文章目錄
- 前言:有點長先點贊收藏唄,你的點贊就是我最大的動力
- 一、HashMap的底層資料結構
- 二、鏈表節點是怎么插入的
- 三、什么時候擴容
- 四、為什么默認初始化長度為16
- 五、為什么要求是2的指數冪
- 六、 為啥不直接使用hashCode
- 七、 HashMap擴容的原因
- 八、 jdk 7 與 jdk 8的比較
- 九、為什么jdk.17的hashMap擴容存在死回圈
- 點贊收藏轉發謝謝,關注公眾號回復 hashmap,獲取原始碼講解原圖pos
- 寫在最后,感謝點贊關注收藏轉發
前言:有點長先點贊收藏唄,你的點贊就是我最大的動力
HashMap絕對是最常問的集合之一,基本上所有點都要爛熟于心的那種,下面是一些常見的問題,如果大家都不知道了,那么幫我看看對不對,還模糊的就認真看下,保證你有所識訓,HashMap的底層資料結構?
鏈表節點是怎么插入的?
什么時候會擴容?
Java7和Java8的區別?
為啥會執行緒不安全?
有什么執行緒安全的類代替么?
默認初始化大小是多少?為啥是這么多?為啥大小都是2的冪?
HashMap的擴容方式?負載因子是多少?為什是這么多?
HashMap的主要引數都有哪些?
HashMap是怎么處理hash碰撞的?
hash的計算規則?
一、HashMap的底層資料結構
HashMap是我們非常常用的資料結構,由陣列和鏈表組合構成的資料結構,
在不發生hash沖撞的情況下資料結構是陣列,一但出現hash沖突,則Entry.next 來實作鏈表結構
大概如下,陣列里面每個地方都存了Key-Value這樣的實體,在Java7叫Entry在Java8中叫Node,

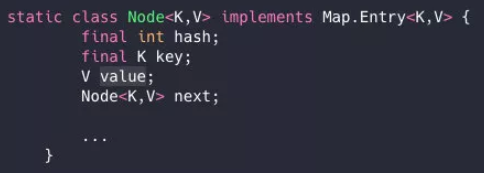
二、鏈表節點是怎么插入的
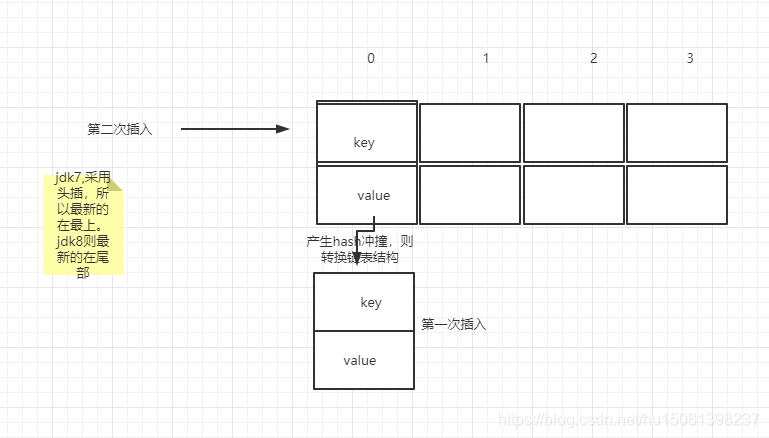
java7 頭插法,就是說新來的值會取代原有的值,原有的值就順推到鏈表中去,就像上面的例子一樣,因為寫這個代碼的作者認為后來的值被查找的可能性更大一點,提升查找的效率,
但是,在java8之后,都是所用尾部插入了,(圖畫的有點low,體諒)
tip:為啥尾部插呢?就是因為多執行緒情況,在擴容的時候容易形成倍訓(死回圈),最后面我會畫圖說明這個問題的,大家耐心往下看,畢竟這是本文的重點
三、什么時候擴容
陣列容量是有限的,資料多次插入的,到達一定的數量就會進行擴容,也就是resize,什么時候resize呢?有兩個因素:Capacity:HashMap當前長度,
LoadFactor:負載因子,默認值0.75f,
怎么理解呢,就比如當前的容量大小為16,當你存進第14個的時候,判斷發現需要進行resize了,那就進行擴容,但是HashMap的擴容也不是簡單的擴大點容量這么簡單的,
擴容分兩步
1.創建一個新的Entry空陣列,長度是原陣列的2倍,
2.遍歷原Entry陣列,把所有的Entry重新Hash到新陣列,
(為什么不直接復制過去呢?是因為hash在計算的時候其實涉及了陣列長度 ,你擴容長度都改變了,那么就好導致擴容前后計算的hash值是不一樣的)
四、為什么默認初始化長度為16
因為計算位置的時候用到了位運算(位與運算比算數計算的效率高了很多)
index的計算公式:index = HashCode(Key) & (Length- 1)其實這個計算index的方法和hashCode%length小說是一樣的
例如: hashCode : 2 2%16 index= 2
hashCode: 2 (0010) & 1111(16-1的二進制) = 0010(2)
所以用位與運算效果與取模一樣,性能也提高了不少!
那為啥用16不用別的呢
因為在使用不是2的冪的數字的時候,Length-1的值是所有二進制位全為1,這種情況下,index的結果等同于HashCode后幾位的值,
只要輸入的HashCode本身分布均勻,Hash演算法的結果就是均勻的,
這是為了實作均勻分布,
五、為什么要求是2的指數冪
因為 底層hash運算 是 h &(length -1) 這樣情況能保證空間不浪費,如果傳的是偶數,-1后就是奇數,他的2進制位末尾肯定是0 進行位運算 末尾也是0 一旦高位算出是 1 則好多空間浪費
HashMap初始化時,如果指定容量大小為10,那么實際大小是多少?
16,因為HashMap的初始化函式中規定容量大小要是2的指數倍,即2,4,8,16,所以當指定容量為10時,實際容量為16,
六、 為啥不直接使用hashCode
HashMap的 hash(Obeject k)方法中為什么在呼叫 k.hashCode()方法獲得hash值后,為什么不直接對這個hash進行取余,而是還要將hash值進行右移和異或運算?
A:如果HashMap容量比較小而hash值比較大的時候,哈希沖突就容易變多,基于HashMap的indexFor底層設計,假設容量為16,那么就要對二進制0000 1111(即15)進行按位與操作,那么hash值的二進制的高28位無論是多少,都沒意義,因為都會被0&,變成0,所以哈希沖突容易變多,那么hash(Obeject k)方法中在呼叫 k.hashCode()方法獲得hash值后,進行的一步運算:h=(h>>>20)(h>>>12);有什么用呢?首先,h>>>20和h>>>12是將h的二進制中高位右移變成低位,其次異或運算是利用了特性:同0異1原則,盡可能的使得h>>>20和h>>>12在將來做取余(按位與操作方式)時都參與到運算中去,綜上,簡單來說,通過h=(h>>>20)(h>>>12);運算,可以使k.hashCode()方法獲得的hash值的二進制中高位盡可能多地參與按位與操作,從而減少哈希沖突,
七、 HashMap擴容的原因
提升HashMap的get、put等方法的效率,因為如果不擴容,鏈表就會越來越長,導致插入和查詢效率都會變低,
八、 jdk 7 與 jdk 8的比較
1.1.7基于頭插,1.8是尾插
- 1.7 采用陣列加鏈表,1.8采用 陣列+紅黑樹(jdk1.8引入紅黑樹后,如果單鏈表節點個數超過8個,是否一定會樹化?
不一定,它會先去判斷是否需要擴容(即判斷當前節點個數是否大于擴容的閾值),如果滿足擴容條件,直接擴容,不會樹化,因為擴容不僅能增加容量,還能縮短單鏈表的節點數,一舉兩得,
,當鏈表節點個數超過8個(m默認值)以后,開始使用紅黑樹,使用紅黑樹一個綜合取優的選擇,相對于其他資料結構,紅黑樹的查詢和插入效率都比較高,而當紅黑樹的節點個數小于6個(默認值)以后,又開始使用鏈表,這兩個閾值為什么不相同呢?主要是為了防止出現節點個數頻繁在一個相同的數值來回切換,舉個極端例子,現在單鏈表的節點個數是9,開始變成紅黑樹,然后紅黑樹節點個數又變成8,就又得變成單鏈表,然后節點個數又變成9,就又得變成紅黑樹,這樣的情況消耗嚴重浪費,因此干脆錯開兩個閾值的大小,使得變成紅黑樹后“不那么容易”就需要變回單鏈表,同樣,使得變成單鏈表后,“不那么容易”就需要變回紅黑樹,
)
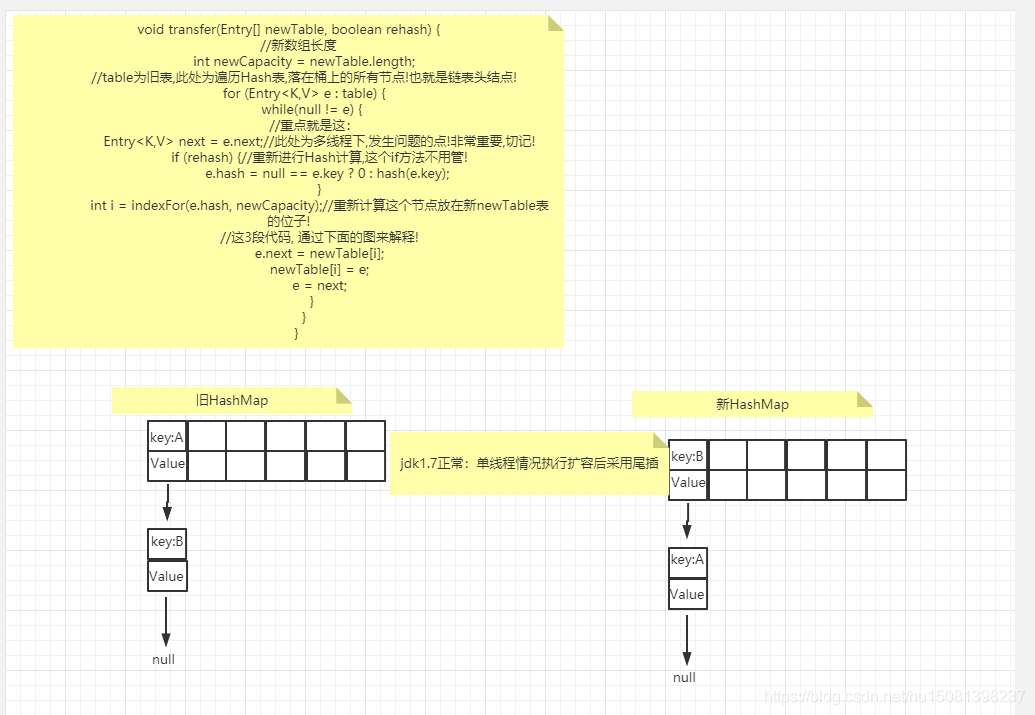
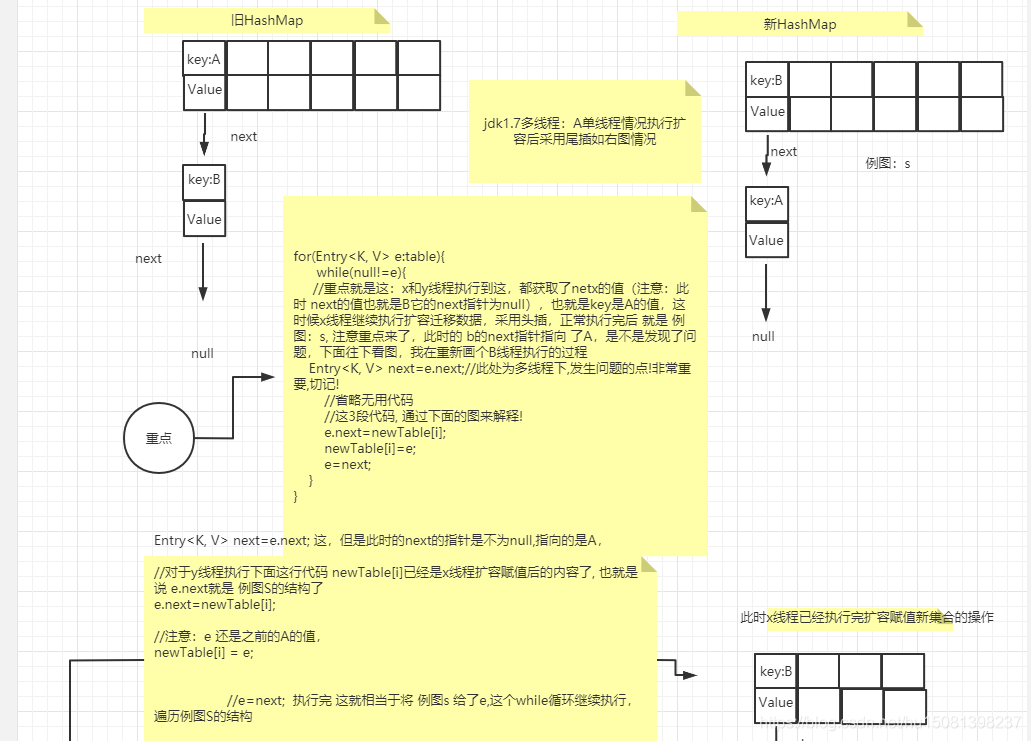
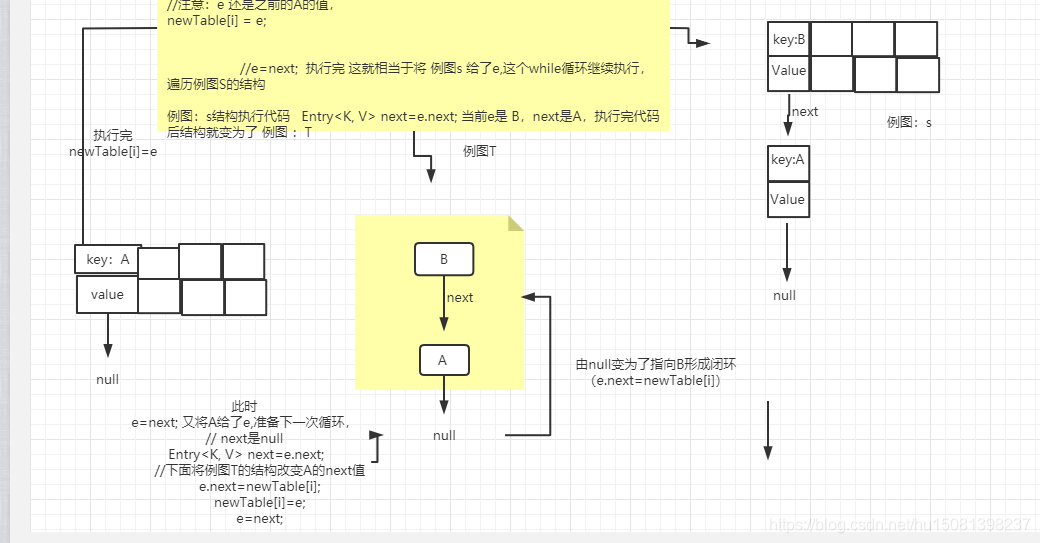
九、為什么jdk.17的hashMap擴容存在死回圈
重點就是這:
Entry<K,V> next = e.next;(兩個執行緒同時走到這,其中一個等待CPU的執行權,另一個直接順利執行 擴容,然后回圈遍歷舊集合,將資料遷移到新創建的集合中,因為鏈表這種節點的特殊性:當前節點持有下一個節點的參考,所以在遷移的程序中next的值會有問題下面看源代碼大家簡單了解下程序,后面畫圖講解 )
/**
* jdk1.7hashMap擴容的核心方法
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
//新陣列長度
int newCapacity = newTable.length;
//table為舊表,此處為遍歷Hash表,落在桶上的所有節點!也就是鏈表頭結點!
for (Entry<K,V> e : table) {
while(null != e) {
//重點就是這:
Entry<K,V> next = e.next;//此處為多執行緒下,發生問題的點!非常重要,切記!
if (rehash) {//重新進行Hash計算,這個if方法不用管!
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);//重新計算這個節點放在新newTable表的位子!
//這3段代碼, 通過下面的圖來解釋!
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
點贊收藏轉發謝謝,關注公眾號回復 hashmap,獲取原始碼講解原圖pos

寫在最后,感謝點贊關注收藏轉發
歡迎關注我的微信公眾號 【猿之村】

來聊聊Java面試
加我的微信進一步交流和學習,微信手動搜索
【codeyuanzhicunup】添加即可
如有相關技術問題歡迎留言探討,公眾號主要用于技術分享,包括常見面試題剖析、以及原始碼解讀、微服務框架、技術熱點等,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/246512.html
標籤:其他
上一篇:游戲安全:服務端SQL安全方案。
下一篇:越過山丘--與你共勉!