1 要解決的問題
集群分配給多個用戶使用時,需要使用配額以限制用戶的資源使用,包括 CPU 核數、記憶體大小、GPU 卡數等,以防止資源被某些用戶耗盡,造成不公平的資源分配,
大多數情況下,集群原生的 ResourceQuota 機制可以很好地解決問題,但隨著集群規模擴大,以及任務型別的增多,我們對配額管理的規則需要進行調整:
ResourceQuota針對單集群設計,但實際上,開發/生產中經常使用 多集群 環境,- 集群大多數任務通過比如
deployment、mpijob等 高級資源物件 進行提交,我們希望在高級資源物件的 提交階段 就能對配額進行判斷,但ResourceQuota計算資源請求時以pod為粒度,從而無法滿足此需求,
基于以上問題,我們需要自行進行配額管理,而 Kubernetes 提供了動態準入的機制,允許我們撰寫自定義的插件,以實作請求的準入,我們的配額管理方案,就以此入手,
2 集群動態準入原理
進入 K8s 集群的請求,被 API server 接收后,會經過如下幾個順序執行的階段:
- 認證/鑒權
- 準入控制(變更)
- 格式驗證
- 準入控制(驗證)
- 持久化
請求在上述前四個階段都會被相應處理,并且依次被判斷是否允許通過,各個階段都通過后,才能夠被持久化,即存入到 etcd 資料庫中,從而變為一次成功的請求,其中,在 準入控制(變更) 階段,mutating admission webhook 會被呼叫,可以修改請求中的內容,而在 準入控制(驗證) 階段,validating admission webhook 會被呼叫,可以校驗請求內容是否符合某些要求,從而決定是否允許或拒絕該請求,而這些 webhook 支持擴展,可以被獨立地開發和部署到集群中,
雖然,在 準入控制(變更) 階段,webhook也可以檢查和拒絕請求,但其被呼叫的次序無法保證,無法限制其它 webhook 對請求的資源進行修改,因此,我們部署用于配額校驗的 validating admission webhook,配置于 準入控制(驗證) 階段呼叫,進行請求資源的檢查,就可以實作資源配額管理的目的,
3 方案
3.1 如何在集群中部署校驗服務
在 K8s 集群中使用自定義的 validating admission webhook 需要部署:
ValidatingWebhookConfiguration配置(需要集群啟用 ValidatingAdmissionWebhook) ,用于定義要對何種資源物件(pod,deployment,mpijob等)進行校驗,并提供用于實際處理校驗的服務回呼地址,推薦使用在集群內配置Service的方式來提供校驗服務的地址,- 實際處理校驗的服務,通過在
ValidatingWebhookConfiguration配置的地址可訪問即可,
單集群環境中,將校驗服務以 deployment 的方式在集群中部署,多集群環境中,可以選擇:
- 使用 virtual kubelet,cluster federation 等方案將多集群合并為單集群,從而退化為采用單集群方案部署,
- 將校驗服務以
deloyment的方式部署于一個或多個集群中,但要注意保證服務到各個集群網路連通,
需要注意的是,不論是單集群還是多集群的環境中,處理校驗的服務都需要進行資源監控,這一般由單點實作,因此都需要 進行選主,
3.2 如何實作校驗服務
3.2.1 校驗服務架構設計
3.2.1.1 基本組件構成
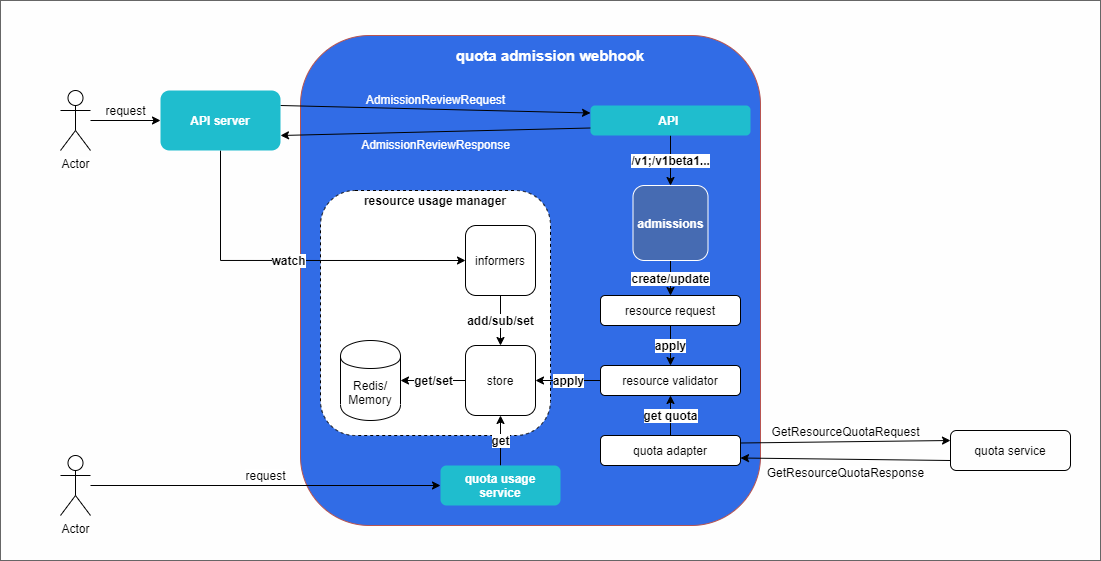
- API server:集群請求入口,呼叫
validating admission webhook以驗證請求 - API:準入服務介面,使用集群約定的 AdmissionReview 資料結構作為請求和回傳
- Quota usage service:請求資源使用量介面
- Admissions:準入服務實作,包括
deployment和mpijob等不同資源型別準入 - Resource validator:對資源請求進行配額校驗
- Quota adapter:對接外部配額服務供 validator 查詢
- Resource usage manager:資源使用管理器,維護資源使用情況,實作配額判斷
- Informers:通過 K8s 提供的 watch 機制監控集群中資源,包括
deployment和mpijob等,以維護當前資源使用 - Store:存放資源使用資料,可以對接服務本地記憶體實作,或者對接 Redis 服務實作
3.2.1.2 資源配額判斷的基本流程
以用戶創建 deployment 資源為例:
- 用戶創建
deployment資源,定義中需要包含指定了應用組資訊的annotation,比如ti.cloud.tencent.com/group-id: 1,表示申請使用應用組1中的資源(如果沒有帶有應用組資訊,則根據具體場景,直接拒絕,或者提交到默認的應用組,比如應用組0等), - 請求由 API server 收取,由于在集群中正確配置了
ValidatingWebhookConfiguration,因此在準入控制的驗證階段,會請求集群中部署的validating admission webhook的 API,使用 K8s 規定的結構體AdmissionReviewRequest作為請求,期待AdmissionReviewResponse結構體作為回傳, - 配額校驗服務收到請求后,會進入負責處理
deployment資源的 admission 的邏輯,根據改請求的動作是 CREATE 或 UPDATE 來計算出此次請求需要新申請或者釋放的資源, - 從
deployment的spec.template.spec.containers[*].resources.requests欄位中提取要申請的資源,比如為cpu: 2和memory: 1Gi,以 apply 表示, - Resource validator 查找 quota adapter 獲取應用組
1的配額資訊,比如cpu: 10和memory: 20Gi,以 quota 表示,連同上述獲取的 apply,向 resource usage manager 申請資源, - Resource usage manager 一直在通過 informer 監控獲取
deployment的資源使用情況,并維護在 store 中,Store 可以使用本地記憶體,從而無外部依賴,或者使用Redis作為存盤介質,方便服務水平擴展, - Resource usage manager 收到 resource validator 的請求時,可以通過 store 查到應用組
1當前已經占用的資源情況,比如cpu: 8和memory: 16Gi,以 usage 表示,檢查發現 apply + usage <= quota 則認為沒有超過配額,請求通過,并最侄訓傳給 API server,
以上就是實作資源配額檢查的基本流程,有一些細節值得補充說明:
- 校驗服務的介面 API 必須采用 https 暴露服務,
- 針對不用的資源型別,比如
deployment、mpijob等,都需要實作相應的 admission 以及 informer , - 每個資源型別可能有不同的版本,比如
deployment有apps/v1、apps/v1beta1等,需要根據集群的實際情況兼容處理, - 收到 UPDATE 請求時,需要根據資源型別中
pod的欄位是否變化,來判斷是否需要重建當前已有的pod實體,以正確計算資源申請的數目, - 除了 K8s 自帶的資源型別,比如
cpu等,如果還需要自定義的資源型別配額控制,比如 GPU 型別等,需要在資源請求約定好相應的annotations,比如ti.cloud.tencent.com/gpu-type: V100 - 在 resource usage manager 進行使用量、申請量和配額的判斷程序中,可能會出現 資源競爭、配額通過校驗但實際 資源創建失敗 等問題,接下來我們會對這兩個問題進行解釋,
3.2.2 關于資源申請競爭
由于并發資源請求的存在:
- usage 需要能夠被在資源請求后即時更新
- usage 的更新需要進行并發控制
在上述步驟 7 中,Resource usage manager 校驗配額時,需要查詢應用組當前的資源占用情況,即應用組的 usage 值,此 usage 值由 informers 負責更新和維護,但由于從資源請求被 validating admission webhook 通過,到 informer 能夠觀察到,存在時間差,這個程序中,可能仍有資源請求,那么 usage 值就是不準確的了,因此,usage 需要能夠被在資源請求后即時更新,
并且對 usage 的更新需要進行并發控制,舉個例子:
- 應用組
2的 quota 為cpu: 10,usage 為cpu: 8 - 進入兩個請求
deployment1和deployment2申請使用應用組2,它們的 apply 同為cpu: 2 - 需要首先判斷
deployment1, 計算 apply + usage =cpu: 10,未超過 quota 值,因此deployment1的請求允許通過, - usage 被更新為
cpu: 10 - 再去判斷
deployment2,由于 usage 被更新為cpu: 10,則算出 apply + usage =cpu: 12,超過了 quota 的值,因此不允許通過該請求,
上述程序中,容易發現 usage 是關鍵的 共享 變數,需要順序查詢和更新,若 deployment1 和 deployment2 不加控制地同時使用 usage 為 cpu: 8,就會導致 deployment1 和 deployment2 請求都被通過,從而實際超出了配額限制,這樣,用戶可能占用 超過 配額規定的資源,
可行的解決辦法:
- 資源申請進入佇列,由單點的服務依次消費和處理,
- 將共享的變數 usage 所處的臨界區上鎖,在鎖內查詢和更新 usage 的值,
3.2.3 關于資源創建失敗
由于資源競爭的問題,我們要求 usage 需要能夠被在資源請求后即時更新,但這也帶來新的問題,在 4. 準入控制(驗證) 階段之后,請求的資源物件會進入 5. 持久化 階段,這個程序中也可能出現例外(比如其他的 webhook 又拒絕了該請求,或者集群斷電,etcd 故障等)導致任務沒有實際提交成功到集群資料庫,在這種情況下,我們在 驗證 階段,已經增加了 usage 的值,就把沒有實際占用配額的任務算作占用了配額,這樣,用戶可能占用 不足 配額規定的資源,
為了解決這個問題,后臺服務會定時全域更新每個應用組的 usage 值,這樣,如果出現了 驗證 階段增加了 usage 值,但任務實際提交到資料庫失敗的情況,在全域更新的時候,usage 值最侄訓重新更新為那個時刻應用組在集群內資源使用的準確值,
但在極少數情況下,全域更新會在這種時刻發生:某最侄訓成功存入 etcd 持久化 的資源物件創建請求,已經通過
webhook驗證,但尚未完成 持久化 的時刻,這種時刻的存在,導致全域更新依然會帶來用戶占用 超過 配額的問題,
比如,在之前的例子中,deployment1更新了 usage 值之后,恰巧發生了全域更新,此時deployment1的資訊恰好尚未存入 etcd,所以全域更新會把 usage 重新更新為舊值,這樣會導致dployment2也能被通過,從而超過了配額限制,
但通常,從 驗證 到 持久化 的時間很短,低頻 的全域更新情況下,此種情況 幾乎不會發生,后續,如果有進一步的需求,可以采用更復雜的方案來規避這個問題,
3.2.3 原生 ResourceQuota 的作業方式
K8s 集群中原生的配額管理 ResourceQuota 針對上述 資源申請競爭 和 資源創建失敗 問題,采用了類似的解決方案:
即時更新解決申請競爭問題
檢查完配額后,即時更新資源用量,K8s 系統自帶的樂觀鎖保證并發的資源控制(詳見 K8s 原始碼中 checkQuotas 的實作),解決資源競爭問題,
checkQuotas 中最相關的原始碼解讀:
// now go through and try to issue updates. Things get a little weird here:
// 1. check to see if the quota changed. If not, skip.
// 2. if the quota changed and the update passes, be happy
// 3. if the quota changed and the update fails, add the original to a retry list
var updatedFailedQuotas []corev1.ResourceQuota
var lastErr error
for i := range quotas {
newQuota := quotas[i]
// if this quota didn't have its status changed, skip it
if quota.Equals(originalQuotas[i].Status.Used, newQuota.Status.Used) {
continue
}
if err := e.quotaAccessor.UpdateQuotaStatus(&newQuota); err != nil {
updatedFailedQuotas = append(updatedFailedQuotas, newQuota)
lastErr = err
}
}
這里 quotas 是經過校驗后的配額資訊,其中 newQuota.Status.Used 欄位則記錄了該配額的資源使用情況,如果針對該配額的資源請求通過了,運行到這段代碼時,Used 欄位中已經被加上了新申請資源的量,隨后,Equals 函式被呼叫,即如果 Used 欄位未變,說明沒有新的資源申請,否則,就會運行到 e.quotaAccessor.UpdateQuotaStatus,立刻去把 etcd 中的配額資訊按照 newQuota.Status.Used 來更新,
定時全域更新解決創建失敗問題
定時全域更新資源使用量(詳見 K8s 原始碼中 Run 的實作),解決可能的資源創建失敗問題 ,
Run 中最相關的原始碼解讀:
// the timer for how often we do a full recalculation across all quotas
go wait.Until(func() { rq.enqueueAll() }, rq.resyncPeriod(), stopCh)
這里 rq 為 ResourceQuota 物件對應 controller 的自參考,這個 Controller 運行 Run 回圈,持續地控制所有 ResourceQuota 物件,回圈中,不間斷定時呼叫 enqueueAll,即把所有的 ResourceQuota 壓入佇列中,修改其 Used 值,進行全域更新,
4 參考
- Controlling Access to the Kubernetes API
- Dynamic Admission Control
- A Guide to Kubernetes Admission Controllers
- 深入理解 Kubernetes Admission Webhook
- https://github.com/kubernetes/kubernetes/blob/v1.13.0/test/images/webhook/main.go
- Admission Webhooks: Configuration and Debugging Best Practices - Haowei Cai, Google
【騰訊云原生】云說新品、云研新術、云游新活、云賞資訊,掃碼關注同名公眾號,及時獲取更多干貨!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/247994.html
標籤:其他
上一篇:云游戲,打響5G第一戰