資料的深度分析
機器學習與資料挖掘
從基礎資料計算一些聚集統計量(Aggregations),生成報表(Reports),觀察同比/環比的變化,以及通過資料透視表(Pivotal Table),從不同維度觀察資料的匯總資訊,只能算是對資料的簡單分析,
要從資料里面挖掘和提取隱含的模式和規律,簡單分析是無能為力的,我們需要在資料上運行,更加復雜的演算法,這些演算法主要是機器學習和資料挖掘演算法,
什么是機器學習
–從廣義上來說,機器學習是一種能夠賦予機器學習的能力,讓它完成直接編程無法完成的功能
的方法,
–但從實踐上來說,機器學習是一種通過利用資料,訓練出模型,然后使用模型預測的一種方
法,由此可見,資料對于機器學習的意義,可以說資料是原材料,機器學習是加工工具,模型是
產品,我們可以利用這個產品做預測,指導未來的決策,
什么是資料挖掘
?資料挖掘,可以認為是機器學習演算法在資料庫上的應用,很多資料挖掘中的演算法是機器學習算
法在資料庫中的優化,
–但是,資料挖掘能夠形成自己的學術圈,是因為它也貢獻了獨特的演算法,其中最著名的是關聯
規則分析方法Apriori
機器學習的目的
機器學習的目的是分類和預測,所謂分類是根據輸入資料,判別這些資料隸屬于哪個類別
(Category),而預測則是根據輸入資料,計算一個輸出值(Numeric),輸入資料一般為一個向
量,也稱為特征(Feature),輸出則是一個分類或者一個數值
機器學習的基本程序
機器學習的基本程序是用訓練資料(包含輸入資料和預期輸出的分類或者數值)訓練一個模型
(Model),利用這個模型,就可以對新的實體資料(Instances)進行分類和計算一個預測值
監督、非監督、半監督學習
監督學習是機器學習的一種類別,訓練資料由輸入特征(features)和預期的輸出構成,輸出可
以是一個連續的值(稱為回歸分析),或者是一個分類的類別標簽(稱為分類);
<hr/>
無監督學習與監督學習的區別是,它沒有訓練樣本,直接對資料進行建模;
<hr/>
半監督學習,是監督學習與無監督學習相結合的一種學習方法
具體的機器學習演算法
決策樹
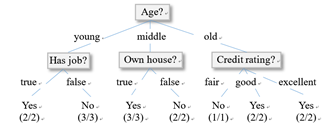
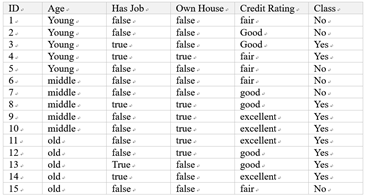
在機器學習中,決策樹是一個預測模型,它表示物件屬性(比如貸款用戶的年齡、是否有作業、
是否有房產、信用評分等)和物件值(是否批準其貸款申請)之間的一種映射,決策樹中的非葉子
節點,表示物件屬性的判斷條件,其分支表示符合節點條件的所有物件,樹的葉子節點表示物件
所屬的預測結果
決策樹構造程序
決策樹的創建從根節點開始,也就是需要確定一個屬性,根據不同記錄在該屬性上的取值,對所
有記錄進行劃分,接下來,對每個分支重復這個程序,即對每個分支,選擇一個另外一個未參與
樹的創建的屬性,繼續對樣本進行劃分,一直到某個分支上的樣本都屬于同一類(或者隸屬該路
徑的樣本大部分屬于同一類),
屬性的選擇也稱為特征選擇,特征選擇的目標,是使得分類后的資料集比較純,
其中一個應用廣泛的度量函式,是資訊增益(Information Gain),
聚類分析K - means演算法
–K-Means演算法是最簡單的一種聚類演算法,屬于無監督學習演算法,
–假設我們的樣本是{x^((1)),x^((2)),…,x^((m))},每個x^((i))∈R^n,現在用戶給定一個
K值,要求將樣本聚類(Clustering)成K個類簇(Cluster),

缺點
(1) K-means演算法中K是事先給定的,一個合適的K值難以估計,
(2) 在K-means演算法中,首先需要根據初始類簇中心來確定一個初始劃分,然后對初始劃分進行
優化,這個初始類簇中心的選擇,對聚類結果有較大的影響,一旦初始值選擇的不好,可能無法
得到有效的聚類結果,可以使用遺傳演算法(Genetic Algorithm),幫助選擇合適的初始類簇中
心,
(3) 演算法需要不斷地進行樣本分類調整,不斷地計算調整后的新的聚類中心,因此當資料量非常
大時,演算法的時間開銷是非常大的,
分類演算法支持向量機SVM
支持向量機以其在解決小樣本、非線性、以及高維模式識別中,表現出來的特有優勢,獲得廣泛的應用,其應用領域包括文本分類、影像識別等,
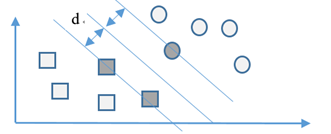
支持向量
我們尋找分類函式y=f(x)=𝜔^𝑇 𝑥+𝑏,超平面上的點代入這個分類函式,得到f(x)=0;超平面一
邊的資料點代入分類函式,得到f(x)=1;超平面另外一邊的資料點代入分類函式,得到
f(x)=-1,在二維平面上,這個分類函式對應一根直線y=f(x)=ax+b,
如何確定w和b呢?答案是尋找一個超平面,它到兩個類別資料點的距離都盡可能大,這樣的超平
面為最優的超平面
核函式技巧
有時候兩個資料點集,在低維空間中,我們無法找到一個超平面來進行清晰的劃分,如圖中的二
維平面上的兩類資料點,找不到一根直線把它們劃分開,SVM資料分析方法里,有一個核函式
(Kernel Function)技巧,可以巧妙地解決這個問題,通過核函式,可以把低維空間的資料點
(向量)映射到高維空間的資料點,經過映射以后,兩類資料點在高維空間里,可以有一個超平面
把它們分開,
例外值的處理
超平面本身是由少數幾個支持向量(Support Vector)確定的,未考慮Outlier(離群值,例外
值)的影響,
這個問題,通過在模型中引入松弛變數(Relax Variable)來解決,松弛變數是為了糾正或約束
少量“不安分”或脫離集體不好歸類的資料點的因子,
關聯規則分析
關聯規則是形如X→Y的蘊含式,表示通過X可以“推匯出”Y,X稱為關聯規則的左部(Left Hand Side, LHS),Y稱為關聯規則的右部(Right Hand Side, RHS),
關聯規則分析,最典型的例子是購物籃分析,通過關聯規則分析,能夠發現顧客每次購物交易的
購物籃中的不同商品之間的關聯,從而了解客戶的消費習慣,讓商家能夠了解那些商品被客戶同
時購買,從而幫助他們制定更好的營銷方案
在購物籃分析結果里,“尿布→啤酒”表示客戶在購買尿布的同時,有很大的可能性購買啤酒,
關聯規則有兩個指標,分別是支持度(Support)和置信度(Confidence)
關聯規則A->B的支持度support=P(AB),指的是事件A和事件B同時發生的概率,
置信度confidence=P(B|A)=P(AB)/P(A),指的是是發生事件A的基礎上,發生事件B的概率,
比如,如果“尿布à啤酒”關聯規則的支持度為30%,置信度為60%,那么就表示所有的商品交易中,30%交易同時購買了尿布和啤酒,而在購買尿布的交易中,60%的交易同時購買了啤酒,
挖掘關聯規則的主流演算法為Apriori演算法,它的基本原理是,在資料集中找出同時出現概率符合預定義(Pre-defined)支持度的頻繁項集,而后從以上頻繁項集中,找出符合預定義置信度的關聯規則,
EM(Expectation–Maximization)演算法
EM (Expectation Maximization, 最大期望)演算法,是在概率模型(Probability Distribution Model)中,尋找引數的最大似然估計的演算法,其中,這個概率模型包含無法觀測的隱藏變數(Latent Variables),EM演算法一般用于機器學習的聚類(Clustering),
協同過濾推薦演算法(Collaborative Filtering Recommendation)
推薦演算法能夠根據用戶的喜好,向用戶推薦商品或者服務,在電子商務 (E-commerce,比如Amazon等)網站、音樂、電影、和圖書分享網站,推薦引擎取得了巨大的成功
(1) 根據推薦系統是否為不同用戶推薦不同的物品或者內容,推薦系統分為個性化推薦系統和大眾化推薦系統,
(2) 根據推薦系統使用的資料源,推薦系統分為基于內容的推薦系統(Content-based
Recommendation,它根據推薦物品或內容的描述,發現物品或者內容的相關性,進行推薦)
基于人口統計學的推薦(Demographic-based Recommendation,它根據用戶的資訊,發現用
戶的之間的相關程度,進行推薦)、基于協同過濾的推薦(Collaborative Filtering-based
Recommendation,它根據用戶對物品或者資訊的偏好,發現物品或者內容本身的相關性,或者
是發現用戶的相關性,進行推薦),
(3) 根據推薦模型的基本技術原理,推薦系統分為基于用戶和物品評價矩陣的推薦系統、基于
關聯規則的推薦系統(Rule-based Recommendation,它通過關聯規則的挖掘,找到哪些物品
經常被同時購買,或者用戶購買了一些物品后通常會購買哪些其它的物品,進行推薦)、基于模
型的推薦(Model-based Recommendation,將已有的用戶喜好資訊作為訓練樣本,訓練出一個
模型,用于預測預測用戶的喜好,以后用戶在進入系統的時候,可以基于這個模型進行推薦),
基于模型的推薦,需要考慮如何利用用戶近期或者實時的喜好資訊,更新訓練好的模型,提高
推薦的準確度,
基于人口統計學的推薦機制(Demographic-based Recommendation)
基于人口統計學的推薦機制,是一種最易于實作的推薦方法,它根據用戶的基本資訊發現用戶的相關程 度,然后將相似用戶喜愛的其它物品,推薦給當前用戶,
具體來講,系統對每個用戶都有一個用戶畫像(Profile)的建模,這個畫像包括用戶的基本資訊比如年齡、性別等,然后,系統根據用戶的Profile計算用戶的相似度,相似用戶稱為“近鄰”,
(1) 對于系統的新用戶來講,系統沒有“冷啟動”(Cold Start)問題,因為它不使用用戶對物品的喜好歷史資料,
(2) 該方法不依賴于物品資料,所以它是領域獨立的(domain-independent),但是該方法過于粗糙,對品味要求較高的領域不適用,比如圖書、電影、和音樂等領域,推薦效果不是很好
基于內容的推薦
基于內容的推薦,其基本思路是,根據物品或者內容的描述資訊,發現它們之間的相關性,然后基于用戶以往的喜好歷史記錄,推薦相似的物品或者內容,
比如在電影推薦系統里,我們首先需要對電影的描述資訊(元資料)進行建模,這個模型可以包含電影的型別、電影的導演、電影的演員等,對于具體用戶,根據他歷史上喜歡看的電影,可以給他推薦類似的電影,這里就需要上述的描述資訊,計算電影之間的相似度,
基于內容的推薦,存在若干問題:
(1) 推薦的質量依賴于對物品模型的完整和全面程度,
(2) 物品相似度的分析沒有考慮人對物品的態度,
(3) 需要基于用戶以往的喜好歷史做出推薦,于是存在“冷啟動”問題,
雖然這個方法有這些不足,但是仍然在電影、音樂、圖書推薦應用中,取得成功,
基于協同過濾的推薦
基于協同過濾的推薦,是根據用戶對物品或者資訊的偏好,發現物品或者內容本身的相關性,或者是發現用戶的相關性,然后再基于這些相關性進行推薦,
基于協同過濾的推薦可以分為三個子類:
(1) 基于用戶的推薦(User-based Recommendation),
(2) 基于物品的推薦(Item-based Recommendation),
(3) 基于模型的推薦(Model-based Recommendation),
基于用戶的協同過濾推薦
基于用戶的協同過濾推薦,是根據用戶對物品或者內容的偏好,發現與某個用戶偏好相似的“近鄰”用戶群(可以使用KNN演算法進行計算),然后基于這K個近鄰的歷史偏好資訊,為該用戶進行推薦,
以電商領域為例,比如我們現在要給用戶C進行商品推薦,我們首先進行用戶間相似度的計算,發現用戶C和用戶D和E的相似度較高,也就是用戶D和E是用戶C的“K最近鄰”,于是,我們可以給用戶C推薦用戶D和E瀏覽或者購買過的商品,需要注意的是,我們只需推薦用戶C還沒有瀏覽或者購買過的商品即可,對于用戶C瀏覽或者購買過的商品,無需重復推薦,
基于專案的協同過濾推薦
基于專案的協同過濾推薦,是使用所有用戶對物品或者內容的偏好資訊,發現物品和物品之間的相似度,然后根據用戶的歷史偏好資訊,將類似的物品推薦給用戶,
以電商領域為例,當需要對用戶C基于商品3進行商品推薦時,首先尋找商品3的“K最近鄰”,也就是和商品3相似的商品,比如商品3的K最近鄰為商品4和商品5,然后計算商品4、5與其它商品的相似度,并且進行排序,然后給用戶C推薦新的商品,也就是用戶C沒有瀏覽或者購買過的商品,
基于協同過濾的推薦機制,是應用最為廣泛的推薦機制,它的優勢包括:
(1) 它無需對用戶、物品進行嚴格的建模,它是領域無關的,
(2) 該方法支持用戶發現潛在的興趣偏好,
但是我們也需要了解到,該方法存在若干問題:
(1) 該方法基于歷史資料做出推薦,對新用戶和新物品,存在“冷啟動”問題,
(2) 推薦效果,依賴于用戶歷史偏好資料的資料量及其準確性,
(3) 少部分人的錯誤偏好,可能會對推薦的準確度產生很大的影響,
(4) 不能照顧特殊偏好和品位的用戶,不能給予精細的推薦,
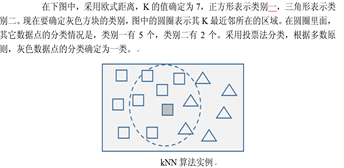
kNN(k近鄰)演算法
kNN(Near Neighbors)演算法是一種分類演算法,它根據某個資料點周圍的最近K個鄰居的類別標簽情況,賦予這個資料點一個類別,具體的程序是,給定一個測驗資料點,計算它與資料集中其它資料點的距離;找出距離最近的K個資料點,作為該資料點的近鄰資料點集合;根據這K個近鄰所歸屬的類別,來確定當前資料點的類別,
樸素Bayes(Naive Bayes)演算法
貝葉斯定理
P(B|A)表示在事件A已經發生的前提下,事件B發生的概率,稱為事件A發生情況下,事件B發生的“條件概率”

AdaBoost演算法
整個AdaBoost 迭代演算法包含3個主要步驟
(1) 初始化訓練資料的權值分布,如果有M個樣本,則每一個訓練樣本最開始時都被賦予相同的權值:1/M,
(2) 訓練弱分類器,在訓練程序中,如果某個樣本點已經被準確地分類,那么在構造下一個訓練集中,它的權值就被降低;相反,如果某個樣本點沒有被準確地分類,那么它的權值就得到提高,在第t輪訓練結束后,根據得到的弱分類器ht的性能,計算該分類器對應的權值α_t,并由ht的在訓練集上的分類結果對權重向量WiàWi+1進行更新,接著,權值更新過的樣本集被用于訓練下一個分類器,整個訓練程序如此迭代地進行下去,
(3) 將各個訓練得到的弱分類器組合成強分類器,各個弱分類器的訓練程序結束后,加大分類誤差率小的弱分類器的權重,使其在最終的分類函式中起著較大的決定作用,而降低分類誤差率大的弱分類器的權重,使其在最終的分類函式中起著較小的決定作用,換言之,誤差率低的弱分類器在最終分類器中占的權重較大,否則較小,
AdaBoost演算法的特點
AdaBoost是一種有很高精度的分類器,其演算法具有如下的特點:
(1) 可以使用各種方法構建子分類器,AdaBoost演算法提供對其進行組合以及提升的框架,
(2) 當使用簡單分類器時,計算出的結果是可以理解的,
(3) 弱分類器構造極其簡單,無需做特征篩選,
(4) AdaBoost演算法簡單,不用調整分類器,不會導致Over Fitting,即過度擬合,
AdaBoost演算法的應用
AdaBoost演算法的應用場景,包括:
(1) 用于二值分類或多分類的應用場景,
(2) 用于特征選擇(Feature Selection),
(3) 無需變動原有分類器,而是通過增加新的分類器,可以提升分類器的性能,
線性回歸、Logistic回歸
線性回歸與多元線性回歸
回歸分析是應用廣泛的統計分析方法,用于分析事物之間的相關關系,其中一元線性回歸模型,指的是只有一個解釋變數的線性回歸模型,而多元線性回歸模型則是包含多個解釋變數的線性回歸模型,所謂解釋變數就是自變數,而被解釋變數則是因變數,回歸模型就是描述因變數和自變數之間依存的數量關系的模型,
神經網路與深度學習(Neural Network and Deep Learning)
人工神經網路是模仿動物和人類神經系統特征,進行分布式并行資訊處理的數學模型,通過把大量人工神經元節點(感知機)連接起來,形成神經網路,并且利用訓練資料調整優化節點間的連接強度,從而達到對新資料進行處理(分類、預測等)的目的,
主流資料深度分析工具
Mahout系統
Mahout是Hadoop大資料平臺上的開源機器學習軟體包,Mahout提供了在大規模集群上對大資料進行深度分析的能力,主流的資料挖掘和機器學習演算法不斷在Mahout平臺上實作,包括聚類、分類、協同過濾(Collaborative Filtering,用于推薦),以及頻繁集挖掘等眾多的演算法,
Spark MLlib系統
?MLlib是Spark大資料平臺的機器學習程式庫,這個庫包含很多通用的機器學習與資料挖據演算法,包括分類、回歸、聚集、聯合過濾(Collaborative Filtering)、降維(Dimensionality Reduction),還包含底層的優化原語(Optimization Primitives)以及資料分析流水線API,有了MLlib庫,使得在Spark平臺上對資料進行深度分析的編程變得更加容易,
?MLlib包含兩套API,分別是spark.mllib和spark.ml,前者包含老版本原有的RDD上的API,而后者是基于DataFrame資料抽象層的高層的API,
?由于運行在Spark平臺上,利用Spark的高性能和大規模資料處理能力,某些資料分析任務比Hadoop上的MapReduce實作獲得10倍(資料保存在磁盤中)到100倍(資料完全存放在記憶體中)的性能提高,
Weka系統
?在Weka平臺上,已經實作了資料預處理、分類、聚類、回歸、關聯規則分析等機器學習和資料挖掘演算法,用戶不經可以使用Weka的作業臺,可視化地對資料進行分析,也可以呼叫Weka的Java包,撰寫自己的資料分析軟體,
?Weka Explorer(探索者界面)是Weka最簡單的使用界面,所有的Weka功能都能在這個界面中,通過點擊滑鼠和表單填寫來使用,由于很多選項都預設了常用的默認值,使用戶以最小的代價取得結果,在這個界面上,有六個標簽,分別是資料預處理(Preprocess)、分類(Classify)、聚類(Cluster)、關聯(Associate)、屬性選擇(Select Attributes)和可視化(Visualize),
?Weka Knowledge Flow(知識流界面)的主體是一個設計畫布,用戶從工具條中選擇Weka組件,并將其置于設計畫布上,連接成一個資料處理和分析的流程圖,用戶通過可視化的編程,可以實作更加靈活和復雜的資料分析功能,在實際研究作業中,研究者可能需要處理好幾個資料集,計算量非常大,這時候就需要實驗者界面(Weka Experimenter)來解決問題了,實驗者界面允許使用多種演算法對多個資料集進行操作,并且支持分布式計算,
R系統與語言
?R是一套開源免費的軟體集成環境,用于對資料進行統計分析(Statistical Computing)和可視化(Graphical Display),R可以運行在Unix、Windows以及MacOS作業系統上,
?R的特性包括:
(1) 有效的資料存盤和管理;
(2) 在陣列、矩陣等資料物件進行計算的一套操作原語;
(3) 統計分析工具集;
(4) 對資料分析結果的圖形展示能力;
(5) 簡便而有效的編程語言(稱為S),支持資料的輸入輸出,可實作分支、回圈、用戶自定義函式等功能,CRAN為Comprehensive R Archive Network的簡稱,它除了收藏了R的可執行版本、源代碼和說明檔案,還收錄了開源社區貢獻的各種擴展軟體包,新的擴展軟體包,使得R可以支持分布式計算(distributed computing),處理更大的資料集,目前,全球有超過一百個CRAN鏡像站,
SPSS與MatLab
?SPSS可以運行在Windows、MacOS、Unix等作業系統上,我們常用的SPSS的版本是Windows上的SPSS,SPSS的功能包括資料管理、統計分析、圖表生成、輸出管理等,SPSS是Statistical Package for Social Science的縮寫,由于SPSS目前不僅適用于社會科學,而是有了更加廣泛的應用范圍,其名字已經改為Statistical Product and Service Solutions,縮寫仍然是SPSS,
?SPSS是一個軟體家族,這個家族中包括SPSS Statistics、SPSS Modeler、SPSS Collection等軟體,分別實作統計分析、預測性分析、資料收集等作業,
?MatLab已經成為強大的支持科學計算、可視化、以及互動式程式設計的資料分析軟體包,它將數值分析、矩陣計算、科學資料可視化、以及非線性動態系統的建模和仿真等諸多強大功能,集成在一個易于使用的視窗環境中,MatLab目前已經應用到數值分析、影像處理、信號處理、金融建模、工程與科學繪圖、控制系統的設計與仿真、通訊系統的設計與仿真等領域,
TensorFlow
TensorFlow是開源的深度學習軟體包,
–TensorFlow具有靈活的架構,用戶使用相同的API開發程式,程式則可以部署到不同的平臺上,包括移動設備、臺式機、以及服務器集群,它可以運行在CPU,也可以運行在GPU上,利用GPU的并行處理能力加快深度學習的程序,
–TensorFlow把計算程序表達成一個有向無環的資料流圖(Data Flow Graph),圖中的節點表示某種數學運算(Mathematical Operations)、或者資料輸入、資料輸出、讀寫持久化的變數等(Persistent Variables),而圖中的邊,表示節點之間的輸入輸出關系,也就是節點間的多維陣列的通訊傳輸(稱為Tensor,或者張量),多維陣列(Tensor)流過(Flow)一個流程圖(Graph),這正是TensorFlow得名的來由,這種計算模型,類似于Spark或者Dryad等的圖計算模型,
–用戶定義機器學習的邏輯,軟體架構則負責資源分配、任務調度、以及容錯等問題,資料流圖的調度采用異步并行處理的方式,即各個圖的節點分配到計算資源上(CPU),然后當進入該節點的邊上有可用資料(Tensor)的時候,這些節點被異步執行,執行程序利用了CPU和GPU的并行處理能力,
–目前,TensorFlow支持CNN、RNN和LSTM演算法,這些演算法在影像識別、語音識別、自然語言處理比如機器翻譯等得到了廣泛應用,
Caffe
?Caffe是一個高效的深度學習軟體框架,Caffe使用C++語言和CUDA軟體架構進行撰寫,可以在CPU和GPU之間無縫切換運行,目前支持命令列、Python語言介面、以及MatLab介面,
–由于使用C++撰寫,和可以運行在GPU上,Caffe運行速度很快,能夠在海量資料上運行復雜的模型,利用Caffe進行開發,模型和優化引數可以通過文本方式進行定義,而不是撰寫在代碼里,在建模方面具有極大的靈活性,
–Caffe的網路(Net)是由層(Layer)組成的有向無環圖(DAG),一個典型的網路,開始于資料層,終止于輸出層,該層計算目標任務,比如進行分類和預測,中間每個網路層,消費一些資料,然后計算結果,輸出到下一層,各個網路層之間的資料傳輸通過BLOB物件進行封裝,BLOB的內容是多維陣列,Caffe采用隨機梯度下降演算法進行神經網路的訓練,
–Caffe可以應用在影像與視覺、語音識別、機器翻譯、機器人等眾多的應用領域,
–除了TensorFlow和Caffe之外,其它開源的深度學習軟體還有Theano和Torch等,
特征選擇
在機器學習中,特征選擇起到至關重要的作用,特征選擇的好,可以對資料量進行有效精簡,提高訓練速度,這點對于復雜模型來講尤其重要,此外,特征選擇,可以減少噪音特征(Noise Feature),提高模型在測驗資料集上的準確性,防止過擬合(Over fit)以及欠擬合(Under fit)情況的發生,另外,從模型復雜度看,特征越多,模型越復雜,越容易發證過擬合的情況,常用的特征選擇方法有互資訊、資訊增益、開放檢驗等方法,
資訊增益法
資訊增益法,根據某特征項(Feature i)為整個分類能夠提供多少資訊量,衡量該特征項的重要程度,從而決定對特征項的取舍,某個特征項的資訊增益,指的是有該特征或沒有該特征時,為整個分類所能提供的資訊量的差別,其中,資訊量的多少由熵來衡量,
卡方檢驗法
?卡方檢驗是統計學的基本方法,它的基本思想,是通過觀察實際值與理論值(預期)的偏差,來決定理論的正確與否,
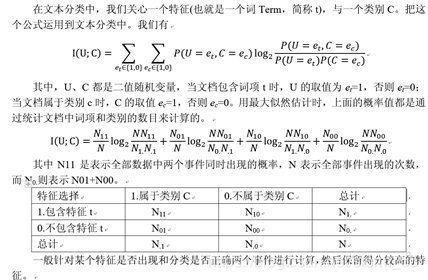
?首先提出原假設,假設兩個變數確實是獨立的,比如在文本分類中,我們關心一個特征(也就是一個詞Term,簡稱t),與一個類別C,是否相互獨立,如果相互獨立,那么說明詞Term對類別C沒有區分作用,也就是我們無法根據t是否出現,來判斷一篇檔案是否屬于類別C,
?提出原假設后,根據觀察實際值與理論值的差別(原假設成立情況下其應該有的值),如果這個差別足夠小,我們可以認為誤差是由于測量手段不夠精確導致或者偶然發生的,兩者確確實實是獨立的,此時就接受原假設,如果這個差別足夠大,則這個誤差不太可能是偶然產生或者測量不精確所致,詞t和類別C兩者實際上是相關的,也就是我們否定了原假設,接受了備擇假設,
互資訊法
互資訊用來評價一個事件的出現,對于另一個事件的出現所貢獻的資訊量,它的基本定義公式為
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/245183.html
標籤:其他
上一篇:期末學習總結