冒泡排序和插入排序的時間復雜度相同,容易搞混淆,
冒泡排序最壞情況時間復雜度O(N^2), 最好情況時間復雜度O(N),
插入排序最壞情況時間復雜度也是O(N^2), 最好情況時間復雜度也是O(N),
冒泡排序和插入排序都是穩定的,穩定是指如果兩個數相等,排序過后它們的前后順序不變,如A=B, 排序前A在B的前面,排序后A仍然在B的前面,葉大蟲39:排序的穩定性
首先是冒泡排序:
#include <iostream>
int main() {
//int a[10] = {9, 10, 8, 7, 1, 2, 4, 5, 3, 6};
int a[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
//冒泡排序
int num = 0;
for (int i = 0; i < 9; i++) {
for (int j = 0; j < 9 - i; j++) {
num++;
if (a[j] > a[j + 1]) {
int tmp = a[j];
a[j] = a[j + 1];
a[j + 1] = tmp;
}
}
}
for (int i = 0; i < 10; i++) std::cout<<a[i]<<" ";
std::cout<<"比較次數:"<<num<<std::endl;
std::cin.get();
return 0;
}
輸出

為什么說冒泡排序最好的情況時間復雜度是O(N)呢,是因為上面的代碼還可以優化,當a[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}時會有不必要的數值比較,然而卻沒有交換發生,即序列已經有序,此時上述代碼就可以優化為:
#include <iostream>
int main() {
//int a[10] = {9, 10, 8, 7, 1, 2, 4, 5, 3, 6};
int a[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
//冒泡排序
int num = 0;
for (int i = 0; i < 9; i++) {
int flag = 0;
for (int j = 0; j < 9 - i; j++) {
num++;
if (a[j] > a[j + 1]) {
int tmp = a[j];
a[j] = a[j + 1];
a[j + 1] = tmp;
flag = 1;
}
}
if (0 == flag) break;
}
for (int i = 0; i < 10; i++) std::cout<<a[i]<<" ";
std::cout<<"比較次數:"<<num<<std::endl;
std::cin.get();
return 0;
}
輸出:
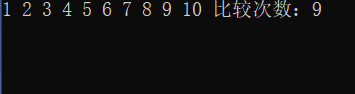
插入排序:
#include <iostream>
int main() {
//int a[10] = {9, 10, 8, 7, 1, 2, 4, 5, 3, 6};
int a[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
//插入排序
int num = 0;
for (int i = 1; i < 10; i++) {
int j = i;
num++;
while (a[j] < a[j - 1] && j > 0) {
num++;
int tmp = a[j];
a[j] = a[j - 1];
a[j - 1] =tmp;
j--;
}
}
for (int i = 0; i < 10; i++) std::cout<<a[i]<<" ";
std::cout<<"比較次數:"<<num<<std::endl;
std::cin.get();
return 0;
}
很明顯,插入排序在有序的情況下復雜度為O(N),程式輸出為:
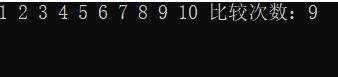
總結:冒泡排序(從小到大)的思想就是比較相鄰的元素,如果前一個元素大于后一個元素,則交換這兩個元素,然后繼續比較和交換,而插入排序(從小到大)則和冒泡排序相反,插入排序是將當前位置的數和它之前的數進行比較,如果該數小于它前面的數,則交換位置,繼續向前比較,直觀上看,冒泡排序(從小到大)是將較大值往后移動,插入排序(從小到大)是將較小值往前移動,兩者起到的效果一樣,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/248509.html
標籤:其他