**深入理解MySQL索引原理**
熊大
說索引之前我們先談下mysql 這個渣男,
它支持諸多存盤引擎,各存盤引擎對索引的支持也各不相同,因此MySQL支持多種索引型別,如BTree索引,二叉樹索引,哈希索引,有序陣列、全文索引等等,
現實作業中如果一個sql比較慢分析一番說加一個索引吧,一般這個sql就會飛起那么在這其中索引起什么作用呢?
有人說索引就像一本書的目錄如果一本書1000頁,如果想找到某個具體的內容最簡單方法就是查看目錄然后翻到該頁即可,
常見的索引型別:
哈希索引
哈希思路很簡單,把值放在陣列里,用一個哈希函式把
key 換算成一個確定位置,然后把 value 放在陣列的這個位置,
當然我們知道哈希程序中算出的值可能是一樣的那就拉出一個鏈表來記錄即可,
假如有一本戀愛寶典里面記錄了各種戀愛秘籍那么對呀hash如下圖
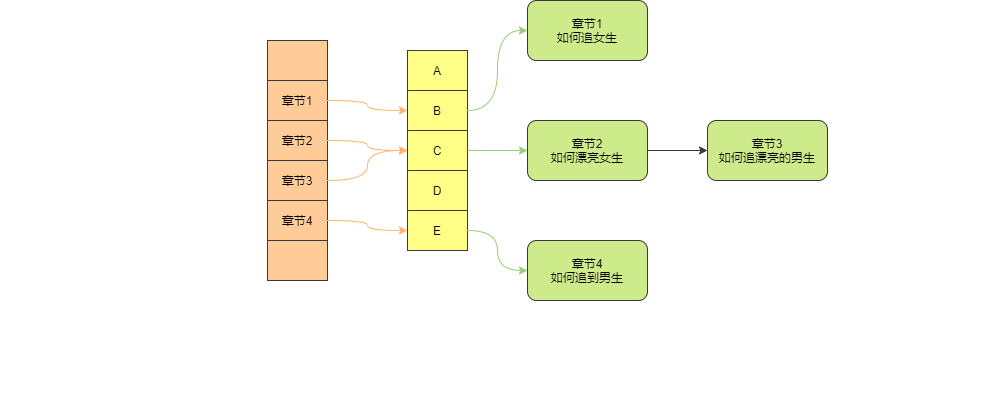
那么其實可以看到如果是等值查詢的情況我們很容易就把值查詢出來 但是如果范圍查詢這個就比較尷尬了,
等值查詢這種情況一般noSql運用較多
備注:上面的資料結構和hashmap是否一致呢?那么一道經典面試題map、list如何選擇
面對范圍查詢于是有序陣列應運而生,那么存盤結構如下
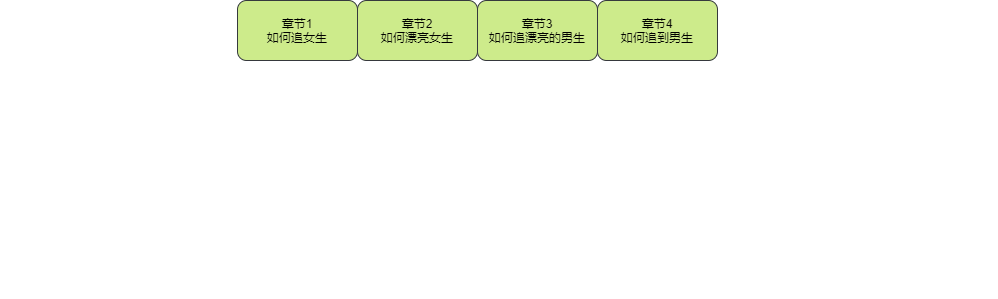
那么可以看出這個簡直就是為范圍查找量身制作的,但是如果更新資料代價有點大后續資料會挨個挪動,
二叉搜索樹也是經典的資料結構:
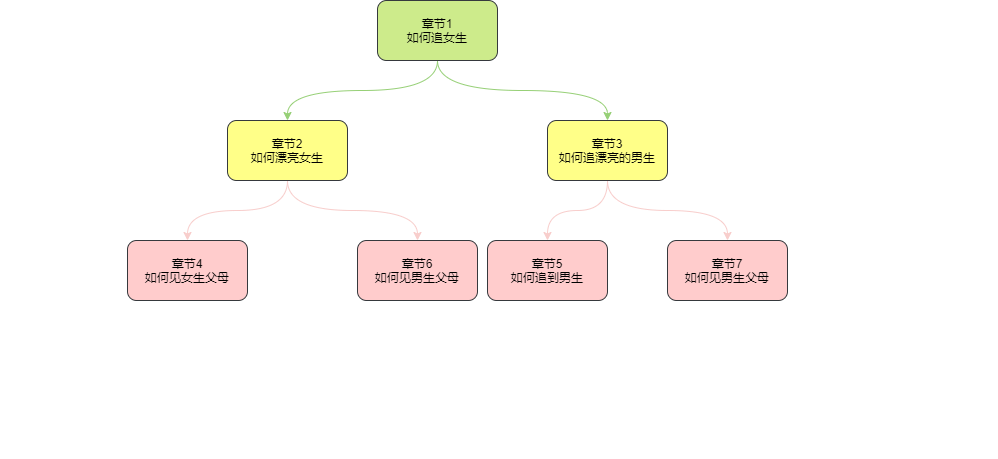
二叉樹的特點
就是左節點要比父節點小、右節點比父節點大,如果要查章節4那么他會一次從1–>2—>4
理論來講二叉搜索樹是查找最快的因為他的時間復雜度O(log(N))
當然前提是要維持這個二叉樹的平衡,
全文索引
通過建立倒排索引,可以極大的提升檢索效率,解決判斷欄位是否包含的問題,
那么我們經常使用的mysql innodb引擎是怎么存盤資料的呢
我們都知道它采用的是btree模型假如我們有一個表如下:
innodb使用了 B+ 樹索引模型,所以資料都是存盤在 B+ 樹中的,
create table test(
id int primary key,
k int not null,
name varchar(16),index (k))engine=InnoDB;
存盤資料如下圖:
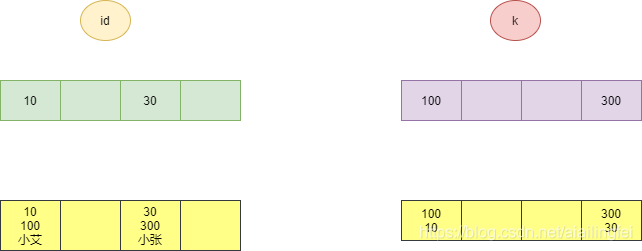
由上圖可以看出主鍵直接對應的是該行內容,而普通索引對應的是相應的主鍵,
也就是說普通索引如果查找相應資料需要先找到對應主鍵然后根據主鍵在找到相應的資料,
這就是我們所說的回表,當然只查這個索引對應的內容是不需要回表的,
select * from test where id=10;
select k from test where k=300;
這兩個陳述句是不用回表的,第一個sql是因為根據主鍵查詢 第二個雖然根據普通索引查詢但是只是查詢了改欄位所以也不需要回表,
索引的維護:
我們知道innodb的存盤結構是b+tree
每一個索引就是一顆b+tree 而其中每個葉子節點則是資料頁(page) 資料頁里面是由一行行的資料組成的,
那么對這個資料頁我們則是希望它能夠寫滿再去申請下一頁自增主鍵則滿足這個要求,當然在實際使用情況中頁可能裂開或者合并,
小知識點
假設mysql 引擎是innodb沒有主鍵它是怎么做的?
如果沒有主鍵innodb會給默認創建一個Rowid做主鍵
主鍵如何選擇:
業務允許的情況下最好選擇自增主鍵
1、自增主鍵可以更充分的使用資料頁,
2、普通索引的空間占用也比較小
參考:
<Mysql 實戰45講>
<結構與演算法>
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/247170.html
標籤:其他
下一篇:thinkPHP6報錯:Failed to listen on 0.0.0.0:8000 (reason: ????“