NAS with RL
2017-ICLR-Neural Architecture Search with Reinforcement Learning
來源:ChenBong 博客園
- Google Brain
- Quoc V . Le etc
- GitHub: stars
- Citation:1499
Abstract
we use a recurrent network to generate the model descriptions of neural networks and train this RNN with reinforcement learning to maximize the expected accuracy of the generated architectures on a validation set.
用RNN生成模型描述(邊長的字串),用RL(強化學習)訓練RNN,來最大化模型在驗證集上的準確率,
Motivation
Along with this success is a paradigm shift from feature designing to architecture designing,
深度學習的成功是因為范式的轉變:特征設計(SIFT、HOG)到結構設計(AlexNet、VGGNet),
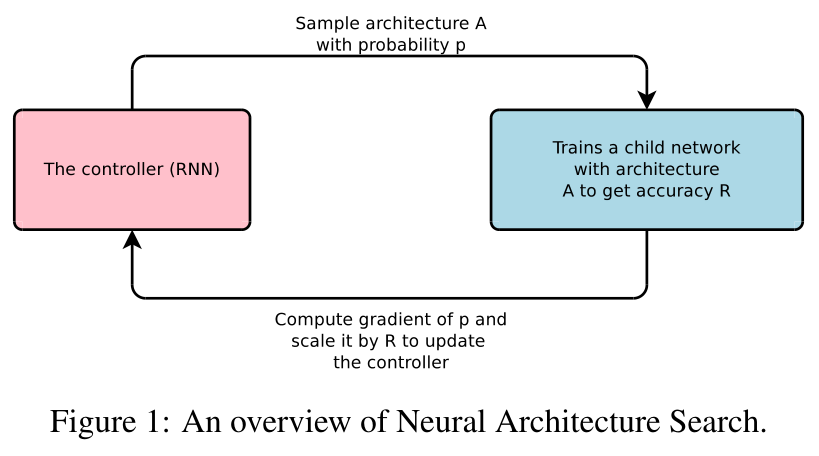
This paper presents Neural Architecture Search, a gradient-based method for finding good architectures (see Figure 1) .
控制器RNN生成很多網路結構(用變長字串描述),以p的概率采樣出結構A,訓練網路A,得到準確率R,計算p的梯度,and scale it by R* to update the controller(RNN).
Our work is based on the observation that the structure and connectivity of a neural network can be typically specified by a variable-length string.
觀察到網路結構和連接可以可以表示為變長的字串,
It is therefore possible to use a recurrent network – the controller – to generate such string.
變長字串可以用RNN(控制器)來生成,
Training the network specified by the string – the “child network” – on the real data will result in an accuracy on a validation set.
訓練特定的字串(子網路),在驗證集上,得到驗證集準確率,
Using this accuracy as the reward signal, we can compute the policy gradient to update the controller.
使用驗證集準確率作為獎勵,更新控制器RNN,
As a result, in the next iteration, the controller will give higher probabilities to architectures that receive high accuracies. In other words, the controller will learn to improve its search over time.
在下一個迭代中,控制器RNN生成準確率高的結構的概率會更大,就是說控制器RNN會學會不斷改進搜索(生成)策略,以生成更好地結構,
Contribution
- 將卷積網路結構描述為變長的字串
- 使用RNN控制器來生成變長的字串
- 使用準確率來更新RNN使得生成的結構(字串)質量越來越高
Method
3.1 GENERATE MODEL DESCRIPTIONS WITH A CONTROLLER RECURRENT NEURAL NETWORK
Let’s suppose we would like to predict feedforward neural networks with only convolutional layers, we can use the controller to generate their hyperparameters as a sequence of tokens:
設我們要預測(生成/搜索)的前向網路是卷積網路,我們可以用控制器RNN來生成每一層的超引數(序列):(卷積核高、寬,stride 高、寬,卷積核數量)五元組
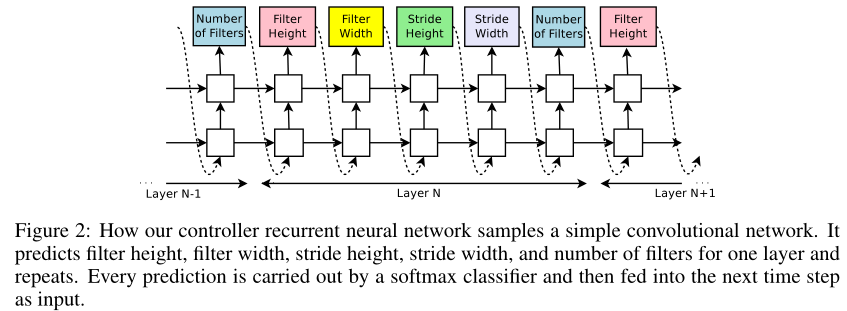
In our experiments, the process of generating an architecture stops if the number of layers exceeds a certain value.
根據經驗,層數超過特定值的時候,生成結構的程序將會停止,**層數從少到多?最后都是生成指定層的結構?
This value follows a schedule where we increase it as training progresses.
這個指定值隨著訓練程序逐漸增加,
Once the controller RNN finishes generating an architecture, a neural network with this architecture is built and trained.
一旦控制器RNN完成一個結構的生成,該結構的網路已經建立并且被訓練完畢**,
At convergence, the accuracy of the network on a held-out validation set is recorded.
(子網路訓練**)收斂時,記錄驗證集上的準確率,
The parameters of the controller RNN, θc, are then optimized in order to maximize the expected validation accuracy of the proposed architectures.
根據驗證集準確率更新控制器RNN,引數θc,
In the next section, we will describe a policy gradient method which we use to update parameters θc so that the controller RNN generates better architectures over time.
下一部分繼續闡述如何根據梯度策略更新控制器RNN的引數θc
3.2 Training with Reinforce
The list of tokens that the controller predicts can be viewed as a list of actions \(a_{1:T}\) to design an architecture for a child network.
控制器RNN生成的代表子網路的序列可以寫為\(a_{1:T}\).
At convergence, this child network will achieve an accuracy R on a held-out dataset.
子網路訓練到收斂時,會得到在驗證集上的準確率R
We can use this accuracy R as the reward signal and use reinforcement learning to train the controller.
我們可以使用R作為訓練RNN控制器的獎勵
More concretely, to find the optimal architecture, we ask our controller to maximize its expected reward, represented by \(J(θ_c)\):
具體地,我們讓控制器最大化獎勵R的期望,期望可以表示為\(J(θ_c)\):
\(J\left(\theta_{c}\right)=E_{P\left(a_{1: T} ; \theta_{c}\right)}[R]\).
?? **如何計算R的期望?\(P\left(a_{1: T} ; \theta_{c}\right)\),是什么?
Since there ward signal R is non-differentiable, we need to use a policy gradient method to iteratively update \(θ_c\).
由于R是不可微的,所以我們使用梯度方法來迭代更新\(θ_c\).
\(\nabla_{\theta_{c}} J\left(\theta_{c}\right)=\sum_{t=1}^{T} E_{P\left(a_{1: T} ; \theta_{c}\right)}\left[\nabla_{\theta_{c}} \log P\left(a_{t} | a_{(t-1): 1} ; \theta_{c}\right) R\right]\).
?? **\(P\left(a_{t} | a_{(t-1): 1} ; \theta_{c}\right)\).是什么?\(\sum_{t=1}^{T}\).又是什么?
An empirical approximation of the above quantity is:
上述等式右邊根據經驗近似為:
\(\frac{1}{m} \sum_{k=1}^{m} \sum_{t=1}^{T} \nabla_{\theta_{c}} \log P\left(a_{t} | a_{(t-1): 1} ; \theta_{c}\right) R_{k}\).
?? 怎么近似的?
Where m is the number of different architectures that the controller samples in one batch and T is the number of hyperparameters our controller has to predict to design a neural network architecture.
公式中m是不同結構的數量,T是控制結構的序列的長度(超參的數量)
The validation accuracy that the k-th neural network architecture achieves after being trained on a training dataset is \(R_k\).
\(R_k\)是第k個結構的訓練精度
The above update is an unbiased estimate for our gradient, but has a very high variance. In order to reduce the variance of this estimate we employ a baseline function:
以上是梯度的無偏估計,但??方差較大?,我們將其剪去baseline
\(\frac{1}{m} \sum_{k=1}^{m} \sum_{t=1}^{T} \nabla_{\theta_{c}} \log P\left(a_{t} | a_{(t-1): 1} ; \theta_{c}\right)\left(R_{k}-b\right)\)
As long as the baseline function b does not depend on the on the current action, then this is still an unbiased gradient estimate.
只要baseline不依賴當前值,就仍然是無偏估計
In this work, our baseline b is an exponential moving average of the previous architecture accuracies.
具體地,baseline的值b為先前結構的指數移動平均值(EMA)
In Neural Architecture Search, each gradient update to the controller parameters \(θ_c\) corresponds to training one child net-work to convergence.
?? 每次訓練一個子網路到收斂時才更新控制器RNN的梯度?
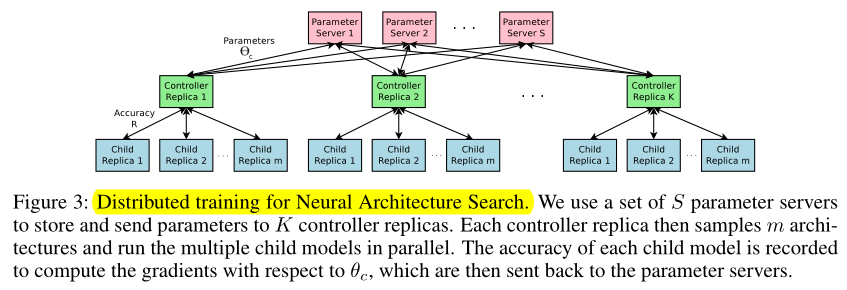
As training a child network can take hours, we use distributed training and asynchronous parameter updates in order to speed up the learning process of the controller (Dean et al., 2012).
訓練一個子網路花費幾個小時,我們使用分布式訓練來加速控制器RNN的學習
We use a parameter-server scheme where we have a parameter server of S shards, that store the shared parameters for K controller replicas.
我們使用parameter-server的策略進行分布式訓練....
3.3 Increase Architecture Complexity Skip Connections and Other Layer Types
In Section 3.1, the search space does not have skip connections, or branching layers used in modern architectures such as GoogleNet (Szegedy et al., 2015), and Residual Net (He et al., 2016a).
在3.1節中,搜索空間只有卷積層,沒有skip connection(ResNet),branching layers(GoogLeNet)
In this section we introduce a method that allows our controller to propose skip connections or branching layers, thereby widening the search space.
這一節中,我們允許控制器RNN提出skip connections 和 branch layers,即擴大搜索空間
To enable the controller to predict such connections, we use a set-selection type attention (Neelakan-tan et al., 2015) which was built upon the attention mechanism (Bahdanau et al., 2015; Vinyals et al., 2015).
為了讓控制器RNN預測這些新的連接,我們使用了一種? ?? 注意力機制(集合選擇型注意力?)
At layer N, we add an anchor point which has N ? 1 content-based sigmoids to indicate the previous layers that need to be connected.
在第N層,我們添加N-1個anchor point ?? ,anchor point是基于content 的sigmoids 函式,來指示之前的N-1個層是否需要連接到當前層
Each sigmoid is a function of the current hiddenstate of the controller and the previous hiddenstates of the previous N ? 1 anchor points:
每個sigmoid函式是控制器RNN當前隱藏狀態 和 之前N-1個anchor points隱藏狀態的函式,第 \(i/N\) 層的sigmoid函式可以表示為:
\(\mathrm{P}(\text { Layer } \mathrm{j} \text { is an input to layer } \mathrm{i})=\operatorname{sigmoid}\left(v^{\mathrm{T}} \tanh \left(W_{\text {prev}} * h_{j}+W_{\text {curr}} * h_{i}\right)\right)\)
where \(h_j\) represents the hiddenstate of the controller at anchor point for the j-th layer, where j ranges from 0 to N ? 1.
式中 \(h_j\) 表示控制器RNN第 \(j\) 層anchor point的隱藏狀態,\(j∈[0, N-1]\)
We then sample from these sigmoids to decide what previous layers to be used as inputs to the current layer.
我們從這些sigmoids中采樣,以決定將先前的哪個層作為當前層的輸入
The matrices \(W_{prev}\), \(W_{currand}\) ,\(v\) are trainable parameters.
As these connections are also definedby probability distributions, the REINFORCE method still applies without any significant modifications.
在這些連接中,我們一樣定義概率分布,強化(學習)的方法依然應用,無需額外修改
Figure 4 shows how the controller uses skip connections to decide what layers it wants as inputs to the current layer.
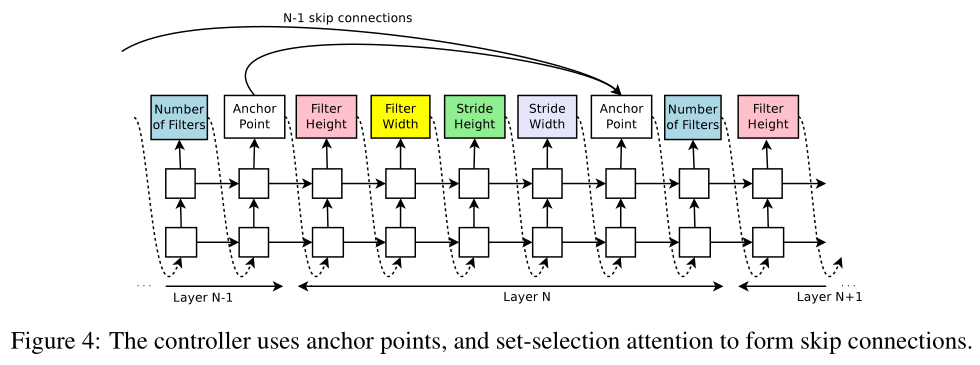
In our framework, if one layer has many input layers then all input layers are concatenated in the depth dimension.
如果有多個input layer,那么這些input在depth維度上concatenated
Skip connections can cause “compilation failures” where one layer is not compatible with another layer, or one layer may not have any input or output. To circumvent these issues, we employ three simple techniques.
skip connections會導致concatenated失敗,比如不同層的output維度不同、一個層沒有input或沒有output,為了解決這個問題,我們使用了3個技術
First, if a layer is not connected to any input layer then the image is used as the input layer.
一,如果一個層沒有input layer,那么把image作為input layer
Second, at the final layer we take all layer outputs that have not been connected and concatenate them before sending this final hidden state to the classifier.
二,在最后一層,我們將之前所有沒有output layer的層的outputs concatenate,作為最后一層的輸入/ ?? 隱藏狀態?
Lastly, if input layers to be concatenated have different sizes, we pad the small layers with zeros so that the concatenated layers have the same sizes.
三,如果需要concatenate的多個input layers的維度不同,用zeros padding小的input使維度統一
Finally, in Section 3.1, we do not predict the learning rate and we also assume that the architectures consist of only convolutional layers, which is also quite restrictive.
在3.1節中,我們不預測learning rate,且假設網路只包含卷積層,限制很嚴格
It is possible to add the learning rate as one of the predictions.
加上對learning rate的預測
Additionally, it is also possible to predict pooling, local contrast normalization (Jarrett et al., 2009; Krizhevsky et al., 2012), and batchnorm (Ioffe & Szegedy, 2015) in the architectures.
此外,也可以加上對pooling,LCN(區域對比度歸一化),bn層的預測
To be able to add more types of layers, we need to add an additional step in the controller RNN to predict the layer type, then other hyperparameters associated with it.
為了增加更多層型別,我們需要在控制器RNN增加額外的步驟,以及額外的超引數(來表示新的層)
Experiments
We apply our method to an image classification task with CIFAR-10
On CIFAR-10, our goal is to find a good convolutional architecture. On each dataset, we have a separate held-out validation dataset to compute the reward signal.
The reported performance on the test set is computed only once for the network that achieves the best result on the held-out validation dataset.
Search space: Our search space consists of convolutional architectures, with rectified linear units(ReLU) as non-linearities (Nair & Hinton, 2010), batch normalization (Ioffe & Szegedy, 2015) and skip connections between layers (Section 3.3).
搜索空間:卷積結構,包含ReLU、BN、skip connections
For every convolutional layer, the controller RNN has to select a filter height in [1, 3, 5, 7], a filter width in [1, 3, 5, 7], and a number of filters in [24, 36, 48, 64]. For strides, we perform two sets of experiments, one where we fix the strides to be 1, and one where we allow the controller to predict the strides in [1, 2, 3].
具體的搜索空間:filter height[1 3 5 7], weight[1 3 5 7], num[24 36 48 67],stride[1] or [1 2 3]
Training details: The controller RNN is a two-layer LSTM with 35 hidden units on each layer. It is trained with the ADAM optimizer (Kingma & Ba, 2015) with a learning rate of 0.0006. The weights of the controller are initialized uniformly between -0.08 and 0.08.
trained on 800 GPUs concurrently at any time.
同時在800塊GPU上訓練
Once the controller RNN samples an architecture, a child model is constructed and trained for 50 epochs.
The reward used for updating the controller is the maximum validation accuracy of the last 5 epochs cubed.
過去5個epochs的最高測驗集精度作為更新控制器RNN的獎勵
The validation set has 5,000 examples randomly sampled from the training set, the remaining 45,000 examples are used for training.
從5w個訓練集樣本中抽5000個作為驗證集,剩下45000個作為訓練集
We use the Momentum Optimizer with a learning rate of 0.1, weight decay of 1e-4, momentum of 0.9 and used Nesterov Momentum
定義Optimizer,weight decay,momentum
During the training of the controller, we use a schedule of increasing number of layers in the child networks as training progresses.
隨著訓練程序進行,逐漸增加網路層數
On CIFAR-10, we ask the controller to increase the depth by 2 for the child models every 1,600 samples, starting at 6 layers.
層數從2開始,每1600個子網路層數增加2
Results: After the controller trains 12,800 architectures, we find the architecture that achieves the best validation accuracy.
共訓練了12800個子網路
We then run a small grid search over learning rate, weight decay, batchnorm epsilon and what epoch to decay the learning rate.
網格搜索結構的超引數:learning rate, weight decay, batchnorm epsilon,lr進行weight decay的epoch數
The best model from this grid search is then run until convergence and we then compute the test accuracy of such model and summarize the results in Table 1.

First, if we ask the controller to not predict stride or pooling, it can design a 15-layer architecture that achieves 5.50% error rate on the test set.
不預測stride(stride fix to1)和pooling的15層卷積網路,err rate:5.50
This architecture has a good balance between accuracy and depth. In fact, it is the shallowest and perhaps the most inexpensive architecture among the top performing networks in this table.
該網路的優點:深度最淺,計算量最小
This architecture is shown in Appendix A, Figure 7.
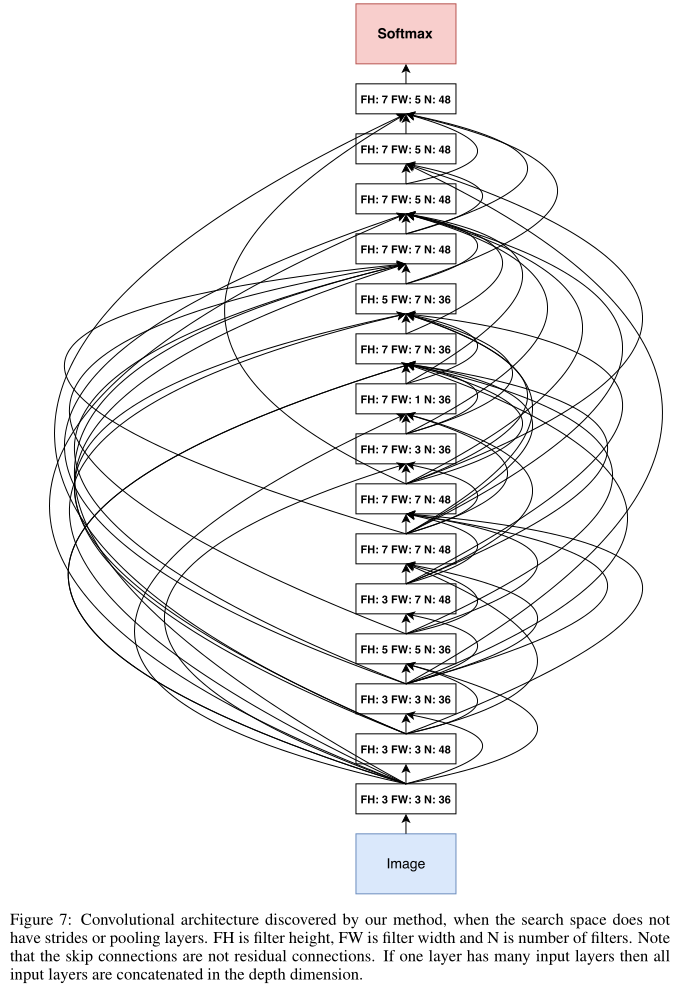
A notable feature of this architecture is that it has many rectangular filters and it prefers larger filters at the top layers. Like residual networks (He et al., 2016a), the architecture also has many one-step skip connections.
觀察該結構,1.有很多矩形卷積核(?? 矩形卷積核?)2.越深的層偏愛大卷積核 3.有很多skip connections
This architecture is a local optimum in the sense that if we perturb it, its performance becomes worse.
該結構只是區域最優,對結構引數(字串)進行微小擾動的話,會降低網路表現
In the second set of experiments, we ask the controller to predict strides in addition to other hyperparameters.
另一組實驗,(stride in [1 2 3])
In this case, it finds a 20-layer architecture that achieves 6.01% error rate on the test set, which is not much worse than the first set of experiments.
找到一個20層的結構,err rate:6.01,比第一組實驗還差
Finally, if we allow the controller to include 2 pooling layers at layer 13 and layer 24 of the architectures, the controller can design a 39-layer network that achieves 4.47% which is very close to the best human-invented architecture that achieves 3.74%.
允許引入2個pooling層(分別在第13和24層),設計39層的網路,err rate:4.47
To limit the search space complexity we have our model predict 13 layers where each layer prediction is a fully connected block of 3 layers.
為了限制搜素空間復雜度,我們搜索13層,每層都是3層的full connected block(如下,網上找的圖) 的結構( ?? 一共19層?)
Additionally, we change the number of filters our model can predict from [24, 36, 48, 64] to [6, 12, 24, 36].
改變每層filter num的搜索范圍從[24 36 48 64] 改為 [6 12 24 36]
Our result can be improved to 3.65% by adding 40 more filters to each layer of our architecture. Additionally this model with 40 filters added is 1.05x as fast as the DenseNet model that achieves 3.74%, while having better performance.
每一層額外添加40+個filters,err rate:3.65%,比DenseNet 的 3.74% 更好
Conclusion
In this paper we introduce Neural Architecture Search, an idea of using a recurrent neural network to
compose neural network architectures.
介紹了NAS
By using recurrent network as the controller, our method is flexible so that it can search variable-length architecture space.
使用RNN控制器,靈活地搜索變長的結構搜索空間
Our method has strong empirical performance on very challenging benchmarks and presents a new research direction for automatically finding good neural network architectures.
搜索到的結構有很強的性能
Appendix
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/24848.html
標籤:其他