文章目錄
- 前言
- 1. 模型介紹
- 1.1 Encoder-Decoder框架
- 1.2 Attention機制
- 1.3 代碼實作
- 2. 安裝依賴庫
- 3. 模型部署
- 4. 測驗
前言
??哈哈,重頭戲終于來了,經過兩天的服務器配置、模型訓練,今天終于在微信公眾號上部署了自己使用TensorFlow訓練的聊天機器人,
??本篇博客主要介紹一下Seq2Seq模型,以及模型訓練后的部署,使用的深度學習框架為TensorFlow2.1,GPU為Tesla P100(白嫖Kaggle的),由于網站有時間限制,只訓練了兩個epoch就先部署了哈,所以機器人目前還很沙雕,
??有關騰訊云服務器配置流程和Django對接微信公眾號以實作訊息自動回復可以參考這兩篇博客,
1. 模型介紹
?? S e q 2 S e q Seq2Seq Seq2Seq的全稱是 S e q u e n c e Sequence Sequence t o to to S e q u e n c e Sequence Sequence,也就是我們常說的序列到序列模型,它是基于 E n c o d e r ? D e c o d e r Encoder-Decoder Encoder?Decoder框架的 R N N ( R e c u r r e n t RNN(Recurrent RNN(Recurrent N e u r a l Neural Neural N e t w o r k , 循 環 神 經 網 絡 ) Network,回圈神經網路) Network,循環神經網絡)變種, S e q 2 S e q Seq2Seq Seq2Seq引入 E n c o d e r ? D e c o d e r Encoder-Decoder Encoder?Decoder框架,提高了神經網路對長文本資訊的提取能力,取得了比單純使用 L S T M ( L o n g LSTM(Long LSTM(Long S h o r t ? T e r m Short-Term Short?Term M e m o r y , 長 短 期 記 憶 神 經 網 絡 ) Memory,長短期記憶神經網路) Memory,長短期記憶神經網絡)更好的效果, S e q 2 S e q Seq2Seq Seq2Seq中有兩個很重要的概念,一個就是上面提到的 E n c o d e r ? D e c o d e r Encoder-Decoder Encoder?Decoder框架,另一個就是 A t t e n t i o n Attention Attention機制,這里簡單介紹一下這兩個概念,
1.1 Encoder-Decoder框架
??
E
n
c
o
d
e
r
?
D
e
c
o
d
e
r
Encoder-Decoder
Encoder?Decoder又稱為編碼器-解碼器模型,顧名思義,它有兩部分組成,即編碼器和解碼器,它是一種處理輸入、輸出長短不一的多對多文本預測問題的框架,其提供了有效的文本特征提取、輸出預測的機制,
??編碼器的作用是對輸入的文本資訊進行有效的編碼后,將其作為解碼器的輸入資料,其目的是對輸入的文本資訊進行特征提取,盡量準確高效地表征該文本的特征資訊,
??解碼器的作用是從背景關系的文本資訊中獲取盡可能多的特征,然后輸出預測文本,根據對文本資訊的獲取方式不同,解碼器一般分為4種結構,分別是直譯式解碼、回圈式解碼、增強式解碼和注意力機制解碼,
- 直譯式解碼:按照編碼器的費那事進行逆操作得到的預測文本
- 回圈式解碼:將編碼器輸出的編碼向量作為第一時刻的輸入,然后將得到的輸出作為下一個時刻的輸入,依次進行回圈解碼
- 增強回圈式解碼:在回圈式解碼的基礎上,每一時刻增加一個編碼器輸出的編碼向量作為輸入
- 注意力機制解碼:在增強式回圈解碼的基礎上增加注意力機制,這樣可以有效地訓練解碼器在繁多的輸入中重點關注某些有效特征資訊,以增加解碼器的特征獲取能力,進而得到更好的解碼效果,
1.2 Attention機制
??雖然
E
n
c
o
d
e
r
?
D
e
c
o
d
e
r
Encoder-Decoder
Encoder?Decoder結構的模型在機器翻譯、語音識別以及文本生成等諸多領域均取得了非常不錯的效果,但同時也存在著不足之處,編碼器將輸入的序列編碼成一個固定長度的向量,再由解碼器將其解碼,得到輸出序列,但個固定長度的向量所具有的表征能力是有限的,解碼器又受限于這個固定長度的向量,當輸入的文本序列較長時,編碼器很難將所有的重要資訊都編碼到這個定長的向量中,從而使得模型的輸出結果大大折扣,
??
A
t
t
e
n
t
i
o
n
Attention
Attention機制有效解決了輸入長序列資訊時真實含義難以獲取的問題,在進行長文本序列處理的任務中,影響當前時刻狀態的資訊可能隱藏在前面的時刻里,根據馬爾可夫假設,這些資訊有可能就會被忽略掉,比如,在“我快餓死了,今天搬了一天的磚,我要大吃一頓”這句話中,我們知道“我要大吃一頓”是因為“我快餓死了”,但是基于馬爾可夫假設,“今天搬了一天的磚”和“我要大吃一頓”在時序上離得更近,相比于“我快餓死了”,“今天搬了一天的磚”對“我要大吃一頓”的影響力更強,但是在真實的
N
L
P
(
N
a
t
u
r
a
l
NLP(Natural
NLP(Natural
L
a
n
g
u
a
g
e
Language
Language
P
r
o
c
e
s
s
i
n
g
,
自
然
語
言
處
理
)
Processing,自然語言處理)
Processing,自然語言處理)中不是這樣的,從這個例子中可以看出,神經網路模型沒有辦法很好地準確獲取倒裝時序的語言資訊,要解決這個問題就需要經過訓練自動建立起“我要大吃一頓”和“我快餓死了”的關聯關系,這就是
A
t
t
e
n
t
i
o
n
Attention
Attention機制,即注意力機制,
1.3 代碼實作
class Encoder(tf.keras.Model):
"""編碼器"""
def __init__(self, vocab_size, embedding_dim, enc_units, batch_size):
super(Encoder, self).__init__()
self.batch_size = batch_size
self.enc_units = enc_units
self.embedding = tf.keras.layers.Embedding(input_dim=vocab_size, output_dim=embedding_dim)
self.gru = tf.keras.layers.GRU(units=self.enc_units, recurrent_initializer='glorot_uniform',
return_sequences=True, return_state=True)
def call(self, x, hidden):
# 此處添加模型呼叫的代碼(處理輸入并回傳輸出)
x = self.embedding(x)
output, state = self.gru(inputs=x, initial_state=hidden)
return output, state
def initialize_hidden_state(self):
return tf.zeros(shape=(self.batch_size, self.enc_units))
class BahdanauAttention(tf.keras.Model):
"""Bahdanau Attention"""
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W1 = tf.keras.layers.Dense(units=units)
self.W2 = tf.keras.layers.Dense(units=units)
self.V = tf.keras.layers.Dense(units=1)
def call(self, query, values):
# query為Encoder最后一個時間步的隱狀態(hidden), shape為(batch_size, hidden_size)
# values為Encoder部分的輸出,即每個時間步的隱狀態,shape為(batch_size, max_length, hidden_size)
# 為方便后續計算,需將query的shape轉為(batch_size, 1, hidden_size)
# 給query增加一個維度
query = tf.expand_dims(input=query, axis=1)
# 計算score(相似度), 使用MLP網路,即再引入一個神經網路來專門計算score
# score的shape為(batch_size, max_length, 1)
score = self.V(
inputs=tf.nn.tanh(self.W1(inputs=query) + self.W2(inputs=values))
)
# 計算attention_weights
# 計算attention_weights的shape為(batch_size, max_length, 1)
attention_weights = tf.nn.softmax(logits=score, axis=1)
# 計算context vector
# context vector的shape為(batch_size, max_length, hidden_size)
context_vector = attention_weights * values
# 加權求和
# 求和之后的shape為(batch_size, hidden_size)
context_vector = tf.reduce_sum(input_tensor=context_vector, axis=1)
return context_vector, attention_weights
class Decoder(tf.keras.Model):
"""解碼器"""
def __init__(self, vocab_size, embedding_dim, dec_units, batch_size):
super(Decoder, self).__init__()
self.batch_size = batch_size
self.dec_units = dec_units
self.embedding = tf.keras.layers.Embedding(input_dim=vocab_size, output_dim=embedding_dim)
self.gru = tf.keras.layers.GRU(units=self.dec_units, recurrent_initializer='glorot_uniform',
return_sequences=True, return_state=True)
self.fc = tf.keras.layers.Dense(units=vocab_size)
self.attention = BahdanauAttention(units=self.dec_units)
def call(self, x, hidden, enc_output):
# 獲取context vector和attention weights
context_vector, attention_weights = self.attention(hidden, enc_output)
# 編碼之后x的shape為(batch_size, 1, embedding_dim)
x = self.embedding(inputs=x)
# 將context_vector與輸入x進行拼接
# 拼接后的shape為(batch_size, 1, embedding_dim + hidden_size)
# 這里的hidden_size即context_vector向量的長度
x = tf.concat(values=[tf.expand_dims(input=context_vector, axis=1), x], axis=-1)
# 拼接后輸入GRU網路
output, state = self.gru(inputs=x)
# print("Decoder output shape: {}".format(output.shape))
# print("Decoder state shape: {}".format(state.shape))
# (batch_size, 1, hidden_size) ==> (batch_size, hidden_size)
output = tf.reshape(tensor=output, shape=(-1, output.shape[2]))
# x的shape為(batch_size, vocab_size)
x = self.fc(inputs=output)
return x, state, attention_weights
??我也是這學期才開始入手TensorFlow2,以前用的都是TensorFlow 1.13.1,代碼不明白的地方可以查看《簡單粗暴 TensorFlow 2》檔案,
2. 安裝依賴庫
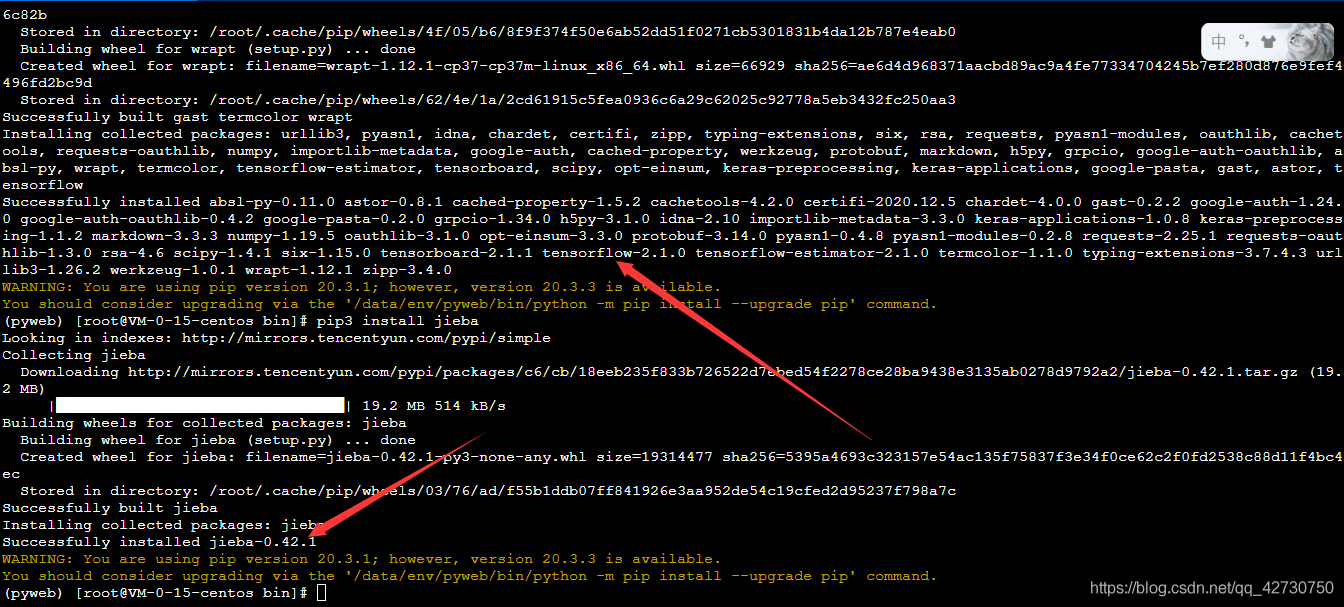
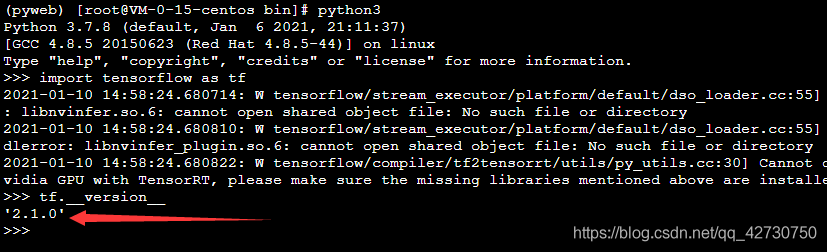
- 安裝TensorFlow 2.1
pip3 install tensorflow==2.1.0
- 安裝jieba
pip3 install jieba
3. 模型部署
??騰訊云服務器用的是學生版的1核2G,感覺不一定能夠支撐模型運行,先嘗試一下吧,在此之前還是在本地通過Postman進行一下測驗:
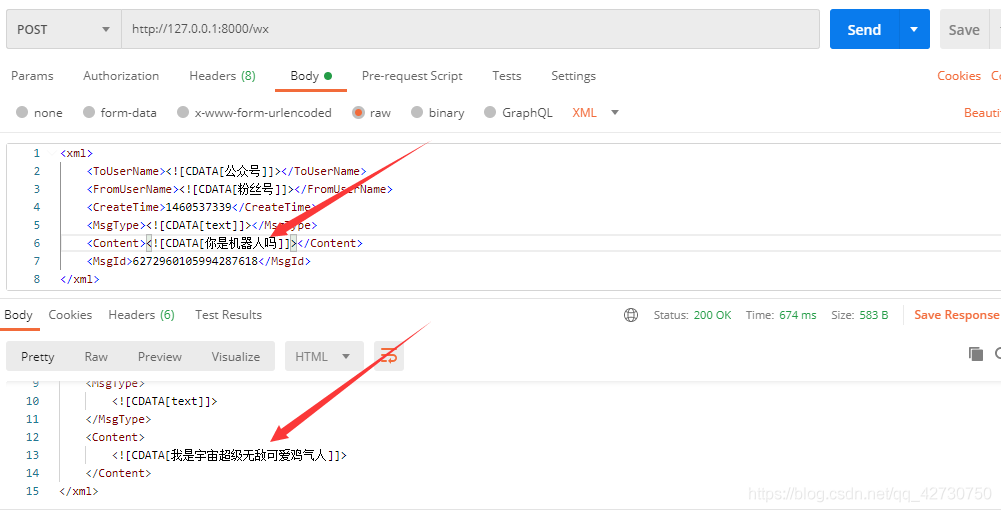
??還是OK的,就是模型加載的較慢,下面把模型檔案以及相關代碼上傳到服務器的專案目錄,目錄內容更新為如下:
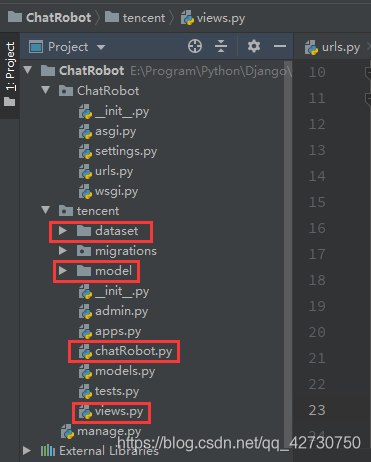
??上傳到服務器之后,大致等到模型差不多加載好就可以準備測驗了,測驗結果如下:

??查看一下日志檔案,發現了一些端倪:
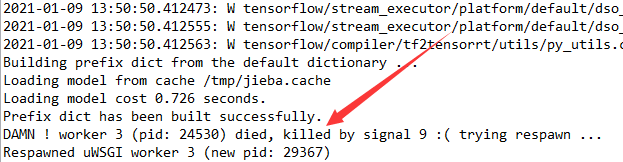
??行程被殺死了,查了一下相關檔案,說是超時了,enmmmmm,貌似有些道理【雖然不是很確定,但是模型確實是被重新加載了,更改了相關uwsgi的引數之后依舊是這個結果】,于是我直接上傳了一個更改后的測驗模型檔案CR.py,直接在環境中運行,果不其然:
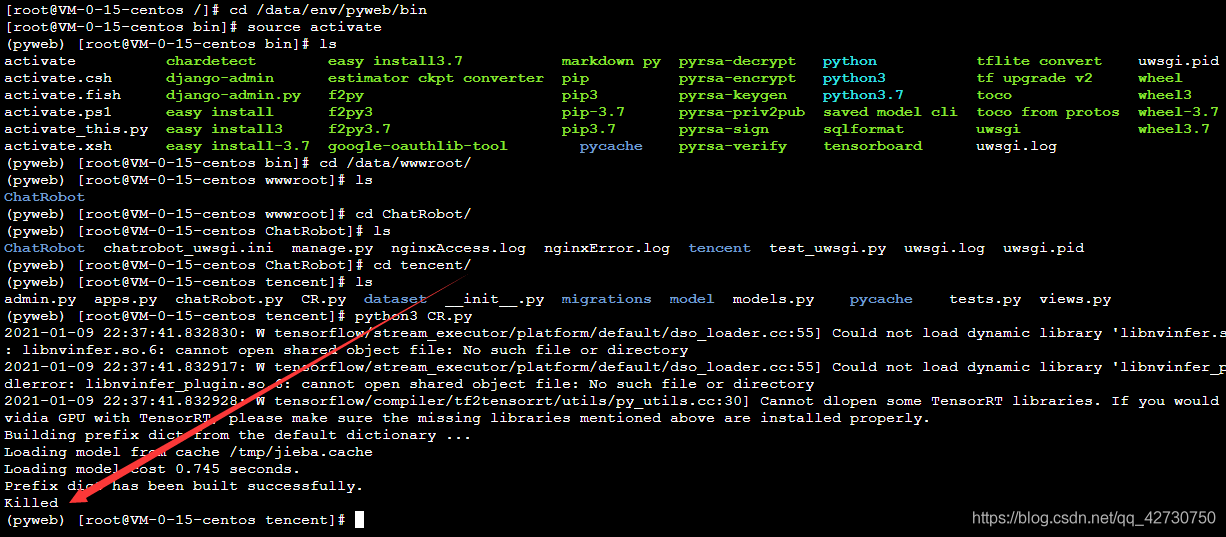

??這應該是記憶體不夠吧~OK,暫時到此結束,
??昨天出了一點意外,1核2G的騰訊云服務器運行不了這個模型,所以今天換成了2核4G的阿里云服務器【有一說一,阿里云的這個學生套餐還是挺實惠的,又成功白嫖】,阿里云的配置程序同騰訊云的一樣,可參考我的這篇博客,
??服務器配置完成之后,把專案檔案上傳到阿里云服務器的wwwroot檔案夾下,然后進入pyweb虛擬環境,再次運行一下CR.py檔案,看看模型能不能運行起來,結果如下:
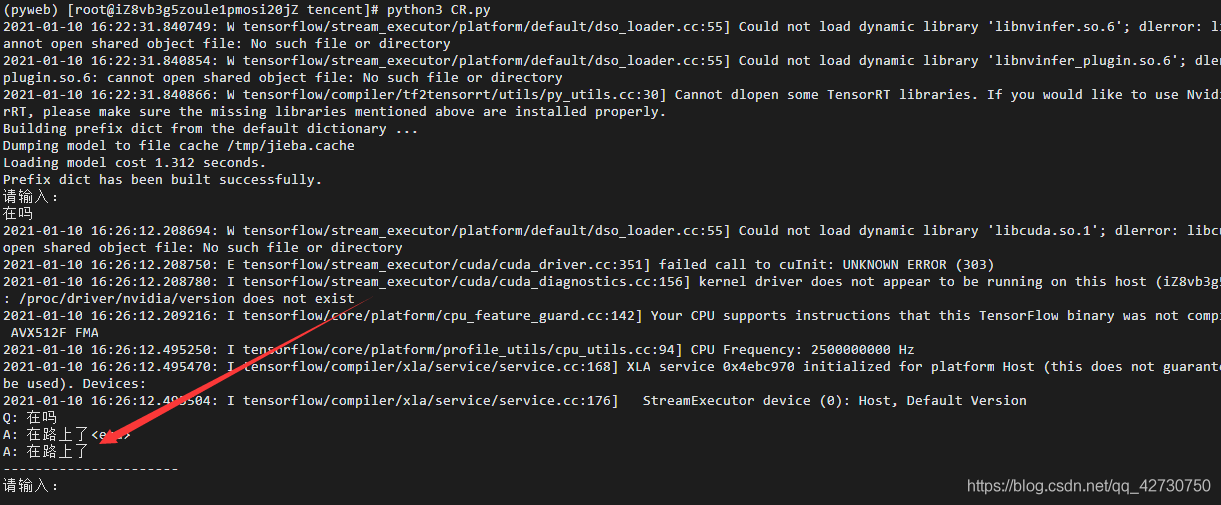
??還是很nice的,模型能夠運行,OK,接入到微信公眾號上,配置代碼很簡單,只需要把微信公眾號發送過來的訊息送入到模型即可,代碼如下:
# views.py
# 匯入模型的介面
from tencent.chatRobot import predict
input_info = recMsg.Content.decode('utf-8')
try:
content = predict(sentence=input_info)
except Exception as err:
content = '小悠沒理解主銀的意思~'
replyMsg = TextMsg(toUser, fromUser, content)
??當時,還考慮了很久,模型如何先被加載,因為模型加載的時間稍長,不能等到微信公眾號訊息來了再加載模型,那肯定會超時的,而且每次都加載,肯定還很麻煩,當時還考慮到用執行緒等方法來加載,enmmmmm,后來嘛,就突然想到,為何不用全域變數的形式來加載,就是Python執行的時候是順序執行嘛,像函式、類之類的這種物件,雖然定義了,但只要不被呼叫,這些代碼就不會被運行,而函式、類之外的代碼會正常按順序執行,相當于就是全域變數了嘛,
# chatRobot.py
# -*- coding: utf-8 -*-
# @Time : 2021/1/4 22:47
# @Author : XiaYouRan
# @Email : youran.xia@foxmail.com
# @File : chatRobot.py
# @Software: PyCharm
import tensorflow as tf
import jieba
import os
def preprocess_sentence(sentence):
"""
給句子添加開始和結束標記
:param sentence:
:return:
"""
sentence = '<start> ' + sentence + ' <end>'
return sentence
def max_length(tensor):
"""
計算資料集中問句和答句中最長的句子長度
:param tensor:
:return:
"""
return max([len(t) for t in tensor])
def tokenize(sentences):
"""
分詞器函式
:param sentence:
:return:
"""
# 初始化分詞器,并生成詞典
sentence_tokenizer = tf.keras.preprocessing.text.Tokenizer(filters='')
sentence_tokenizer.fit_on_texts(sentences)
# 利用字典將文本資料轉為id
# 也是二維的
tensor = sentence_tokenizer.texts_to_sequences(texts=sentences)
# 將資料填充成統一長度
# 默認統一為最長句子長度
# 將長為nb_samples的序列(標量序列)轉化為形如(nb_samples,nb_timesteps) 2D numpy array
tensor = tf.keras.preprocessing.sequence.pad_sequences(tensor, maxlen=30, padding='post')
return tensor, sentence_tokenizer
def load_dataset(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
q = ''
a = ''
qa_pairs = []
# len(lines) 總行數
for i in range(len(lines)):
if i % 3 == 0:
q = ' '.join(jieba.cut(lines[i].strip()))
elif i % 3 == 1:
a = ' '.join(jieba.cut(lines[i].strip()))
else:
# 問句與答句進行組合
pair = [preprocess_sentence(q), preprocess_sentence(a)]
qa_pairs.append(pair)
# zip 拆解
q_sentences, a_sentences = zip(*qa_pairs)
# question資料集(id)及其分類器詞匯表
q_tensor, q_tokenizer = tokenize(q_sentences)
# answer資料集(id)及其分類器詞匯表
a_tensor, a_tokenizer = tokenize(a_sentences)
return q_tensor, a_tensor, q_tokenizer, a_tokenizer
class Encoder(tf.keras.Model):
"""編碼器"""
class BahdanauAttention(tf.keras.Model):
"""Bahdanau Attention"""
class Decoder(tf.keras.Model):
"""解碼器"""
# 使用Adam優化器
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
def predict(sentence):
"""模型測驗"""
# 加載模型
checkpoint = tf.train.Checkpoint(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
encoder=encoder,
decoder=decoder)
checkpoint.restore(save_path=tf.train.latest_checkpoint(checkpoint_dir=checkpoint_dir))
sentence = ' '.join(jieba.cut(sentence.strip()))
sentence = preprocess_sentence(sentence=sentence)
inputs = [q_tokenizer.word_index[i] for i in sentence.split(' ')]
inputs = tf.keras.preprocessing.sequence.pad_sequences(sequences=[inputs], maxlen=30, padding='post')
inputs = tf.convert_to_tensor(value=inputs)
result = ''
hidden = [tf.zeros(shape=(1, units))]
enc_out, enc_hidden = encoder(inputs, hidden)
dec_hidden = enc_hidden
dec_input = tf.expand_dims(input=[a_tokenizer.word_index['<start>']], axis=0)
for t in range(q_tesor_length):
predictions, dec_hidden, attention_weights = decoder(dec_input, dec_hidden, enc_out)
predicted_id = tf.argmax(predictions[0]).numpy()
result += a_tokenizer.index_word[predicted_id] + ' '
if a_tokenizer.index_word[predicted_id] == '<end>':
break
dec_input = tf.expand_dims(input=[predicted_id], axis=0)
# print("Q: %s" % sentence[8:-6].replace(' ', ''))
# print("A: {}".format(result[:-6].replace(' ', '')))
# print("A: {}".format(result.replace(' ', '')))
return result[:-6].replace(' ', '')
file_path = os.path.dirname(__file__)
corpus_path = os.path.join(file_path, 'dataset/corpus.txt')
checkpoint_dir = os.path.join(file_path, 'model/train_checkpoints')
q_tensor, a_tensor, q_tokenizer, a_tokenizer = load_dataset(file_path=corpus_path)
q_tesor_length = max_length(q_tensor)
a_tesor_length = max_length(a_tensor)
buffer_size = len(q_tensor)
batch_size = 32
steps_per_epoch = len(q_tensor) // batch_size
embedding_dim = 128
units = 256
# q_tokenizer.word_index 字典型別(word, id)
vocab_q_size = len(q_tokenizer.word_index) + 1
vocab_a_size = len(a_tokenizer.word_index) + 1
# 模型初始化
encoder = Encoder(vocab_size=vocab_q_size, embedding_dim=embedding_dim, enc_units=units, batch_size=batch_size)
attention_layer = BahdanauAttention(units=10)
decoder = Decoder(vocab_size=vocab_a_size, embedding_dim=embedding_dim, dec_units=units, batch_size=batch_size)
if __name__ == '__main__':
input_sentence = "Start chatting..."
while input_sentence != "stop":
print("請輸入:")
input_sentence = input()
try:
predict(input_sentence)
print("----------------------")
except Exception as err:
print('Test model error info: ', err)
4. 測驗
??首先要把微信公眾號的基本配置改一下,把那個服務器地址更改成阿里云的公網IP,然后啟動服務器就可以了(大致需要五六分鐘),
??測驗的結果如下:
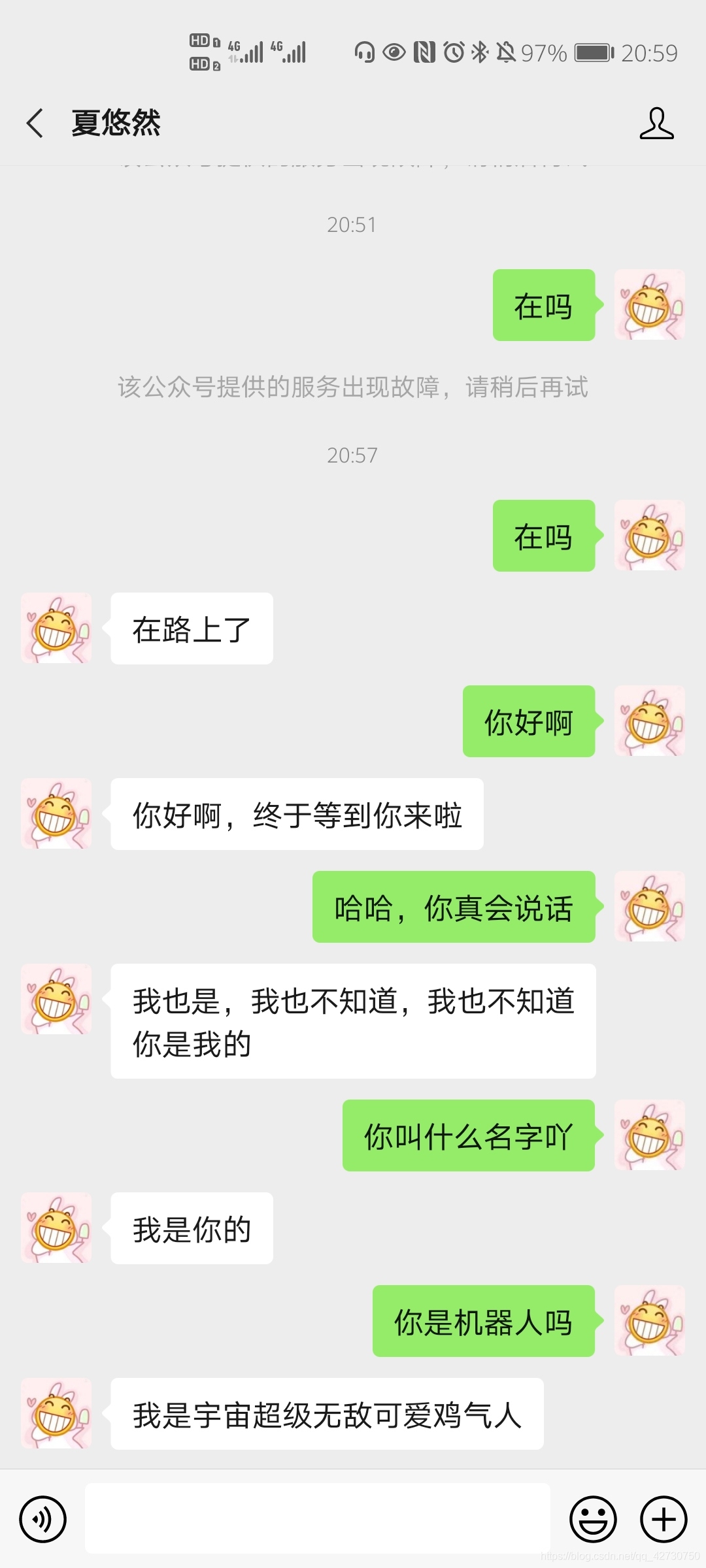
??目前來看,機器人還很沙雕,畢竟只訓練了兩個epoch,準備再多訓練幾次,不過整體來看還蠻好的,部署的流程成功的走了一下,接下來就開始繼續訓練模型了,
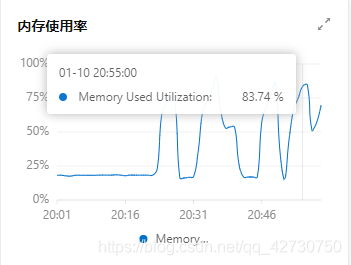
??在阿里云后臺看了一下服務器,模型確實比較吃記憶體,4G記憶體占用了近80%,怪不得2G記憶體不夠用!
??總的來說,很OK,很nice!!!!想體驗的小伙伴們,歡迎來玩哦,關注微信公眾號夏悠然,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/247594.html
標籤:AI
下一篇:CSDN 博客之星