大家好,我的名字是跳表,沒有聽說過的,心里肯定莫名其妙,這是什么鬼名字?且容我慢慢道來,
說說我的家族
相信你一定知道單向鏈表和雙向鏈表,還有可能知道回圈鏈表,為什么要提這些鏈表呢?因為我就是屬于鏈表家族的,
我的家族最讓人詬病的是,不支持隨機訪問(RandomAccess),因為它通常對外只暴露一個頭(head)節點,只能一次一個的向后迭代訪問,
所以隨著鏈表長度的增加,訪問元素需要迭代的次數也在增加,所以時間復雜度就是O(n),這里的n就是鏈表的長度,
我的家族最讓人稱贊的是,可以在任意地方快速的插入/洗掉元素,而且只需要常量時間,即時間復雜度是O(1),因為只是修改了幾個指標的指向而已,
這里的1表示是一個固定的時間,且該時間不隨鏈表長度的增加而發生改變,這些都是基本的資料結構,相信每個人早已耳熟能詳,所以我就不畫圖啦,
但是,在實際使用中卻未必如此,雖然插入/洗掉元素只需要常量時間,可是它有一個大前提,就是已經定位到了插入點/洗掉點,這樣才可以操作指標的指向,
可是這個定位(插入/洗掉)節點的程序難道就不是一個元素訪問了嗎?當然是了,所以仍需要O(n)時間,如果把這個考慮進去,插入/洗掉元素的總時間其實也是O(n),因為首先要找到它,
而且在插入元素時,還需要分配記憶體,可能也需要消耗一點點時間,等等,關于鏈表更多的內容,請參考我之前的文章《一篇圖文徹底搞懂單鏈表,嗯,是有可能的》《List家族遺產繼承PK賽(一)》《List家族遺產繼承PK賽(二)》,
因此,對于我的家族來說,提高元素的訪問速度非常重要,因為它同時對插入/洗掉元素也是有利的,可以降低花費的總時間,
提高訪問速度的大前提
我的主人經常說,當要處理一個不熟悉的事物時,優先從身邊熟悉的事物入手,仔細思考并逐步演化、類比,
書對于任何人來說都再熟悉不過了,而且幾乎所有的人都看過書,基本上所有的書都會標頁碼,
標頁碼的真正目的是什么,其實我也不知道,但至少有一個作用,就是可以快速的定位到某一頁,
不過這依然有一個大前提,那就是頁碼必須是有序的,無論升序降序都行,注意,不一定非得是連續的,
這樣我們就不用一頁一頁的翻,可以一下子翻幾十頁或上百頁,定位速度自然會快很多,
設想一下,如果頁碼是雜亂無序的,可能200多頁在100多頁的前面,那此時頁碼就沒有快速定位的功能了,
只能回到最原始的方式,一頁一頁的翻,速度奇慢無比,這就是不按套路出牌,就像狄仁杰里的天字二號房間旁邊并不是天字一號房間一樣,
但是在編程方面,最好還是按套路走,畢竟鐵打的公司流水的碼農,總要有后人來接手你的代碼,整太多“超常規”的話,后生會太痛苦的,
書的頁碼是一頁接一頁的,鏈表的元素也是一個接一個的,所以它們的本質其實比較相似,頁碼是有序的,所以鏈表的元素也必須是有序的,
因此,要想提高對鏈表元素的訪問速度,元素之間必須是有序的才行,如果是無序的、雜亂無章的,那基本沒有提高的可能性,
提高訪問速度方法的探索
還是從書說起,如果一本書有500頁,如何才能快速的找到250頁左右呢?這個其實對于不愛看書的人也很容易,
那就是讓書的側面對著自己的眼睛,目測一下書的厚度,從中間劈開即可,絕對是250頁左右,
如果要找300頁呢?當然300頁離250頁不遠,其實就是從中間稍往后偏一點即可,
那如果要找400頁呢?如果要找100頁呢?采用同樣的方法,是不是精確度就要低一些了,因此花費的時間就要多一些,
假如書的總頁數是1000頁,要找700頁,是不是難度就進一步加大了,如果要找730頁,難度會更大,
這又該如何搞定呢?我們從熟悉的英文詞典入手,由于英文有26個字母,所以所有單詞的首字母也只能是26個中的一個,
這樣把單詞按首字母劃分(分組),分為26組,有些詞典就把每組印刷成一個顏色,這樣從側面很容易看到顏色交界處,
這些就是特殊的地方(頁碼),因為首字母在這里發生了變化,還可以把每個字母印刷到側面上,使用字母加顏色來實作快速定位,
這就給了我們一個啟發,要想在一本厚書里快速定位,必須找出特殊的頁碼,比如100頁、200頁,,,800頁、900頁等等,這些特殊地方,
我們可以在每整百頁的地方夾上一個紙條,一端露在外面,并寫上對應的整百數字,這樣再找700頁的時候直接找到這個整百紙條即可,速度超快的,
如果我要找770頁的話,依然是找到700對應的紙條和800對應的紙條,因為770一定在它們中間而且是靠近800的,
可能有人會想,我干脆也把50頁、150頁,,,850頁、950頁等等,這些整五十頁的地方也夾上紙條不就得了,
這樣在定位770的時候精度更高些,直接找到750和800,在它們之間尋找肯定比在700和800之間要快些,
這種想法(思路)是對的,雖然區間越小越精確,但是不要忘記了,這將使特殊頁碼變的更多,繼而夾的紙條就更多,這樣一來看這些紙條反而成了越來越大的負擔,
想象一下,如果在每一頁上都夾一個紙條,那和壓根兒不夾紙條又有什么區別呢?
所以這是一個權衡的問題,其實就是一個顆粒度的問題,實際是可以根據相關引數計算出來的,
快快快,該我上場了
哎呀,終于輪到我了,為了使大家更容易讀懂我,還是以循序漸進的方式展開吧,
首先準備一個有序鏈表,如下圖01:

其中H表示頭節點,N表示NULL,
假如要查詢節點11,那么需要經過11次才能找到,因為我們只能拿到頭節點,而頭節點只指向了第一個節點,
鏈表的訪問特點是無法改變的,只能通過指標一次次向后迭代,所以如果要想更快的找到節點11,唯一的方法就是改變切入點,
即不從第一個節點開始向后遍歷,而直接從中間的某個節點開始向后遍歷,可問題是我們沒有指向中間某個節點的指標啊,
這好辦,那就加一個唄,我們讓頭節點除了指向第一個節點外,再額外的指向中間的某個節點,如下圖02:

可以認為兩個頭節點是同一個節點,兩個NULL節點也是同一個,兩個6節點也是同一個,
所以這個圖表達的含義就是,我們又增加了一個指標,它指向了節點6,這樣一來這個鏈表就有了兩個指標了,
此時從頭節點開始,一下子就可以到節點6,接著再向后遍歷到節點11,這樣一共需要6次,比上回少了5次,
這就相當于在一本書的正中間加了一個書簽,可以一步定位到正中間,可是加了一個書簽后,人們并不滿足,
于是他們就在前半部分的中間和后半部分的中間再各加一個書簽,這樣三個書簽等于把書平均分成四份了,
那么對應到鏈表中,就是再用兩個指標分別指向前半部分的中間節點和后半部分的中間節點,如下圖03:
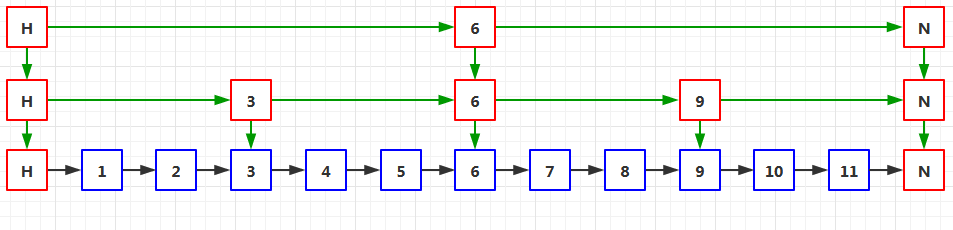
豎直方向上的三個H節點其實是一個節點,同理,3節點、6節點、9節點和N節點也是這樣子的,
這里的指標需要注意,指向3節點的指標依然是從H節點發出,但是指向9節點的指標則是從6節點發出的,
這樣從H節點一步定位到6節點,然后再一步定位到9節點,接著再向后遍歷到11節點,這樣一共用去4次,比上回又少了2次,
這樣的效果隨著鏈表的增長會變得越來越明顯,鏈表越長,減少的次數就會越多,
更加容易的來理解跳表
上面展示的跳表看明白了嗎?哈哈,相信大家都看懂了,但是好像又沒有get到本質,那就繼續吧,
我們先以一個簡單好理解的方式來逐步的構建跳表吧,
首先,準備一個有序鏈表,如下圖01:

其次,從這個鏈表中均勻的抽出部分節點組成一個新的鏈表,并放到原鏈表上方,如下圖04:

再次,從剛剛的新鏈表中均勻的抽出部分節點再組成一個新的鏈表,并放到原鏈表上方,如下圖05:
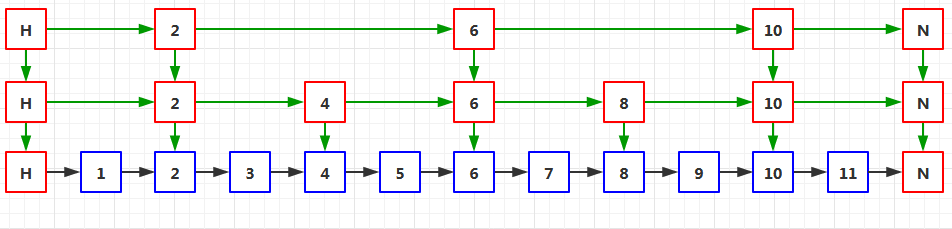
最后,重復上述程序,如下圖06:
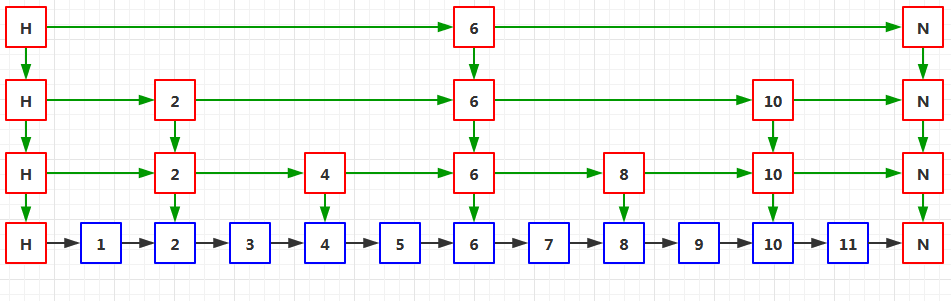
這樣看來,這個跳表是由四層鏈表組成的,其中最底層就是原始鏈表,包含全量的節點,
從底層往上走,每一層新的鏈表的節點數都在逐步減少,所以最上層的節點數最少,
由于每一層的鏈表都是從它的下一層構建出來的,所以每一層都是它的下一層的子集,
即每一層的節點必須在它的下一層中也存在,這很好理解,因為這些節點就是從它的下一層中抽出來的嘛,
就這個跳表而言,假如最底層是0級,那么最高層就是3級,下面來做些練習,看看資料的查找程序是怎樣的,
下面是查找節點11的程序:
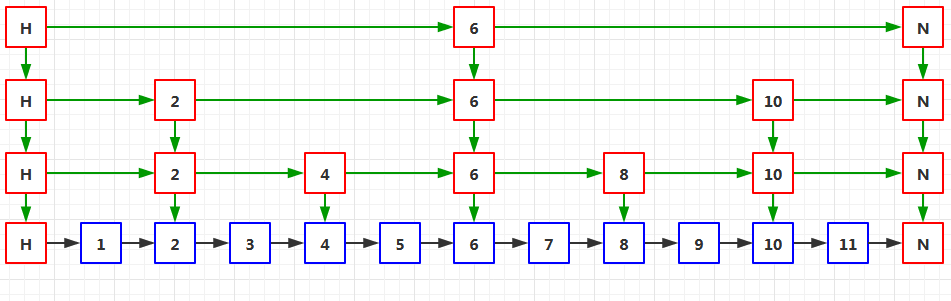
在第3級上,從H節點向右定位到6節點,由于11大于6,所以繼續向右,6節點的右邊是NULL,所以就沿著6節點向下進入第2級中,
在第2級上,從6節點向右定位到10節點,由于11大于10,所以繼續向右,10節點的右邊是NULL,所以沿著10節點向下進入第1級中,
在第1級上,10節點的右邊是NULL,所以沿著10節點向下進入第0級中,
在第0級上,從10節點向右定位到11節點,于是節點11就找到了,
下面是查找節點5的程序:
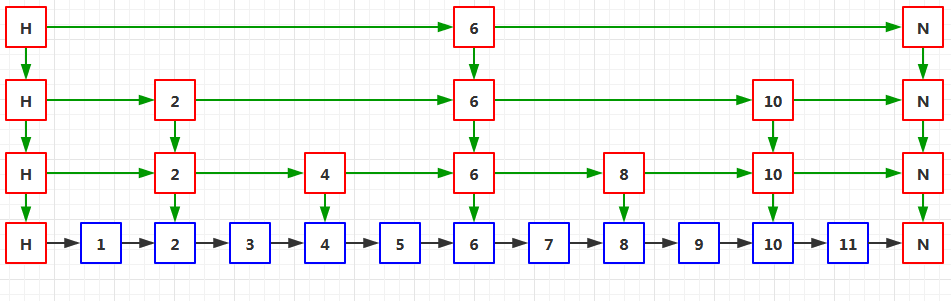
在第3級上,從H節點向右定位到6節點,發現6大于5,所以就沿著H節點向下進入第2級中,
在第2級上,從H節點向右定位到2節點,發現2小于5,繼續向右定位6節點,發現6大于5,所以沿著2節點向下進入第1級中,
在第1級上,從2節點向右定位到4節點,發現4小于5,繼續向右定位6節點,發現6大于5,所以沿著4節點向下進入第0級中,
在第0級上,從4節點向右定位到5節點,于是節點5就找到了,
其實整個作業原理和二叉樹差不多,首先從最頂層開始,可以理解為樹的根,
如果要查找的節點比當前節點大,那就在右邊部分找,如果沒有那就進入下一級中,繼續在右邊找,
如果要查找的節點比當前節點小,則直接進入下一級中,繼續在右邊找,
只要重復這個程序,就會逐級下降,如果這個節點存在的話,最后一定會找到,
其實除了最底層的原始鏈表外,其余的上層鏈表都可以認為是構建的索引,正是利用了這些索引,才加快了查找,
利用索引的效果就是我們可以跳過一些節點來快速定位,因此這就是跳表名稱的由來吧,
很明顯這是在用空間換取時間,所以查找、插入和洗掉操作的平均時間復雜度就由O(n)降為O(logn)了,
如果一個鏈表的長度是n的話,在不考慮頭尾節點的情況下,共需要n個指標,
在構建跳表時,如果每一層的節點數目都是它的下一層的一半的話,那么總共需要2n個指標,即翻了一倍,
由于全部層級的元素節點都是共用的,所以節點數目沒有變化,因此空間復雜度和抽取節點的比例有關,且只對指標數目產生影響,
作者是作業超過10年的碼農,現在任架構師,喜歡研究技術,崇尚簡單快樂,追求以通俗易懂的語言解說技術,希望所有的讀者都能看懂并記住,

>>> 熱門文章集錦 <<<
畢業10年,我有話說
我是一個協程
執行緒池開門營業招聘開發人員的一天
【面試】我是如何面試別人List相關知識的,深度有點長文
我是如何在畢業不久只用1年就升為開發組長的
爸爸又給Spring MVC生了個弟弟叫Spring WebFlux
【面試】我是如何在面試別人Spring事務時“套路”對方的
【面試】Spring事務面試考點吐血整理(建議珍藏)
【面試】我是如何在面試別人Redis相關知識時“軟懟”他的
【面試】吃透了這些Redis知識點,面試官一定覺得你很NB(干貨 | 建議珍藏)
【面試】如果你這樣回答“什么是執行緒安全”,面試官都會對你刮目相看(建議珍藏)
【面試】迄今為止把同步/異步/阻塞/非阻塞/BIO/NIO/AIO講的這么清楚的好文章(快快珍藏)
【面試】一篇文章幫你徹底搞清楚“I/O多路復用”和“異步I/O”的前世今生(深度好文,建議珍藏)
【面試】如果把執行緒當作一個人來對待,所有問題都瞬間明白了
Java多執行緒通關———基礎知識挑戰
品Spring:帝國的基石
>>> 玩轉SpringBoot系列文章 <<<
【玩轉SpringBoot】組態檔yml的正確打開姿勢
【玩轉SpringBoot】用好條件相關注解,開啟自動配置之門
【玩轉SpringBoot】給自動配置來個整體大揭秘
【玩轉SpringBoot】看似復雜的Environment其實很簡單
【玩轉SpringBoot】翻身做主人,一統web服務器
【玩轉SpringBoot】讓錯誤處理重新由web服務器接管
【玩轉SpringBoot】SpringBoot應用的啟動程序一覽表
【玩轉SpringBoot】通過事件機制參與SpringBoot應用的啟動程序
【玩轉SpringBoot】異步任務執行與其執行緒池配置
>>> 品Spring系列文章 <<<
品Spring:帝國的基石
品Spring:bean定義上梁山
品Spring:實作bean定義時采用的“先進生產力”
品Spring:注解終于“成功上位”
品Spring:能工巧匠們對注解的“加持”
品Spring:SpringBoot和Spring到底有沒有本質的不同?
品Spring:負責bean定義注冊的兩個“排頭兵”
品Spring:SpringBoot輕松取勝bean定義注冊的“第一階段”
品Spring:SpringBoot發起bean定義注冊的“二次攻堅戰”
品Spring:注解之王@Configuration和它的一眾“小弟們”
品Spring:bean工廠后處理器的呼叫規則
品Spring:詳細解說bean后處理器
品Spring:對@PostConstruct和@PreDestroy注解的處理方法
品Spring:對@Resource注解的處理方法
品Spring:對@Autowired和@Value注解的處理方法
品Spring:真沒想到,三十步才能完成一個bean實體的創建
品Spring:關于@Scheduled定時任務的思考與探索,結果尷尬了
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/24744.html
標籤:其他
下一篇:求助!!