復習提綱:
1. 為什么要并行編程
(1)分布和并行計算的區別(重點)
答:并行:單機多核,問題并行編程;分布:多機網路連接,對外以整體提供服務
(2)并行和并發的區別(重點)
答:并發:支持同時存在;并行:支持同時執行,并行是并發的一個子集,
并發是指一個處理器同時處理多個任務,
并行是指多個處理器或者是多核的處理器同時處理多個不同的任務,
并發是邏輯上的同時發生,而并行是物理上的同時發生,
(3)行程、執行緒的區別
答:行程是作業系統的資源分配的基本單位,執行緒是處理器任務調度的基本單位,
(4)并發編程中的兩種觀點
答:訊息傳遞和分布式記憶體,
(5)并行計算的核心內容(重點)
答:并行計算的核心內容是指計算機能夠以任何順序來執行的獨立計算
(6)并行程式撰寫的步驟
答:
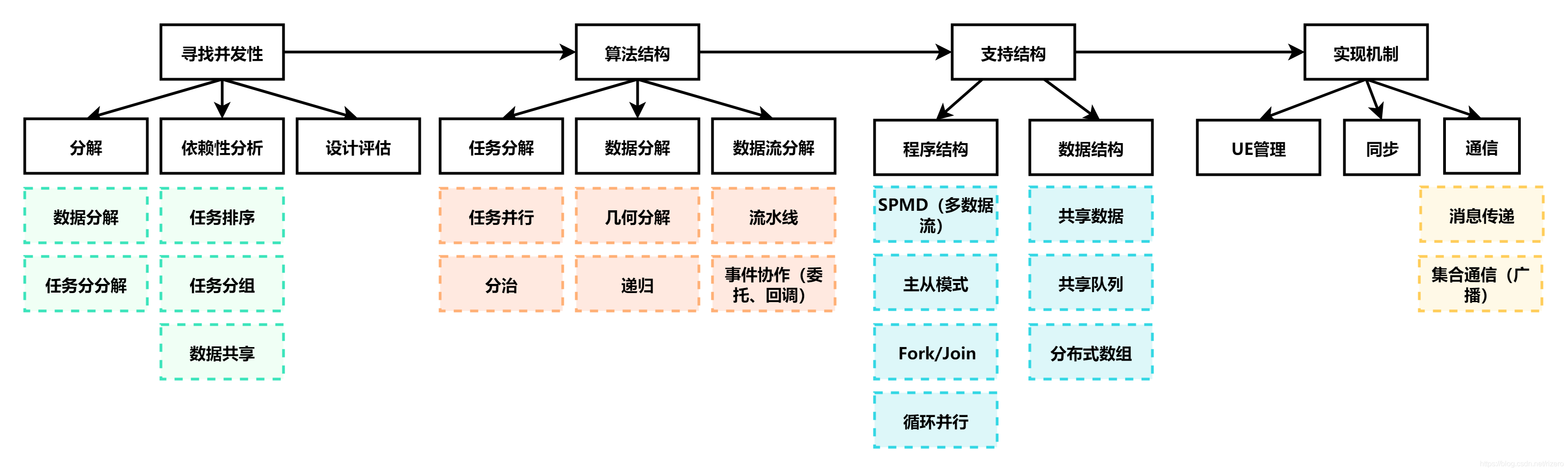
【1】尋找并發性
【2】設定演算法結構 → \rightarrow →支持結構 → \rightarrow →實作機制
任務并行和資料并行的觀點:
- 任務并行就是多個任務分割并且分配到多個核進行執行
- 資料并行就是對資料進行分割,然后將分割好的資料分配到多個核上執行,
(7)基于執行緒化方法學
答:分析,設計實作,測驗正確性,性能調優
2. 并行硬體和并行軟體
(1)基于 Flynn 分類法的劃分(重點)
答:指令核資料,單流,多流,
SISD:
(Uint改正:Unit)
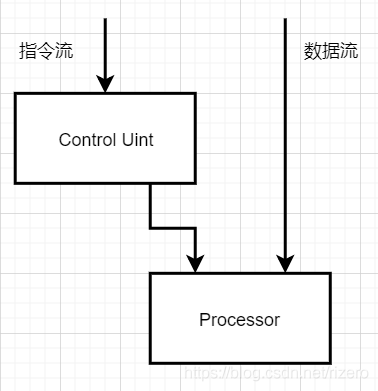
SIMD:
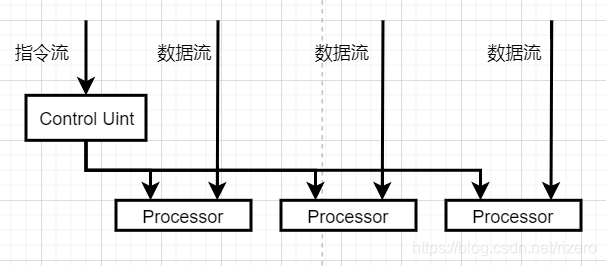
GPUs 都采用SIMD并行,
MIMD:
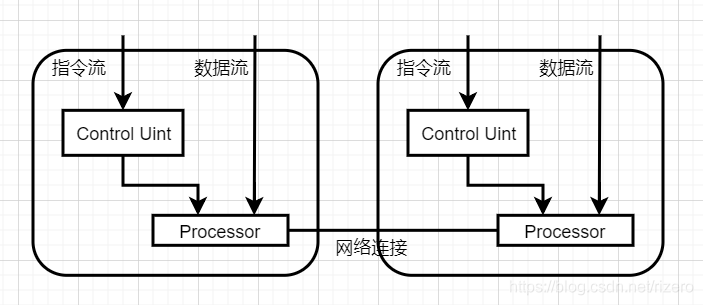
(2)MIMD 的進一步劃分(重點,分布內容和共享記憶體,要求能畫出圖并詳細說明)
答:共享記憶體:每個記憶體區域都能被每個處理器訪問的到,分布式記憶體是記憶體獨立,但是大家能通過網路訪問,
共享記憶體:
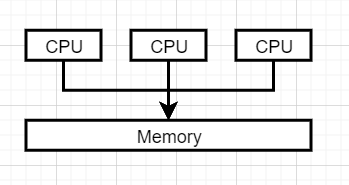
一組自治的處理器通過互聯網路與記憶體系統相連接,每個處理器能訪問每個記憶體區域,每個處理器都可以訪問每個存盤單元,處理器通過訪問共享的資料結構來隱式通信
分布式記憶體:
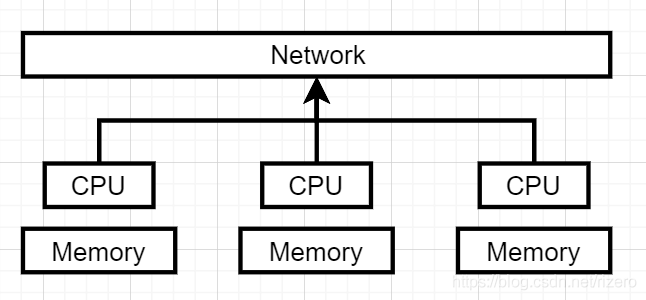
(3)并行計算的度量,加速比(重點)
答: T p a r a l l l e l = T s e r i a l / P T_{paralllel} = T_{serial} / P Tparalllel?=Tserial?/P, S = T s / T p S = T_s/T_p S=Ts?/Tp?
3. 尋找并發性設計空間
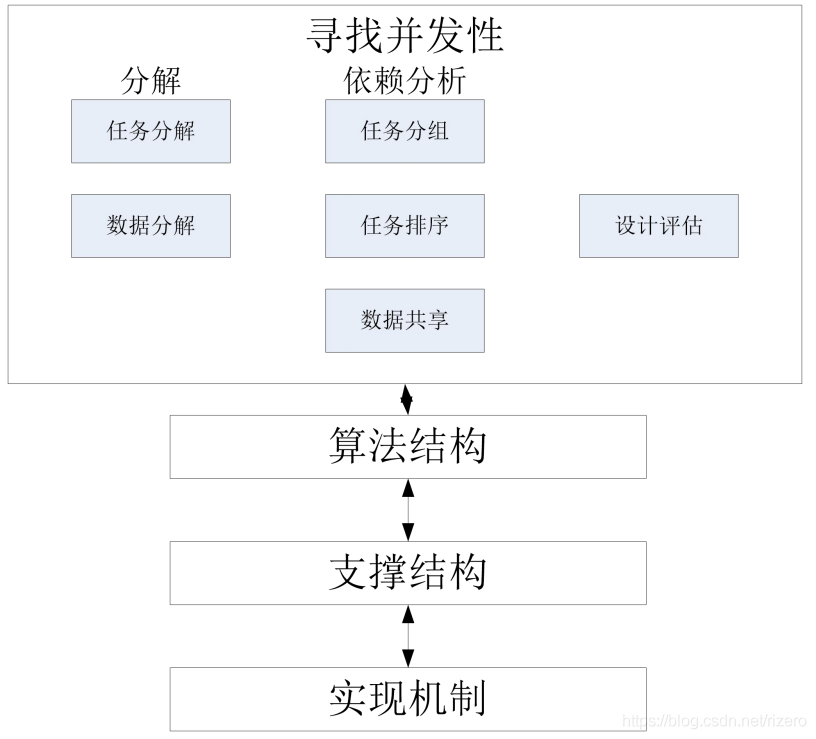
尋找并發性設計空間,如果從分解的角度去看問題的話:任務分解和資料分解,還有資料流分解,如果從依賴性分析的話:任務的分組,任務的排序,資料的共享,
(1)理解任務分解模式(重點,能舉出例子或者分析例子)
答:任務分解:計算被分解為一組獨立的任務,多個執行緒可以用任意順序執行這些任務,
例子:如果兩個園丁到達一個客戶家,一個修剪草坪,另一個鏟除雜草,修剪草坪和鏟除雜草是兩個被分開的功能,
(2)理解資料分解模式(重點,能舉出例子或者分析例子)
答:資料分解:應用程式需要處理一個大型資料集,并且可以對資料集中的每個元素進行獨立計算,
例子:如果園丁應用資料分解來分解他們的任務,他們兩個會同時修剪一半的草坪,然后兩個人分別鏟除一半的雜草
任務分解:識別出多個可以并發執行的任務;
資料分解:識別出每個任務所需要的區域資料
4. 演算法結構設計空間
淺談并行編程中的任務分解模式
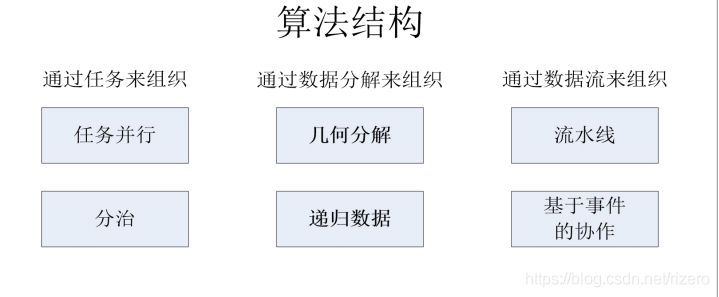
(1)理解任務并行模式(重點,能舉出例子或者分析例子)
答:把問題分解為一個能夠并發執行的任務集合,
一塊草坪,需要完成修剪和除雜草的任務,現在兩個園丁分配到不同的任務去完成,當然這個程序需要協調的,因為兩個人不可能說同時處理一塊地方的,
(2)了解分治策略
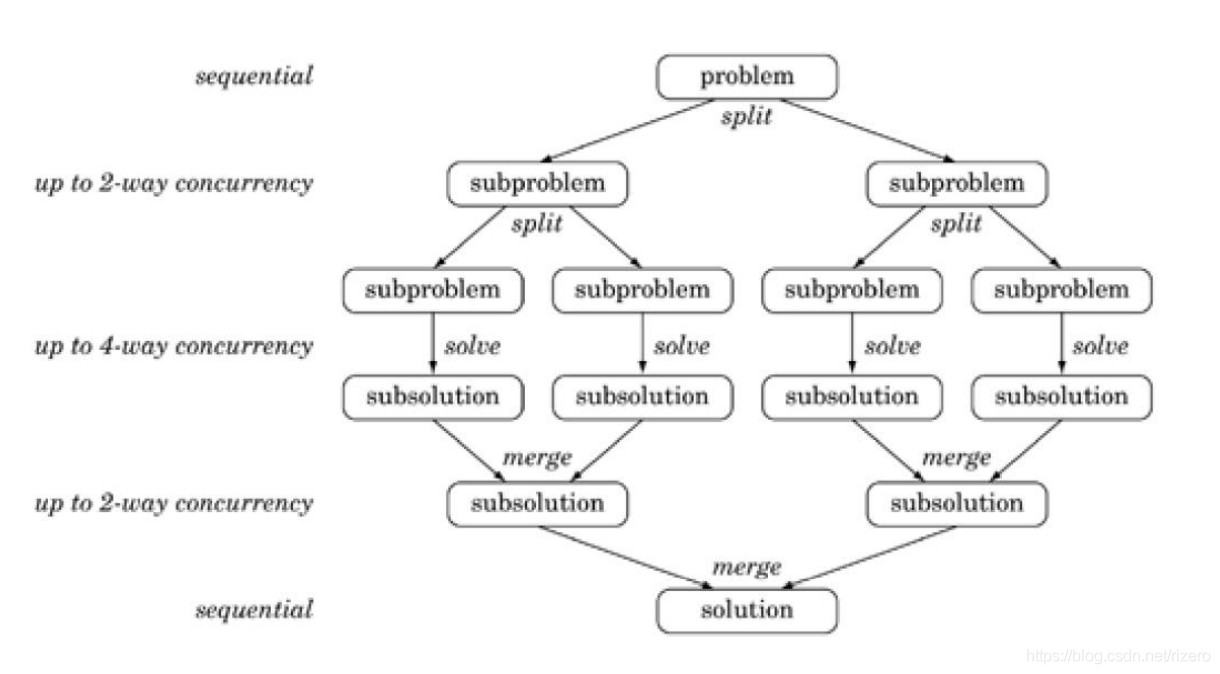
(3)了解幾何分解模式(重點,能舉出例子或者分析例子)
答:幾何分解模式基于正在解決問題的資料結構的并行化,在幾何分解中,每個執行緒負責操作資料塊
幾何分解實際上就是資料的并行化,我們的園丁分到這塊草坪的兩半,每人負責一半,然后都同時完成:除草和修剪的任務,
(4)了解流水線模式(重點,能舉出例子或者分析例子)
答:流水線模式的意思類似于一條工廠的產品裝配線,這種尋找并發的方式使計算被分割成一系列階段,每個執行緒在不同的階段同時作業,
生產者消費者的實作就是典型的流水線模式,一塊草坪,我們把需要完成的任務進行步驟的分解,比如:拿出除草劑,插電,推動,每一步都由不同的園丁來完成,工廠的流水線就是一個最好的理解例子,
(5)理解基于事件的協作模式
答:定義任務,表示事件流,強制執行事件的順序,避免死鎖,調度和處理器分配,事件的高效通信
當一個人完成了作業,就通知他人開始他的任務,這樣可以做到很好的協作,
5. 支持結構設計空間(重點)
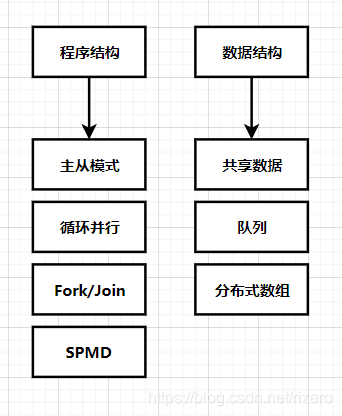
(1)了解 SPMD 模式
在SPMD程式中,所有UE并行執行同一個程式(單程式),但每個UE都擁有自己的私有資料集(多資料)
(2)了解主從模式(重點)
答:主行程為從行程建立一個作業池和一個任務包,所有從行程并發執行,每個從行程迭代的從任務包中移除一個任務并處理它,指導所有任務都處理完畢或到達某些終止條件為止
核心思想是基于分而治之的思想,將一個原始任務分解為若干個語意等同的子任務,并由專門的作業者執行緒來并行執行這些任務,原始任務的結果是通過整合各個子任務的處理結果形成,
比如Master:RW,那么他的Slave是R和W,也就是我們常說的讀寫分離,
這個可以用執行緒池的思想去理解,
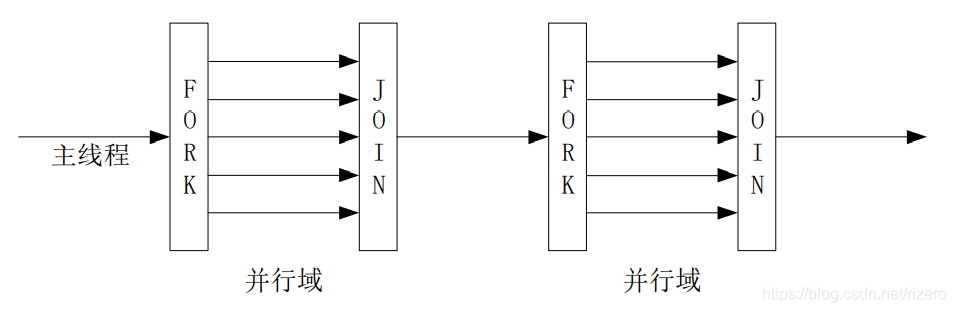
(3)理解派生聚合模式(重點,和主從模式之間的區別)
百度一下:Fork/Join 模式即可理解,
一個主UE里面Fork出多個子的UE,這些子UE并行完成任務,的一部分,等待這一步的全部子UE完成了這些任務之后,我們再繼續分支,
(4)理解共享資料模式和佇列模式(重點,能舉出例子或者分析例子)
答:共享佇列:使用“執行緒安全”實作,即使并發執行的多個UE共同使用時,該實作也能保證正確,
如果使用共享資料的話,需要考慮:確保需要這種模式,定義抽象資料型別,實作一種合理的并發控制協議,一次執行一個操作,非干擾的操作集合,讀訪問者/寫訪問者,縮減臨界區大小,嵌套鎖,特定應用的語意釋放,回顧其他考慮事項,任務調度
(5)了解分布式陣列模式
答:一維或多維陣列,被劃分為多個子陣列,并在行程或執行緒間進行分配
6. 實作機制設計空間
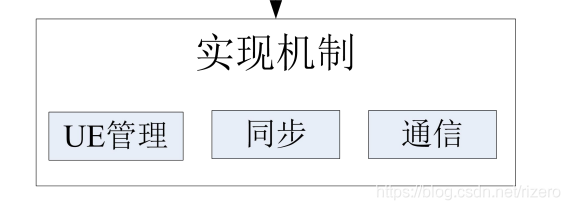
(1)理解通信及相關技術實驗相關(重點,以下內容都會出對應題目,會有簡答題、程式填空題及案例分析題,實驗會和上面的知識點結合一起出題)
訊息傳遞,集合通信,其他通信構造,
訊息是最基本的通信元素,包含資訊標識,
廣播:發送單條訊息給所有UE
柵欄:程式中的同步點,所有UE都必須到達該點,然后才能繼續向后執行
歸約:獲得一個物件集合,每個物件映射到一個UE,操作把它們組合為位于一個UE的單個物件,或組合它們并將結果廣播到每個UE上
7. 實驗思考:
三個實驗例子:生命游戲,PAI計算,日志挖掘,
(1)任務分解和資料分解的具體應用(例子,生命游戲實驗、計算π、車牌實驗,怎么應用的?)
生命游戲的分解:如果從任務分解的角度去想的話,我們的對于每一個格子都需要判斷多個條件,那么這些條件就是我們的任務步驟,也是我們可以對其進行分解的地方,如果從資料分解的角度去思考的話,我們把一個棋盤分為多塊,那么我們就完成了資料分解,
計算π的分解:
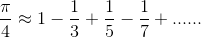
首先,我們對于算出:每個
1
2
n
+
1
\frac{1}{2n+1}
2n+11?進行步驟分解,這樣就是任務分解,單很明顯這個不大適合進行任務分解,因為每一個任務都非常小,我們進行資料分解,執行緒1計算
n
∈
[
0
,
10
]
n \in[0,10]
n∈[0,10],執行緒2計算
n
∈
[
11
,
20
]
n\in[11,20]
n∈[11,20]
如此類推,同時進行,
日志挖掘:檔案讀取的資料并行和處理資料時的任務并行,
(3)執行緒相關知識(執行緒創建、使用,執行緒安全訪問共享變數,不考執行緒池,對于生命游戲,使用執行緒還是執行緒池效率高?為什么?對于計算π,使用執行緒還是執行緒池率高?為什么?類似在課堂上說過的對比,)
關于執行緒池:
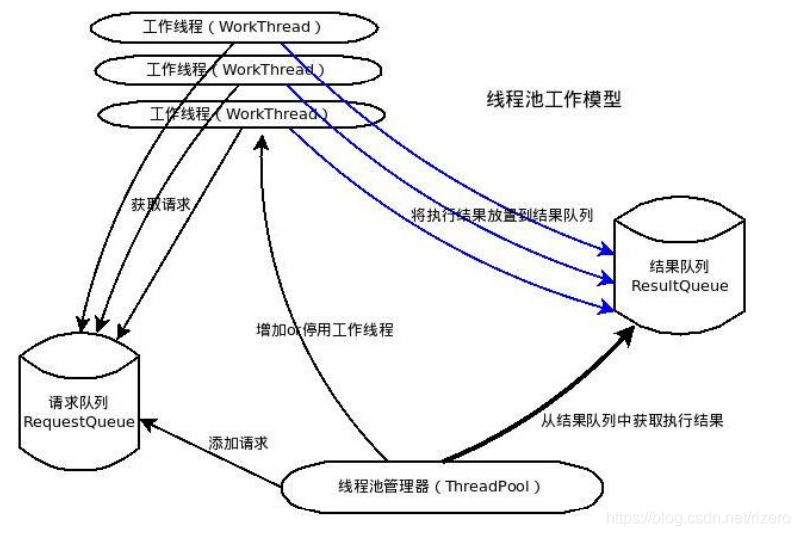
在處理迭代生命游戲的時候,由于我們采用派生聚合的模式去完成任務,因此,我們在每迭代一次的時候同步一次再發起一次并行迭代,因此需要重復創建,銷毀執行緒,需要消耗大量的資源,因此,更適合用執行緒池,
對于計算 π \pi π問題,我們可以指定多個執行緒同時計算多個任務,只需要最后一次合并,無需多次創建消耗資源,因此,我們使用執行緒池效率不見得比直接手動使用多執行緒效率高,
但在實際開發當中,為了安全考慮,我們是不應該直接手動創建多執行緒去處理問題的,(原因參見阿里的編程規范)
(4)共享資源的訪問(要求,能以簡單程式說明兩個執行緒之間安全訪問共享資源的偽代碼)
global Var
lock = new Lock()
Thread:
while(True):
if lock.is_alive == False:
lock.Lock()
#do something fo Var
lock.unLock()
else:
sleep(random)
break
T1 = Thread().start()
T2 = Thread().start()
(5)日志挖掘中,怎么樣對資料進行劃分?怎么樣對資料進行預處理?
我們需要考慮是讀取資料部分和處理資料部分,比如說,我們可以根據等長資料進行劃分,或者根據日期資料進行劃分,
資料分塊存盤,分塊讀取,
(6)支持結構中主從模式和派生聚合模式的區別和選擇(生命游戲和計算π的實驗對比,有什么區別?)
- 生命游戲:派生聚合模式(按照資料更新迭代的次數進行任務分割)
- 計算PAI:主從模式(指定一個作業池,運算完之后合并在一起)
(7)能畫出生產者-消費者模型,并對各部分進行詳細說明,
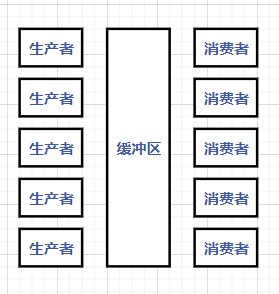
(8)生產者-消費者模型(重點,請參考阿里云 MQ 服務相關檔案,會以阿里云訊息服務MQ 為基礎,包括基本概念(例如 Topic、生產者、消費者、Tag 等等),訊息佇列種類(如普通訊息、順序訊息(全域順序和磁區順序),消費模式(集群消費和廣播消費),訂閱關系一致,
- Topic:訊息主題,一級訊息型別,通過Topic對訊息進行分類
- Tag:訊息標簽,二級訊息型別,用來進一步區分某個Topic下的訊息分類
- 訊息(Message):訊息佇列中資訊傳遞的載體
- Producer:訊息生產者,也稱為訊息發布者,負責生產并發送訊息,
- Consumer:訊息消費者,也稱為訊息訂閱者,負責接收并消費訊息,可分為兩類:
【1】Push Consumer:訊息由訊息佇列RocketMQ版推送至Consumer,(被動消費者)
【2】Pull Consumer:該類Consumer主動從訊息佇列RocketMQ版拉取訊息,(主動消費者) - Group: 一類Producer或Consumer,這類Producer或Consumer通常生產或消費同一類訊息,且訊息發布或訂閱的邏輯一致
- 集群消費: 一個Group ID所標識的所有Consumer平均分攤消費訊息,例如某個Topic有9條訊息,一個Group ID有3個Consumer實體,那么在集群消費模式下每個實體平均分攤,只消費其中的3條訊息,
- 廣播消費:一個Group ID所標識的所有Consumer都會各自消費某條訊息一次,例如某個Topic有9條訊息,一個Group ID有3個Consumer實體,那么在廣播消費模式下每個實體都會各自消費9條訊息,
- 定時訊息:Producer將訊息發送到訊息佇列RocketMQ版服務端,但并不期望這條訊息立馬投遞,而是推遲到在當前時間點之后的某一個時間投遞到Consumer進行消費,該訊息即定時訊息,同理,延時訊息也類似的意思
- 順序訊息:
【1】全域順序:對于指定的一個Topic,所有訊息按照嚴格的先入先出(FIFO)的順序進行發布和消費
【2】磁區順序:對于指定的一個Topic,所有訊息根據Sharding Key進行區塊磁區,同一個磁區內的訊息按照嚴格的FIFO順序進行發布和消費,Sharding Key是順序訊息中用來區分不同磁區的關鍵欄位,電商的訂單創建,以訂單ID作為Sharding Key,那么同一個訂單相關的創建訂單訊息、訂單支付訊息、訂單退款訊息、訂單物流訊息都會按照發布的先后順序來消費 - 訂閱關系一致:訂閱關系一致指的是同一個消費者 Group ID 下所有 Consumer 實體所訂閱的 Topic、Group ID、Tag 必須完全一致,
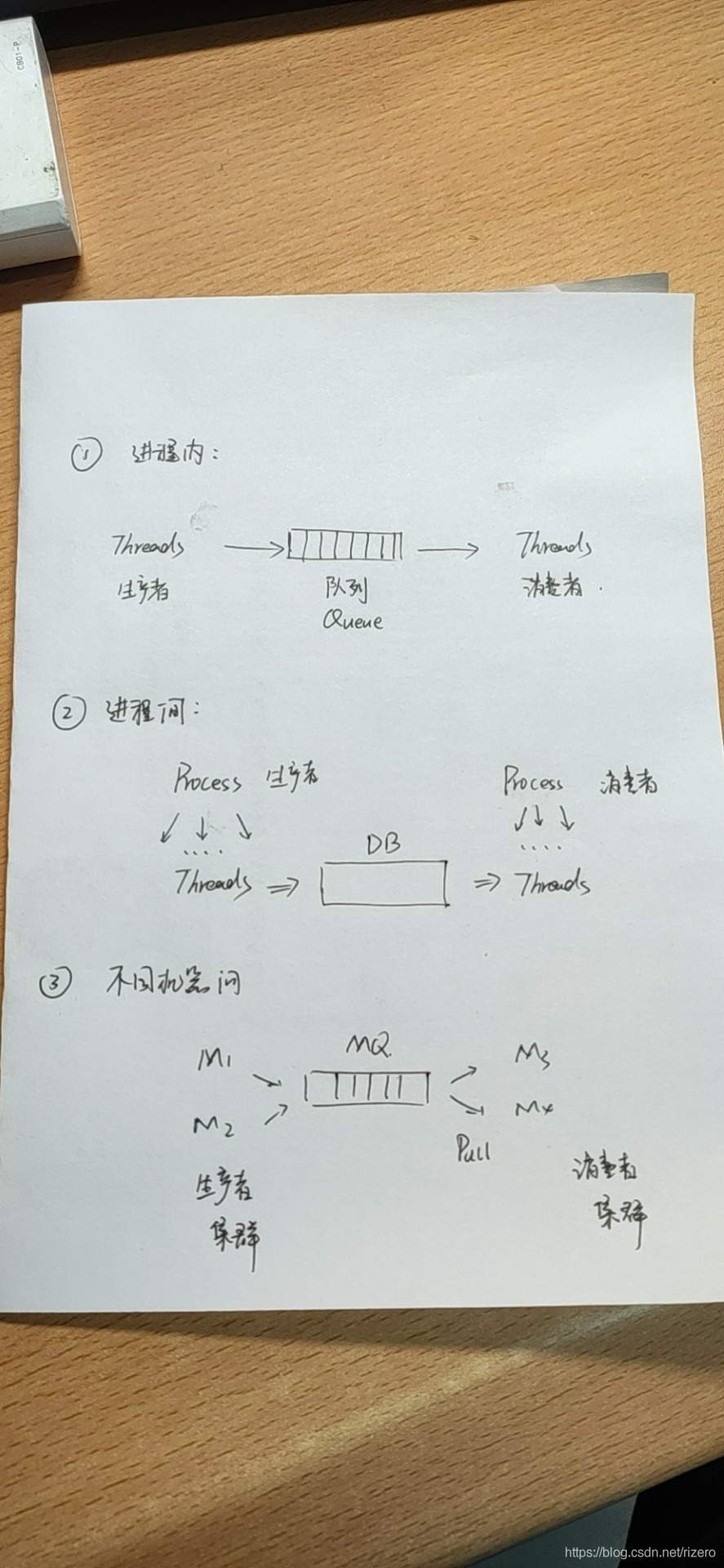
(9)根據生產者-消費者模型衍生出來的相關并行化解決方案:(要求,能畫圖說清楚以上三種結構)
- 【1】行程內實作相關結構;
- 【2】行程之間實作的相關結構;
- 【3】機器間之間的通信,
(分別對應生產者消費者實驗),
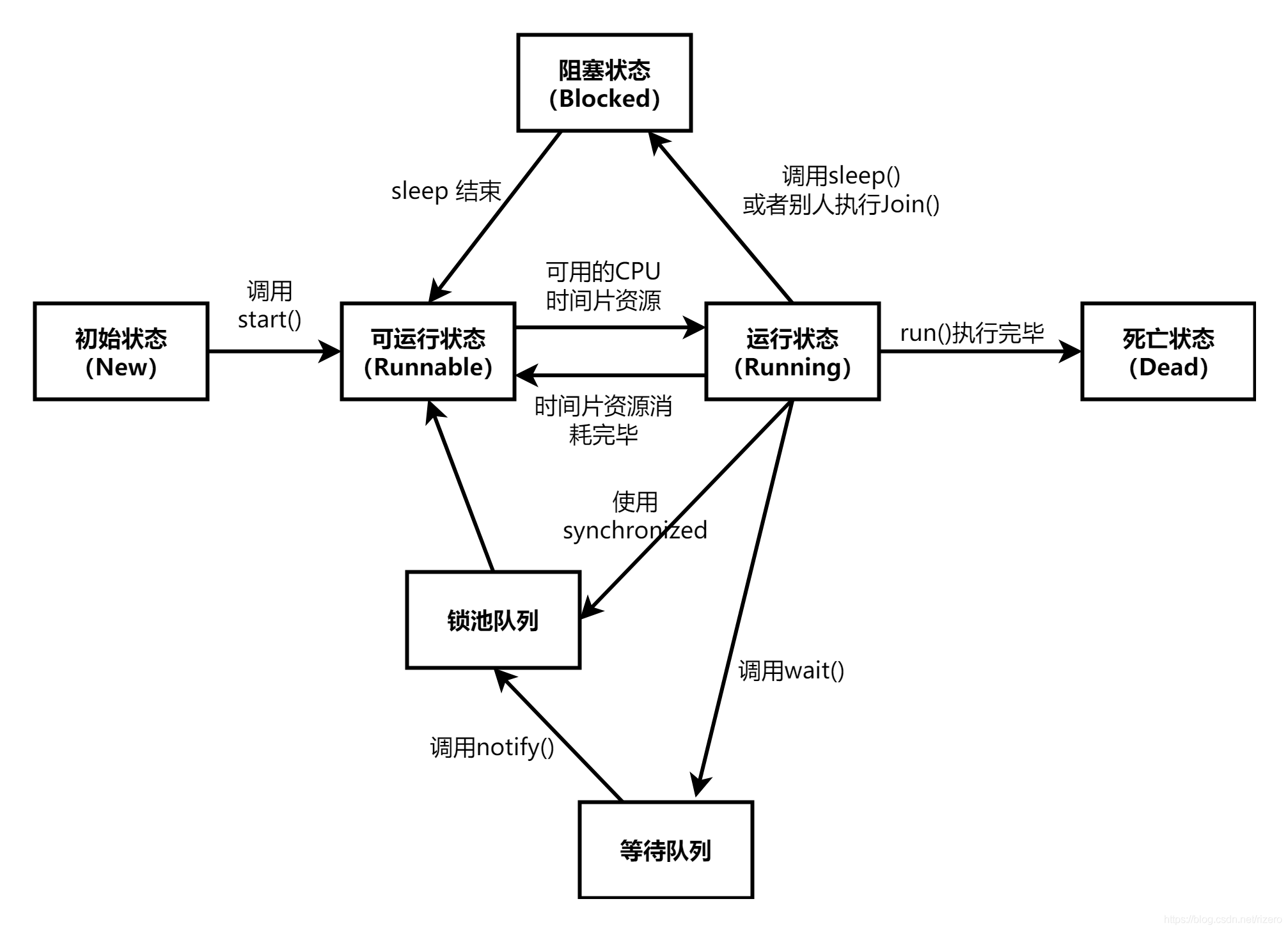
附:執行緒的五種狀態
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/248095.html
標籤:其他