大資料學習筆記第3課 基于Yarn的Spark實時計算
- 1、說明
- 2、hadoop單節點運行mapreduce程式
- 3、配置Yarn集群
- 4、使用hadoop Yarn集群運行mapreduce程式
- 5、下載并安裝spark
- 5、配置spark使用本地單節點計算圓周率PI
- 6、配置spark使用集群節點計算圓周率PI
- 7、總結
1、說明
本文是在前面2課搭建好的hadoop集群的基礎上進行的,如果不熟悉環境請先看前面的2課練習,
- 《大資料學習筆記第1課 Hadoop基礎理論與集群搭建》
- 《大資料學習筆記第2課 Zookeeper & Kafka集群搭建》
- 《大資料學習筆記第2課(續) 通過filebeat收集nginx訪問日志到kafka集群》
本文的測驗程式使用的是hadoop官方案例程式,程式所在目錄如下(關于mapreduce程式結構與案例原始碼不在本文范圍)
/program/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar
2、hadoop單節點運行mapreduce程式
mapreduce的程式如果計算的資料量很小則不需要使用集群計算,因為啟動集群會有額外資源開銷計算的效率反而會慢,
1、首先進入hadoop1的終端,然后切換當前目錄
cd /program/hadoop-3.3.0/bin
2、使用以下命令查看hadoop官方案例程式的主要功能,如下圖:
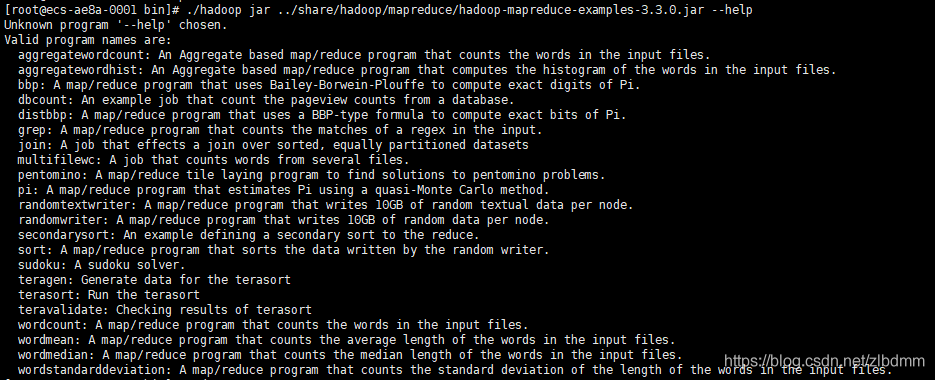
可以看到一個wordcount,這個功能是統計一組檔案中每個單詞出現的次數,本文我們就用這個功能做測驗,
3、通過以下命令執行mapreduce程式實作對hadoop組態檔中的單詞進行統計的功能,并把結果放到output目錄下,如下:
./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount file:///program/hadoop-3.3.0/etc/hadoop/* output
執行完畢之后可以通過下圖看出實作了對file:///program/hadoop-3.3.0/etc/hadoop/目錄下所有檔案的所有單詞的次數統計,
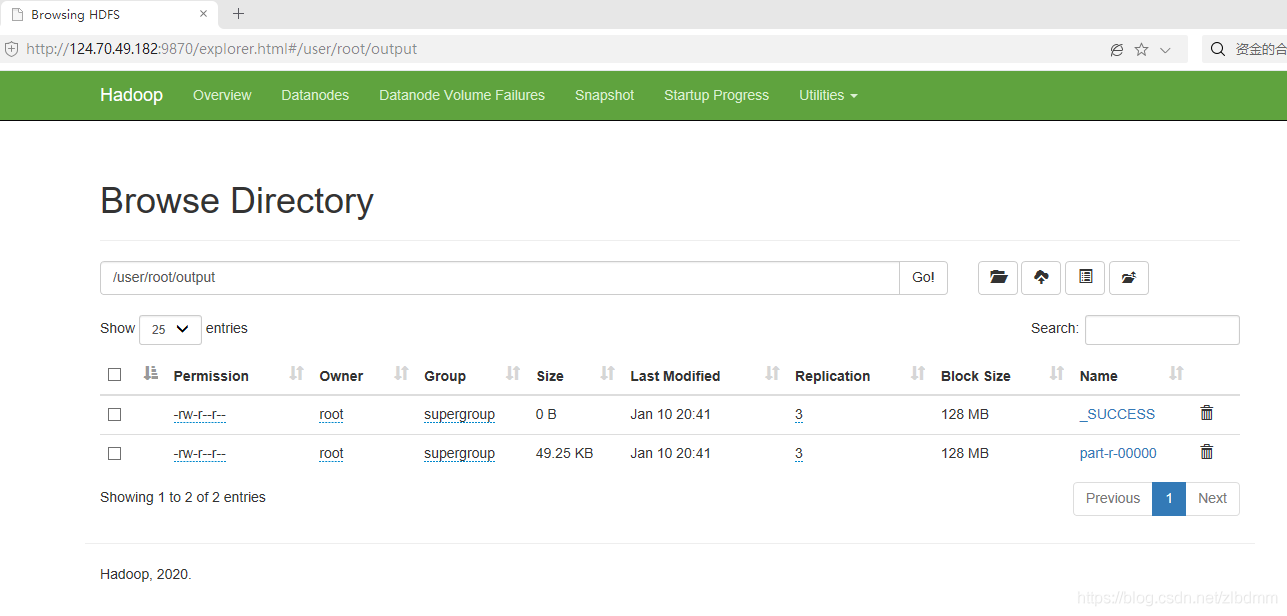
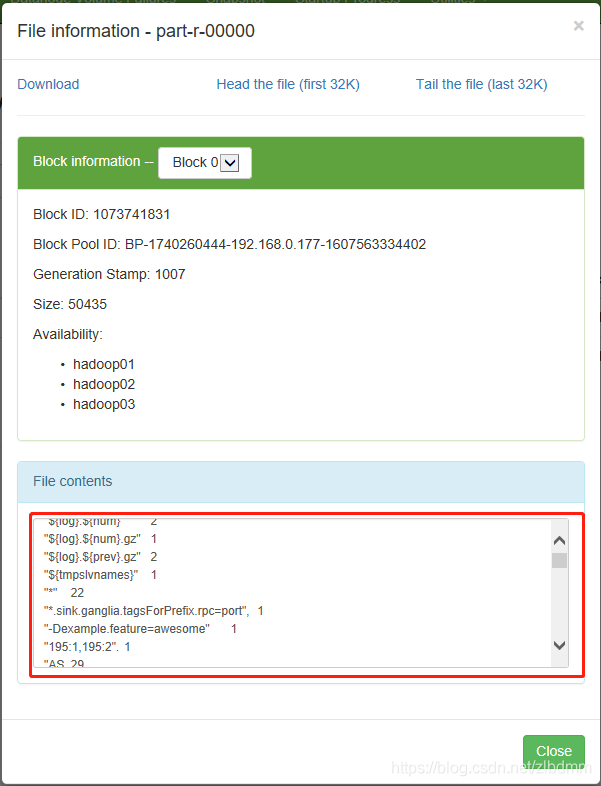
4、如果重新執行上面的命令計算,則需要修改輸出目錄,如果不修改會出現目錄已存在的例外,如下:
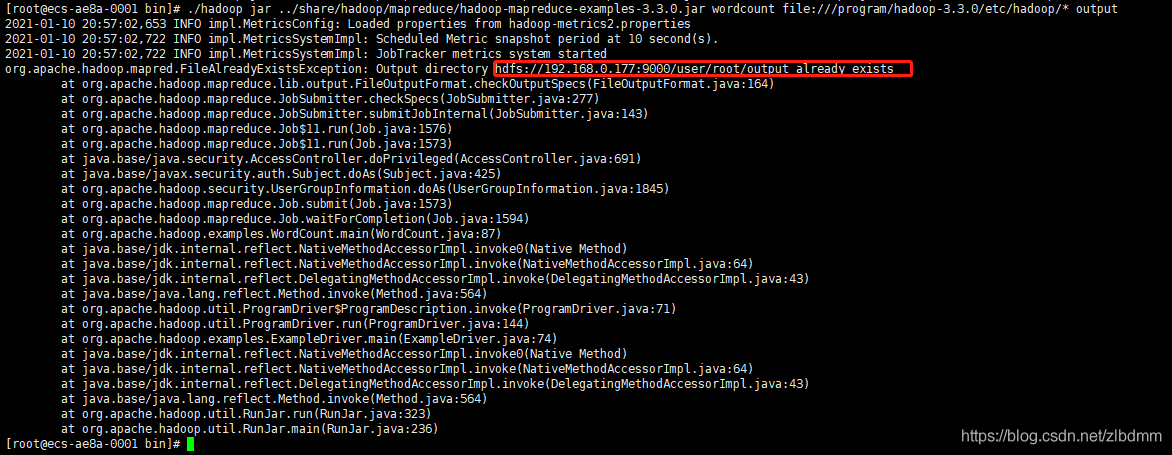
5、可以先在hadoop的圖形界面中洗掉/user目錄,如果出現提示權限不夠了需要修改權限,修改hadoop檔案系統的目錄權限的方式如下:
./hadoop fs -chmod -R 777 /
或者
./hdfs dfs -chmod -R 777 /
3、配置Yarn集群
如果計算的資料量很大,則適合使用集群的進行計算,這通常是計算的時間遠遠大于集群初始化及其他資源分配與管理的時間,要想啟用yarn集群,則需要按以下步驟進行配置,
1、先進入hadoop01的終端,切換當前目錄如下
cd /program/hadoop-3.3.0/bin
2、通過vim命令編輯…/etc/hadoop/mapred-site.xml,開啟yarn集群計算,內容如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<!-- 默認是local 表示不配置走本地多執行緒計算,yarn表示開啟集群計算 -->
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/program/hadoop-3.3.0</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/program/hadoop-3.3.0</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/program/hadoop-3.3.0</value>
</property>
</configuration>
3、通過vim命令編輯…/etc/hadoop/yarn-site.xml,配置resourcemanager,內容如下:
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
以上資訊表示使用hadoop01作為yarn的resourcemanager,
4、通過scp命令把…/etc/hadoop/yarn-site.xml復制到hadoop02和hadoop03節點上,如下圖:

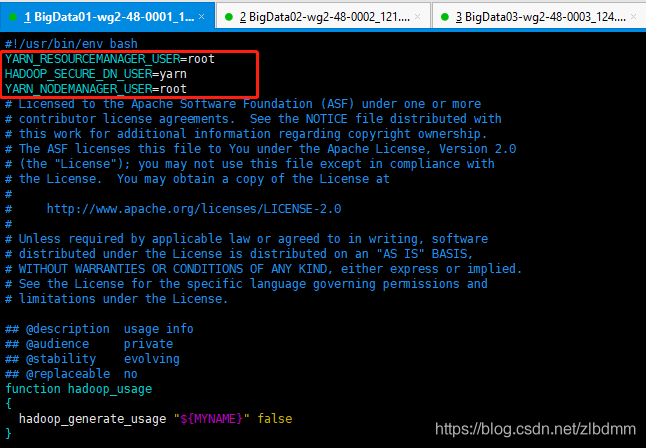
5、在啟動yarn集群之前,先通過vim命令編輯…/sbin/start-yarn.sh和…/sbin/stop-yarn.sh,在檔案頂部添加以下內容:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
不然在啟動的時候會報以下錯誤:
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
修改方法如下圖:
6、通過…/sbin/start-yarn.sh啟動yarn集群,并通過jps查看運行行程,如下圖:
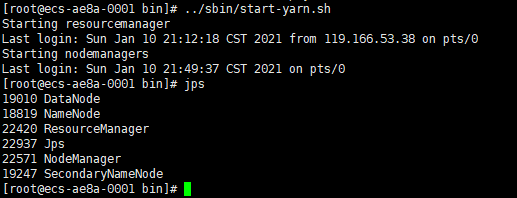
hadoop2
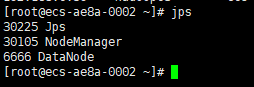
hadoop3
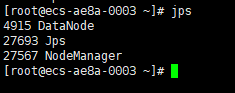
7、使用yarn圖形界面查看集群
可以通過http://hadoop01:8088進入yarn集群的圖形管理界面,如下圖:
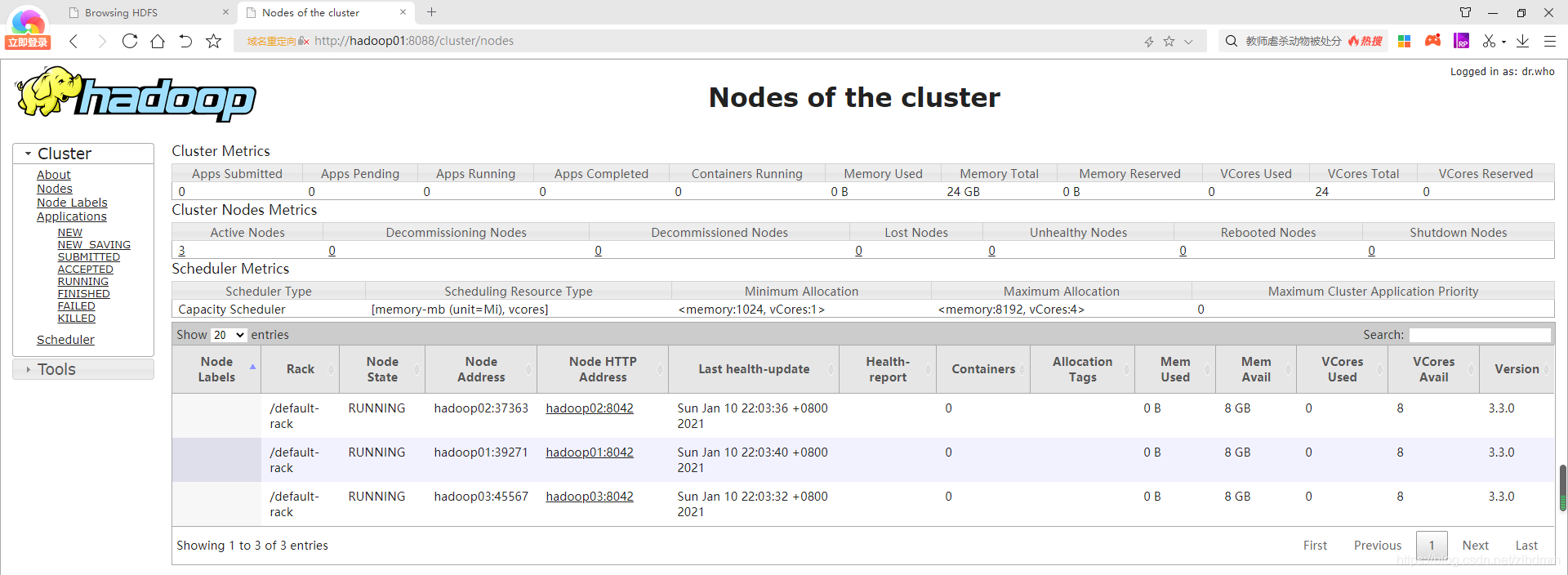
上圖可以看出yarn的集群共24GB記憶體,24核,
4、使用hadoop Yarn集群運行mapreduce程式
1、使用yarn集群執行mapreduce統計組態檔中的各單詞數量,如下:
[root@ecs-ae8a-0001 bin]# ./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount file:///program/hadoop-3.3.0/etc/hadoop/* output2
執行程序輸出如下
2021-01-11 10:21:37,218 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at hadoop01/192.168.0.177:8032
2021-01-11 10:21:37,473 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1610330660573_0002
2021-01-11 10:21:37,650 INFO input.FileInputFormat: Total input files to process : 32
2021-01-11 10:21:37,710 INFO mapreduce.JobSubmitter: number of splits:32
2021-01-11 10:21:37,868 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1610330660573_0002
2021-01-11 10:21:37,868 INFO mapreduce.JobSubmitter: Executing with tokens: []
2021-01-11 10:21:37,987 INFO conf.Configuration: resource-types.xml not found
2021-01-11 10:21:37,987 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2021-01-11 10:21:38,033 INFO impl.YarnClientImpl: Submitted application application_1610330660573_0002
2021-01-11 10:21:38,055 INFO mapreduce.Job: The url to track the job: http://hadoop01:8088/proxy/application_1610330660573_0002/
2021-01-11 10:21:38,055 INFO mapreduce.Job: Running job: job_1610330660573_0002
2021-01-11 10:21:42,158 INFO mapreduce.Job: Job job_1610330660573_0002 running in uber mode : false
2021-01-11 10:21:42,159 INFO mapreduce.Job: map 0% reduce 0%
2021-01-11 10:21:47,225 INFO mapreduce.Job: map 3% reduce 0%
2021-01-11 10:21:48,244 INFO mapreduce.Job: map 6% reduce 0%
2021-01-11 10:21:49,255 INFO mapreduce.Job: map 9% reduce 0%
2021-01-11 10:21:50,260 INFO mapreduce.Job: map 16% reduce 0%
2021-01-11 10:21:51,278 INFO mapreduce.Job: map 19% reduce 0%
2021-01-11 10:21:52,286 INFO mapreduce.Job: map 22% reduce 0%
2021-01-11 10:21:53,305 INFO mapreduce.Job: map 25% reduce 0%
2021-01-11 10:21:54,333 INFO mapreduce.Job: map 28% reduce 0%
2021-01-11 10:21:55,345 INFO mapreduce.Job: map 34% reduce 0%
2021-01-11 10:21:56,350 INFO mapreduce.Job: map 38% reduce 0%
2021-01-11 10:21:57,354 INFO mapreduce.Job: map 41% reduce 0%
2021-01-11 10:21:58,359 INFO mapreduce.Job: map 44% reduce 0%
2021-01-11 10:21:59,364 INFO mapreduce.Job: map 47% reduce 0%
2021-01-11 10:22:00,369 INFO mapreduce.Job: map 50% reduce 0%
2021-01-11 10:22:01,379 INFO mapreduce.Job: map 53% reduce 0%
2021-01-11 10:22:02,405 INFO mapreduce.Job: map 59% reduce 0%
2021-01-11 10:22:03,448 INFO mapreduce.Job: map 63% reduce 0%
2021-01-11 10:22:04,473 INFO mapreduce.Job: map 63% reduce 20%
2021-01-11 10:22:05,487 INFO mapreduce.Job: map 69% reduce 20%
2021-01-11 10:22:06,493 INFO mapreduce.Job: map 72% reduce 20%
2021-01-11 10:22:07,504 INFO mapreduce.Job: map 78% reduce 20%
2021-01-11 10:22:08,511 INFO mapreduce.Job: map 81% reduce 20%
2021-01-11 10:22:09,515 INFO mapreduce.Job: map 84% reduce 20%
2021-01-11 10:22:10,523 INFO mapreduce.Job: map 88% reduce 27%
2021-01-11 10:22:11,527 INFO mapreduce.Job: map 94% reduce 27%
2021-01-11 10:22:12,530 INFO mapreduce.Job: map 100% reduce 27%
2021-01-11 10:22:13,534 INFO mapreduce.Job: map 100% reduce 100%
2021-01-11 10:22:13,539 INFO mapreduce.Job: Job job_1610330660573_0002 completed successfully
2021-01-11 10:22:13,596 INFO mapreduce.Job: Counters: 55
File System Counters
FILE: Number of bytes read=214309
FILE: Number of bytes written=8925679
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=3860
HDFS: Number of bytes written=50478
HDFS: Number of read operations=69
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Killed map tasks=1
Launched map tasks=32
Launched reduce tasks=1
Rack-local map tasks=32
Total time spent by all maps in occupied slots (ms)=59346
Total time spent by all reduces in occupied slots (ms)=22721
Total time spent by all map tasks (ms)=59346
Total time spent by all reduce tasks (ms)=22721
Total vcore-milliseconds taken by all map tasks=59346
Total vcore-milliseconds taken by all reduce tasks=22721
Total megabyte-milliseconds taken by all map tasks=60770304
Total megabyte-milliseconds taken by all reduce tasks=23266304
Map-Reduce Framework
Map input records=2931
Map output records=12842
Map output bytes=158516
Map output materialized bytes=103077
Input split bytes=3860
Combine input records=12842
Combine output records=5739
Reduce input groups=2504
Reduce shuffle bytes=103077
Reduce input records=5739
Reduce output records=2504
Spilled Records=11478
Shuffled Maps =32
Failed Shuffles=0
Merged Map outputs=32
GC time elapsed (ms)=623
CPU time spent (ms)=13090
Physical memory (bytes) snapshot=8035414016
Virtual memory (bytes) snapshot=97197834240
Total committed heap usage (bytes)=6829375488
Peak Map Physical memory (bytes)=252547072
Peak Map Virtual memory (bytes)=2952425472
Peak Reduce Physical memory (bytes)=176435200
Peak Reduce Virtual memory (bytes)=2949914624
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=111418
File Output Format Counters
Bytes Written=50478
[root@ecs-ae8a-0001 bin]#
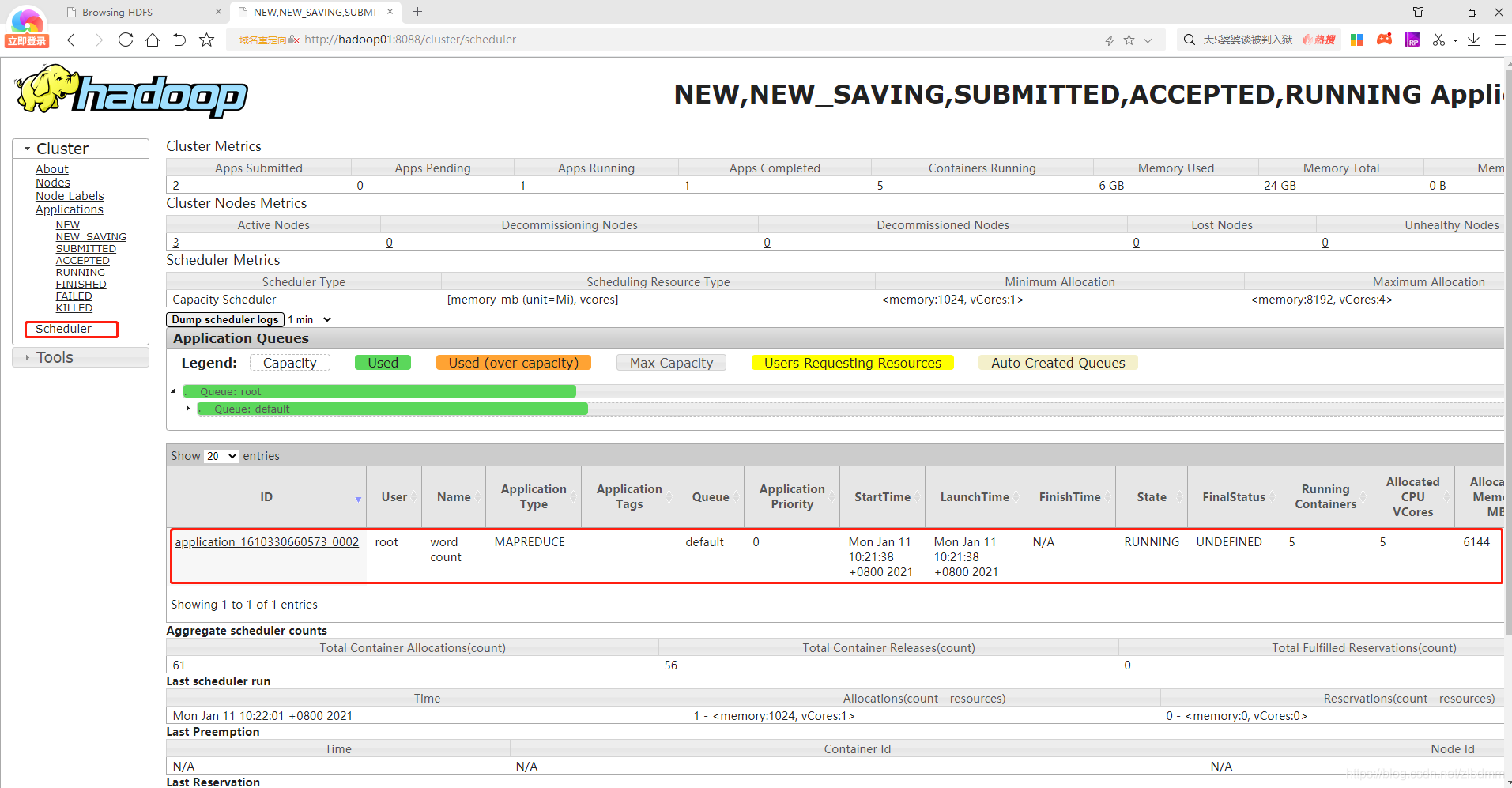
2、在執行的程序中可以在yarn的圖形界面中查看任務的執行進度和資訊,如下圖:
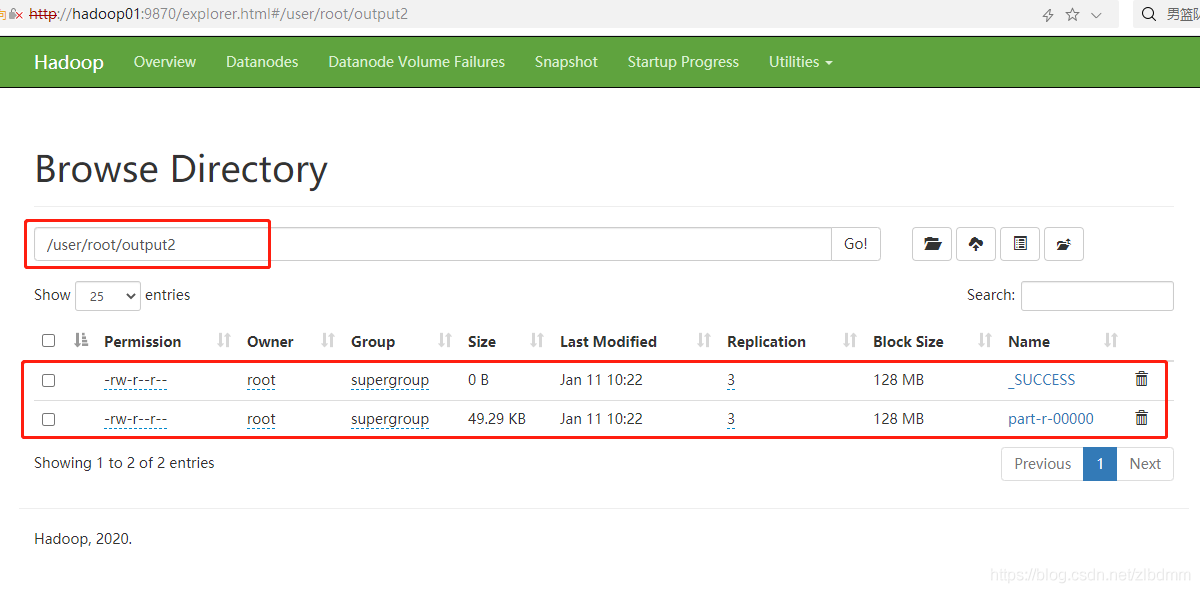
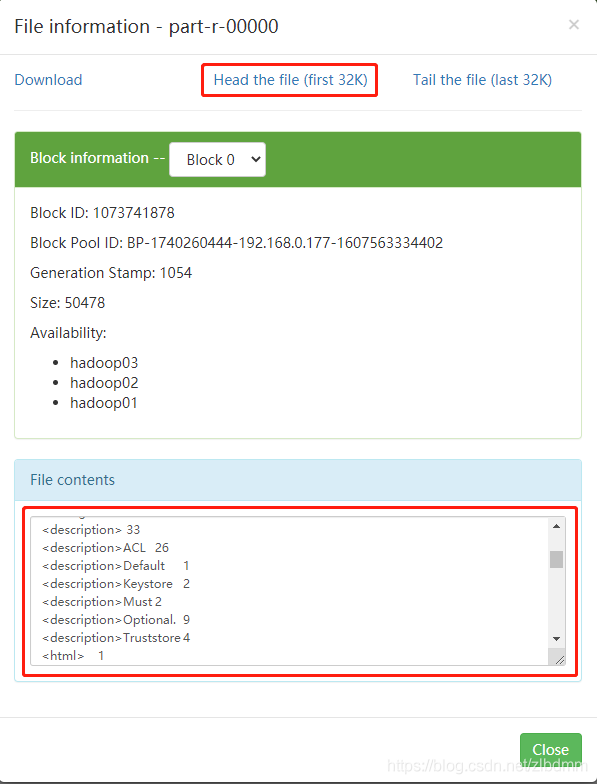
3、在hadoop的檔案系統中看到保存的結果如下圖:
5、下載并安裝spark
1、首先進入apache官網,地址:http://www.apache.org,如下圖:

2、點擊中間的Projects鏈接,能看到子選單,如下圖:

3、選擇上圖中的Projects->Project List選單項進入專案串列頁面,如下圖:
4、在上圖中找到S開頭的專案,選中Spark,則進入Spark主頁面,如下圖:
5、點擊頂部導航欄的Download鏈接,或者右側的Download Spark鏈接,進入下載頁面,如下圖:
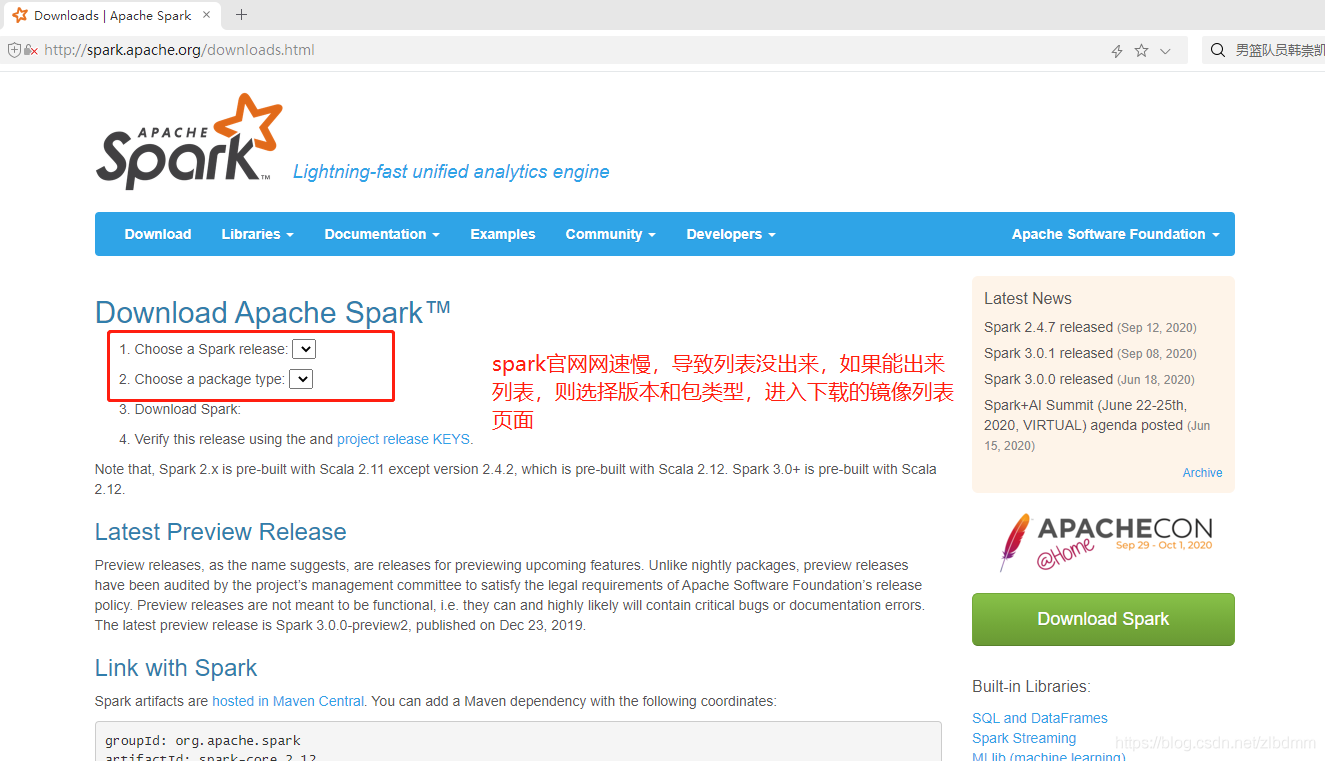
6、在鏡像串列頁面中,復制一個鏡像地址,這里的鏡像地址如下:
https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.0.1/spark-3.0.1-bin-hadoop3.2.tgz
7、進入hadoop01終端,并切換當前目錄為/opt/soft
cd /opt/soft
8、使用wget命令從鏡像地址下載spark到hadoop01節點,如下:
wget https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.0.1/spark-3.0.1-bin-hadoop3.2.tgz
下載程序如下圖:

9、解壓縮spark-3.0.1-bin-hadoop3.2.tgz
tar -xzvf spark-3.0.1-bin-hadoop3.2.tgz
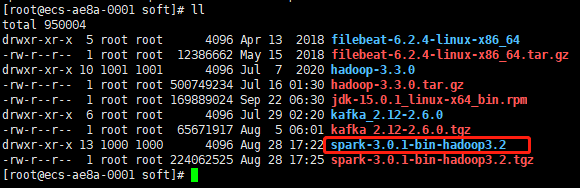
10、解壓后可以看到在/opt/soft目錄下多了spark-3.0.1-bin-hadoop3.2的目錄,如下圖:
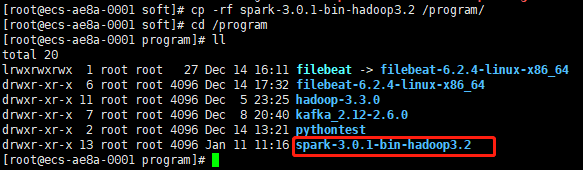
11、把spark-3.0.1-bin-hadoop3.2目錄復制到/program目錄下(代表安裝目錄)
cp -rf spark-3.0.1-bin-hadoop3.2 /program/
然后切換當前目錄為/program,并查看目錄下內容,則看到了spark-3.0.1-bin-hadoop3.2,執行程序如下圖:
5、配置spark使用本地單節點計算圓周率PI
1、在hadoop01終端中切換當前目錄為/program/spark-3.0.1-bin-hadoop3.2/bin
cd /program/spark-3.0.1-bin-hadoop3.2/bin
2、通過./spark-submit命令本次執行jar程式計算圓周率,命令如下:
./spark-submit --master local --deploy-mode client --executor-memory 2G --executor-cores 2 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.12-3.0.1.jar 1000
執行結果如下:
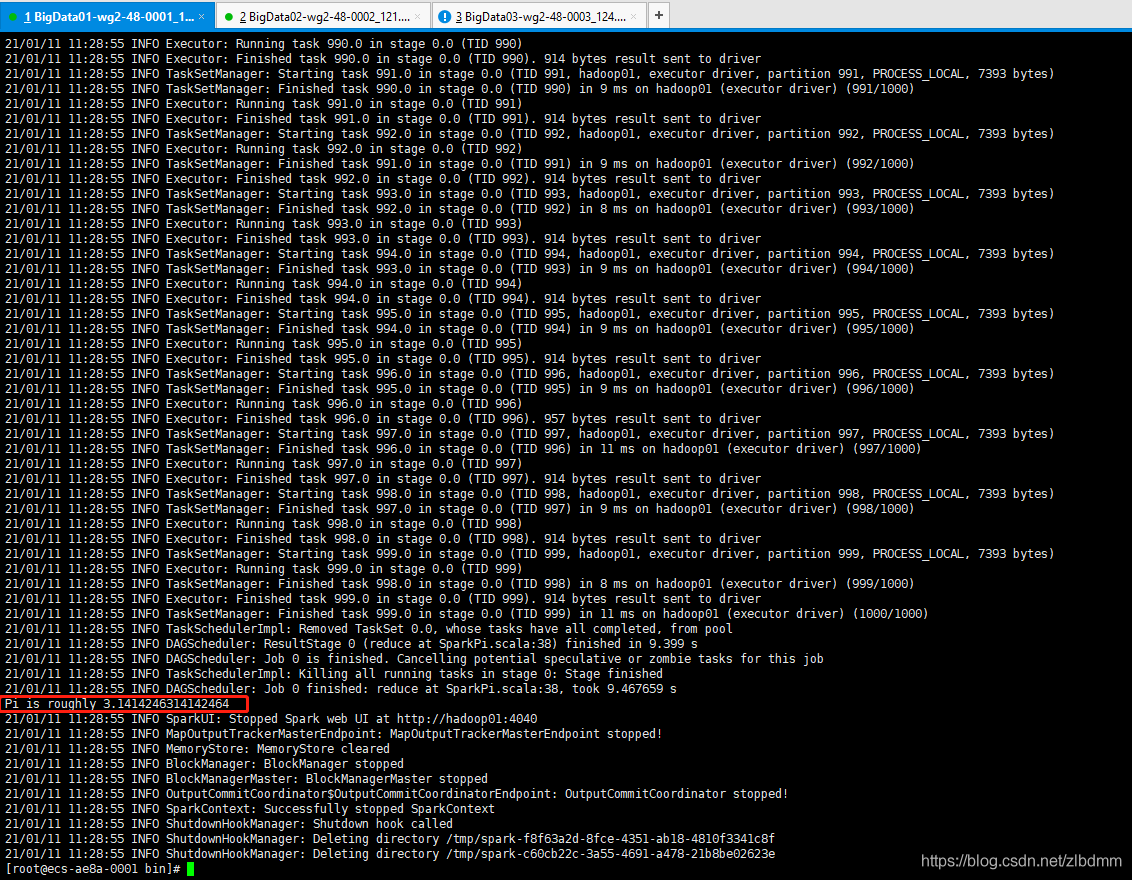
可以通過增加最后一個引數1000值更大的值得到更高精度的PI值,
6、配置spark使用集群節點計算圓周率PI
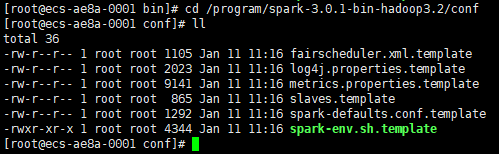
1、切換當前目錄為/program/spark-3.0.1-bin-hadoop3.2/conf
cd /program/spark-3.0.1-bin-hadoop3.2/conf
執行如下圖:
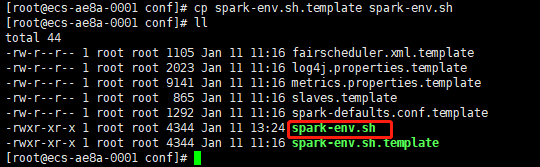
2、通過spark-env.sh.template生成spark-env.sh,如下:
cp spark-env.sh.template spark-env.sh
執行如下圖:
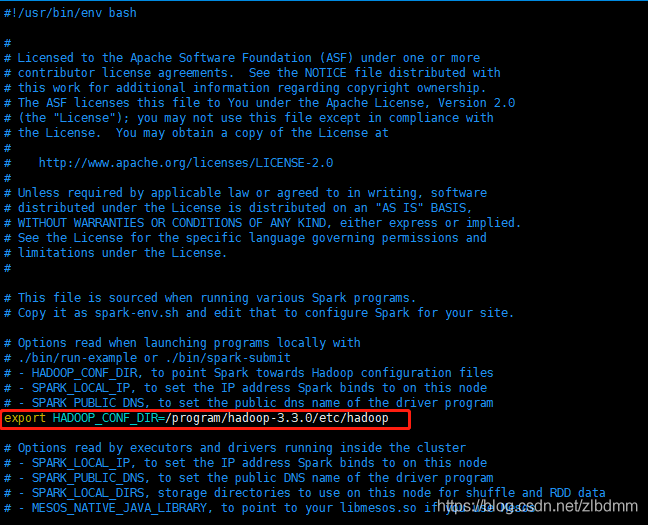
3、通過vim命令修改spark-env.sh,增加HADOOP_CONF_DIR的配置,就是在spark中指定hadoop組態檔的位置,內容如下:
export HADOOP_CONF_DIR=/program/hadoop-3.3.0/etc/hadoop
具體如下圖:
4、保存spark-env.sh后,切換當前目錄為/program/spark-3.0.1-bin-hadoop3.2/bin
cd /program/spark-3.0.1-bin-hadoop3.2/bin
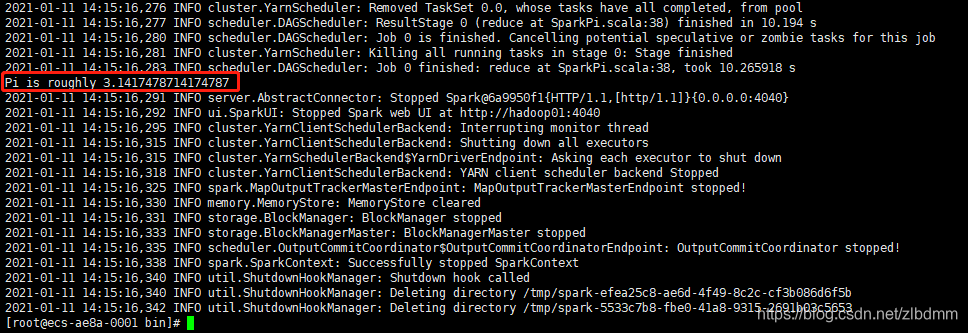
5、通過./spark-submit命令呼叫yarn集群(–master后面的引數由local改為yarn)計算圓周率PI的值
./spark-submit --master yarn --deploy-mode client --executor-memory 2G --executor-cores 2 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.12-3.0.1.jar 1000
執行結果如下圖:
6、重新執行上面的命令,可以試著調整后面的引數1000為10000看看PI的精度是否提高,如下:
./spark-submit --master yarn --deploy-mode client --executor-memory 2G --executor-cores 2 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.12-3.0.1.jar 10000
執行結果如下圖:
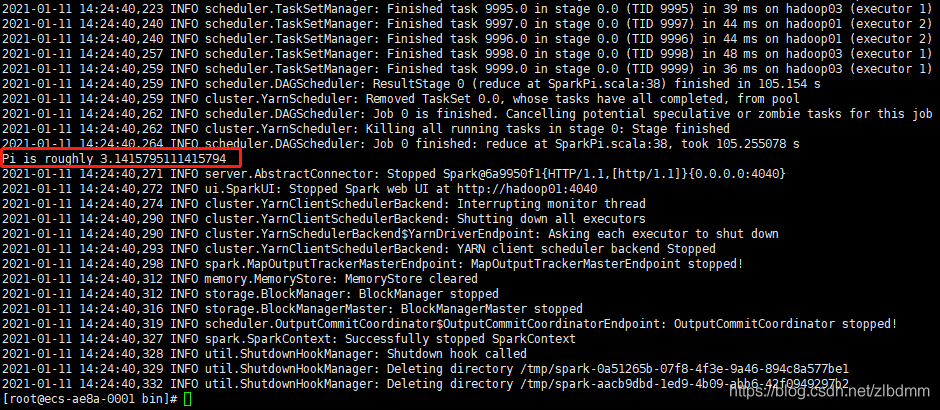
可以看出執行的結果PI的精度提高了,
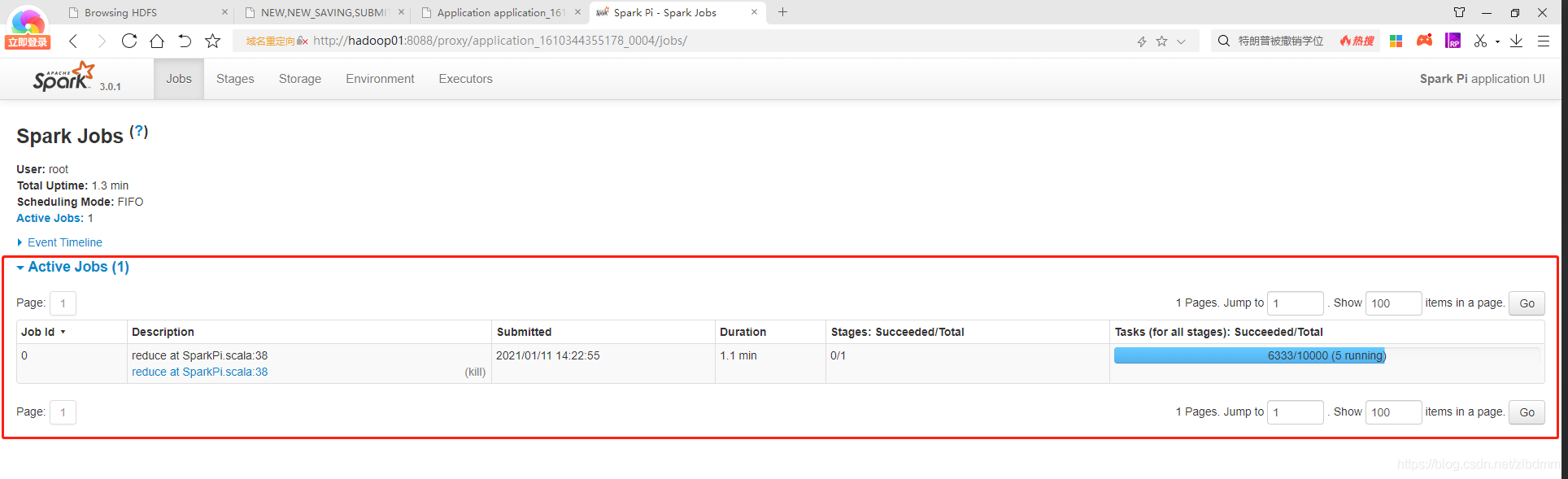
7、在執行程序中可以通過yarn的圖形界面和spark的圖形界面查看執行進度和相關任務資訊,如下圖:
yarn圖形界面如下:
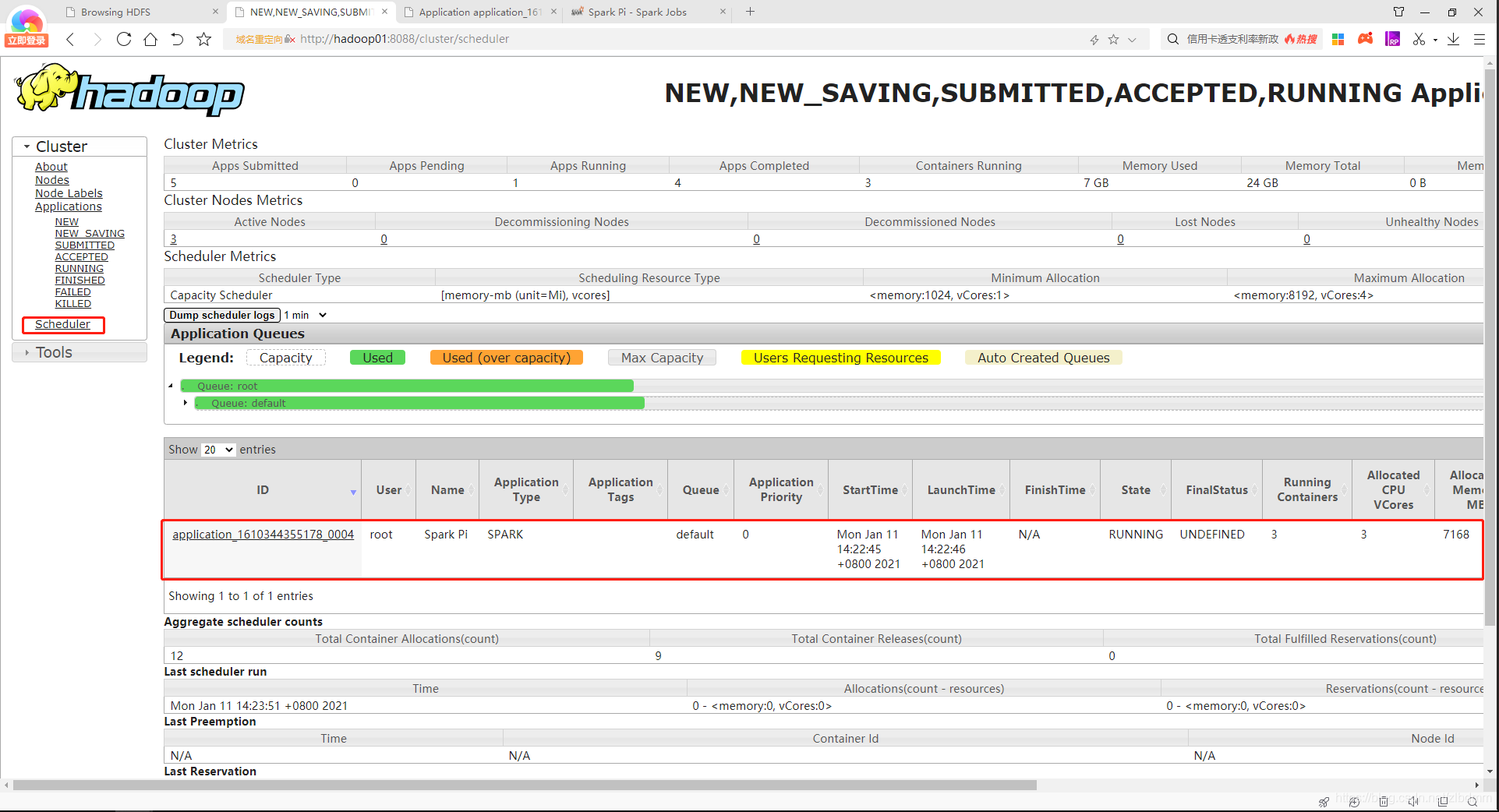
spark圖形界面如下:
7、總結
至此一個簡單的基于Yarn集群的Spark實時計算環境搭建完畢,希望對初學的朋友能有個參考,最后感謝一下csdn大資料的老師吧,畢竟有個人帶著學要快的多,如果覺得有幫助點個贊吧~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/247625.html
標籤:其他