概要介紹
大資料期末整理,巖哥牛逼,
往期文章
資料可視化思維導圖網頁設計期末復習 選擇+簡答+大題
文章目錄
- 第一章
- 1. 大資料的4個v
- 2. 大資料的影響
- 3. 大資料的兩大核心技術及對應關系
- 4. 產品對應關系
- 5. 三者關系
- 第二章
- 1. hadoop最初是創始人Doug Cutting 開發的文本搜索庫,hadoop源自于2002年的Apache Nutch專案
- 2. hadoop分布式處理的軟體框架 ,特性如下
- 3. Apache hadoop 版本演變 1.0-》2.0
- 4. hadoop生態系統
- 5. hadoop專案組建功能
- 6. 組態檔 core-site.xml hdfs-site.xml 引數(屬性)理解
- 第三章
- 1. 總而言之 HDFS實作以下目標
- 2. HAFS特殊的設定,使得本身具有一些應用局限性
- 3.塊的概念
- 4. HDFS主要組件的功能 (名稱節點 資料節點)(課本更詳細)
- 5. 名稱節點的資料結構
- 6. 第二名稱節點:
- 7. 第二名稱節點的作業流程(個人概括)
- 8. HDFS體系機構概述
- 9. HDFS通信協議
- 10. 多副本方式冗余資料的保存
- 11. 資料存盤策略(重點)
- 12. 資料錯誤與恢復(名稱節點出錯 資料節點出錯 資料出錯)(了解)
- 13. HDFS資料讀寫操作(背)(待補充)
- 第四章
- 1. 從BigTable說起
- 2. HBase 和BigTable的底層技術對應關系
- 3. HBase與傳統關系資料庫的對比分析
- 4. HBase資料模型概述
- 5. HBase功能組件及各組件功能
- 6. HBase的三層結構(名稱+各自作用)
- 7. Region服務器作業原理(理解)
- 未完待續
- 總結
第一章
1. 大資料的4個v
:volume velocity variety value 大量的 快速的 多樣的 價值化
2. 大資料的影響
在思維方式方面:大資料完全顛覆了傳統的思維方式:全樣而非抽樣、效率而非精確、相關而非因果
在社會發展方面:大資料決策逐漸成為一種新的決策方式,大資料應用有力促進了資訊技術與各行業的深度融合,大資料開發大大推動了新技術和新應用的不斷涌現,
在就業市場方面:大資料的興起使得資料科學家成為熱門職業,
在人才培養方面:大資料的興起,將在很大程度上改變中國高校資訊技術相關專業的現有教學和科研體制,
3. 大資料的兩大核心技術及對應關系
分布式存盤(GFS HDFS NOSQL NewSQL)分布式處理(MapReduce Sparlk)
4. 產品對應關系
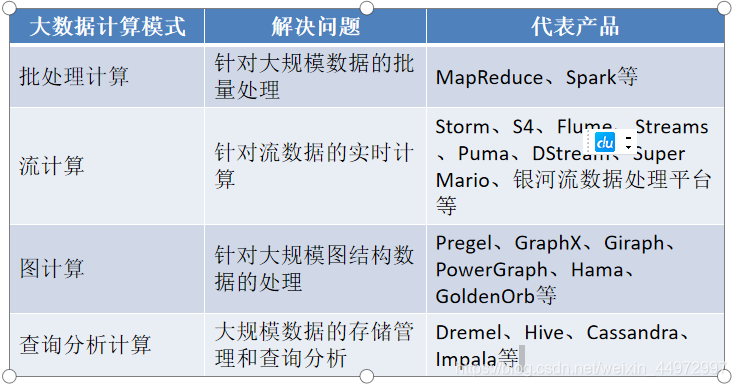
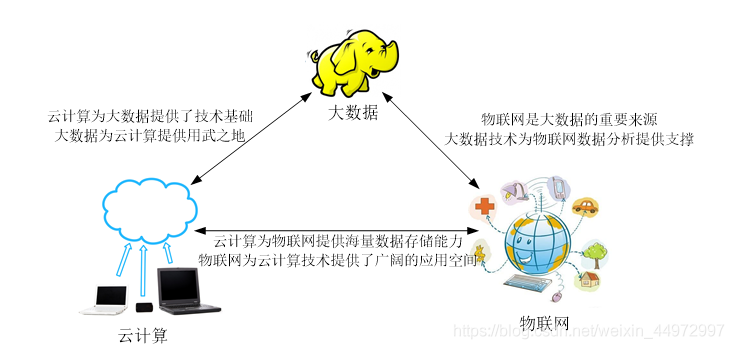
5. 三者關系
:云計算、大資料和物聯網代表了IT領域最新的技術發展趨勢,三者相輔相成,既有聯系又有區別
第二章
1. hadoop最初是創始人Doug Cutting 開發的文本搜索庫,hadoop源自于2002年的Apache Nutch專案
2. hadoop分布式處理的軟體框架 ,特性如下
:高可靠 高效性 高可擴展性 高容錯性 成本低 運行在Linux平臺上,支持多種編程語言
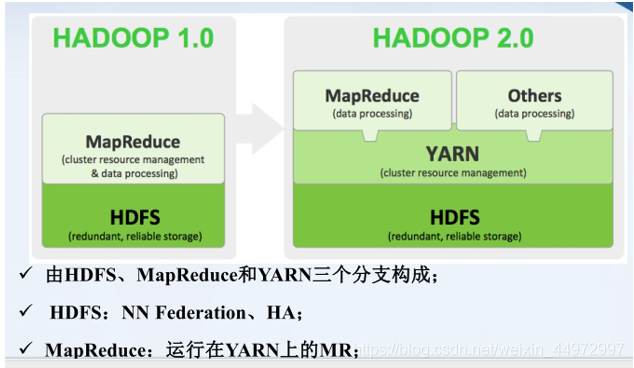
3. Apache hadoop 版本演變 1.0-》2.0
,即增加了分布式資源調度管理框架YARN 和 HDFS HA
4. hadoop生態系統
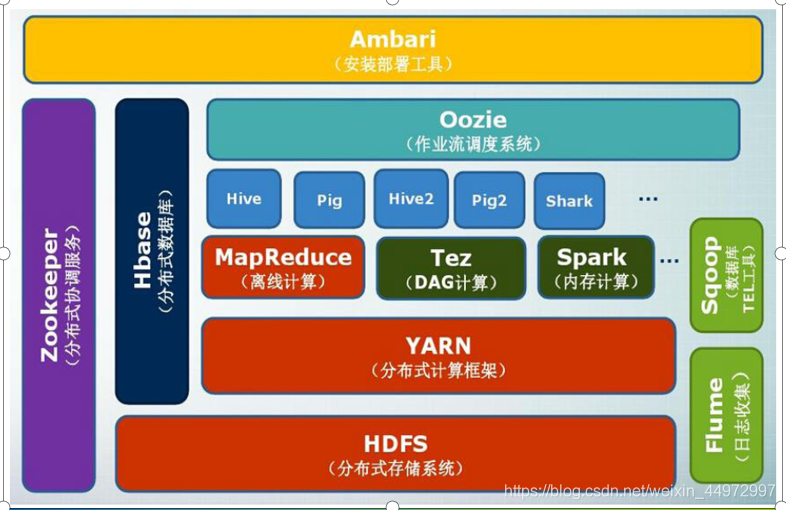
5. hadoop專案組建功能
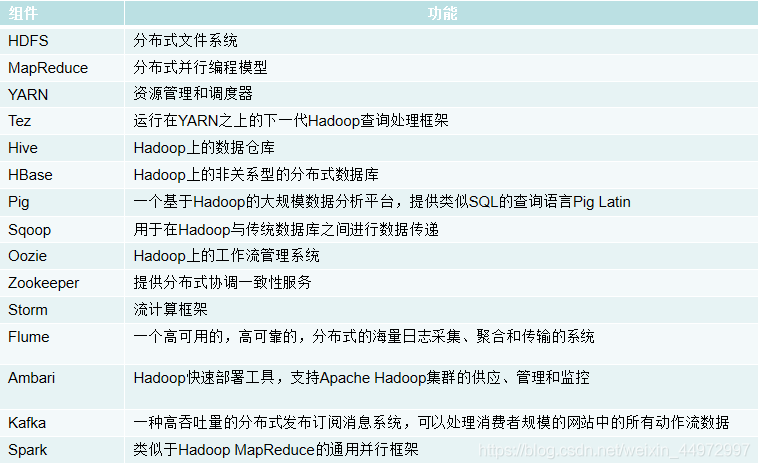
6. 組態檔 core-site.xml hdfs-site.xml 引數(屬性)理解
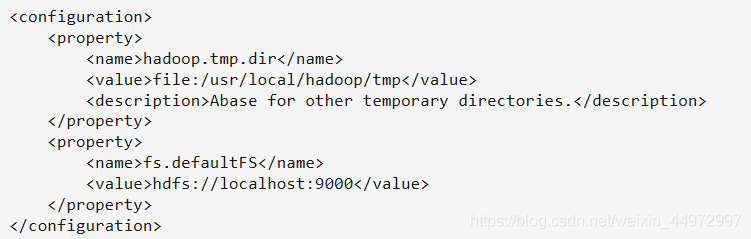
其中 name 標簽表示配置項的名稱 value 表示配置的值,
hadoop.tmp.dir表示存放臨時資料的目錄,即包括NameNode的資料,也包括DataNode的資料,該路徑任意指定,只要實際存在該檔案夾即可
name為fs.defaultFS的值,表示hdfs路徑的邏輯名稱
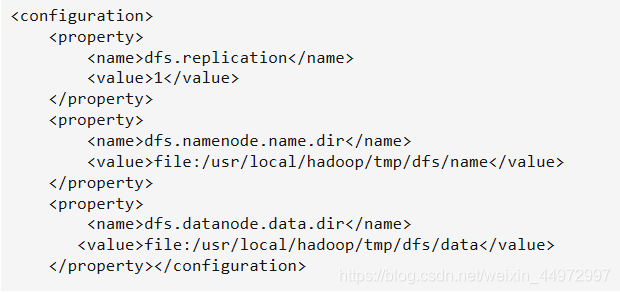
dfs.replication表示副本的數量,偽分布式要設定為1
dfs.namenode.name.dir表示本地磁盤目錄,是存盤fsimage檔案的地方
dfs.datanode.data.dir表示本地磁盤目錄,HDFS資料存放block的地方
第三章
1. 總而言之 HDFS實作以下目標
- 兼容廉價的硬體設備
- 流資料讀寫
- 大資料集
- 簡單的檔案模型
- 強大的跨平臺兼容性
2. HAFS特殊的設定,使得本身具有一些應用局限性
1. 不適合低延遲的資料訪問
2. 無法高效存盤大量小檔案
3. 不支持多用戶寫入及任意修改檔案
3.塊的概念
HDFS默認一個塊64MB,一個檔案被分成多個塊,以塊作為存盤單位,塊的大小遠遠小于普通檔案系統,可以最小化尋址開銷
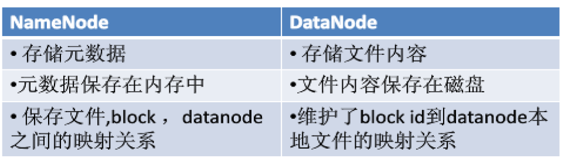
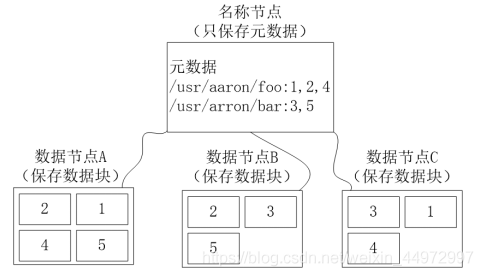
4. HDFS主要組件的功能 (名稱節點 資料節點)(課本更詳細)
名稱節點
- 負責管理分布式檔案系統的命名空間,保存了兩個核心的資料結構,即FsImage 和 EditLog
- 記錄了每個檔案中各個塊所在的資料節點和位置資訊
- 存盤元資料
- 元資料保存在記憶體中
- 保存檔案block,datanode之間的映射關系
- 管理客戶端對檔案的訪問
資料節點:
- 資料節點是分布式檔案系統HDFS的作業節點,負責資料的存盤和讀取,會根據客戶端或者名稱節點的調度來驚醒資料的存盤和檢索,并且向名稱節點定期發送自己所存盤的塊的串列
- 存盤文本內容
- 檔案內容保存在磁盤
- 維護了block id 到 datanode本地檔案的映射關系
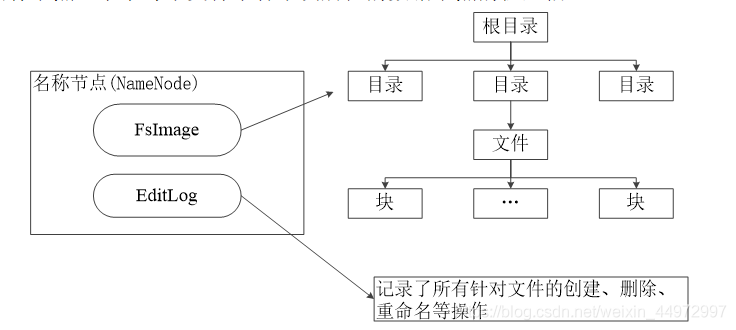
5. 名稱節點的資料結構
名稱節點負責管理分布式檔案系統的命名空間,保存了兩個核心的資料結構,即FsImage EditLog并且名稱節點記錄了每個檔案中各個塊所在的資料節點的位置資訊,
-
FsImage用于維護檔案系統樹以及檔案樹中所有的檔案和檔案夾的元資料
-
操作日志檔案EditLog中記錄了所有針對檔案的創建、洗掉、重命名等操作
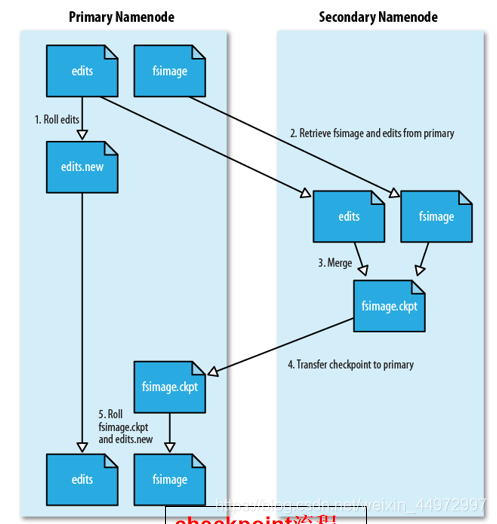
6. 第二名稱節點:
第二名稱節點是HDFS架構中的一個組成部分,它是用來保存名稱節點中對HDFS元資料資訊的備份,并減少名稱節點重啟的時間,SecondaryNameNode一般是單獨運行在一臺機器上,
補充
(所有更新操作寫入Editlog,導致過大,每次名稱節點重啟的時候把Fsimage里面所有內容映射到記憶體,再一條一條執行EditLog中的記錄會非常的慢當Editlog檔案非常大)(引出第二名稱節點)
7. 第二名稱節點的作業流程(個人概括)
- 第二名稱節點定期要求名稱節點停止使用editlog檔案
- 將新的寫操作寫在edit.new
- 第二名稱節點通過get方式獲取FsImage和Editlog
- FsImage加載記憶體,Editlog執行檔案中的更新操作,合并為新的FsImage
- 新的FsImage通過post發送到名稱節點替換舊的,而edit.new替換為新的Editlog
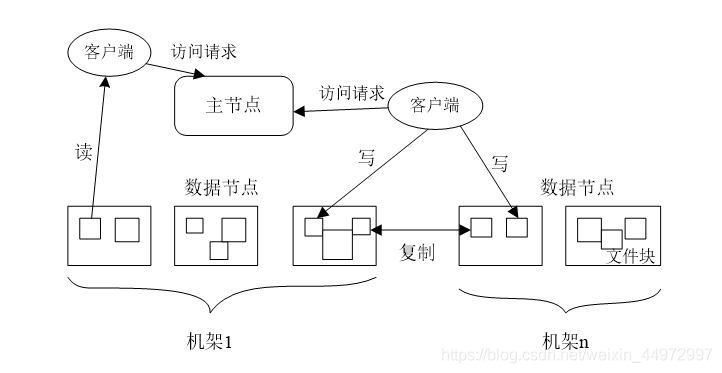
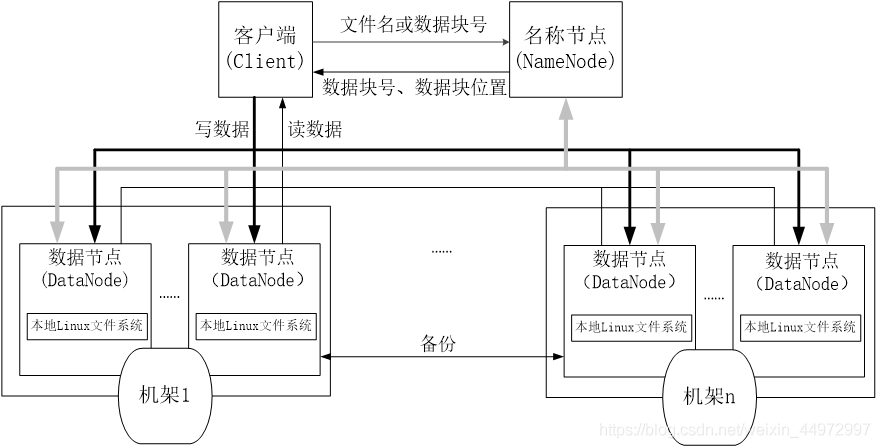
8. HDFS體系機構概述
- 大概就是客戶端向名稱節點請求需要操作的檔案名和資料塊號,名稱節點回傳資料塊號和資料塊位置,再然后就是客戶端直接在資料節點進行讀寫操作
- HDFS采用的是主從(Master/Slave)結構模型,一個HDFS集群包括一個名稱節點和若干個資料節點
- 資料節點的資料保存在本地Linux檔案系統中
- 資料節點會周期性向名稱節點發送“心跳資訊”
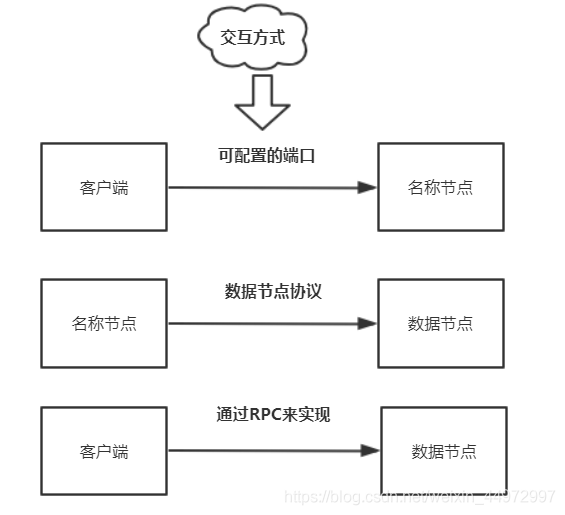
9. HDFS通信協議
概述:
- HDFS是一個部署在集群上的分布式檔案系統,因此很多資料需要通過網路進行傳輸
- 所有的HDFS通信協議都是構建在TCP/IP協議基礎之上的
10. 多副本方式冗余資料的保存
目的:為了保證系統的容錯性和可用性
優點:加快資料傳輸速度
-
加快資料傳輸速度
-
容易檢查資料錯誤
-
保證資料可靠性
什么是多副本:通常一個資料塊的多個副本會被分布到不同的資料節點
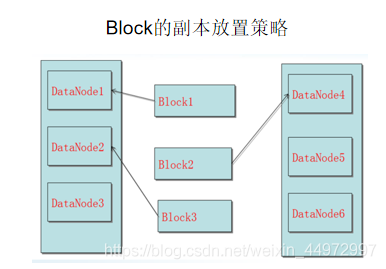
11. 資料存盤策略(重點)
-
第一個副本:放置在上傳檔案的資料節點;如果是集群外提交,則隨機挑選一臺磁盤不太滿、CPU不太忙的節點
-
第二個副本:放置在與第一個副本不同的機架的節點上
-
第三個副本:與第一個副本相同機架的其他節點上
-
更多副本:隨機節點
12. 資料錯誤與恢復(名稱節點出錯 資料節點出錯 資料出錯)(了解)
名稱節點出錯
名稱節點保存了所有的元資料資訊,其中,最核心的兩大資料結構是FsImage和Editlog,如果這兩個檔案發生損壞,那么整個HDFS實體將失效,因此,HDFS設定了備份機制,把這些核心檔案同步復制到備份服務器SecondaryNameNode上,當名稱節點出錯時,就可以根據備份服務器SecondaryNameNode中的FsImage和Editlog資料進行恢復,
資料節點出錯
每個資料節點會定期向名稱節點發送“心跳”資訊,向名稱節點報告自己的狀態
當資料節點發生故障,或者網路發生斷網時,名稱節點就無法收到來自一些資料節點的心跳資訊,這時,這些資料節點就會被標記為“宕機”,節點上面的所有資料都會被標記為“不可讀”,名稱節點不會再給它們發送任何I/O請求
這時,有可能出現一種情形,即由于一些資料節點的不可用,會導致一些資料塊的副本數量小于冗余因子
名稱節點會定期檢查這種情況,一旦發現某個資料塊的副本數量小于冗余因子,就會啟動資料冗余復制,為它生成新的副本
HDFS和其它分布式檔案系統的最大區別就是可以調整冗余資料的位置
資料錯誤
網路傳輸和磁盤錯誤等因素,都會造成資料錯誤
客戶端在讀取到資料后,會采用md5和sha1對資料塊進行校驗,以確定讀取到正確的資料
在檔案被創建時,客戶端就會對每一個檔案塊進行資訊摘錄,并把這些資訊寫入到同一個路徑的隱藏檔案里面
當客戶端讀取檔案的時候,會先讀取該資訊檔案,然后,利用該資訊檔案對每個讀取的資料塊進行校驗,如果校驗出錯,客戶端就會請求到另外一個資料節點讀取該檔案塊,并且向名稱節點報告這個檔案塊有錯誤,名稱節點會定期檢查并且重新復制這個塊
13. HDFS資料讀寫操作(背)(待補充)
HDFS有很多命令,其中fs命令可以說是HDFS最常用的命令,利用fs命令可以查看HDFS檔案系統的目錄結構、上傳和下載資料、創建檔案資訊等,該命令的用法如下
hadoop fs [genericOptions] [commandOptions]

第四章
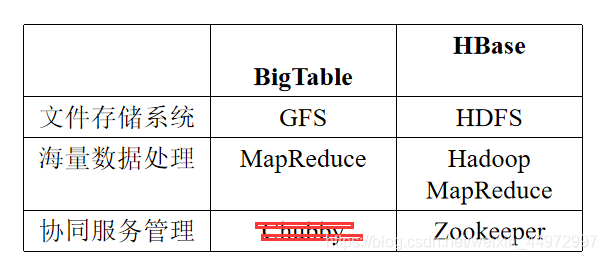
1. 從BigTable說起
- BigTable是一個分布式存出系統
- BigTable起初是用于解決典型的互聯網搜索問題
2. HBase 和BigTable的底層技術對應關系
3. HBase與傳統關系資料庫的對比分析
HBase與傳統的關系資料庫的區別主要體現在以下幾個方面:
- 資料型別:關系資料庫采用關系模型,具有豐富的資料型別和存盤方式,HBase則采用了更加簡單的資料模型,它把資料存盤為未經解釋的字串
- 資料操作:關系資料庫中包含了豐富的操作,其中會涉及復雜的多表連接,HBase操作則不存在復雜的表與表之間的關系,只有簡單的插入、查詢、洗掉、清空等,因為HBase在設計上就避免了復雜的表和表之間的關系
- 存盤模式:關系資料庫是基于行模式存盤的,HBase是基于列存盤的,每個列族都由幾個檔案保存,不同列族的檔案是分離的
- 資料索引:關系資料庫通常可以針對不同列構建復雜的多個索引,以提高資料訪問性能,HBase只有一個索引——行鍵,通過巧妙的設計,HBase中的所有訪問方法,或者通過行鍵訪問,或者通過行鍵掃描,從而使得整個系統不會慢下來
- 資料維護:在關系資料庫中,更新操作會用最新的當前值去替換記錄中原來的舊值,舊值被覆寫后就不會存在,而在HBase中執行更新操作時,并不會洗掉資料舊的版本,而是生成一個新的版本,舊有的版本仍然保留
- 可伸縮性:關系資料庫很難實作橫向擴展,縱向擴展的空間也比較有限,相反,HBase和BigTable這些分布式資料庫就是為了實作靈活的水平擴展而開發的,能夠輕易地通過在集群中增加或者減少硬體數量來實作性能的伸縮
4. HBase資料模型概述
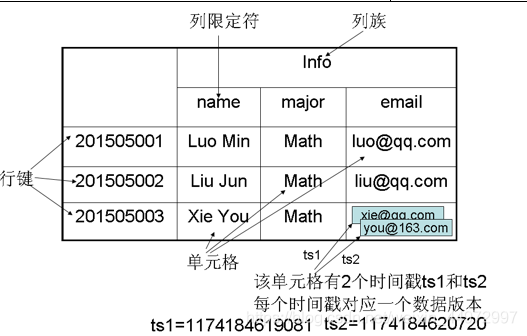
概述:HBase是一個稀疏、多維度、排序的映射表,這張表的索引是行鍵、列族、列限定符和時間戳
表:HBase采用表來組織資料,表由行和列組成,列劃分為若干個列族
行:每個HBase表都由若干行組成,每個行由行鍵(row key)來標識,
列族:一個HBase表被分組成許多“列族”(Column Family)的集合,它是基本的訪問控制單元
列限定符:列族里的資料通過列限定符(或列)來定位
單元格:在HBase表中,通過行、列族和列限定符確定一個“單元格”(cell),單元格中存盤的資料沒有資料型別,總被視為位元組陣列byte[]
時間戳:每個單元格都保存著同一份資料的多個版本,這些版本采用時間戳進行索引
5. HBase功能組件及各組件功能
- 庫函式:鏈接到每個客戶端
- 一個Master主服務器
- 許多個Region服務器
Master:主服務器Master負責管理和維護HBase表的磁區資訊,維護Region服務器串列,分配Region,負載均衡**
Region:Region服務器負責存盤和維護分配給自己的Region,處理來自客戶端的讀寫請求**
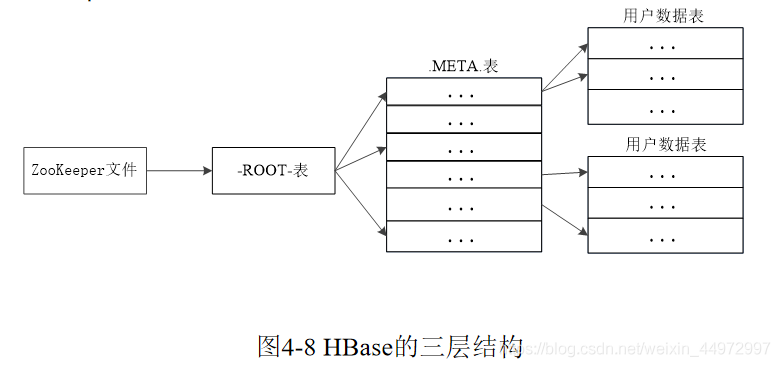
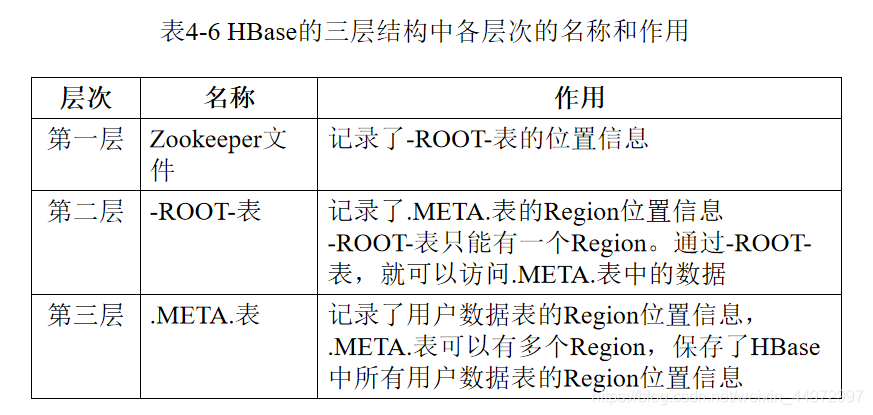
6. HBase的三層結構(名稱+各自作用)
什么是region:表示一個磁區,包含了位于某個值域區間內的所有資料,它是負載均衡和資料分發的基本單位,初始時候,一個表只有一個Region,隨著資料插入,持續變多
- 元資料表,又名.META.表,存盤了Region和Region服務器的映射關系
- 當HBase表很大時, .META.表也會被分裂成多個Region
- 根資料表,又名-ROOT-表,記錄所有元資料的具體位置
- -ROOT-表只有唯一一個Region,名字是在程式中被寫死的
- Zookeeper檔案記錄了-ROOT-表的位置
7. Region服務器作業原理(理解)
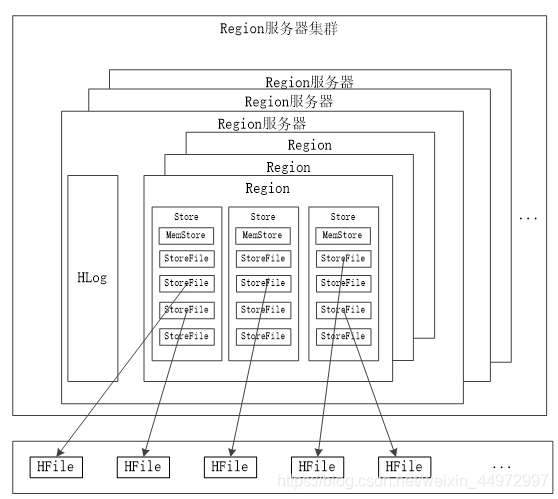
- 用戶讀寫資料程序:①用戶寫入資料時,被分配到相應Region服務器去執行②用戶資料首先被寫入到MemStore和Hlog中③只有當操作寫入Hlog之后,commit()呼叫才會將其回傳給客戶端④當用戶讀取資料時,Region服務器會首先訪問MemStore快取,如果找不到,再去磁盤上面的StoreFile中尋找
- 快取的重繪:①系統會周期性地把MemStore快取里的內容刷寫到磁盤的StoreFile檔案中,清空快取,并在Hlog里面寫入一個標記
②每次刷寫都生成一個新的StoreFile檔案,因此,每個Store包含多個StoreFile檔案
③每個Region服務器都有一個自己的HLog 檔案,每次啟動都檢查該檔案,確認最近一次執行快取重繪操作之后是否發生新的寫入操作;如果發現更新,則先寫入MemStore,再刷寫到StoreFile,最后洗掉舊的Hlog檔案,開始為用戶提供服務 - StoreFile的合并:①每次刷寫都生成一個新的StoreFile,數量太多,影響查找速度
②呼叫Store.compact()把多個合并成一個
③合并操作比較耗費資源,只有數量達到一個閾值才啟動合并
未完待續
總結
文章純屬期末復習整理,如有不足和錯誤的地方,希望
評論指出或私信,
最后希望給文章點個贊,整理不易!!!
最后希望給文章點個贊,整理不易!!!
最后希望給文章點個贊,整理不易!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/245188.html
標籤:其他
下一篇:計算機組成原理簡答