上個禮拜我就想噴eBPF了,由于周末時間實在太緊,就準備拖延一周,但還是立了個flag,先發了個朋友圈:
ebpf就像牛皮蘚一樣,已經遍布在linux內核的各個角落,每個呼叫點都看上去很隨意,毫無規劃,讓人覺得好像自己覺得哪里需要這么一個呼叫點并不很難…
但實際上如果你真的去嘗試在某處加一個ebpf呼叫點時,就會覺得這件事和清除牛皮蘚的程序非常類似,修改散落在各個目錄的多個檔案,還得重新編譯,大概率失敗,還要重新做一次,很難一次做干凈,當你好不容易成功了,會有一種“不過如此”的嗟嘆…
我曾將ebpf比做擴散的癌細胞,這個比喻沒有給人密集恐懼的效果,所以我換成了牛皮癬,該存在ebpf呼叫點的地方一個也沒有,沒必要ebpf的地方到處都是,這些點還在持續增加,迄至5.11內核,ebpf已經有大三十個點了,依然在毫無規劃地瘋長著…
eBPF是個創新,但人們明顯狂熱過度了,ebpf增加呼叫點也過于隨意,太業務導向了,損壞了內核的內聚性,遠遠比不上當初netfilter的五個hook點以及qdisc這種經過良好設計的機制,另外還有一個問題,netfilter的五個hook點上如果部署了ebpf點,其實就能解決大部分性能問題,然而直到現在都沒有,感覺是社區矯枉過正了,真的徹底把netfilter當成了舊時代的象征,把馬殺掉的同時,輪子也不要了
人們都像蟲子一樣在這里你爭我搶,吃的都是良心,拉的全是思想,
終于到了周末,我終于還是不能說話,我甚至已經不知道該說些什么了,
昨天,我把自己血祭了,這種自我犧牲在古羅馬共和國是一種美德,執政官會把自己獻給神,以換取戰爭的勝利,
為了噴eBPF,在平時的作業和學習中,我積累了很多素材,eBPF的領地分為兩個部分:
- 網路協議堆疊功能
- trace跟蹤
在網路方面,我用牛皮癬的比喻來說明eBPF不斷瘋長的畫面是多么糟糕,而在trace跟蹤方面,我想拿性能和功能說事,
我本希望用這些素材來佐證自己的一些怪異的觀點,昨天,我準備用我的實際作業來作為我最后一個素材,結果它恰恰驗證了我的認知錯誤,它恰恰說明了eBPF作為trace跟蹤工具是多么的好用!
我的故事是這樣的,
在大流量的背景下,特別是如果你的代碼使用類似Bonding,tun/tap,GRE,IPIP等虛擬網卡,排查skb在哪里被drop一直都是一個很麻煩的事情,即便是你已經知道了一個特定的五元組,這件事也不會因此變得簡單,
抓包?抓包永遠是第一步的操作,但也只是第一步,它只能告訴你skb收到了或者沒有收到,如果沒有收到,進一步就需要確認skb到底在哪里丟了,當然了,如果最后實在是定位不了,一般會把鍋甩給運營商這個黑洞,
?
類似wireguard這種,其所有復雜的操作,包括加密,分發等邏輯在內均在wireguard虛擬網卡的xmit函式中完成,跟蹤wg_xmit的細節除了要求你對wireguard的代碼非常熟悉之外,還需要各種奇技淫巧的手藝,
?
以下面這個場景為例:
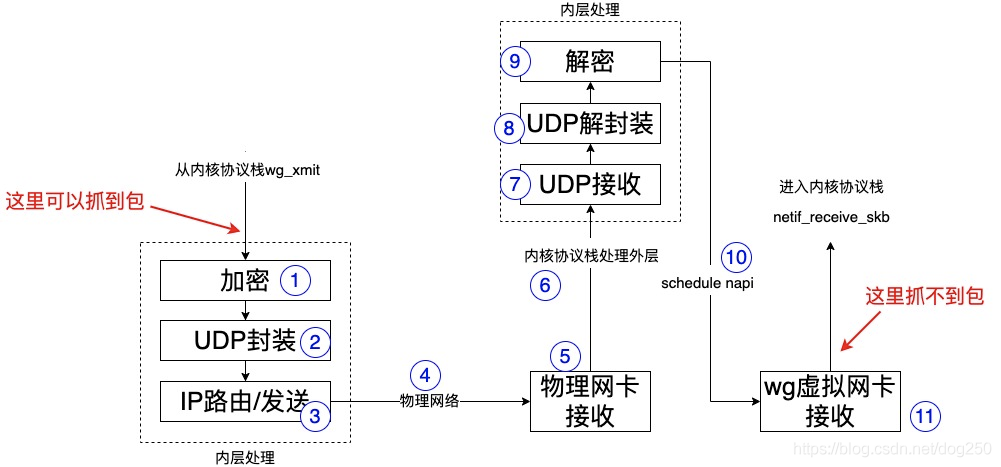
我要實錘skb在從1到11的哪一步被drop的,要怎么做?
?
這不正是stap的地盤嗎?哦,我不能說stap,在有了bpftrace可供選擇的時候,再說stap有點不正確,如果我堅持要用stap,會有一群人建議我用bpftrace,并說stap是多么的糟糕,過時,不友好,
那好,那就用bpftrace,下面的腳本可以對skb進行完美的全程trace:
#!/usr/local/bin/bpftrace
?
#include <linux/skbuff.h>
#include <linux/udp.h>
#include <net/sock.h>
?
k:encrypt_packet
{
$skb = (struct sk_buff *)arg0;
// 這個skb的mark需要iptables來為特定的五元組標記上,但是encrypt_packet這里是可以使用mark的最后的地方,
// 在encrypt_packet成功回傳后,skb的幾乎所有附屬標記都會被reset,包括skb->mark,
// 因此這里必須用另一個標記,以確保在encrypt_packet之后還能用此特征跟蹤到特定的skb,
// 由于bpftrace只能讀不能寫,這里我選擇直接用skb的地址!
if ($skb->mark == 1234) {
printf("encrypt got %p\n", $skb);
@addr = $skb;
}
}
?
//k:send4
k:udp_tunnel_xmit_skb
{
$daddr = arg4;
$saddr = arg3;
$skb = (struct sk_buff *)arg2;
// 這里除了match地址之外,是不是也要match一下其它欄位呢?畢竟slub中的skb是可以重用的,
// 如果mark 1234的skb在這個之前被drop & free了,它被重新alloc后依然會到這里,這就錯了!
// 然而由于流量可控,且我是一個函式一個函式trace,上述概率極低,手藝人不求完美!
if ($skb == @addr) {
printf("---- skb:%p daddr:%08x saddr:%08x \n", @addr, $daddr, $saddr);
}
}
?
k:iptunnel_xmit
//k:dev_queue_xmit
//k:dev_hard_start_xmit
//k:dev_queue_xmit_nit
{
$skb = (struct sk_buff *)arg2;
// 從裸包中取外層協議頭的內容,
$udph = (struct udphdr *)($skb->head + $skb->transport_header);
$sport = $udph->source;
$dport = $udph->dest;
if ($skb == @addr) {
$port = (($sport & 0xff00) >>8) | (($sport & 0xff) << 8);
$port2 = (($dport & 0xff00) >>8) | (($dport & 0xff) << 8);
printf("sport:%d dport:%d\n", $port, $port2);
// trace結束,重置全域變數,
@addr = (struct sk_buff *)0;
}
}
啊哈,我覺得這是一個讓人感覺很順暢的腳本,skb在進入wg_xmit前打上mark,在wg_xmit的程序中清除skb的mark之前將其地址保存,此后跟蹤該地址的skb,然而悲哀的是,skb順利發送出去了,我一無所獲,然而悲哀的是,內層的報文在對端wireguard的wg網卡上沒有抓到,
?
去對端反著來一遍且OK?思路是一回事,落地是另一回事,
?
怎么才能在對端繼續trace這個skb呢?
如果沒有辦法trace這個skb,你怎么區分這個報文是被中間網路設備drop了還是被對端wireguard接收程序drop了呢?由于發送端已經可以獲取內層和外層的特定五元組,在接收端用外層五元組去match外層協議頭當然是一個正確的思路,問題是如果外層隧道的五元組被大流量復用,你又將如何在skb解密前去匹配內層五元組,流量實在太大了,就像很多抓包由于流量大無法進行一樣,你想要的資訊幾憾訓被瞬間淹沒!
?
我想知道的是,bpftrace怎么來做這件事,如果不能方便快捷地解決這個問題,我就有充分的理由使用舊時代的舊事物了,
?
問題是bpftrace不允許我修改skb啊!現在,我決定扔掉bpftrace,用stap來做正確的事,
?
我需要做的僅僅是,為特定的資料包打上一個標記,該標記必須在對端可以被識別,我決定使用無傷大雅的IP頭TTL欄位,使用stap完成這件事非常簡單,順便地,我將為skb打mark這件事也用stap來做,于是我也刪掉了iptables規則:
#!/usr/local/bin/stap -g
%{
#include <linux/skbuff.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#include <net/addrconf.h>
struct sk_buff *tmp = NULL;
%}
function getinfo(pskb:long)
%{
struct sk_buff *skb = (struct sk_buff *)STAP_ARG_pskb;
struct iphdr *hdr = ip_hdr(skb);
const struct skb_shared_info *shinfo = skb_shinfo(skb);
struct dst_entry *dst = skb_dst(skb);
if (dst && !strcmp("wg0", dst->dev->name)) {
struct tcphdr *tp = (struct tcphdr *)((char *)hdr + sizeof(struct iphdr));
if (ntohs(tp->source) == 443 && ntohs(tp->dest) == 3663) {
STAP_PRINTF("sport:%d dport:%d addr:%p\n", ntohs(tp->source), ntohs(tp->dest), skb);
skb->mark = 1234;
tmp = skb;
}
}
%}
probe kernel.function("ip_forward")
{
getinfo($skb)
}
function setttl(pskb:long)
%{
struct sk_buff *skb = (struct sk_buff *)STAP_ARG_pskb;
struct iphdr *hdr;
if (skb == NULL)
return;
hdr = ip_hdr(skb);
if (skb == tmp) {
hdr->ttl = 120;
tmp = NULL;
}
%}
// 這個是在確認了skb順利通過了wg server后,為了在wg client端跟蹤所使用的,
// 由于資料包沒有什么好的欄位可利用來打標,就隨手選了ttl,作為一個特殊值,不一定是120,180更好,,,
probe kernel.function("ip_local_out")
{
setttl($skb)
}?
如此一個腳本,在對端直接match外層五元組和TTL值就行了,我們只需要在匹配外層五元組的同時,匹配TTL值大于70的skb即可,bpftrace只能讀不能寫,為了讓這件事成為可能,我只能用stap,
?
以上就是我的態度,我不是不接受bpftrace,我更不是不接受新事物,我只是想說不能在接受新事物的時候把舊事物一棍子打死!不能因為eBPF的流行就選擇bpftrace而把stap丟進垃圾桶,
?
…
?
我正準備吐槽,然而我正準備噴bpftrace做不到某某事情的時候,我血祭了!
?
我明明可以在wireguard的資料接收端像資料發送端一樣用bpftrace來trace這個特定的skb,畢竟我只是想知道它在哪里被drop了,這完全沒有寫操作的必要,然而我為了一種假裝成格調的態度,死活非要用stap來完成這件事而放棄bpftrace,
?
雖然我自以為自己是stap的熟練工,但我卻幾乎都是在用-g的guru模式,不是因為我自信,而是因為我搞不清楚又記不住stap的語法,我幾乎只會C和匯編,我幾乎總是記不住任何其它語言的語法,包括Bash在內…
?
我在使用stap來trace內核或者模塊的函式前,我總會看下它的引數決議情況:
stap -L 'module("wireguard").function("wg_allowedips_lookup_src")'?
很不幸,無法使用任何引數,原因未知,因此當我希望使用它的引數的時候,我只能裸取暫存器了,像下面這樣:
...
probe module("wireguard").function("wg_allowedips_lookup_src")
{
// 由于stap -L無法決議引數,只能用x86_64的呼叫規則直接取暫存器
if (cmpskb(register("rsi"))) {
a = 1;
}
}
probe module("wireguard").function("wg_allowedips_lookup_src").return
{
if (a == 1) {
printf("peer returned::%p\n", register("rax"));
a = 0;
}
}?
...
既然都用stap了,為何不讓事情簡單一些呢?于是我就開始了自信滿滿的寫操作,改skb記憶體,手工修改skb的data,以期望能bypass掉很多不必要的流程,
?
…
?
在我持續這么玩了大概幾個小時后,大概就是開著飛機修引擎的感覺,我有些疲勞,大概在某個精確的時間點,crash or soft lockup,完美的完成了血祭!
這是一次線上作業,鍋顯然是我的,
?
這不能說明我的手藝不精湛,在這種硬著陸之前,我畢竟還放飛了幾個小時呢,但這說明一個問題,bpftrace就是比stap好,至少安全,而這恰恰是我要反駁的觀點,卻被我證明了,
在穩定性方面,eBPF的兩個不允許就夠了:
- eBPF不允許你寫任何有潛在風險的代碼,
- eBPF不允許你寫任何復雜的代碼,
stap里你可以隨便一個while(true)而把系統鎖死,bpftrace中卻不行,
…
處理類似的問題時,其實我是帶有偏見的,我不喜歡使用工具特別是不喜歡使用新工具的原因背后更多的是因為我比較懶,我不喜歡面對和駕馭一大坨不相關的東西,比方說我明明知道有個dropwatch卻沒有使用,就是因為它太復雜了,還要去了解那么復雜的命令列,與其這樣,還不如我直接stap probe kfree_skb然后dump_stack呢,
一開始我對stap也是抵觸的,因為它也是足夠復雜,我寧愿裸寫ftrace函式,比方說手工把一個函式的頭5個位元組替換成call stub_handler這種,如今即便我對stap已經輕車熟路了,我依然還是堅持只寫guru模式的腳本,我依然還是懶得去學習stap的語法,
使用工具提高效率那是針對熟悉這種工具的人來講的,對于不熟悉該工具的來講,比如我,花在學習這種工具的使用方法上的時間將讓我延遲對真正問題的處理,
同樣,磨刀不誤砍柴工,工欲善其事必先利其器,我并不贊同這是普適的,這種話術是針對頻繁解決同類問題的人來講的,他們需要的是總結出一種范式,錘子能釘釘子,如果你需要頻繁釘釘子,你當然需要買一把錘子,但如果你只需要釘一次釘子,隨手拿起邊上的一塊磚或許比去買一把錘子更方便,
如果你每次玩的都是新花樣,當然不需要工具了,
此外 “在路上” 的價值觀在我針對工具的觀點也起到了推波助瀾的作用,我一向覺得自己是在路上的人,因此我討厭任何累贅,我不回去攜帶,背負,記憶那些隨處可以得到的東西,杭州往上海搬家,既然上海可以買到被子,我何必要把被子寄回來,直接扔掉不是更好嗎?
在石器時代,人們就已經擁有了類別豐富的工具,但對于一個母系時代凈身出戶的男人而言,唯一可以帶走并且他們自愿選擇的工具就是弓箭,彈弓這種類似的遠程攻擊工具,可能就連刀,斧之類的,都屬于累贅,抓住問題的本質本身,這就足夠了,
浙江溫州皮鞋濕,下雨進水不會胖!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/247601.html
標籤:AI
上一篇:實作網頁長截圖的常見思路總結