1.背景
大資料開發的測驗環境,很多人不以為然,其實重復的打包,上傳,測驗雖然每次時間大概也就幾分鐘,但是積累起了往往會花費很多的時間,但是一個完整的測驗環境在生產環境下往往難形成倍訓,拋開堡壘機權限不說,hadoop,hive,spark等服務端的權限也會難倒一群英雄好漢,主要是太繁瑣了,測驗環境的搭建,我這里采用Docker容器,適合多端遷移,而且容器的鏡像大小也比虛擬機小很多,難度上說,也只需要掌握幾個基礎的命令即可,除非想引入K8s等技術,但測驗環境完全沒必要,Docker環境搭建大資料平臺的系列從這里大資料開發-Docker-使用Docker10分鐘快速搭建大資料環境,Hadoop、Hive、Spark、Hue、Kafka、ElasticSearch.....[https://blog.csdn.net/hu_lichao/article/details/112125800](https://blog.csdn.net/hu_lichao/article/details/112125800),環境搭建好了,可能還是會有一些特殊的問題
2.如何解決缺失winutils.exe
在Win作業系統,idea下開發hadoop程式或者Spark程式,那么你肯定會遇到下面的問題
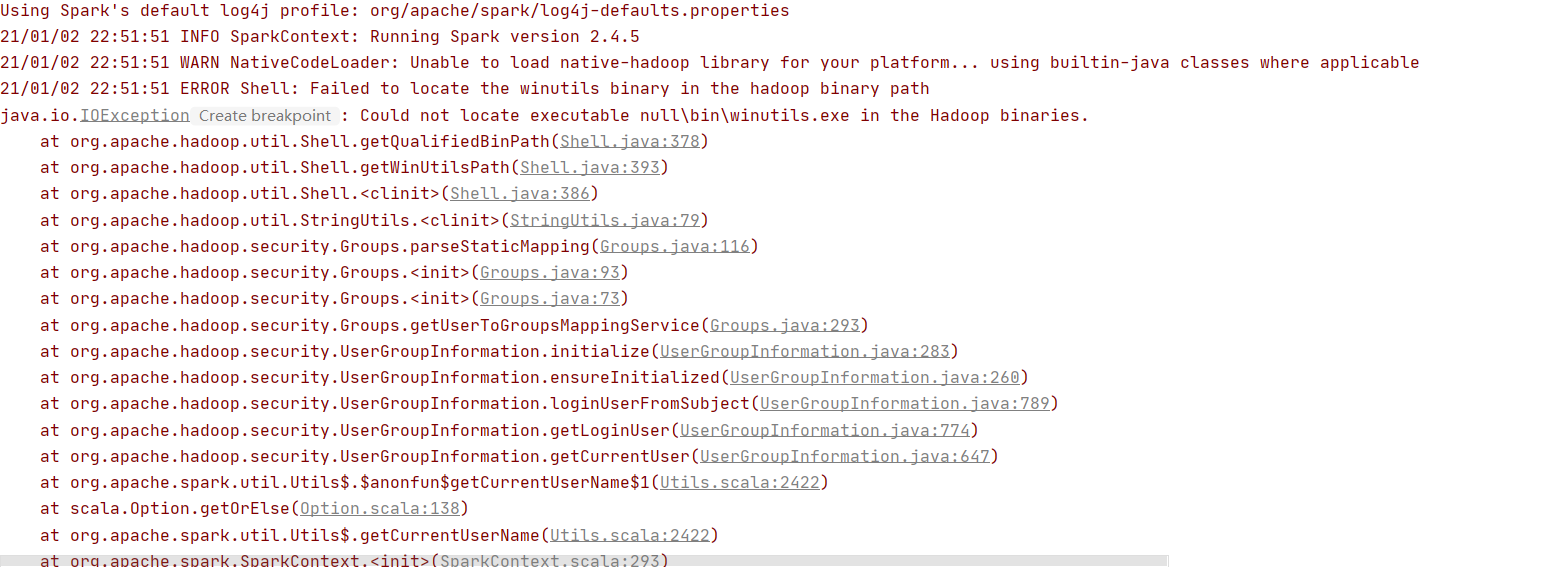
之所以出現上面的問題,Spark程式和Hadoop在idea寫撰寫的程式是依賴hadoop的環境的,所以要提前配置好,并且設定HADOOP_HOME ,不一定需要$HADOOP_HOME/bin 到PATH ,后者是給快捷方式用的
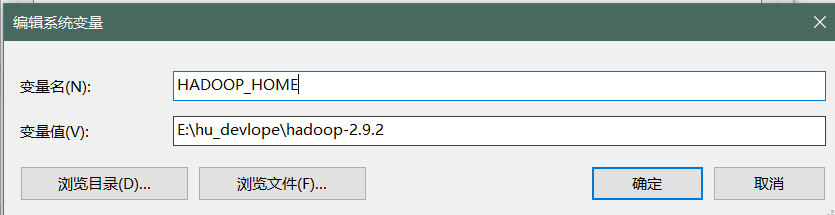
注意:配置完環境變數后要將idea,退出后重進,不能Restart
3.如何解決java.lang.NoSuchMethodError: org.apache.hadoop.security.authentication.util.KerberosUtil.hasKerberosKeyTab(Ljavax/security/auth/Subject;)Z
錯誤如下圖
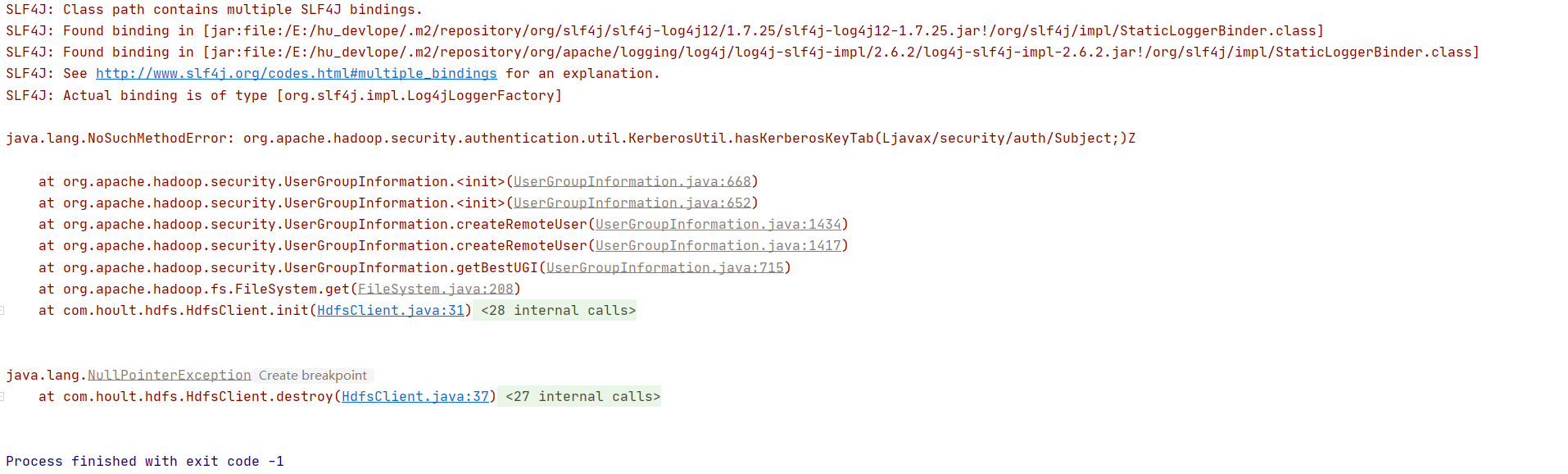
出現這個問題的原因是版本沖突,即使看起來不那么明顯,可能是spark依賴的包中的hadoop和hadoop依賴的版本不一致https://stackoverflow.com/questions/45470320/what-is-the-kerberos-method,具體不一致的問題,可能各有不同,解決難易程度因人而異??????,我的解決方式就是exclude掉spark的低版本hadoop
4.如何解決Exception in thread "main" org.apache.spark.SparkException: Task not serializable
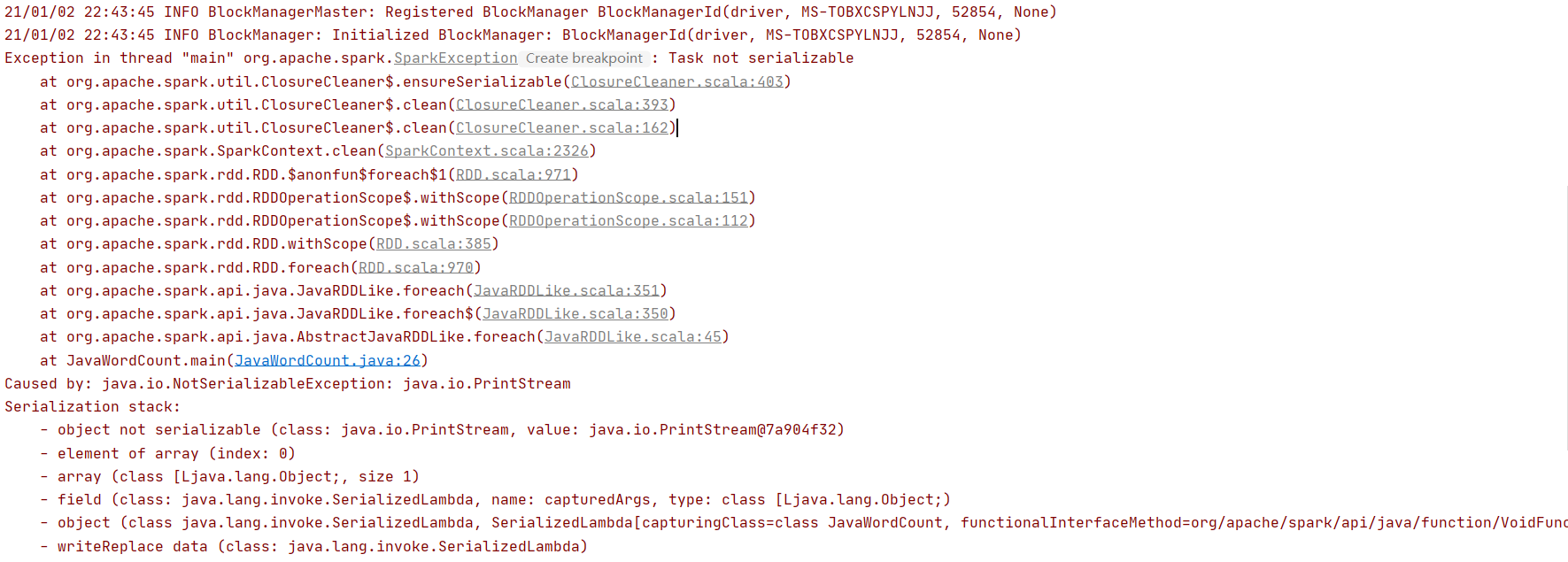
這個問題,我是這么遇到的,如下程式:
// results.foreach(System.out::println); //輸出沒有序列化
results.foreach(x -> System.out.println(x));
首先foreach是action算子,需要將task上的資料拉到driver上來遍歷顯示,就需要序列化,如果習慣了Java的lambda寫法,可能會寫第一種,第一種寫法的問題是沒有序列化,序列化是在閉包里完成的,而使用靜態方法呼叫的方式,沒有閉包化,所以會報序列化的問題,寫成第二種就可以了,System.out是一個final static物件,
public final static PrintStream out = null;
吳邪,小三爺,混跡于后臺,大資料,人工智能領域的小菜鳥,
更多請關注

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/247525.html
標籤:其他
上一篇:大資料開發-Docker-使用Docker10分鐘快速搭建大資料環境,Hadoop、Hive、Spark、Hue、Kafka、ElasticSearch.....