型實體
model = MyModel().to(device)
# 創建多任務損失計算器
loss_function = MyModel.loss_function
# 創建引數調整器
optimizer = torch.optim.Adam(model.parameters())
# 記錄訓練集和驗證集的正確率變化
training_rpn_accuracy_history = []
training_cls_accuracy_history = []
validating_rpn_accuracy_history = []
validating_cls_accuracy_history = []
# 記錄最高的驗證集正確率
validating_rpn_accuracy_highest = -1
validating_rpn_accuracy_highest_epoch = 0
validating_cls_accuracy_highest = -1
validating_cls_accuracy_highest_epoch = 0
# 讀取批次的工具函式
def read_batches(base_path):
for batch in itertools.count():
path = f"{base_path}.{batch}.pt"
if not os.path.isfile(path):
break
x, y = load_tensor(path)
yield x.to(device), y
# 計算正確率的工具函式
calc_accuracy = MyModel.calc_accuracy
# 開始訓練程序
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根據訓練集訓練并修改引數
# 切換模型到訓練模式,將會啟用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.train()
training_rpn_accuracy_list = []
training_cls_accuracy_list = []
for batch_index, batch in enumerate(read_batches("data/training_set")):
# 劃分輸入和輸出
batch_x, batch_y = batch
# 計算預測值
predicted = model(batch_x)
# 計算損失
loss = loss_function(predicted, batch_y)
# 從損失自動微分求導函式值
loss.backward()
# 使用引數調整器調整引數
optimizer.step()
# 清空導函式值
optimizer.zero_grad()
# 記錄這一個批次的正確率,torch.no_grad 代表臨時禁用自動微分功能
with torch.no_grad():
training_batch_rpn_accuracy, training_batch_cls_accuracy = calc_accuracy(batch_y, predicted)
# 輸出批次正確率
training_rpn_accuracy_list.append(training_batch_rpn_accuracy)
training_cls_accuracy_list.append(training_batch_cls_accuracy)
print(f"epoch: {epoch}, batch: {batch_index}: " +
f"batch rpn accuracy: {training_batch_rpn_accuracy}, cls accuracy: {training_batch_cls_accuracy}")
training_rpn_accuracy = sum(training_rpn_accuracy_list) / len(training_rpn_accuracy_list)
training_cls_accuracy = sum(training_cls_accuracy_list) / len(training_cls_accuracy_list)
training_rpn_accuracy_history.append(training_rpn_accuracy)
training_cls_accuracy_history.append(training_cls_accuracy)
print(f"training rpn accuracy: {training_rpn_accuracy}, cls accuracy: {training_cls_accuracy}")
# 檢查驗證集
# 切換模型到驗證模式,將會禁用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.eval()
validating_rpn_accuracy_list = []
validating_cls_accuracy_list = []
for batch in read_batches("data/validating_set"):
batch_x, batch_y = batch
predicted = model(batch_x)
validating_batch_rpn_accuracy, validating_batch_cls_accuracy = calc_accuracy(batch_y, predicted)
validating_rpn_accuracy_list.append(validating_batch_rpn_accuracy)
validating_cls_accuracy_list.append(validating_batch_cls_accuracy)
# 釋放 predicted 占用的顯存避免顯存不足的錯誤
predicted = None
validating_rpn_accuracy = sum(validating_rpn_accuracy_list) / len(validating_rpn_accuracy_list)
validating_cls_accuracy = sum(validating_cls_accuracy_list) / len(validating_cls_accuracy_list)
validating_rpn_accuracy_history.append(validating_rpn_accuracy)
validating_cls_accuracy_history.append(validating_cls_accuracy)
print(f"validating rpn accuracy: {validating_rpn_accuracy}, cls accuracy: {validating_cls_accuracy}")
# 記錄最高的驗證集正確率與當時的模型狀態,判斷是否在 20 次訓練后仍然沒有重繪記錄
# 只依據標簽分類正確率判斷,因為標簽分類正確率同時基于 RPN 正確率
if validating_cls_accuracy > validating_cls_accuracy_highest:
validating_rpn_accuracy_highest = validating_rpn_accuracy
validating_rpn_accuracy_highest_epoch = epoch
validating_cls_accuracy_highest = validating_cls_accuracy
validating_cls_accuracy_highest_epoch = epoch
save_tensor(model.state_dict(), "model.pt")
print("highest cls validating accuracy updated")
elif (epoch - validating_rpn_accuracy_highest_epoch > 20 and
epoch - validating_cls_accuracy_highest_epoch > 20):
# 在 20 次訓練后仍然沒有重繪記錄,結束訓練
print("stop training because highest validating accuracy not updated in 20 epoches")
break
# 使用達到最高正確率時的模型狀態
print(f"highest rpn validating accuracy: {validating_rpn_accuracy_highest}",
f"from epoch {validating_rpn_accuracy_highest_epoch}")
print(f"highest cls validating accuracy: {validating_cls_accuracy_highest}",
f"from epoch {validating_cls_accuracy_highest_epoch}")
model.load_state_dict(load_tensor("model.pt"))
# 檢查測驗集
testing_rpn_accuracy_list = []
testing_cls_accuracy_list = []
for batch in read_batches("data/testing_set"):
batch_x, batch_y = batch
predicted = model(batch_x)
testing_batch_rpn_accuracy, testing_batch_cls_accuracy = calc_accuracy(batch_y, predicted)
testing_rpn_accuracy_list.append(testing_batch_rpn_accuracy)
testing_cls_accuracy_list.append(testing_batch_cls_accuracy)
testing_rpn_accuracy = sum(testing_rpn_accuracy_list) / len(testing_rpn_accuracy_list)
testing_cls_accuracy = sum(testing_cls_accuracy_list) / len(testing_cls_accuracy_list)
print(f"testing rpn accuracy: {testing_rpn_accuracy}, cls accuracy: {testing_cls_accuracy}")
# 顯示訓練集和驗證集的正確率變化
pyplot.plot(training_rpn_accuracy_history, label="training_rpn_accuracy")
pyplot.plot(training_cls_accuracy_history, label="training_cls_accuracy")
pyplot.plot(validating_rpn_accuracy_history, label="validating_rpn_accuracy")
pyplot.plot(validating_cls_accuracy_history, label="validating_cls_accuracy")
pyplot.ylim(0, 1)
pyplot.legend()
pyplot.show()
def eval_model():
"""使用訓練好的模型識別圖片"""
# 創建模型實體,加載訓練好的狀態,然后切換到驗證模式
model = MyModel().to(device)
model.load_state_dict(load_tensor("model.pt"))
model.eval()
# 詢問圖片路徑,并顯示所有可能是人臉的區域
while True:
try:
image_path = input("Image path: ")
if not image_path:
continue
# 構建輸入
with Image.open(image_path) as img_original: # 加載原始圖片
sw, sh = img_original.size # 原始圖片大小
img = resize_image(img_original) # 縮放圖片
img_output = img_original.copy() # 復制圖片,用于后面添加標記
tensor_in = image_to_tensor(img)
# 預測輸出
cls_result = model(tensor_in.unsqueeze(0).to(device))[-1][0]
final_result = MyModel.merge_predicted_result(cls_result)
# 標記在圖片上
draw = ImageDraw.Draw(img_output)
for label, box, rpn_score, cls_score in final_result:
x, y, w, h = map_box_to_original_image(box, sw, sh)
score = rpn_score * cls_score
color = "#00FF00" if CLASSES[label] == "with_mask" else "#FF0000"
draw.rectangle((x, y, x+w, y+h), outline=color)
draw.text((x, y-10), CLASSES[label], fill=color)
draw.text((x, y+h), f"{score:.2f}", fill=color)
print((x, y, w, h), CLASSES[label], rpn_score, cls_score)
img_output.save("img_output.png")
print("saved to img_output.png")
print()
except Exception as e:
print("error:", e)
def eval_video():
"""使用訓練好的模型識別視頻"""
# 創建模型實體,加載訓練好的狀態,然后切換到驗證模式
model = MyModel().to(device)
model.load_state_dict(load_tensor("model.pt"))
model.eval()
# 詢問視頻路徑,給可能是人臉的區域添加標記并保存新視頻
import cv2
font = ImageFont.truetype("FreeMonoBold.ttf", 20)
while True:
try:
video_path = input("Video path: ")
if not video_path:
continue
# 讀取輸入視頻
video = cv2.VideoCapture(video_path)
# 獲取每秒的幀數
fps = int(video.get(cv2.CAP_PROP_FPS))
# 獲取視頻長寬
size = (int(video.get(cv2.CAP_PROP_FRAME_WIDTH)), int(video.get(cv2.CAP_PROP_FRAME_HEIGHT)))
# 創建輸出視頻
video_output_path = os.path.join(
os.path.dirname(video_path),
os.path.splitext(os.path.basename(video_path))[0] + ".output.avi")
result = cv2.VideoWriter(video_output_path, cv2.VideoWriter_fourcc(*"XVID"), fps, size)
# 用于減少誤判的歷史結果
history_results = deque(maxlen = fps // 2)
# 逐幀處理
count = 0
while(True):
ret, frame = video.read()
if not ret:
break
# opencv 使用的是 BGR, Pillow 使用的是 RGB, 需要轉換通道順序
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 構建輸入
img_original = Image.fromarray(frame_rgb) # 加載原始圖片
sw, sh = img_original.size # 原始圖片大小
img = resize_image(img_original) # 縮放圖片
img_output = img_original.copy() # 復制圖片,用于后面添加標記
tensor_in = image_to_tensor(img)
# 預測輸出
cls_result = model(tensor_in.unsqueeze(0).to(device))[-1][0] or []
cls_result = MyModel.merge_predicted_result(cls_result)
# 根據歷史結果減少誤判
final_result = MyModel.fix_predicted_result_from_history(cls_result, history_results)
# 標記在圖片上
draw = ImageDraw.Draw(img_output)
for label, box, rpn_score, cls_score in final_result:
x, y, w, h = map_box_to_original_image(box, sw, sh)
score = rpn_score * cls_score
color = "#00FF00" if CLASSES[label] == "with_mask" else "#FF0000"
draw.rectangle((x, y, x+w, y+h), outline=color, width=3)
draw.text((x, y-20), CLASSES[label], fill=color, font=font)
draw.text((x, y+h), f"{score:.2f}", fill=color, font=font)
# 寫入幀到輸出視頻
frame_rgb_annotated = numpy.asarray(img_output)
frame_bgr_annotated = cv2.cvtColor(frame_rgb_annotated, cv2.COLOR_RGB2BGR)
result.write(frame_bgr_annotated)
count += 1
if count % fps == 0:
print(f"handled {count//fps}s")
video.release()
result.release()
cv2.destroyAllWindows()
print(f"saved to {video_output_path}")
print()
except Exception as e:
raise
print("error:", e)
def main():
"""主函式"""
if len(sys.argv) < 2:
print(f"Please run: {sys.argv[0]} prepare|train|eval")
exit()
# 給亂數生成器分配一個初始值,使得每次運行都可以生成相同的亂數
# 這是為了讓程序可重現,你也可以選擇不這樣做
random.seed(0)
torch.random.manual_seed(0)
# 根據命令列引數選擇操作
operation = sys.argv[1]
if operation == "prepare":
prepare()
elif operation == "train":
train()
elif operation == "eval":
eval_model()
elif operation == "eval-video":
eval_video()
else:
raise ValueError(f"Unsupported operation: {operation}")
if __name__ == "__main__":
main()
訓練以后使用 python3 example.py eval-video 即可識別視頻,
如果你想要現成訓練好的模型可以下載這個檔案,改名為 model.pt 然后放在以上代碼的所在的目錄下,
視頻識別結果
以下是視頻識別結果??:
視頻 1
視頻 2
我還把相同視頻傳到騰訊視頻上了,但審核需要幾天,蛋疼,
寫在最后
這篇介紹了如何改進 Faster-RCNN 模型來更準確的識別人臉位置與是否戴口罩,不過中國目前已經開始接種疫苗了,我附近的鎮區也出現疫苗接種點了(還是免費的),相信很快所有人都不再需要戴口罩,國家應對疫情的表現非常令人驕傲,喊一句:厲害了我的國??!
下一篇將會介紹 YOLO 模型,場景同樣是識別人臉位置與是否戴口罩,寫完就會研究其他東西去了??,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/245093.html
標籤:其他