HTTP的請求報文結構和回應報文結構
HTTP請求報文主要由請求行、請求頭、空行、請求正文(Get請求沒有請求正文)4部分組成,
1、請求行
由三部分組成,分別為:請求方法、URL以及協議版本,之間由空格分隔;
請求方法包括GET、HEAD、PUT、POET、TRACE、OPTIONS、DELETE以及擴展方法,當然并不是所有的服務器都實作了所有的方法,部分方法即便支持,出于安全性的考慮也是不同的;
協議版本的格式為:HTTP/主版本號.次版本號,常用的有HTTP/1.0和HTTP/1.1;
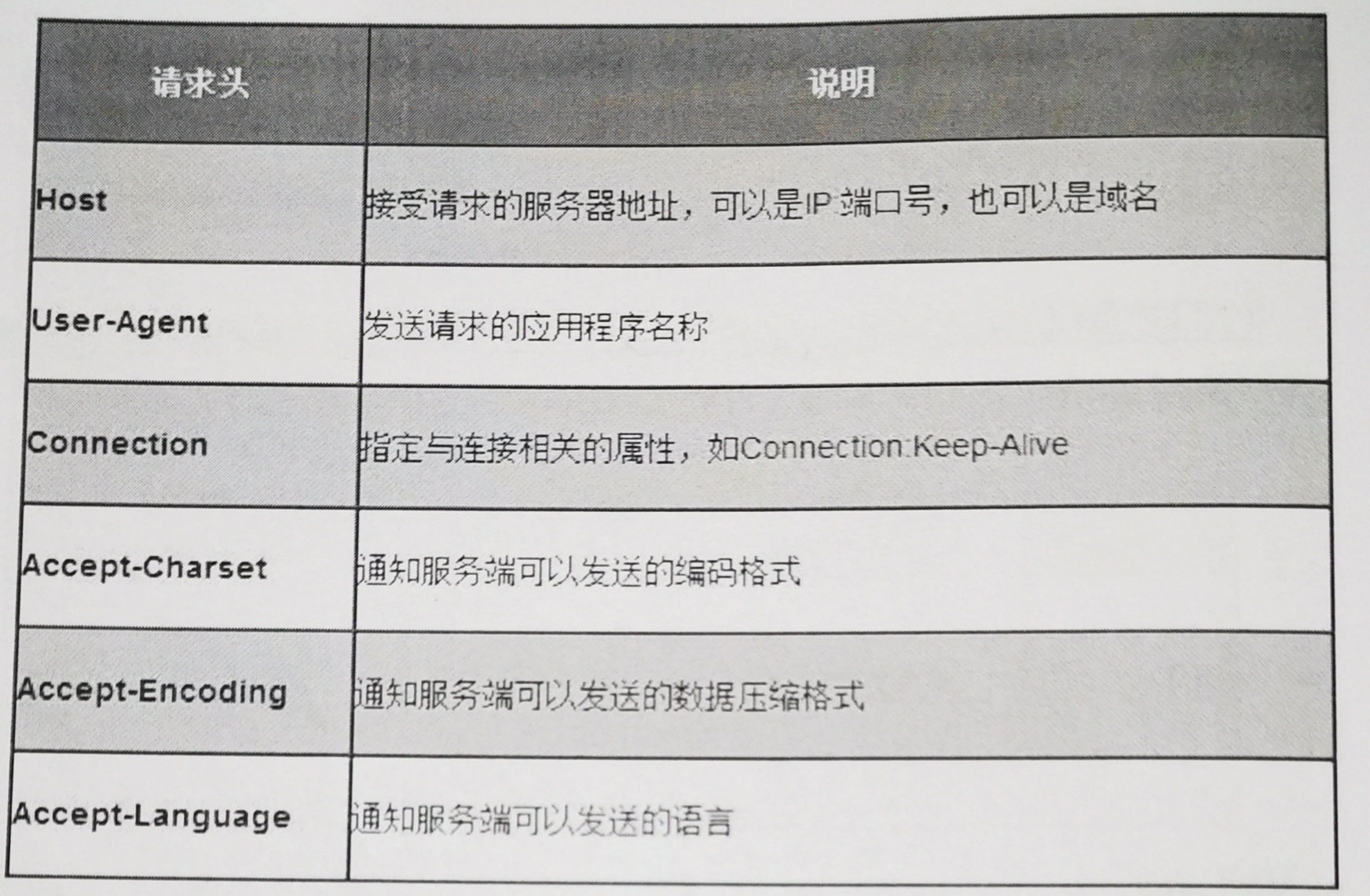
2、請求頭
請求頭部為請求報文添加了一些附加資訊,由“名/值”對組成,每行一對,名和值之間使用冒號分隔,
常見請求頭如下:
3、空行
請求頭的最后會有一個空行,表示請求頭部結束,接下來為請求正文,這一行非常重要,必不可少,
4、請求正文
可選部分,比如GET請求就沒有請求正文,
HTTP回應報文主要由狀態行、回應頭、空行、回應正文4部分組成,
1、狀態行
由3部分組成,分別為:協議版本、狀態碼、狀態碼描述,之間由空格分隔;
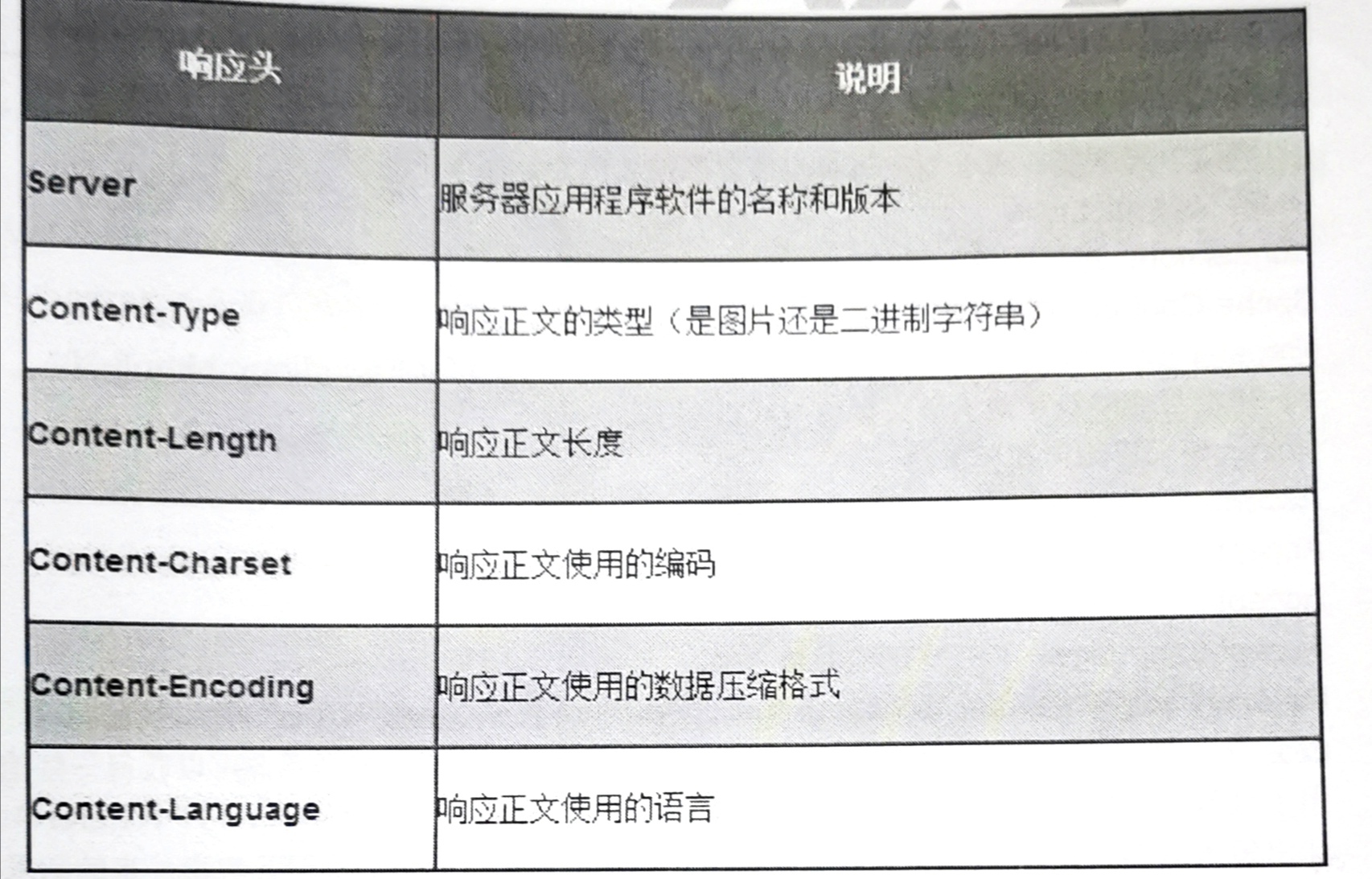
2、回應頭
與請求頭類似,為回應報文添加一些附加資訊,
常見回應頭如下:
3、空行
4、回應正文
常見HTTP首部欄位
A、通用首部欄位(請求報文與回應報文都會使用的首部欄位)
Date:創建報文時間
Connection:連接的管理
Cache-Control:快取的控制
Transfer-Encoding:報文主體的傳輸編碼方式,如Transfer-Encoding: chunked,
B、請求首部欄位(請求報文會使用的首部欄位)
Host:請求資源所在服務器
Accept:可處理的媒體型別
Accept-Charset:可接收的字符集
Accept-Encoding:可接受的內容編碼
Accept-Language:可接受的自然語言
Referer:HTTP Referer是header的一部分,當瀏覽器向web服務器發送請求的時候,一般會帶上Referer,告訴服務器我是從哪個頁面鏈接過來的,服務器可以獲得一些資訊用于處理,比如從我主頁上鏈接到一個朋友那里,他的服務器就能夠從HTTP Referer中統計出每天有多少用戶點擊我主頁上的鏈接訪問他的網站,如果是CSRF攻擊傳來的請求,Referer欄位會是包含惡意網址的地址,這時候服務器就能識別出惡意的訪問,
C、回應首部欄位(回應報文會使用的首部欄位)
Accept-Ranges:可接受的位元組范圍
Location:另客戶端重新定向到的URI
Server:HTTP服務器的安裝資訊
D、物體首部欄位(請求報文與回應報文的物體部分使用的首部欄位)
Allow:資源可支持的HTTP方法
Content-Type:物體主類的型別
Content-Encoding:物體主體適用的編碼方式
Content-Language:物體主體的自然語言
Content-Length:物體主體的位元組數
Content-Range:物體主體的位置范圍
HTTP狀態碼含義
200 OK 服務器已成功處理了請求并提供了請求的網頁,
202 Accepted 已經接受請求,但處理尚未完成,
204 No Content 沒有新檔案,瀏覽器應該繼續顯示原來的檔案,
206 Partial Content 客戶但進行了范圍請求,回應報文中由Content-Range指定物體內容的范圍,實作斷點續傳,
-----------------------------------------------------------------------------------------------------
301 Moved Permanently 永久性重定向,請求的網頁已永久移動到新位置,
302(或307) Moved Temporatily 臨時性重定向,請求的網頁臨時移動到新位置,
304 Not Modified 未修改,自從上次請求后,請求的內容未修改過,
-----------------------------------------------------------------------------------------------------
401 Unauthorized 客戶試圖未經授權訪問受密碼保護的頁面,應答侄訓包含一個WWW-Authenticate頭,瀏覽器據此顯示用戶名字/密碼對話框,然后再填寫合適的Authorization頭后再次發出請求,
403 Forbidden 服務器拒絕請求,----------403.6-IP address rejected
404 Not Found 服務器上不存在客戶機所請求的資源,
-----------------------------------------------------------------------------------------------------
500 Internal Server Error 服務器遇到一個錯誤,使其無法為請求提供服務,
HTTP中有關快取的首部欄位有哪些?HTTP的瀏覽器快取機制?
1、Last-Modified和If-Modified-Since
簡單地說,Last-Modified和If-Modified-Since都是用于記錄頁面最后修改時間的HTTP頭資訊,只是Last-Modified是由服務器王客戶但發送的HTTP頭,而If-Modified-Since則是由客戶端往服務器發送的頭,當再次請求本地存在的快取頁面時,客戶端會通過If-Modified-Since頭把瀏覽器快取頁面的最后一次被服務器修改的時間一起發到服務器去,服務器會把這個時間與服務器上實際檔案的最后修改時間進行比較,通過這個時間戳判斷客戶端的頁面是否是最新的,如果不是最新的,就回傳HTTP狀態碼200和新檔案內容,客戶端收到之后,會丟棄舊檔案,把新檔案快取起來,并顯示到瀏覽器中;如果是最新的,則回傳304告訴客戶端其本地快取的頁面是最新的,就直接把本地快取檔案顯示到瀏覽器中,這樣在網路上傳輸的資料量就會大大減少,同時也減輕了服務器的負擔,
1)什么是“Last-Modified”
在瀏覽器第一次請求某一個URL時,服務器端的回傳狀態是200,內容是你請求的資源,同時有一個Last-Modified的屬性標記此檔案在服務器端最后被修改的時間,格式類似這樣:Last-Modified:Fri, 12 May 2010 18:53:33 GMT
客戶端第二次請求此URL時,瀏覽器會向服務器傳送If-Modified-Since報頭,詢問該時間之后檔案是否有被修改過:If-Modified-Since: Fri, 12 May 2010 18:53:33 GMT
如果服務器的資源沒有變化,則自動回傳HTTP 304狀態碼,內容為空,這樣就節省了傳輸資料量,當服務器端代碼發生改變或者重啟服務器時,則重新發出資源,回傳和第一次請求時類似,從而保證不向客戶端重復發出資源,也保證當服務器有變化時,客戶端能夠得到最新的資源,
2、ETag和 If-None-Match
ETag和 If-None-Match是一種常用的判斷資源是否改變的方法,類似于Last-Modified和If-Modified-Since,但是有所不同的是Last-Modified和If-Modified-Since只判斷資源的最后修改時間,而ETag和 If-None-Match可以是資源的任何屬性,比如資源的MD5等,
ETag和 If-None-Match的作業原理是在HTTP Response中添加ETags資訊,當客戶端再次請求該資源時,將在HTTP Request中加入If-None-Match資訊(也就是ETags的值),如果服務器驗證資源的ETags沒有改變(該資源的內容沒有改變),將回傳一個304狀態;否則,服務器將回傳200狀態,并回傳該資源和新的ETags,
1)什么是“ETag”?
服務器為每個資源分配對應的ETag值,根據資源的內容得到其值,當資源內容發生改變時,其值也會改變,以下是服務器端回傳的格式:
ETag:"50b1c1d4f775c61:df3"
客戶端的查詢更新格式是這樣的:
If-None-Match:W/"50b1c1d4f775c61:df3"
如果ETag沒有改變,則回傳狀態304,這也和Last-Modified一樣,
擴展1:Last-Modified和ETags如何幫助提高性能?
聰明的開發者會把Last-Modified和ETags請求的HTTP報頭一起使用,這樣可利用客戶端的快取,因為服務器首先產生Last-Modified/Etag標記,服務器可在稍后使用它來判斷頁面是否已經被修改,本質上,客戶端通過將該記號傳回服務器要求服務器驗證其(客戶但)快取,
擴展2:既然有了Last-Modified,為什么還要用ETag欄位呢?
1)某些檔案修改非常頻繁,比如在秒以下的時間內進行修改,If-Modified-Since能檢查到的粒度是秒級的,這種修改無法體現,
2)一些檔案也許會周期性的更改,但是它的內容并不改變(僅僅改變修改的時間),這個時候我們并不希望客戶端認為這個檔案被修改了,而重新GET;
3)某些服務器不能精確的得到檔案的最后修改時間,
因此,HTTP/1.1利用Entity Tag 頭提供了更加嚴密的驗證,Last-Modified與ETag一起使用時,服務器會優先驗證ETag的值,
3、Expires/Cache-Control(優先使用)
用來控制快取的失效日期,控制瀏覽器是直接從瀏覽器快取取資料還是重新發請求到服務器取資料,
Expires是web服務器回應訊息頭欄位,在回應HTTP請求時告訴瀏覽器在過期時間前瀏覽器可以直接從瀏覽器快取取資料,而無需再次請求,Expires的一個缺點是,回傳的到期時間是服務器端的時間,這樣就存在一個問題,如果客戶端的時間與服務器的時間相差很大(比如時間不同步,或者跨時區),那么誤差就很大,所以在HTTP1.1版開始,使用Cache-Control: max-age=(秒)替代,
當服務器發出回應的時候,可以通過兩種方式來告訴客戶端快取請求:
第一種是Expires,比如:Expires: Sun, 16 Oct 2016 05:43:02 GMT
不過Expires有缺點,比如說,服務端和客戶端的時間設定可能不同,這就會使快取的失效可能并不能精確地按服務器的預期進行,
第二種是Cache-Control,比如:Cache-Control: max-age=315360000
這里宣告的是一個相對的秒數,表示從現在起,315360000秒內快取都是有效的,這樣就避免了服務端和客戶端時間不一致的問題,
但是Cache-Control是HTTP1.1才有的,不適用于HTTP1.0,而Expires既適用于HTTP1.0,也適用于HTTP1.1,所以說在大多數情況下,同時發送這兩個頭回是一個更好的選擇,當用戶端兩種頭都能決議的時候,會優先使用Cache-Control,
程序如下:
(1)客戶端請求一個頁面(A),
(2)服務器回傳頁面A,并再給A加上一個Last-Modified和ETag,
(3)客戶端展現該頁面,并將頁面連同Last-Modified和ETag的值一起快取,
(4)客戶再次請求頁面A,并將上次請求時服務器回傳的Last-Modified和ETag的值一起傳遞給服務器,
(5)服務器檢查該Last-Modified或ETag,并判斷出該頁面自上次客戶端請求之后還未被修改,直接回傳回應304和一個空的回應體,
1.首先在服務器創建一個簡單的HTML檔案,用瀏覽器訪問一下,成功表示HTML頁面,Fiddler就會產生下面的捕獲資訊,
需要留意的是:
(1)因為是第一次訪問該頁面,客戶端發請求時,請求頭中沒有If-Modified-Since標簽,
(2)服務器回傳的HTTP狀態碼是200,并發送頁面的全部內容,
(3)服務器回傳的HTTP頭標簽中有Last-Modified,告訴客戶端頁面的最后修改時間,
2.在瀏覽器中重繪一下頁面,Fiddler就會產生下面的捕獲資訊,
需要注意的是:
(1)客戶端發HTTP請求時,使用If-Modified-Since標簽,把上次服務器告訴它的檔案最后修改時間回傳到服務器端了,
(2)因為檔案沒有改動過,所以服務器回傳的HTTP狀態碼是304,沒有發送頁面的內容,
3.用文本編輯器稍微改動一下頁面檔案,保存,再用瀏覽器訪問一下,Fiddler就會產生下面的捕獲資訊,
需要注意的是:
(1)客戶端發HTTP請求時,使用If-Modified-Since標簽,把上次服務器告訴它的檔案最后修改時間回傳到服務器端了,
(2)因為檔案被改動過,兩邊的時間不一致,所以服務器回傳的HTTP狀態碼是200,并發送新頁面的全部內容,
(3)服務器回傳的HTTP頭標簽中有Last-Modified,告訴客戶端頁面的新的最后修改時間,
HTTP1.1和HTTP1.0的區別,(HTTP1.1版本的4個特性)
1、默認持久連接和流水線
HTTP/1.1默認使用持久連接,只要客戶端服務端任意一端沒有明確提出斷開TCP連接,就一直保持連接,在同一個TCP連接下,可以發送多次HTTP請求,同時,默認采用流水線的方式發送請求,即客戶端每遇到一個物件參考就立即發出一個請求,而不必等到收到前一個回應之后才能發出下一個請求,但服務器端必須按照接收到客戶端請求的先后順序依次回送相應結果,以保證客戶端能夠區分出每次請求的相應內容,這樣也顯著地減少了整個下載程序所需要的時間,
HTTP/1.0默認使用短連接,要建立長連接,可以在請求訊息中包含Connection: Keep-Alive頭域,如果服務器愿意維持這條連接,在回應訊息中也會包含一個Connection: Keep-Alive的頭域,Connection請求頭的值為Keep-Alive時,客戶端通知服務器回傳本次清秋節過后保持連接;Connection請求頭的值為close時,客戶端通知服務器回傳本次請求結果后關閉連接,
2、分塊傳輸資料
HTTP/1.0可用來指定物體長度的唯一機制是通過Content-Length欄位,靜態資源的長度可以很容易的確定,但是對于動態生成的回應來說,為獲取它的真是長度,只能等它完全生成之后,才能正確地填寫Content-Length的值,這便要求快取整個回應,在服務器端占用大量的快取,從而延長了回應用戶的時間,
HTTP/1.1引入了被稱為分塊(chunked)的傳輸方法,該方法使發送方能將訊息物體分割為任意大小的組塊(chunk),并單獨地發送它們,在每個組塊前面,都加上了該組塊的長度,使接收方可確保自己能夠完整地接收到這個組塊,更重要的是,在最末尾的地方,發送方生成了長度為零的組塊,接收方可據此判斷整條訊息都已安全地傳輸完畢,這樣也避免了在服務器端占用大量的的快取,Transfer-Encoding:chunked向接收方指出:回應將被分組塊,對回應分析時,應采取不同于非分組塊的方式,
3、狀態碼 100 Continue
HTTP/1.1加入了一個新的狀態碼 100 Continue,用于客戶端在發送POST資料給服務器前,征詢服務器的情況,看服務器是否處理POST資料,
當要POST的資料大于1024位元組的時候,客戶端并不會直接就發起了POST請求,而是會分為2步:
(1)發送一個請求,包含一個Except: 100-continue,詢問Server是否愿意接受資料,
(2)接收到Server回傳的100 continue應答以后,才把資料POST給Server,
這種情況通常發生在客戶端準備發送一個冗長的請求給服務器,但是不確認服務器是否有能力接收,如果沒有得到確認,而將一個冗長的請求包發送給服務器,然后包被服務器給拋棄了,這種情況挺浪費資源的,
4、Host域
HTTP1.1在Request訊息頭里多了一個Host域,HTTP1.0則沒有這個域,在HTTP1.0中認為每臺服務器都系結一個唯一的IP地址,這個IP地址上只有一個主機,但隨著虛擬主機技術的發展,在一臺物理服務器上可以存在多個虛擬主機,并且它們共享一個IP地址,
常用的HTTP方法有哪些?

注意:只有POST和PUT方法才有請求內容,
GET:用于請求訪問已經被URI(統一資源識別符號)識別的資源,可以通過URL傳參給服務器,
POST:用于傳輸資訊給服務器,主要功能與GET方法類似,但一般推薦使用POST方式,
PUT:傳輸檔案,報文主體中包含檔案內容,保存到對應URI位置,
HEAD:獲得報文首部,與GET方法類似,只是不回傳報文主體,
DELETE:洗掉檔案,與PUT方法相反,洗掉對應URI位置的檔案,
OPTIONS:查詢相應URL支持的HTTP方法,
注意:并非所有的服務器都實作了這幾個方法,有的服務器還實作了自己持有的HTTP方法,稱為擴展方法,
GET:GET可以說是最常見的了,它本質就是發送一個請求來取得服務器上的某一資源,資源通過一組HTTP頭和呈現資料回傳給客戶端,GET請求中,永遠不會包含呈現資料,
HEAD:HEAD和GET本質是一樣的,區別在于HEAD不含有呈現資料,而僅僅是HTTP頭資訊,有的人可能覺得這個方法沒什么用,其實不是這樣的,想象一個業務情景:欲判斷某個資源是否存在,我們通常用GET,但這里用HEAD則意義更加明確,
PUT:這個方法比較少見,HTML表單也不支持這個,本質上來講,PUT和POST極為相似,都是向服務器發送資料,但它們之間有一個重要區別,PUT通常指定了資源的存放位置,而POST沒有,POST的資料存放位置由服務器自己決定,舉個例子:如一個用于提交博文的URL,/addBlog,如果用PUT,則提交的URL會是像這樣的“/addBlog/abc123”,其中的abc123就是這個博文的地址,而如果用POST,則這個地址會在提交后由服務器告知客戶端,目前大部分博客都是這樣的,顯然,PUT和POST用途是不一樣的,具體用哪個還取決于當前業務場景,
DELETE:洗掉某一個資源,基本上這個也很少見,不過還是有一些地方比如amazon的S3云服務里面就用的這個方法來洗掉資源,
POST:向服務器提交資料,這個方法用途廣泛,幾乎目前所有的提交操作都是靠這個完成,
OPTIONS:這個方法很有趣,但極少使用,它用于獲取當前URL所支持的方法,若請求成功,則它會在HTTP頭中包含一個名為“Allow”的頭,值是所支持的方法,如“GET,POST”,
TRACE:請求服務器回送收到的請求資訊,主要用于測驗和判斷,所以是安全的,
HEAD、GET、OPTIOINS和TRACE視為安全的方法,因為它們只是從服務器獲得資源而不對服務器做任何修改;但是HEAD、GET、OPTIONS在用戶端不安全,而POST則影響服務器上的資源,
GET雖然不修改服務器資料,但是GET方法通過URL請求來傳遞用戶的輸入;HEAD只獲得訊息的頭部,但是資料傳入也是通過URL, 這樣對客戶端而言并不安全,
TRACE方法對與服務端和用戶端一定是安全的,
HTTP的請求方式get和post的區別?
1、GET一般用于獲取或者查詢資源資訊,這就意味著它是冪等的(對于同一個URL的多個請求回傳同樣的結果)和安全的(沒有修改資源的狀態),而POST一般用于更新資源資訊,POST既不是安全的,也不是冪等的,
2、采用GET方法時,客戶端把要發送的資料添加到URL后面(就是把資料放置在HTTP協議頭中,GET是通過URL提交資料的),并用“?”連接,各個變數之間用“&”連接;
HTTP協議沒有對URL長度進行限制,由于特定的瀏覽器及服務器對URL的長度在限制,所以傳遞的資料量有限;
通過GET提交資料,用戶名和密碼將明文出現在URL上,因為(1)登陸頁面有可能被瀏覽器快取;(2)其他人查看瀏覽器的“歷史記錄”,那么別人就可以拿到你的賬號和密碼了,
而POST把要傳遞的資料放到HTTP請求報文的訊息體中;HTTP協議也沒有進行大小限制,起限制作用的是服務器處理程式的能力,但是,傳送的資料量比GET方法更大些;由于傳遞的資料在訊息體中,安全性高,但其實用抓包軟體(如httpwatch)進行抓包的話,可以看到傳遞的資料內容的,
3、GET請求的資料會被瀏覽器快取起來,會留下歷史記錄;而POST提交的資料不會被瀏覽器快取,不會留下歷史記錄,
為什么HTTP是無狀態的?如何保持狀態(會話跟蹤技術、狀態管理)?
HTTP無狀態:無狀態是指協議對于事務處理沒有記憶能力,不能保存每次客戶端提交的資訊,即當服務器回傳應答之后,這次事務的所有資訊就都丟掉了,如果用戶發來一個新的請求,服務器也無法知道它是否與上次的請求有聯系,
這里我們用一個比較熟悉的例子來解釋HTTP的無狀態性,如一個包含多圖片的網頁的瀏覽,步驟為:(1)建立連接,客戶端發送一個請求,服務器端回傳一個HTML頁面(這里的頁面只是一個純文本的頁面,也就是我們寫的HTML代碼),關閉連接;(2)瀏覽器決議HTML檔案,遇到圖片標記得到url,這時,客戶端和服務器再建立連接,客戶端發送一個圖片請求,服務器回傳圖片應答,關閉連接,(這里又涉及到無狀態定義:對于服務器來說,這次的請求雖然是同一個客戶端的請求但是服務器還是不知道這個是之前的那個客戶端,即對于事務處理沒有記憶能力),
優點:服務器不用為每個客戶端連接分配記憶體來記憶大量狀態,也不用在客戶端失去連接時去清理記憶體,節省服務器端資源,以更高效地去處理業務,
缺點:缺少狀態意味著如果后續處理需要前面的資訊,則客戶端必須重傳,這樣可能導致每次連接每次連接傳送的資料量增大,
針對這些缺點,可以采用會話跟蹤技術來解決這個問題,把狀態保存在服務器中,只發送回一個識別符號,瀏覽器在下次提交中把這個識別符號發送過來;這樣,就可以定位存盤在服務器上的狀態資訊了,
有四種會話跟蹤技術:
-
- COOKIE
- Session
- URL 重寫
- 作為隱藏域嵌入HTML表單中(隱藏表單域)
在瀏覽器和服務器之間來回傳遞一個識別符號,這就是所謂的會話(session)跟蹤,來自瀏覽器的所有包含同一個識別符號(這里是SESSIONID)的請求同屬于一個會話,
會話的有效期直到它被顯式地終止為止,或者當用戶在一段時間內沒有動作,由服務器自動設定為過期,目前沒有辦法通知服務器用戶已經關閉瀏覽器,因為在瀏覽器和服務器之間沒有一個持久的連接,并且瀏覽器關閉時也不向服務器發送資訊,同時,關閉瀏覽器通常意味著會話ID丟失,COOKIE將過期,或者注入了資訊的URL將不能再使用,所以當用戶再次打開瀏覽器的時候,服務器無法將新得到的請求與以前的會話聯系起來,則只能創建一個新的會話,然而,所有與前一個會話有關的資料依然存在服務器上,直到會話過期被清除為止,
HTTP的短連接和長連接的原理
HTTP協議既可以實作長連接,也可以實作短連接,
在HTTP/1.0中,默認使用的是短連接,也就是說,瀏覽器和服務器每進行一次HTTP操作,就建立一次連接,但任務結束就中斷連接,如果客戶端訪問的某個HTML或其他型別的web頁中包含有其他的web資源,如JavaScript檔案、影像檔案、CSS檔案等,當瀏覽器每遇到這樣一個web資源,就會建立一個HTTP會話,HTTP1.0需要在request中增加“Connection: keep-alive”,header才能夠支持長連接,
HTTP1.0 KeepAlive支持的資料互動流程如下:
1)Client發出request,其中該request的HTTP版本號為1.0,同時在request中包含一個header:“Connection: keep-alive”,
2)web sever收到request中的HTTP協議為1.0及“Connection: keep-alive”就認為是一個長連接請求,其將在response的header中也增加“Conection: keep-alive”,同時不會關閉已建立的TCP連接,
3)Client收到web server的response中包含“Connection: keep-alive”,就認為是一個長連接,不關閉TCP連接,并用該TCP連接再發送request,(跳轉到1))
但從HTTP/1.1起,默認使用長連接,用以保持連接特性,使用長連接的HTTP協議,會在請求頭和回應頭加入這行代碼,Connection: keep-alive,
在使用長連接的情況下,當一個網頁打開完成后,客戶端和服務器之間用于傳輸HTTP資料的TCP鏈接不會關閉,如果客戶端再次訪問這個服務器上的網頁,會繼續使用這一條已經建立的連接(HTTP長連接利用同一個TCP連接處理多個HTTP請求和回應),
Keep-Alive不會永久保持連接,它有一個保持時間,可以在不同的服務器軟體(如Apache)中設定這個時間,實作長連接要客戶端和服務端都支持長連接,長連接中關閉連接通過Connection:closed頭部欄位,如果請求或回應中的Connection被指定為closed,表示在當前請求或相應完成后將關閉TCP連接,TCP的keep-alive是檢查當前TCP連接是否活著;HTTP的Keep-Alive是要讓一個TCP連接活久點,
HTTP1.1 Keep-Alive支持的資料互動流程如下:
1)Client發出request,其中該request的HTTP版本號為1.1,
2)web server收到request中的協議為1.1就認為是一個長連接請求,其將在response的header中也增加“Connection: keep-alive”,同時不會關閉已建立的TCP連接,
3)Client收到 web server的response中包含“Connection:keep-alive”,就認為是一個長連接,不會關閉TCP請求,并用該TCP連接再發送request,(跳轉到 1))
HTTP協議的長連接和短連接,實質上是TCP協議的長連接和短連接,
HTTP長連接的優點:
1)通過開啟和關閉更少的TCP連接,節約CPU時間和記憶體,
2)通過減少TCP開啟和關閉引起的包的數目,降低網路阻塞,
HTTP長連接的缺點:
服務器維護一個長連接會增加開銷,
HTTP短連接的優點:
服務器不用為每個客戶端連接分配記憶體來記憶大量狀態,也不用在客戶端失去連接時去清理記憶體,節省服務器端資源,以更高效地去處理業務,
HTTP短連接的缺點:
如果客戶請求頻繁,將在TCP的建立和關閉操作上浪費時間和帶寬,
HTTP的特點
(1)支持客戶端/服務器端通信模式,
(2)簡單方便快速:當客戶端向服務器端發送請求時,只是簡單的填寫請求路徑和請求方法即可,然后就可以通過瀏覽器或其他方式將該請求發送就行了,比較常用的請求方法有三種,分別是:GET、HEAD、POST,不同的請求方法使得客戶端和服務器聯系的方式各不相同,因為HTTP協議比較簡單,所以HTTP服務器的程式規模相對比較小,從而使得通信的速度非常快,
(3)靈活:HTTP協議允許客戶端和服務器傳輸任意型別任意格式的資料物件,這些不同的型別由Content-Type標記,
(4)無連接:無連接的含義是每次建立的連接只處理一個客戶端請求,當服務器處理完客戶端的請求之后,并且受到客戶的反饋應答后,服務器端立即斷開連接,采用這種通信方式可以大大的節省傳輸時間,
(5)無狀態:HTTP是無狀態的協議,所謂的無狀態是指協議對于請求的處理沒有記憶功能,無狀態意味著如果再次處理先前的資訊,則這些先前的資訊必須要重傳,這就導致了資料量傳輸的增加,但是從另一方面來說,當先前的資訊服務器不再使用的時候,則服務器的回應將會非常快,
HTTP的安全問題
a、通信使用明文不加密,內容可能被竊聽,
b、不驗證通信方身份,可能遭到偽裝,
c、無法驗證報文完整性,可能被篡改,
HTTPS就是HTTP加上加密處理(一般是SLL安全通信線路)+認證+完整性保護
HTTPS的作用
- 內容加密 建立一個資訊安全通道,來保證資料傳輸的安全;
- 身份認證 確認網站的真實性;
- 資料完整性 防止內容被第三方冒充或者篡改;
瀏覽器和服務器在基于HTTPS進行請求連接到資料傳輸程序中,用到哪些技術?
1、對稱加密演算法
用于對真正傳輸的資料進行加密,
2、非對稱加密
用于在握手程序中加密生成的密碼,非對稱加密演算法會生成公鑰和私鑰,公鑰只能用于加密資料,因此可以隨意傳輸,而網站的私鑰用于對資料進行解密,所以網站都會非常小心地保管自己的私鑰,防止泄漏,
3、散列演算法
用于驗證資料的完整性,
4、數字證書
資料證書其實就是一個小的計算機檔案,其作用類似于我們的身份證、護照,用于證明身份,在SSL中,使用數字證書來證明自己的身份,
客戶端有公鑰,服務器有私鑰,客戶端用公鑰對‘對稱密鑰’進行加密,將加密后的對稱密鑰發送給服務器,服務器用私鑰對其進行解密,所以客戶端和服務器可用對稱密鑰來進行通信,公鑰和私鑰是用來加密密鑰,而對稱加密是用來加密資料,分別利用了兩者的優點,
講下HTTP協議
主要包括HTTP建立連接的程序,持久和非持久連接,帶流水與不帶流水,DNS決議程序,GET和POST區別,HTTP與HTTPS的區別等,狀態碼,header各個欄位的意義,
HTTP和Socket的區別,兩個協議哪個更高效一點?
創建socket鏈接時,可以指定使用的傳輸層協議,socket可以支持不同的傳輸層協議(TCP或UDP),當使用TCP協議進行連接時,該socket連接就是一個TCP連接,socket連接一旦建立,通信雙方即可開始發送資料內容,直到雙方連接斷開,注意,同HTTP不同的是HTTP只能基于TCP,socket不僅能走TCP,而且還能走UDP,這個是socket的第一個特點,
HTTP連接使用的是“請求-回應”的方式,不僅在請求時需要先建立連接,而且需要客戶端向服務器發出請求后,服務器端才能回復資料,
很多情況下,需要服務器端主動向客戶端推送資料,保持客戶端與服務器資料的實時與同步,此時若雙方建立的是socket連接,服務器就可以直接將資料傳送給客戶端;若雙方建立的是HTTP連接,則服務器需要等到客戶端發送一次請求后才能將資料傳回給客戶端,
socket效率高,至少不用決議HTTP報文頭部一些欄位,
HTTP與HTTPS的區別
- HTTPS更安全
HTTPS協議是由SSL+HTTP協議構建的可進行加密傳輸、身份認證的網路協議,要比HTTP協議安全,所有傳輸的內容都經過加密,加密采用對稱加密,但對稱加密的密鑰用服務器方的證書進行了非對稱加密,HTTP是超文本傳輸協議,資訊是明文傳輸,沒有加密,通過抓包工具可以分析其資訊內容,
- HTTPS需要申請證書
HTTPS協議需要到CA申請證書,一般免費證書很少,需要交費,而常見的HTTP協議則沒有這一項,
- 埠不同
HTTP使用的是80埠,而HTTPS使用的是443埠,
- 所在層次不同
HTTP協議運行在TCP之上,HTTPS是運行在SSL/TLS之上的HTTP協議,SSL/TLS運行在TCP之上,
補充
HTTP斷點續傳的原理
要實作斷點續傳下載檔案,首先要了解斷點續傳的原理,斷點續傳其實就是在上一次下載斷開的位置開始繼續下載,HTTP協議中,可以在請求報文頭中加入Range段,來表示客戶機希望從何處繼續下載,在以前版本中HTTP協議是不支持斷點的,HTTP/1.1開始就支持了,一般斷點下載時才用到Range和Content-Range物體頭,
1 例子1:
2 GET /test.txt HTTP/1.1
3 Accept:*/*
4 Referer:http://192.168.1.96
5 Accept-Language:zh-cn
6 Accept-Encoding:gzip,deflate
7 User-Agent:Mozilla/4.0(compatible;MSIE 6.0; Windows NT 5.2; .NET CLR 2.0.50727)
8 Host:192.168.1.96
9 Connection:Keep-Alive
10
11 這表示從1024位元組開始斷點續傳(加入了Range:bytes=1024-):
12 GET /test.txt HTTP/1.1
13 Accept:*/*
14 Referer:http://192.168.1.96
15 Accept-Language:zh-cn
16 Accept-Encoding:gzip,deflate
17 User-Agent:Mozilla/4.0(compatible;MSIE 6.0; Windows NT 5.2; .NET CLR 2.0.50727)
18 Host:192.168.1.96
19 Range:bytes=1024- //Range:bytes=0-10000(從0編號)告訴服務器 /test.txt這個檔案從1024位元組開始傳,前面的位元組不用傳了,
20 Connection:Keep-Alive
21
22 -------------------------------------------------------------
23
24 例子2:
25 Connection:close
26 Host:127.0.0.3
27 Accept:*/*
28 Pragma:no-cache
29 Cache-Control:no-cache
30 Referer:http://127.0.0.3/
31 User-Agent:Mozilla/4.04 [en] (Win95;I;Nav)
32 Range:bytes=5275648-
33 HTTP/1.1 206 Partial Content
34 Server:Zero Http Server/1.0
35 Date:Thu, 12 Jul 2001 11:19:40 GMT
36 Cache-Control:no-cache
37 Last-Modified:Tue, 30 Jan 2001 13:11:30 GMT
38 Content-Type:application/octet-stream
39 Content-Range:bytes 5275648-15143085/15143086
40 Content-Length:9867438
41 Connection:close
擴展:服務器斷點續傳檔案增強驗證(If-Range,If-Match)
1、用If-Range進行增強校驗
If-Rnage中的內容可以為最初收到的ETag頭或者是Last-Modified中的最后修改時間,服務端在收到續傳請求時,通過If-Range中的內容進行校驗,看檔案的內容是否發生了變化,校驗一致時(檔案內容沒有發生變化時),回傳206的續傳回應;不一致時(檔案內容發生了變化),服務算回傳200回應,回應的內容為新的檔案的全部資料,
2、用If-Match進行增強校驗與Http 412問題
If-Match:"40e04a44a997d11:0" //第一次獲取到的ETag的值
如果服務器端的資源被修改了,那么,http請求時會發生 http 412 Precondition failed 先決條件失敗,因此,我們建議使用If-Range,這樣,即使檔案被修改,也會以 http 200回傳全部資源,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/24680.html
標籤:其他
上一篇:樹---把二叉樹列印成多行