文章目錄
- 1. RecSim介紹
- 2. RecSim安裝
- 2.1. 環境配置
- 2.2. 安裝步驟
- 3. 運行RecSim示例
- 4. 自定義RecSim環境
- 4.1. 概覽
- 4.2. 模擬場景:專業 vs 喜聞樂見
- 4.2.1. 記錄模型 document
- 4.2.2. 用戶模型 user
- 4.2.2.1. 用戶狀態和用戶采樣器
- 4.2.2.2. 回應模型
- 4.2.2.3. 用戶模型
- 4.2.2.4. 與Agent的互動
- 4.2.3. 模擬場景的試運行
- 5. 自定義Agent
- 5.1. 觀測 Observation
- 5.2. 候選串列 Slate
- 5.3. 搭建Agent
- 5.3.1. 簡單Agent
- 5.3.2. 層次化Agent結構
- 5.3.2.1. ClusterClickStats
- 5.3.2.2. AbstractClickBandit
- 6. RecSim參考檔案
1. RecSim介紹
RecSim是一個可配置的推薦系統仿真平臺,它通過真實推薦系統的用戶資料來構建模擬可控的仿真環境,為推薦系統模型演算法的開發、測評以及對比提供了便利的環境,同時,它作為開源系統為研究人員提供了強化學習與推薦系統的交叉研究環境、并支持模型與演算法的重用與分享,也為學術界和工業界提供了協作的平臺,在無需暴露用戶資料和敏感的行業策略的情況下就能進行有效的研究,
2. RecSim安裝
2.1. 環境配置
RecSim開發者給出的示例中使用的TensorFlow版本是Tensorflow 1.15.0,然而默認安裝的TensorFlow是Tensorflow 2.x,由于這兩個版本的TensorFlow差異巨大,因此必須先解決TensorFlow的版本問題才能正常運行示例代碼,
這里建議選擇先修改TensorFlow版本到Tensorflow 1.15.0,再體驗完RecSim的示例代碼后再自行升級或換用其他工具,
根據 TensorFlow Windows設定 中的提示,無論是CPU版本還是GPU版本的Tensorflow 1.15.0,都僅適用于Python 3.5-3.7,如果是按照GPU版本,還需要額外注意一下 cuDNN 和 CUDA 的版本:
| 版本 | Python 版本 | 編譯器 | 構建工具 | cuDNN | CUDA |
|---|---|---|---|---|---|
| tensorflow-1.15.0 | 3.5-3.7 | MSVC 2017 | Bazel 0.26.1 | × | × |
| tensorflow_gpu-1.15.0 | 3.5-3.7 | MSVC 2017 | Bazel 0.26.1 | 7.4 | 10 |
如果自己設備上的Python版本不在Python 3.5-3.7這個范圍內,建議使用模擬環境(如Pycharm的venv)或者 重新安裝
在確定自己的Python版本之后,并且安裝好RecSim后,使用如下代碼更改TensorFlow版本(選其中一個安裝即可):
pip install tensorflow==1.15.0 # CPU版本
pip install tensorflow_gpu==1.15.0 # GPU版本
博主最終選擇的配置如下:
| 工具 | 版本 |
|---|---|
| Python | 3.7 (Pycharm模擬環境) |
| cuDNN | cuDNN v7.4.2, for CUDA 10.0 |
| CUDA | CUDA Toolkit 10.0 |
| tensorflow | tensorflow_gpu 1.15.0 |
2.2. 安裝步驟
打開終端,使用如下命令下載安裝RecSim:
python -m pip install --upgrade pip
pip install recsim
如果上述命令一直連接不成功,那么可以到 recsim· PyPI 下載recsim-0.2.4.tar.gz,在命令提示符下轉到解壓后的目錄,再輸入:
python setup.py install
等待一段時間之后如果顯示了如下資訊,則說明安裝成功:
Successfully built recsim gym
Installing collected packages: gym, google-pasta, gin-config, gast, flatbuffers, astunparse, tensorflow, dopamine-rl, recsim
Successfully installed astunparse-1.6.3 dopamine-rl-3.0.1 flatbuffers-1.12 gast-0.3.3 gin-config-0.4.0 google-pasta-0.2.0 gym-0.18.0 recsim-0.2.4 tensorflow-2.4.0
接著在GitHub上把 google-research/recsim 中的代碼下載下來,解壓后是一個名為recsim-master 的目錄,用常用的編輯器或IDE打開該目錄下的 ./recsim-master/recsim-master/recsim目錄,這里面是整個RecSim的Python代碼,
例如用Pycharm打開./recsim-master/recsim-master/recsim目錄后顯示如下:
3. 運行RecSim示例
在github下載的RecSim架構自帶有以下論文的復現代碼:
SlateQ: A Tractable Decomposition for Reinforcement Learning with Recommendation Sets. IJCAI 2019: 2592-2599
找到 main.py ,其內容如下:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from absl import app
from absl import flags
import numpy as np
from recsim.agents import full_slate_q_agent
from recsim.environments import interest_evolution
from recsim.simulator import runner_lib
FLAGS = flags.FLAGS
def create_agent(sess, environment, eval_mode, summary_writer=None):
kwargs = {
'observation_space': environment.observation_space,
'action_space': environment.action_space,
'summary_writer': summary_writer,
'eval_mode': eval_mode,
}
return full_slate_q_agent.FullSlateQAgent(sess, **kwargs)
def main(argv):
if len(argv) > 1:
raise app.UsageError('Too many command-line arguments.')
runner_lib.load_gin_configs(FLAGS.gin_files, FLAGS.gin_bindings)
seed = 0
slate_size = 2
np.random.seed(seed)
env_config = {
'num_candidates': 5,
'slate_size': slate_size,
'resample_documents': True,
'seed': seed,
}
runner = runner_lib.TrainRunner(
base_dir=FLAGS.base_dir,
create_agent_fn=create_agent,
env=interest_evolution.create_environment(env_config),
episode_log_file=FLAGS.episode_log_file,
max_training_steps=50,
num_iterations=10)
runner.run_experiment()
runner = runner_lib.EvalRunner(
base_dir=FLAGS.base_dir,
create_agent_fn=create_agent,
env=interest_evolution.create_environment(env_config),
max_eval_episodes=5,
test_mode=True)
runner.run_experiment()
if __name__ == '__main__':
flags.mark_flag_as_required('base_dir')
app.run(main)
在終端輸入:
# Linux (Windows要把"/"改成"\\")
# base_dir 指定了輸出目錄
# gin_bindings 指定了資料系結引數
python main.py --base_dir=./tmp/interest_evolution --gin_bindings=simulator.runner_lib.Runner.max_steps_per_episode=50
等待其訓練結束,在終端下找到最后輸出的eval_file地址:
I0105 14:22:51.851023 7280 runner_lib.py:483] eval_file: .\\tmp\\interest_evolution\eval_5\returns_500
然后復制eval_file檔案的目錄,帶入到以下終端命令中,例如:
# 注意logdir填寫 ./tmp/interest_evolution/eval_5/
# 而不是 ./tmp/interest_evolution/eval_5/returns_500
tensorboard --logdir=./tmp/interest_evolution/eval_5/ --host=127.0.0.1
執行之后會得到一個本地鏈接,用瀏覽器打開它
2021-01-05 14:52:00.686903: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_100.dll
TensorBoard 1.15.0 at http://127.0.0.1:6006/ (Press CTRL+C to quit)
在瀏覽器地址欄輸入http://127.0.0.1:6006/后可以得到如下界面,這就是TensorFlow訓練程序的圖形化的顯示了:
4. 自定義RecSim環境
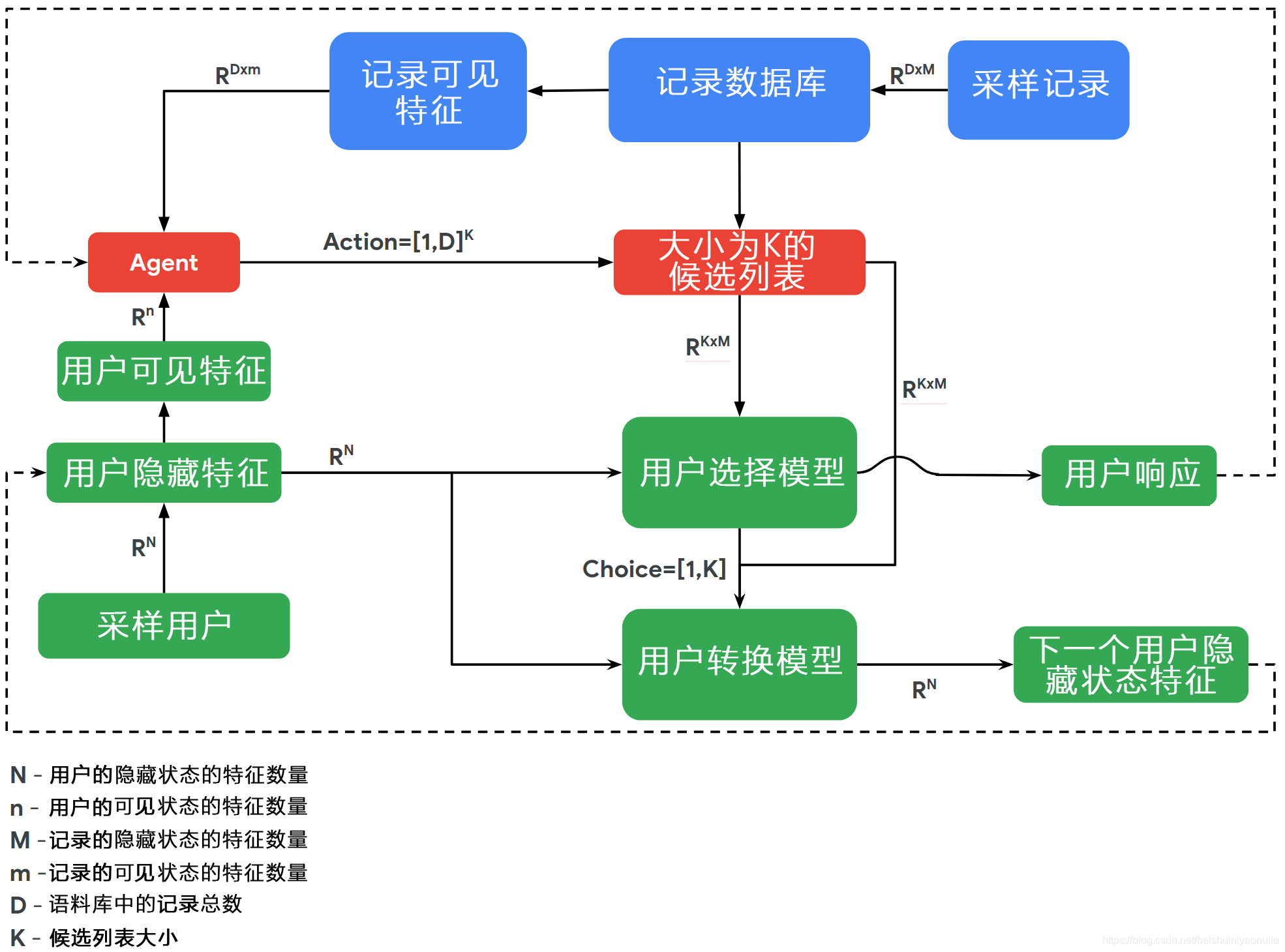
首先我們來看一下RecSim的架構圖,下圖中的綠色和藍色塊表示了RecSim中實作的類,本節將解釋這些類,以及描述它們通過何種方式聚合在一起,并且通過一些小例子來說明它們的具體組織實作方式,
4.1. 概覽
一個RecSim模擬步驟大致可以概括如下:
- 記錄(document)資料庫為推薦器提供 D D D 個記錄的語料庫,每個步驟都可以有不同的記錄資料集(由采樣或某個“候選生成”程序產生),或在整個模擬程序中采用固定的記錄資料集,每個記錄都由一個特征串列表示,在完全可觀察到的情況下,推薦器會觀察每個記錄擁有的可以影響用戶狀態和記錄選擇(以及用戶回應的其他方面)的特征,除此之外,大多數場景都包含了一些無法直接觀察到的特征,
- 推薦器會觀察 D D D 個記錄(及其特征)以及用戶對最后一個推薦的回應,然后選擇(可能是有序的) 其中 k k k 個記錄,并將它們呈現給用戶,排序可能會影響用戶選擇或用戶狀態,因此是否排序以及如何排序取決于我們的模擬目的,
- 用戶查看記錄候選串列并選擇其中一個記錄,或不選擇任何一個記錄,之后用戶狀態會變化,并且輸出一個觀察結果,推薦器在下一次迭代時檢查該觀察結果,觀察通常包括關于用戶對所選擇記錄內容的反饋,以及關于用戶隱藏狀態的潛在線索,通常,用戶的狀態是不完全可見的,
如果我們仔細看上面的圖表,我們會注意到沿著弧線的資訊流是無回圈的,這意味著RecSim環境是一個動態貝葉斯網路(DBN),其中的各種盒子代表條件概率分布,現在我們將簡單模擬一個問題場景并實作它,
4.2. 模擬場景:專業 vs 喜聞樂見
考慮以下場景:我們的語料庫元素的特征有兩種,分別是專業的記錄和喜聞樂見的記錄(document),
喜聞樂見的記錄在用戶中有很高的參與度,但長期過度參與這些記錄會導致用戶滿意度下降,另一方面,專業的記錄在用戶中的參與度相對較低,但參與專業的記錄會帶來長期的滿足感,我們將這種記錄的屬性建模為一個連續特征,稱為專業度(Prof),其值設定在 [ 0 , 1 ] [0,1] [0,1]區間內,得分為1的記錄是非常專業的,而得分為0的記錄是非常讓用戶喜聞樂見的,
用戶的隱藏狀態由一個一維的滿意度變陣列成,每次參與更多的專業的記錄時,滿意度會增加,反之,參與喜聞樂見的記錄時會降低滿意度,在參與一個記錄時,用戶的參與度可以通過某些特征來度量(例如觀看時長等),預期參與度的大小與用戶的滿意度成正比,與記錄內容的專業度成反比,
我們的目標是找到專業和喜聞樂見的最佳比例組合,以便長期保持用戶粘性,在接下來的討論中,我們將討論不同組件的在本模擬場景中的實作方法,
RecSim中的user(用戶)和document(記錄)提供了實體化上述場景的所有組件所需的抽象類,
首先匯入需要的RecSim包
from gym import spaces
import numpy as np
from recsim import document
from recsim import user
from recsim.simulator import environment
from recsim.simulator import recsim_gym
4.2.1. 記錄模型 document
RecSim 記錄(document)是繼承自RecSim.document.AbstractDocument的類,它是document模型、Agent和用戶(user)之間的主要交換單元,document類實作本質上是底層document特征(所有可見的和隱藏的特征)的容器,基類需要實作一個observation_space()靜態方法,將document可見特征的格式宣告為OpenAI gym空間,以及一個create_observe()函式,該函式回傳所述空間的實作,另外,每個document必須有一個唯一的整數ID,
在我們的模擬場景中,document只有一個特征,即它們的專業度(Prof),用一維空間Box來表示,
# 記錄(document)模型
class SIMDocument(document.AbstractDocument):
def __init__(self, doc_id, prof):
self.prof = prof
super(SIMDocument, self).__init__(doc_id)
# 構建環境,回傳OpenAI gym動作空間的實作
def create_observation(self):
return np.array([self.prof])
# 將document的可見特征的格式宣告為OpenAI gym動作空間
@staticmethod
def observation_space():
return spaces.Box(shape=(1,), dtype=np.float32, low=0.0, high=1.0)
# 回傳document物件的描述資訊,自動呼叫
def __str__(self):
return "Document {} with Prof {}.".format(self._doc_id, self.prof)
實作了document模型之后,我們現在需要設計一個document采樣器,document采樣器用于按一定規則生成或抽取document,可以在每個步驟或每個會話結束之后呼叫采樣器來重新生成語料庫(這取決于runner_lib的設定),document在sample_document()函式中生成,它按我們設定的分布規則采樣document,
在我們的模擬場景中,采樣器按均勻分布生成document(包含document的id、專業度Prof),
# document采樣器模型
class SIMDocumentSampler(document.AbstractDocumentSampler):
# 采樣器初始化,自動呼叫
def __init__(self, doc_ctor=SIMDocument, **kwargs):
super(SIMDocumentSampler, self).__init__(doc_ctor, **kwargs)
self._doc_count = 0
# 對document采樣
def sample_document(self):
doc_features = {}
doc_features['doc_id'] = self._doc_count # 賦予ID
doc_features['prof'] = self._rng.random_sample() # 均勻分布采樣
self._doc_count += 1 # ID自增1
return self._doc_ctor(**doc_features)
有了document模型以及document采樣器之后,就可以模擬document了,如下代碼,我們用采樣器生成了5個document模型,它們分別都有各自的專業度(Prof)
# 臨時除錯用
if __name__ == '__main__':
sampler = SIMDocumentSampler() # 實體化一個采樣器
# 采樣5個document
for i in range(5):
print(sampler.sample_document())
d = sampler.sample_document()
print("Documents have observation space:", d.observation_space(), "\nAn example realization is: ", d.create_observation())
輸出:
Document 0 with Prof 0.5488135039273248.
Document 1 with Prof 0.7151893663724195.
Document 2 with Prof 0.6027633760716439.
Document 3 with Prof 0.5448831829968969.
Document 4 with Prof 0.4236547993389047.
Documents have observation space: Box(0.0, 1.0, (1,), float32)
An example realization is: [0.64589411]
Process finished with exit code 0
4.2.2. 用戶模型 user
上一節中我們構造了一個可用的document模型以及它的采樣器,現在我們來構造用戶模型,
用戶模型由以下組件組成:
- 用戶狀態
- 用戶采樣器(用戶啟動狀態的分布)
- 用戶狀態轉換模型
- 用戶回應,
本模擬場景的用戶模型如下:
- 每個用戶都有一個被稱為專業記錄曝光度( npe t \text{npe}_t npet?)和滿意度( sat t \text{sat}_t satt?)的特性,它們通過線性關系聯系起來,反映了滿意度不可能是無限的這一事實,表達為: sat t = σ ( τ ? enga t ) \text{sat}_t=\sigma(\tau\cdot\text{enga}_t) satt?=σ(τ?engat?)其中 τ \tau τ是用戶敏感性引數,由公式可知滿意度 sat t \text{sat}_t satt?與專業記錄曝光度( npe t \text{npe}_t npet?)是雙向相關的,所以只需要知道其中一個就可以跟蹤用戶狀態了,
- 給定一個記錄候選串列(slate) S S S,用戶根據一個以記錄的喜聞樂見程度作為特征的多項邏輯選擇模型(multinomial logit choice model)選擇一個記錄 d i d_i di?: p ( user choose d i from slate S ) ~ e 1 ? p r o f ( d i ) p(\text{user choose }d_i \text{ from slate }S)\sim e^{1-prof(d_i)} p(user choose di? from slate S)~e1?prof(di?)之所以使用 1 ? p r o f ( d i ) 1-prof(d_i) 1?prof(di?),是因為喜聞樂見的記錄更容易被用戶選擇,
- 一旦用戶從記錄候選串列(slate) S S S選擇了一個記錄,專業記錄曝光度( npe t \text{npe}_t npet?)就會變化為: enga t + 1 = β ? enga t + 2 ( p d ? 1 2 ) + N ( 0 , η ) \text{enga}_{t+1}=\beta\cdot\text{enga}_t+2(p_d-\frac{1}{2})+\mathscr{N}(0,\eta) engat+1?=β?engat?+2(pd??21?)+N(0,η)其中 β \beta β是某個用戶的折扣因子, p d p_d pd?是所選記錄的專業度, N ( 0 , η ) \mathscr{N}(0,\eta) N(0,η)是呈正態分布的噪聲資料,
- 最后,用戶查看所選記錄的時間為 s d s_d sd?秒,其中 s d s_d sd?是根據以下公式生成的: s d ~ log ? ( N ( p d μ p + ( 1 ? p d ) μ l , p d σ p + ( 1 ? p d ) σ l ) ) s_d\sim\log\biggl(\mathscr{N}(p_d\mu_p+(1-p_d)\mu_l,p_d\sigma_p+(1-p_d)\sigma_l)\biggr) sd?~log(N(pd?μp?+(1?pd?)μl?,pd?σp?+(1?pd?)σl?))即一個對數正態分布,其值是在純專業分布 ( μ p , σ p ) (\mu_p, \sigma_p) (μp?,σp?)和純喜聞樂見分布 ( μ l , σ l ) (\mu_l,\sigma_l) (μl?,σl?)之間的線性插值,
因此,用戶狀態是由元組 ( sat , τ , β , η , μ p , σ p , μ l , σ l ) (\text{sat},\tau,\beta,\eta,\mu_p, \sigma_p,\mu_l,\sigma_l) (sat,τ,β,η,μp?,σp?,μl?,σl?)定義的,滿意度變數 sat \text{sat} sat是狀態中唯一的動態部分,而其他引數是由用戶定義的,并且是靜態不變的,從技術上講,我們不需要將它們作為狀態的一部分,而是應該硬編碼它們,但是,將它們作為狀態的一部分可以使得我們能夠采樣出具有不同屬性的用戶,
4.2.2.1. 用戶狀態和用戶采樣器
與document類似,我們首先實作一個用戶狀態類,作為所有用戶狀態引數的容器,與AbstractDocument類似,AbstractUserState基類要求我們實作observation_space()和create_observations(),它們用于在每次迭代時向Agent提供關于用戶狀態的部分(或全部)資訊,
我們也有對Session時間的限制,在本模擬場景中,會話長度將固定為某個常量,所以不在時間預算模型中明確說明,但我們也可以將其視為用戶狀態的一部分,并利用它做點其他的事情,
最后,我們將實作一個score_document()方法,該方法將document映射到一個非負實數,
class SIMUserState(user.AbstractUserState):
def __init__(self, memory_discount, sensitivity, innovation_stddev,
like_mean, like_stddev, prof_mean, prof_stddev,
net_professional_exposure, time_budget, observation_noise_stddev=0.1):
# 用戶狀態轉化模型引數
self.memory_discount = memory_discount
self.sensitivity = sensitivity
self.innovation_stddev = innovation_stddev
# 對數正態分布引數
self.like_mean = like_mean
self.like_stddev = like_stddev
self.prof_mean = prof_mean
self.prof_stddev = prof_stddev
# 狀態變數
self.net_professional_exposure = net_professional_exposure
self.satisfaction = 1 / (1 + np.exp(-sensitivity * net_professional_exposure))
self.time_budget = time_budget
# 噪聲資料
self._observation_noise = observation_noise_stddev
def create_observation(self):
# 用戶的狀態是隱藏的
clip_low, clip_high = (-1.0 / (1.0 * self._observation_noise),
1.0 / (1.0 * self._observation_noise))
noise = stats.truncnorm(clip_low, clip_high, loc=0.0, scale=self._observation_noise).rvs()
noisy_sat = self.satisfaction + noise
return np.array([noisy_sat, ])
@staticmethod
def observation_space():
return spaces.Box(shape=(1,), dtype=np.float32, low=-2.0, high=2.0)
# 對document評分——用戶更有可能選擇更喜聞樂見的內容,
def score_document(self, doc_obs):
return 1 - doc_obs
同樣與我們的document模型類似,我們需要一個啟動狀態采樣器,它為每個會話設定初始化的用戶狀態,
對于本模擬場景,我們將只對開頭的專業記錄曝光度( npe t \text{npe}_t npet?)進行采樣,并保持所有靜態引數相同,這意味著我們是以不同的滿意度處理同一個用戶,當然,我們也可以隨機生成具有不同引數的用戶,
注意,如果
η
=
0
\eta = 0
η=0, 則
npe
t
\text{npe}_t
npet?的值始終在
[
?
1
1
?
β
,
…
,
1
1
?
β
]
\left[-\frac{1}{1-\beta},\ldots,\frac{1}{1-\beta} \right]
[?1?β1?,…,1?β1?]區間內,所以作為初始分布,我們只在這個范圍內均勻抽樣,根據基類的要求,采樣代碼必須在sample_user()中實作,
class SIMStaticUserSampler(user.AbstractUserSampler):
_state_parameters = None
def __init__(self,
user_ctor=SIMUserState,
memory_discount=0.9,
sensitivity=0.01,
innovation_stddev=0.05,
like_mean=5.0,
like_stddev=1.0,
prof_mean=4.0,
prof_stddev=1.0,
time_budget=60,
**kwargs):
self._state_parameters = {'memory_discount': memory_discount,
'sensitivity': sensitivity,
'innovation_stddev': innovation_stddev,
'like_mean': like_mean,
'like_stddev': like_stddev,
'prof_mean': prof_mean,
'prof_stddev': prof_stddev,
'time_budget': time_budget}
super(SIMStaticUserSampler, self).__init__(user_ctor, **kwargs)
def sample_user(self):
starting_npe = ((self._rng.random_sample() - .5)*(1 / (1.0 - self._state_parameters['memory_discount'])))
self._state_parameters['net_professional_exposure'] = starting_npe
return self._user_ctor(**self._state_parameters)
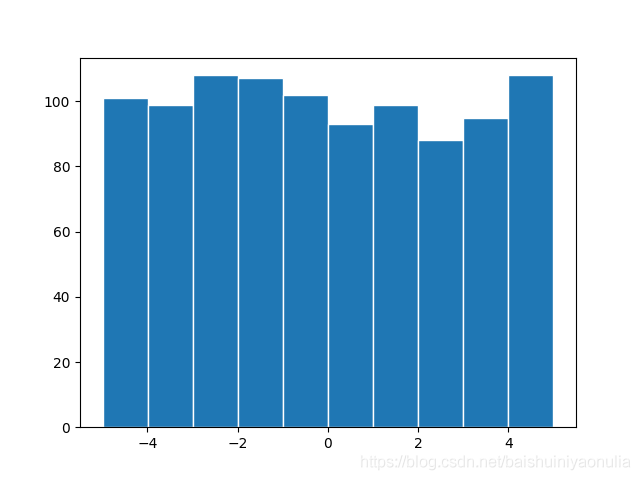
至此,我們可以開始采樣一些用戶,例如下面的代碼就采樣了1000個用戶,并且用直方圖表示了不同專業記錄曝光度區間范圍內的用戶數量各為多少
if __name__ == '__main__':
sampler = SIMStaticUserSampler()
starting_npe = []
for i in range(1000):
sampled_user = sampler.sample_user()
starting_npe.append(sampled_user.net_professional_exposure)
plt.hist(starting_npe,edgecolor='white',linewidth=1) # import matplotlib.pyplot as plt
plt.show()
4.2.2.2. 回應模型
接下來要構造user response類,RecSim將為候選串列中的每個推薦專案生成一個回應,Agent看到的回應內容是用戶對推薦的特定document的反饋(在SIMUserState.create_observation中生成非特定document的反饋),
class SIMResponse(user.AbstractResponse):
# 參與度最大值
MAX_ENGAGEMENT_MAGNITUDE = 100.0
def __init__(self, clicked=False, engagement=0.0):
self.clicked = clicked
self.engagement = engagement
def create_observation(self):
return {'click': int(self.clicked), 'engagement': np.array(self.engagement)}
@classmethod
def response_space(cls):
# engagement的范圍是[0,MAX_ENGAGEMENT_MAGNITUDE]
return spaces.Dict({
'click': spaces.Discrete(2),
'engagement': spaces.Box(
low=0.0,
high=cls.MAX_ENGAGEMENT_MAGNITUDE,
shape=tuple(),
dtype=np.float32)})
4.2.2.3. 用戶模型
現在我們已經有了為會話生成用戶的方法,接下來需要指定實際的用戶行為,RecSim用戶模型(源自recsim.user.AbstractUserModel)負責以下三個動作:
- 維護用戶的狀態;
- 根據推薦的結果,更新用戶狀態;
- 生成對一系列建議的回應,
為此,用戶模型需要實作基類的update_state()和simulate_response()方法,以及控制會話于何時結束的is_terminal,這是通過self.time_budget的自減來實作的,
我們的初始化很簡單,只將需要response_model建構式、用戶采樣器和候選串列大小傳遞給AbstractUserModel基類就可以了,
def __init__(self, slate_size, seed=0):
super(SIMUserModel, self).__init__(SIMResponse, SIMStaticUserSampler(SIMUserState, seed=seed), slate_size)
self.choice_model = MultinomialLogitChoiceModel({}) # from choice_model import MultinomialLogitChoiceModel
simulate_response()方法用于接受由Agent生成的SIMDocuments的候選串列,并輸出用戶回應串列,回應串列中的第
k
k
k個回應對應推薦串列中的第
k
k
k個document,在這種情況下,我們根據我們的選擇模型選擇一個document進行點擊,并產生一個參與度,我們讓未點擊的document的回應為空,或者用其他更好的方式來操作(例如記錄用戶是否檢查了該檔案等等),
def simulate_response(self, slate_documents):
# 空回應串列
responses = [self._response_model_ctor() for _ in slate_documents]
# 從選擇模型獲取點擊
self.choice_model.score_documents(self._user_state, [doc.create_observation() for doc in slate_documents])
scores = self.choice_model.scores
selected_index = self.choice_model.choose_item()
# 填充點擊項
self._generate_response(slate_documents[selected_index], responses[selected_index])
return responses
def _generate_response(self, doc, response):
response.clicked = True
# 專業記錄和喜聞樂見記錄之間的線性插值
engagement_loc = (doc.prof * self._user_state.like_mean + (1 - doc.prof) * self._user_state.prof_mean)
engagement_loc *= self._user_state.satisfaction
engagement_scale = (doc.prof * self._user_state.like_stddev + ((1 - doc.prof) * self._user_state.prof_stddev))
log_engagement = np.random.normal(loc=engagement_loc, scale=engagement_scale)
response.engagement = np.exp(log_engagement)
update_state()方法是用戶狀態轉換的關鍵,它使用推薦的候選串列以及用戶實際的選擇(回應)來誘導狀態轉換,狀態被直接修改,所以函式沒有任何回傳值,
def update_state(self, slate_documents, responses):
for doc, response in zip(slate_documents, responses):
if response.clicked:
innovation = np.random.normal(scale=self._user_state.innovation_stddev)
net_professional_exposure = (self._user_state.memory_discount * self._user_state.net_professional_exposure - 2.0 * (doc.prof - 0.5) + innovation)
self._user_state.net_professional_exposure = net_professional_exposure
satisfaction = 1 / (1.0 + np.exp(-self._user_state.sensitivity * net_professional_exposure))
self._user_state.satisfaction = satisfaction
self._user_state.time_budget -= 1
return
最后,當時間預算time_budge小于等于0時,會話過期,
def is_terminal(self):
# 回傳一個布林值,指示會話是否結束
return self._user_state.time_budget <= 0
我們把上面所講的所有函陣列件封裝在一個類中,命名為SIMUserModel,繼承user.AbstractUserModel基類,
class SIMUserModel(user.AbstractUserModel):
def __init__(self, slate_size, seed=0):
...
def simulate_response(self, slate_documents):
...
def _generate_response(self, doc, response):
...
def update_state(self, slate_documents, responses):
...
def is_terminal(self):
...
最后,我們將所有組件(包括document組件和user組件)配置到一個環境中,
if __name__ == '__main__':
slate_size = 3
num_candidates = 10
simenv = environment.Environment(
SIMUserModel(slate_size),
SIMDocumentSampler(),
num_candidates,
slate_size,
resample_documents=True)
4.2.2.4. 與Agent的互動
我們現在已經實作了一個模擬環境,為了在這種環境中訓練和評估Agent,我們還需要設定一個獎勵函式,用于將一組反應映射到實數域,假設我們想要最大化點擊檔案的參與度,那么就可以這樣設定獎勵函式:
def clicked_engagement_reward(responses):
reward = 0.0
for response in responses:
if response.clicked:
reward += response.engagement
return reward
現在,我們只需使用OpenAI gym包裝器載入我們的模擬環境即可,從4.2.3. 模擬場景的試運行的隨機執行結果可以看到,observation_1的用戶滿意度比observation_0的用戶滿意度高了不少,
if __name__ == '__main__':
'''
其他陳述句
'''
sim_gym_env = recsim_gym.RecSimGymEnv(simenv, clicked_engagement_reward)
observation_0 = sim_gym_env.reset()
print('Observation 0') # 用戶觀測到的環境 0
print('Available documents') # 輸出候選串列中的所有document
doc_strings = ['doc_id ' + key + " prof " + str(value) for key, value
in observation_0['doc'].items()]
print('\n'.join(doc_strings))
print('Noisy user state observation')
print(observation_0['user']) # 用戶滿意度
recommendation_slate_0 = [0, 1, 2] # Agent 推薦出候選串列(slate)的前三個document
observation_1, reward, done, _ = sim_gym_env.step(recommendation_slate_0) # 環境狀態轉移
print('Observation 1') # 用戶觀測到的環境 1
print('Available documents') # 輸出候選串列中的所有document
doc_strings = ['doc_id ' + key + " prof " + str(value) for key, value
in observation_1['doc'].items()]
print('\n'.join(doc_strings))
rsp_strings = [str(response) for response in observation_1['response']]
print('User responses to documents in the slate')
print('\n'.join(rsp_strings)) # 輸出用戶參與(回應)情況
print('Noisy user state observation')
print(observation_1['user']) # 用戶滿意度
4.2.3. 模擬場景的試運行
完整代碼請關注公眾號:推薦系統新視野(RecView),回復“recsim模擬場景”獲取

輸出:
Observation 0
Available documents
doc_id 10 prof [0.79172504]
doc_id 11 prof [0.52889492]
doc_id 12 prof [0.56804456]
doc_id 13 prof [0.92559664]
doc_id 14 prof [0.07103606]
doc_id 15 prof [0.0871293]
doc_id 16 prof [0.0202184]
doc_id 17 prof [0.83261985]
doc_id 18 prof [0.77815675]
doc_id 19 prof [0.87001215]
Noisy user state observation
[0.51296355]
Observation 1
Available documents
doc_id 20 prof [0.97861834]
doc_id 21 prof [0.79915856]
doc_id 22 prof [0.46147936]
doc_id 23 prof [0.78052918]
doc_id 24 prof [0.11827443]
doc_id 25 prof [0.63992102]
doc_id 26 prof [0.14335329]
doc_id 27 prof [0.94466892]
doc_id 28 prof [0.52184832]
doc_id 29 prof [0.41466194]
User responses to documents in the slate
{'click': 0, 'engagement': array(0.)}
{'click': 1, 'engagement': array(55.75022179)}
{'click': 0, 'engagement': array(0.)}
Noisy user state observation
[0.5730411]
Process finished with exit code 0
5. 自定義Agent
在熟悉了RecSim的整體架構以及各個組件之間是如何組合在一起成為一個完整的模擬環境之后,我們現在只剩Agent需要開發了,要弄清楚Agent與RecSim之間的互動方式,可以從下面兩個角度入手:
- RecSim向Agent提供什么資料?以及如何提供資料?資料處理的結果是什么?
- RecSim為開發Agent提供哪些功能?
在了解RecSim給Agent提供的功能之前,我們再看一看RecSim的架構圖,
把關注點放在圖中Agent所在的區域,我們可以得出以下Agent的四種作用:
- 接收用戶狀態(用戶可見特征);
- 接收用戶對推薦的回應(用戶回應);
- 接收一組記錄 D D D(記錄可見特征),
- 輸出大小為 K K K的記錄候選串列,以提供給用戶選擇模型和用戶轉換模型使用,
為了更好地理解RecSim為開發Agent提供的API,我們將在RecSim的興趣探索(interest exploration)環境中實作一個簡單的bandit Agent,
假設整個環境由巨量的記錄組成,這些記錄聚集成不同主題,在RecSim中,我們也假設用戶聚集成不同型別,于是有了:
記錄對用戶的吸引力 = 記錄的質量 + 主題對用戶(用戶型別)的吸引力 \text{記錄對用戶的吸引力}=\text{記錄的質量}+\text{主題對用戶(用戶型別)的吸引力} 記錄對用戶的吸引力=記錄的質量+主題對用戶(用戶型別)的吸引力
這自然會造成這樣一種情況:一個目光短淺的Agent會根據預測的點擊率對記錄進行排名,它會青睞高質量的記錄,因為這樣的記錄在所有用戶型別中都有很高的先驗概率被點擊,這導致Agent忽視探索可能帶來的利益,從而選擇了沒這么好的策略,為了克服這種情況,就需要人為控制Agent采取積極的探索策略,
我們先定義Agent的各種方法,然后將其封裝到一個類中,在這之前,我們先實體化一個模擬環境,以便進行后續處理,
首先匯入需要的包
import functools
from gym import spaces
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
from recsim import agent
from recsim import document
from recsim import user
from recsim.choice_model import MultinomialLogitChoiceModel
from recsim.simulator import environment
from recsim.simulator import recsim_gym
from recsim.simulator import runner_lib
from recsim.environments import interest_exploration
這里我們只使用RecSim提供的create_environment()函式對環境進行初始化,也就是僅構造一個基礎環境,而不添加任何其他的屬性,在構建了環境之后,呼叫reset()方法對環境進行初始化,從而使用戶可以得到最初的觀測結果:
env_config = {'slate_size': 2,
'seed': 0,
'num_candidates': 15,
'resample_documents': True}
ie_environment = interest_exploration.create_environment(env_config)
initial_observation = ie_environment.reset()
5.1. 觀測 Observation
用戶的觀測即用戶看到的部分環境,RecSim中,用戶的觀測可以表示成有3個鍵的字典:
- “user” : 表示架構圖中的"用戶可見特征";
- “doc” : 包含當前值得推薦的記錄及其可見特征,
- “response” : 表示用戶對最后一組推薦的回應(“用戶回應”),在這個階段,“回應”鍵是空白的,將被設定為None,因為還沒有提出任何建議,
print('User Observable Features')
print(initial_observation['user'])
print('User Response')
print(initial_observation['response'])
print('Document Observable Features')
for doc_id, doc_features in initial_observation['doc'].items():
print('ID:', doc_id, 'features:', doc_features)
輸出:
User Observable Features
[]
User Response
None
Document Observable Features
ID: 15 features: {'quality': array(1.22720163), 'cluster_id': 1}
ID: 16 features: {'quality': array(1.29258489), 'cluster_id': 1}
ID: 17 features: {'quality': array(1.23977078), 'cluster_id': 1}
ID: 18 features: {'quality': array(1.46045555), 'cluster_id': 1}
ID: 19 features: {'quality': array(2.10233425), 'cluster_id': 0}
ID: 20 features: {'quality': array(1.09572905), 'cluster_id': 1}
ID: 21 features: {'quality': array(2.37256963), 'cluster_id': 0}
ID: 22 features: {'quality': array(1.34928002), 'cluster_id': 1}
ID: 23 features: {'quality': array(1.00670188), 'cluster_id': 1}
ID: 24 features: {'quality': array(1.20448562), 'cluster_id': 1}
ID: 25 features: {'quality': array(2.18351159), 'cluster_id': 0}
ID: 26 features: {'quality': array(1.19411585), 'cluster_id': 1}
ID: 27 features: {'quality': array(1.03514646), 'cluster_id': 1}
ID: 28 features: {'quality': array(2.29592623), 'cluster_id': 0}
ID: 29 features: {'quality': array(2.05936556), 'cluster_id': 0}
Process finished with exit code 0
此時,我們得到了一個由15個記錄(num_candidates)組成的語料庫,每個記錄都由它們的主題(cluster_id)和質量分數(quality)表示,
用戶觀測的格式規范可以作為OpenAI gym空間的環境特征,它也在初始化時提供給Agent
print('Document observation space')
for key, space in ie_environment.observation_space['doc'].spaces.items():
print(key, ':', space)
print('Response observation space')
print(ie_environment.observation_space['response'])
print('User observation space')
try:
print(ie_environment.observation_space['user'])
except ValueError:
# ValueError: zero-size array to reduction operation minimum which has no identity
# 從上一段代碼的輸出結果可以看出,此時沒有用戶可見特征,則用戶可見特征空間為空
print("Box(0,)")
輸出:
Document observation space
15 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
16 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
17 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
18 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
19 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
20 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
21 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
22 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
23 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
24 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
25 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
26 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
27 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
28 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
29 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
Response observation space
Tuple(Dict(click:Discrete(2), cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32)), Dict(click:Discrete(2), cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32)))
User observation space
Box(0,)
5.2. 候選串列 Slate
RecSim的候選串列是前
K
K
K個索引['doc']的串列,例如,
K
K
K為2的候選串列可以將上述15個記錄表示為:
slate = [0, 1]
for slate_doc in slate:
print(list(initial_observation['doc'].items())[slate_doc])
輸出:
('15', {'quality': array(1.22720163), 'cluster_id': 1})
('16', {'quality': array(1.29258489), 'cluster_id': 1})
環境的動作空間是一個 N ? N N*N N?N記錄大小的多維離散空間
print(ie_environment.action_space)
輸出:
MultiDiscrete([15 15])
當候選串列被用戶選用時,環境就會生成一個新的觀察結果以及對Agent的獎勵,這個程序稱為狀態轉移,Agent的主要作業就是為模擬的每個狀態轉移步驟,并生成有效的候選推薦串列,
observation, reward, done, _ = ie_environment.step(slate)
5.3. 搭建Agent
5.3.1. 簡單Agent
現在我們來實作一個功能簡單的Agent,首先匯入包,
from recsim.agent import AbstractEpisodicRecommenderAgent
RecSim的Agent類繼承自AbstractEpisodicRecommenderAgent,Agent初始化所需的引數是observation_space和action_space,我們可以用這兩個引數來驗證環境是否滿足Agent進行操作的先決條件,
class StaticAgent(AbstractEpisodicRecommenderAgent):
def __init__(self, observation_space, action_space):
# 檢查document語料庫是否足夠大
if len(observation_space['doc'].spaces) < len(action_space.nvec):
raise RuntimeError('Slate size larger than size of the corpus.')
super(StaticAgent, self).__init__(action_space)
def step(self, reward, observation):
print(observation)
return list(range(self._slate_size))
這個Agent命名為StaticAgent,含義是它會靜態地推薦語料庫的前
K
K
K個記錄,我們現在可以使用runner_lib在RecSim中運行它,
def create_agent(sess, environment, eval_mode, summary_writer=None):
return StaticAgent(environment.observation_space, environment.action_space)
# Windows改成'.\\tmp\\recsim\\'
tmp_base_dir = './tmp/recsim/'
runner = runner_lib.EvalRunner(
base_dir=tmp_base_dir,
create_agent_fn=create_agent,
env=ie_environment,
max_eval_episodes=1,
max_steps_per_episode=5,
test_mode=True)
# 運行Agent
# runner.run_experiment()
構建好runner后,就可以打開tensorboard來觀察runner的運行程序
tensorboard --logdir=./tmp/recsim/eval_1/ --host=127.0.0.1
實際上,由于我們沒有進行任何操作,所以此時tensorboard中是沒有任何資料的,
5.3.2. 層次化Agent結構
在5.3.1. 簡單Agent中我們構造了一個基本的Agent,接下來,我們試著把多個Agent組合起來組成一個Agent層,其中每個單獨的Agent稱為“基Agent”,
我們使用bandit演算法來揭示用戶對每個主題的平均參與度,也就是說,每個主題都視作一條arm,一旦演算法選擇了一個主題,我們就可以從這個主題中獲取質量最高的記錄,
當推薦多個產品時,通常會發生這樣的情況:在一個會話期內,用戶將與某些產品產生一些互動,這些互動中會蘊含一些用戶的意圖資訊,有時,用戶會進行顯式的查詢(例如輸入搜索詞),此時的用戶意圖十分明顯,然而大多數情況下,用戶的意圖是隱藏的,即用戶通過從一組物品中選擇來間接地展示自己的意圖,假設我們已經通過某種方法得知了用戶意圖,那么就可以用一個特定于產品的策略來實作Agent,
Agent層的構造方法是模塊化的,RecSim提供了一組易于擴展的Agent構建塊,可以將單個Agent組合到層次化結構中以構建復雜的Agent結構,如下圖所示:
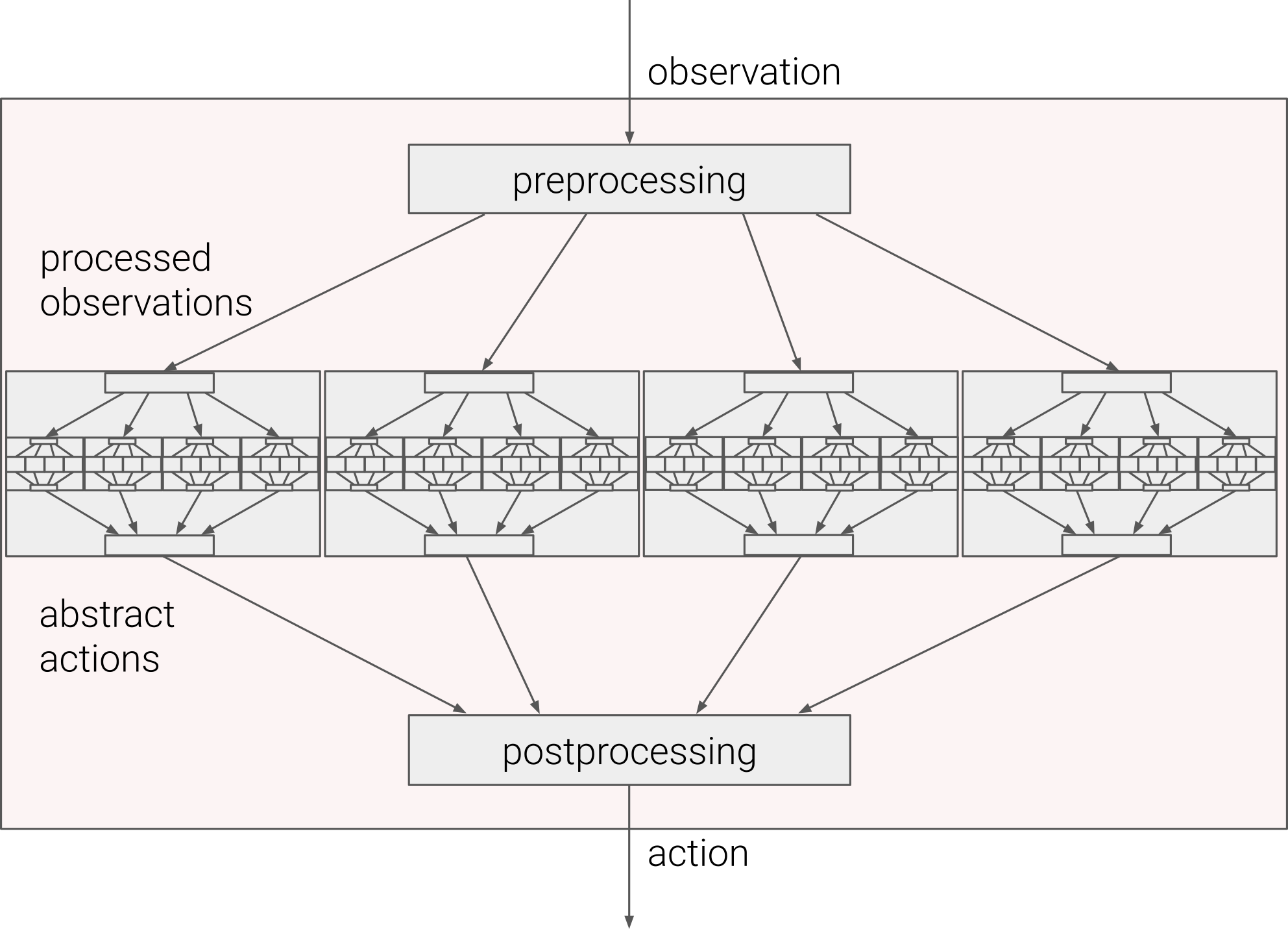
從圖中可以清晰看到,Agent層依賴于一個或多個基Agent來實作:
- Agent層接收用戶觀測和來自環境的反饋;
- 原始用戶觀測需進行預處理后再傳遞給Agent層中的基Agent,
- 每個基Agent都輸出候選串列(或抽象操作),然后進行后處理,以創建/輸出最終候選串列(或具體操作),
通過修改Agent層的前處理和后處理功能定義,可以發揮很多有意思的作用,例如,一個層可以被用作純特征提取器,即它可以從用戶觀測中提取一些特征,并將其傳遞給基Agent,同時不需要再進行后處理,
前處理層-基Agent層-后處理層的分層結構設計有利于特征工程和Agent工程的解耦,通過修改獎勵函式,可以實作各種不同的規范化器,Agent層也可以是動態的,以便于預處理或后處理函式可以實作引數更新或加入學習機制,
5.3.2.1. ClusterClickStats
ClusterClickStats負責為Agent探索提供必要的、足夠的統計資訊,在本節的最開始,我們介紹了興趣探索(Interest Exploration)環境,它提供了用戶點擊的反饋,但沒有跟蹤累積點擊次數,由于在實際專案中維護這樣的統計資料通常是有意義的,所以RecSim實作了這樣一個功能性Agent層來完成這一作業,下面我們來介紹一下ClusterClickStats,
ClusterClickStats監控了回應流,回應空間中有鍵"click"和"cluster_id",分別代表點擊量和聚集簇的編號,
首先匯入包
from recsim.agents.layers.cluster_click_statistics import ClusterClickStatsLayer
ClusterClickStats的建構式與其基Agent(這里就用上面的StaticAgent)一致,且不會對候選串列進行任何后處理,也就是說基Agent輸出的候選串列會直接發送給用戶,
一旦基Agent實體化,ClusterClickStats將向其基Agent的觀測空間中注入足夠的統計資訊,
static_agent = StaticAgent(ie_environment.observation_space, ie_environment.action_space)
static_agent.step(reward, observation)
輸出:
{'user': array([], dtype=float64), 'doc': OrderedDict([
('30', {'quality': array(2.48922445), 'cluster_id': 0}),
('31', {'quality': array(2.12592661), 'cluster_id': 0}),
('32', {'quality': array(1.27448139), 'cluster_id': 1}),
('33', {'quality': array(1.21799112), 'cluster_id': 1}),
('34', {'quality': array(1.17770375), 'cluster_id': 1}),
('35', {'quality': array(2.07948915), 'cluster_id': 0}),
('36', {'quality': array(1.14167652), 'cluster_id': 1}),
('37', {'quality': array(1.20529165), 'cluster_id': 1}),
('38', {'quality': array(1.2424684), 'cluster_id': 1}),
('39', {'quality': array(1.87279668), 'cluster_id': 0}),
('40', {'quality': array(1.19644888), 'cluster_id': 1}),
('41', {'quality': array(1.28254021), 'cluster_id': 1}),
('42', {'quality': array(2.01558539), 'cluster_id': 0}),
('43', {'quality': array(2.46400483), 'cluster_id': 0}),
('44', {'quality': array(1.33980633), 'cluster_id': 1})]),
'response': (
{'click': 0, 'quality': array(1.22720163), 'cluster_id': 1},
{'click': 0, 'quality': array(1.29258489), 'cluster_id': 1})}
cluster_static_agent = ClusterClickStatsLayer(StaticAgent, ie_environment.observation_space, ie_environment.action_space)
cluster_static_agent.step(reward, observation)
輸出:
{'user': {'raw_observation': array([], dtype=float64), 'sufficient_statistics': {'impression_count': array([0, 2]),
'click_count': array([0, 0])}},
'doc': OrderedDict([
('30', {'quality': array(2.48922445), 'cluster_id': 0}),
('31', {'quality': array(2.12592661), 'cluster_id': 0}),
('32', {'quality': array(1.27448139), 'cluster_id': 1}),
('33', {'quality': array(1.21799112), 'cluster_id': 1}),
('34', {'quality': array(1.17770375), 'cluster_id': 1}),
('35', {'quality': array(2.07948915), 'cluster_id': 0}),
('36', {'quality': array(1.14167652), 'cluster_id': 1}),
('37', {'quality': array(1.20529165), 'cluster_id': 1}),
('38', {'quality': array(1.2424684), 'cluster_id': 1}),
('39', {'quality': array(1.87279668), 'cluster_id': 0}),
('40', {'quality': array(1.19644888), 'cluster_id': 1}),
('41', {'quality': array(1.28254021), 'cluster_id': 1}),
('42', {'quality': array(2.01558539), 'cluster_id': 0}),
('43', {'quality': array(2.46400483), 'cluster_id': 0}),
('44', {'quality': array(1.33980633), 'cluster_id': 1})]), 'response': (
{'click': 0, 'quality': array(1.22720163), 'cluster_id': 1},
{'click': 0, 'quality': array(1.29258489), 'cluster_id': 1})}
如上輸出結果中,“user"欄位有了一個新鍵"sufficient_statistics”,而之前的用戶觀測(空的)在"raw_observe"鍵下,之所以這樣做是為了避免命名沖突,
5.3.2.2. AbstractClickBandit
AbstractClickBandit負責實作實際的bandit策略,RecSim提供了一個功能性抽象bandit——AbstractClickBandit,它將基Agent的候選串列作為輸入,并其視為arm進行強化學習,
它利用幾個已經實作的bandit策略(UCB1、KL-UCB、ThompsonSampling)中的一個來構建策略,以實作相對于最佳策略(這是先驗未知的)的次線性遺憾(sub-linear regret),具體選擇哪個bandit策略取決于對環境的要求,
首先匯入包:
from recsim.agents.layers.abstract_click_bandit import AbstractClickBanditLayer
要實體化一個抽象bandit,必須提供一個基Agent的候選串列,在我們的示例中,每個主題都有一個基Agent,該Agent只從語料庫中檢索屬于該主題的document,并根據質量對它們進行排序,
class GreedyClusterAgent(agent.AbstractEpisodicRecommenderAgent):
"""Agent根據質量對主題的所有document進行排序"""
def __init__(self, observation_space, action_space, cluster_id, **kwargs):
del observation_space
super(GreedyClusterAgent, self).__init__(action_space)
self._cluster_id = cluster_id
def step(self, reward, observation):
del reward
my_docs = []
my_doc_quality = []
for i, doc in enumerate(observation['doc'].values()):
if doc['cluster_id'] == self._cluster_id:
my_docs.append(i)
my_doc_quality.append(doc['quality'])
if not bool(my_docs):
return []
sorted_indices = np.argsort(my_doc_quality)[::-1]
return list(np.array(my_docs)[sorted_indices])
然后為每個集群實體化一個GreedyClusterAgent,
num_topics = list(ie_environment.observation_space.spaces['doc'].spaces.values())[0].spaces['cluster_id'].n
base_agent_ctors = [
functools.partial(GreedyClusterAgent, cluster_id=i)
for i in range(num_topics)
]
接下來實體化ClusterClickStatsLayer,并命名為Cluster_Bandit
bandit_ctor = functools.partial(AbstractClickBanditLayer, arm_base_agent_ctors=base_agent_ctors)
cluster_bandit = ClusterClickStatsLayer(bandit_ctor, ie_environment.observation_space, ie_environment.action_space)
現在ClusterClickStatsLayer可以正常作業了,運行之后會輸出一個最終候選串列,也就是推薦給用戶的記錄
observation0 = ie_environment.reset()
slate = cluster_bandit.begin_episode(observation0)
print("Cluster bandit slate 0:")
doc_list = list(observation0['doc'].values())
for doc_position in slate:
print(doc_list[doc_position])
輸出:
Cluster bandit slate 0:
{'quality': array(1.46868751), 'cluster_id': 1}
{'quality': array(1.42269182), 'cluster_id': 1}
6. RecSim參考檔案
僅僅了解上面幾節所講的內容還不能讓我們隨心所欲的開發RecSim,更多的內容請參考./recsim-master/recsim-master/docs/api_docs/python中的參考檔案
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/246956.html
標籤:AI
下一篇:極客日報第 45 期:蝦米音樂將永久關停;GitHub 解禁伊朗開發者使用權;抖音 2020 資料報告:日均視頻搜索量破 4 億