這篇文章主要是介紹下我經歷的一些比較難已提取OCR部分的圖片,從而介紹下一些特別的處理方式,
第一種:差分高斯diff_of_gauss(近似拉普拉斯高斯)
原圖如下:一般的方法基本提取不出來相應的字符,

那我們可以通過差分高斯這個算子直接得出很好的效果圖,代碼以及效果圖如下:
read_image (Image, 'C:/Users/Administrator/Desktop/3.bmp')
rgb1_to_gray (Image, GrayImage)
*差分高斯
diff_of_gauss (GrayImage, DiffOfGauss, 3, 1.6)
threshold (DiffOfGauss, Regions, 2, 12)

這個效果可以直接進行處理,參照我之前的處理OCR的程式,直接就可以得出結果了,這里我就不再寫了,
第二種:環形的字符,主要的思路就是通過極坐標轉換,將環形部分拉直,剩下的就是正常的字符讀取了,
原圖:

read_image (Image, 'C:/Users/Administrator/Desktop/環形字符.png"/>
環形字體拉直效果圖:
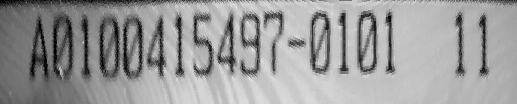
最終結果圖:

一般字體所處的圓環部分,兩次形態學處理再加一次difference,可以直接得出來,這種套路方法一般也應在找邊緣的地方,正常的處理這種圓環中讀取OCR,主要就是polar_trans_image_ext這個算子,其他的都是一些預處理手段,
第三種斜體字處理
原圖:
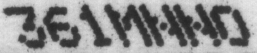
代碼如下:
read_image (Image, 'C:/Users/Administrator/Desktop/斜體字練習.png"/>
處理得到的結果:

以上就是一些需要經過特殊處理之后才能夠正常讀取OCR的三種常見方法,當然還有一些更為難得專案,就比如那種刻字和本體顏色無差異的,而且字體是下沉或者凸起的,遇到這種的話首先先考慮通過低距離低角度打光突出邊緣,如果光源搭設被限制住,那么就可以考慮光度立體這種方法來解決了(diff_of_gauss效果不行的情況下),
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/246914.html
標籤:其他
上一篇:os1-8章重點復習
下一篇:分享給大家的一些軟體資訊