起源
鏈表的出現,是因為在許多業務場景中,需要進行增、刪操作,如果使用陣列進行,要么造成大量資料移動,要么造成大量存盤空間浪費,因此鏈表應運而生,
鏈表是線性表的一種,它如同鎖鏈一般,每個結點包括兩個部分:一個是存盤資料元素的資料域(可能存盤多個不同型別的資料),另一個是存盤下一個結點地址的指標域, 非常便于增刪操作,當然也因為是鏈式結構就造成了一般的鏈表并不具備像陣列那樣直接通過陣列下標隨機訪問的能力,
定義
typedef struct Node{
int data;
struct Node *next;
}LNode, *LinkList;
int main()
{
LNode point1 = {1,NULL};
}
鏈表與陣列的對比
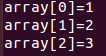
陣列:
int i;
int array[] = {1,2,3};
for(i=0;i<sizeof(array)/sizeof(array[0]);i++){
printf("array[%d]=%d\n",i,array[i]);
}
:Wq
鏈表
LNode point1 = {1,NULL};
LNode point2 = {2,NULL};
LNode point3 = {3,NULL};
point1.next = &point2;
point2.next = &point3;
printf("p1data=%d,p2data=%d,p3data=%d\n",point1.data,point1.next->data,point1.next->next->data);

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/247153.html
標籤:其他
上一篇:實作隱私計算的相關技術
下一篇:NJUPT《信安數基》復習題