Rust語言教程(2) - 從熟悉的部分開始
雖然有默認不變性還有所有權的問題讓Rust一上來用起來有些不同,但是其實大部分語法特點還是我們所熟悉的,
我們沒必要上來就跟自己死磕,可以先從我們熟悉的部分開始學習,
一般我們寫代碼,使用的主要是資料型別、控制結構和函式,我們就從這三部分開始,
資料型別
與Go一樣,Rust的定義陳述句資料也是放在變數名后面的,不過還要加上一個冒號,
布爾型別
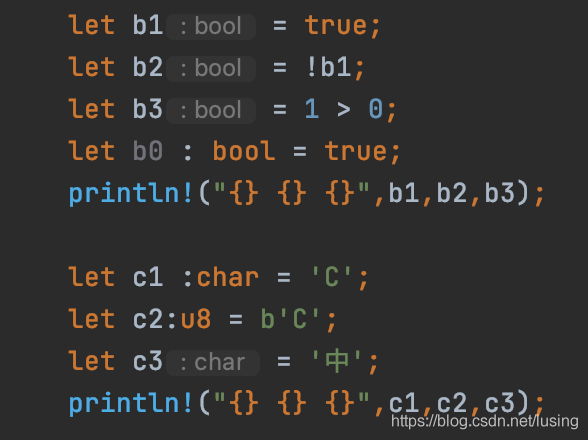
布爾型別是bool:
let b0 : bool = true;
因為Rust是有型別推斷的功能,所以很多時候可以不用指定型別,
let b1 = true;
let b2 = !b1;
let b3 = 1 > 0;
println!("{} {} {}",b1,b2,b3);
如果使用CLion等IDE的話,就可以直接看到IDE提供的灰色的型別推斷的提示,非常方便:
字符型別 - 傳統與現代的結合
Rust的字符型別支持的是Unicode型別,占用4個位元組,同時,Rust也支持單位元組ASCII值,這時用b開頭,型別值就是8位無符號型別u8,
我們來看例子:
let c1 :char = 'C';
let c2:u8 = b'C';
let c3 = '中';
println!("{} {} {}",c1,c2,c3);
同樣,我們可以將字符組成字串,我們來看例子:
let s1 = "Hello";
let s2 = b"World";
println!("{} {:?}",s1,s2);
輸出結果為:
Hello [87, 111, 114, 108, 100]
s1的真實型別是str型別,而s2是u8的陣列,
let s1 :&str = "Hello";
let s2 :&[u8;5] = b"World";
整數型別: 后綴與下劃線齊飛
按照長度,Rust的整數型別支持8位,16位,32位,64位,128位,根據有符號和無符號,分為有符號的i8,i16,i32,i64,i128和無符號的u8,u16,u32,u64,u128,
除此之外,也有根平臺相關的型別,有符號為isize型別,無符號為usize型別,
我們看下例子:
let i1 : i8 = -8;
let i2 : i16 = -16;
let i3 : i32 = -32;
let i4 : i64 = -64;
let i5 : i128 = -128;
let u1 : u8 = 8;
let u2 : u16 = 16;
let u3 : u32 = 32;
let u4 : u64 = 64;
let u5 : u128 = 128;
let p1 : isize = -1;
let p2 : usize = 1;
上面都是跟其它語言比較像,下面我們來看看Rust特色的后綴,這在C++中也有,比如10l, 200L之類的,
在Rust中,我們直接用型別名做為后綴,我們看個例子:
let i6 = -1i8;
let i7 = -2i16;
這樣放在一起可能不太容易區分,沒關系,Rust允許我們在數字上任意的加下劃線來提升可讀性,我們來看幾個例子:
let i08 = -3_i32;
let i09 = -4__i64;
let i10 = -5___i128;
下劃線并非只是用于數字和型別區分,也可以加在數字中間,我們來看個例子:
let u6 = 1_000_000_u128;
println!("{}",u6);
默認的整數型別是i32,如果Rust無法推斷中整數的型別,那么就默認為i32.
整數的進制
在Rust中,避免了077這樣對八進制的偏愛,改為用0o來表示8進制整數,16進制仍然是0xFF前綴,二進制用0b前綴,
我們看例子:
let u07 = 0xFF_u32;
let u08 = 0o7777_u32;
let u09 = 0b01_10_00_u8;
println!("{} {} {}",u07,u08,u09);
輸出結果為:
255 4095 24
整數的溢位
在C語言中,整數的溢位也是一個常出現的問題,
對此,Rust在debug模式下,在編譯時會檢查整數的溢位的問題:
let i_10 : i8 = 0x7f;
let i_11 : i8 = i_10 * 10i8;
println!("{}",i_11);
在編譯時,Rust就會報錯:
84 | let i_11 : i8 = i_10 * 10i8;
| ^^^^^^^^^^^ attempt to compute `i8::MAX * 10_i8`, which would overflow
懂程式分析的同學可能會想,在編譯時檢查不出來怎么辦?好辦,我們在運行時進行檢查,
我們來個例子:
let mut i_20 : i8 = 0x20;
for i in 1..20{
i_20 = 0x20_i8 * i_20;
}
println!("{}",i_20);
在運行時仍然發現了溢位:
thread 'main' panicked at 'attempt to multiply with overflow', src/main.rs:91:16
stack backtrace:
0: rust_begin_unwind
at /rustc/7eac88abb2e57e752f3302f02be5f3ce3d7adfb4/library/std/src/panicking.rs:483
1: core::panicking::panic_fmt
at /rustc/7eac88abb2e57e752f3302f02be5f3ce3d7adfb4/library/core/src/panicking.rs:85
2: core::panicking::panic
at /rustc/7eac88abb2e57e752f3302f02be5f3ce3d7adfb4/library/core/src/panicking.rs:50
3: tools::test
at ./src/main.rs:91
4: tools::main
at ./src/main.rs:34
5: core::ops::function::FnOnce::call_once
at /Users/lusinga/.rustup/toolchains/stable-x86_64-apple-darwin/lib/rustlib/src/rust/library/core/src/ops/function.rs:227
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
型別轉換
Rust語言是強型別的語言,不像C一樣有默認的型別轉換,如果進行跨型別計算需要進行型別轉換,
型別轉換使用“as 型別”的方法來寫,我們來看個例子:
let i_100 : i32 = (16i8 + 1) as i32;
i8計算之后還是i8,不能直接賦給i32型別,需要通過as i32來轉換型別,
如果計算的型別不同,編譯不報錯,在運行的時候也會被檢查出來,
我們看個例子:
let i_101 = 16i8 + 32i32;
會報下面的錯:
error[E0308]: mismatched types
--> src/main.rs:99:24
|
99 | let i_101 = 16i8 + 32i32;
| ^^^^^ expected `i8`, found `i32`
后面還有一個有趣的報錯,讓trait露了一個爪印:
error[E0277]: cannot add `i32` to `i8`
--> src/main.rs:99:22
|
99 | let i_101 = 16i8 + 32i32;
| ^ no implementation for `i8 + i32`
|
= help: the trait `Add<i32>` is not implemented for `i8`
浮點數
浮點數跟C語言差不多,分為32位浮點數和64位浮點數,就這兩種,分別是f32和f64,默認為f64,
我們來看兩個例子:
let f_01 = 2.1;
let f_02 = 2e8;
f_01和f_02都是f64型別,
需要注意的是,對于除0的處理,會引入兩個新的值:
- 對于非0除以0,得到的將是無窮大inf
- 而對于0除以0,將得到NaN,意思是并不是一個數
我們來看例子:
let f_03 = 0.0 / 0.0;
let f_04 = 1.0 / 0.0;
println!("{} {}",f_03,f_04);
輸出結果為:
NaN inf
NaN對應的本尊是std::f64::NAN,而inf是std::f64::INFINITY,我們將其排列在一起:
let f_03 = 0.0 / 0.0;
let f_04 = 1.0 / 0.0;
let f_05 = std::f64::INFINITY;
let f_06 = std::f64::NAN;
println!("{} {} {} {}",f_03,f_04,f_05,f_06);
輸出結果為:
NaN inf inf NaN
32位和64位的無窮大都是無窮大,它們是相等的:
let f_10 = std::f32::INFINITY;
let f_11 = std::f64::INFINITY;
println!("{}",f_11==f_10 as f64);
輸出結果為:
true
但是要注意的是,兩個NAN是不相等的:
let f_12 = std::f64::NAN;
println!("{}",f_12==f_12);
結果為false.
流程控制
分支陳述句
Rust支持if-else運算式,用來處理分支,
if后面不必加括號,有點像Go,我們看個例子:
if n >= 100 {
println!("Grade A");
}else if n>= 60 {
println!("Pass");
}else{
println!("Fail");
}
可以寫成更像運算式一點的方式:
let grade = if n == 100{
"A"
}else if n>=60{
"Pass"
}else{
"Fail"
};
如果用作運算式的話,if和else兩個分支回傳的結果需要轉換成同一型別,畢竟Rust是這么強型別的語言,
回圈陳述句
Rust的回圈分為三種:死回圈loop,while回圈和for回圈,
loop最直接干脆,不需要while(true)或者for(;;)這種寫法,直接loop,如果需要退出回圈就用break,繼續下一輪回圈就用continue,
我們來個簡單例子:
let mut num = 0;
let mut sum = 0;
loop{
if num > 10 {
break;
}else{
sum += num;
num += 1;
}
}
println!("sum={}",sum);
我們再將其翻譯成while回圈:
num = 0;
sum = 0;
while num <= 10 {
sum += num;
num += 1;
}
println!("sum={}", sum);
與if一樣,while后面也不強制要求括號,
最后是for回圈,它主要用于迭代器的遍歷:
sum = 0;
for i in 0..11 {
sum += i;
}
println!("sum={}", sum);
函式
最后說下函式,Rust的函式使用fn關鍵字來定義,回傳值的型別用->分隔而不是":",
另外,Rust中不一定非要用return陳述句來回傳值,運算式的值即可,我們看個例子:
fn fib2(n: i32) -> i64 {
if n <= 2 {
1i64
} else {
fib2(n - 1) + fib2(n - 2)
}
}
按傳統寫法也是可以的:
fn fib2(n: i32) -> i64 {
if n <= 2 {
return 1i64
} else {
return fib2(n - 1) + fib2(n - 2)
}
}
或者將return提到if運算式外面:
fn fib2(n: i32) -> i64 {
return if n <= 2 {
1i64
} else {
fib2(n - 1) + fib2(n - 2)
}
}
小結
在使用基本型別的情況下,Rust跟C語言和Go語言的基礎部分其實還是很類似的,熟悉Javascript等語言的同學也不會覺得陌生,我們可以把原有的知識遷移過來,基本型別變數如果需要修改值的話就加個mut,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/245785.html
標籤:AI
上一篇:開源開發者 David Recordon 被任命白宮技術總監
下一篇:面試題---集合框架篇