Anchor Box 學習筆記(一)
- what is an anchor box ?
- How and where are anchor boxes proposed over an image?
- When are anchor boxes proposed over an image?
- Ground truth – matching anchors and generating batches
- Anchor boxes and calculating detector losses – how are anchor boxes corrected during training
what is an anchor box ?
anchor box 是指在目標檢測程序中,一組預先定義的框的集合,用來標識出被檢測到的物體,其width和height 與資料集中物體的width 和 height 相匹配,這些預定義的anchor box的尺寸包含了資料集中所有可能被檢測到的物體的尺寸組合,eg. 應該包括不同的ratio 和 scale,通常預先定義 4-10 個anchor box作為影像中各個位置的候選anchor box,
在計算機視覺領域中,深度神經網路在影像分類、目標檢測領域表現出了卓越的性能, 首先, 滑窗檢測器在前向傳播程序中定位單個物體,后來,滑窗檢測器被可以處理整個影像并輸出多個檢測結果的single-shot、 two-stage 檢測器所取代,這些檢測器很大程度上是基于anchor box 的概念來優化滑窗檢測演算法的速度和效率,這是因為滑窗檢測器需要多次前向傳播來處理影像,但大部分前向傳播程序只處理了背景像素,
如圖所示:
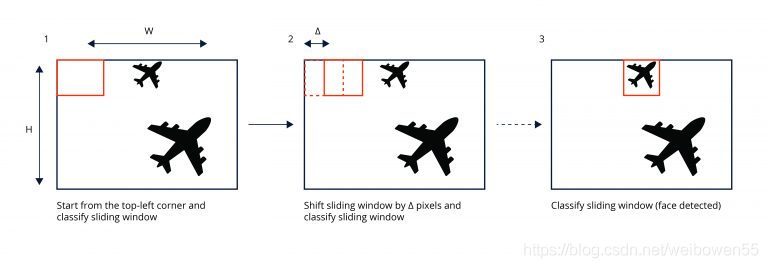
Figure 1: Sliding window detector
訓練目標檢測網路的典型任務包括提出anchor boxes 或者 用傳統computer vision 技術來搜索潛在的anchor,將一部分anchor boxes與 ground truth boxes 進行匹配,剩余未被匹配的anchors被當作背景處理,用這樣的思路訓練出正確的分類器,需要注意的是,預定義的anchor boxes可以理解為給卷積神經網路輸出的feature map上的每一個點都預測固定數量的尺寸不一的boxes,
How and where are anchor boxes proposed over an image?
從本質上講,提出anchor 就是確定一個適合資料集中大多數物體尺寸的boxes的集合,在影像上放置假設的、間隔均勻的boxes并創建一種映射關系,將feature map的輸出映射到影像中的每個位置,
要了解如何提出 anchor boxes, 假設我們的目標檢測資料集中原始影像的大小是256256,影像中包含一些物體,其大小在8080 ~ 80*40 之間,而通常目標檢測專案中,檢測框(ground truth boxes)通常的寬高比為1:1或2:1,因此,在anchor boxes提出程序中,應至少考慮提出1:1、2:1兩種anchor boxes,影像中這些物體的大小比例(ratio)將定義為其長度、寬度(以像素為單位)占整個影像長度、寬度(以像素為單位)的比例,
e.g 假設影像width = 256 px = 1 unit, 那么一個 40px寬的object 占據 40px / 256px = 0.15625個寬度單位, 也就是說,這個物體占整個影像總寬度的15.625%, 類似的,資料集中每張圖片的每個object都有對應的寬度、高度比例(ratio)來表示object的大小,
為了選擇最能代表整個資料集中物體大小的一組比例,我們可以找到最大、最小物體作為參照,即資料集中所有物件的所有寬度、高度比例的最大值和最小值(將寬度ratio、高度ratio放在一起找最大、最小值),若如果資料集中的最大和最小比例為0.15625和0.3125,而我們要為anchor boxes提議選擇三個比例,則三個比例可能為0.15625、0.234375和0.3125, 如果使用上述兩個boxes的寬高比(1:1和2:1)和這三個比例(0.15625、0.234375和0.3125)為該資料集提議anchor boxes,我們將總共有六個錨定框可以在所有輸入影像中的任意位置中提議,
要掌握這些anchor boxes的位置,請看圖2,圖中顯示的是影像上一個均勻分布的8×8網格,可以在每個單元格中心上提出一個anchor box,事實上,我們說的是在每個位置上提出六個框,共384個,在每個位置上,我們可以為每個box的寬高比和之前選擇的object比例的組合提出一個框,每個網格中心點總共有六個框,在每個位置上提出不同長寬比和比例的盒子,以覆寫所有的可能性,object detector采取這種方法來詳盡地提出anchors,
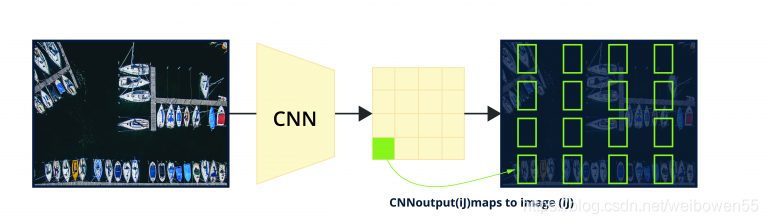
Figure 2 : Image with 8*8 grid over it
為了得到卷積神經網對圖2中網格的每個位置做出的預測,考慮一個4-channel的8×8 feature map,每個通道輸出每個位置一個anchor box的x、y、width和height,而事實上,每個grid中心點都有6個anchor boxes, 所以有 46 channel的88 featuremap,通常應用到anchor boxes概念的網路架構所輸出的特征圖是8的倍數,是因為卷積神經網基本上對輸入進行了下采樣,同時通過二維卷積和池化操作保留了重要的空間特征,完全卷積層輸出了密集的特征圖,如圖3所示,
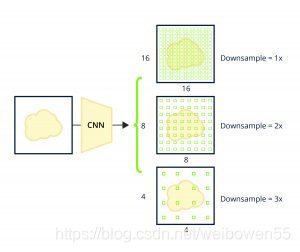
Figure 3: Conv layers showing how down-sampling occurs and how each progressive feature map is smaller.
還有一種情況需要注意,物體的大小可能小于影像中網格(grid)大小,在對input image生成網格的程序中,一個網格中可能包含了多個小物體,可以通過提出更精細的網格并相應調整特征圖輸出形狀來解決,更好的是,可以使用多個網格,并將它們映射到卷積層中的不同卷積層,就像SSD和RetinaNet的預測頭使用的特征金字塔網路一樣,
在下一小節中,我們討論在inference階段生成 ground truth batches 或解釋預測結果時,如何需要在影像上不同位置提出anchors,
When are anchor boxes proposed over an image?
如上所屬,一組anchor boxes可以描述整個資料集,并被一次性提出,在對每個特征圖位置的每個提議的anchor box應用預測偏移之前,可以在任何時刻進行,object detector 并不預測boxes確切的坐標數值,而是會為每個提出的anchor box(anchor box proposal) 預測一組坐標offset和物體所屬類別的confidence score,在對神經網路輸出進行解釋之前,網路并不會將feature map中的坐標映射到input image的某個位置,
理論上來說,由于每幅影像總是與同一套固定形式的anchor box相關聯,并且ground truth 在訓練程序中也不會發生改變,所以并不需要多次提出anchor box,也不需要多次將anchor box與ground truth 或背景進行匹配,當然,這些取決于個人代碼撰寫,通常提議的anchor boxes與ground truth的提議發生在一個batch generator內,有時候提議生成層(proposal generating layers) 會被加入到網路結構當中,目的將anchor資料添加到網路輸出tensor中,但不論如何,anchor boxes的生成程序的邏輯都是類似的,
在了解這一點后,我們可以更快了解何時在影像中生成anchor box proposal,或更確切地說,系統何時真正需要初始化這些anchor boxes并將資料結構傳入記憶體以備使用——在 batch generation time將proposal與ground truth 進行匹配并且在inference 階段將預測的offsets 應用到proposal中去,在上述這些時間節點,anchor boxes必須已經被提出了,
Ground truth – matching anchors and generating batches
Ground truth batches 必須包含需要學習的目標offsets,并且要包含提議的anchors,后者在訓練階段并不會被使用但是的確避免了在inference階段將anchors、offset預測與其他資料結構或代碼相關聯的情況,目標offset 應為將anchor box proposal 移動至與之匹配的ground truth所需的精確數值;同時,若預測為背景(background)則offset為0,因為背景不需要糾正,
概括地說,anchor-based batch generators 構建了一個learning target —— 在訓練程序中將考慮影像中的每個anchor box,無論這個anchor是否被判斷為foreground 或者 background,按照上述例子,一個batch 從6個anchor box開始,分別位于8*8個grid的中心點,總共384個anchor box,
每個anchor box 都會通過以下步驟與ground truth 進行匹配:
- 對每個anchor 找到與其具有最高IOU(intersection over union)的ground truth
- IOU 大于 50%的anchor與ground truth進行匹配
- IOU 大于 40% 的anchor 被認為是模棱兩可的,被忽略
- IOU 小于40% 的anchor被認定為background
現在來探索一下一個batch究竟是什么樣的,首先擁有一個擁有全部提議anchor box的集合(在我們的示例中是384 個),與ground truth 匹配的框將會包含它所屬的object category(類別)并且會更新offset來糾正anchor box的位置,被認定為模棱兩可的或是背景的anchor box會將offset保持為0, 這些offset是需要被我們的神經網路去擬合的,這些是在bounding box regression 階段需要被學習的數值,
確定哪些背景offset將被用于權重更新,并且丟棄不匹配的anchor box的程序將會在損失函式階段出現,
Anchor boxes and calculating detector losses – how are anchor boxes corrected during training
神經網路預測了每個feature map位置上所有提議的offset, 這意味著ground truth資料包含了anchor box到ground truth box 的真實offset,而背景box的真實offset保持為零, 這些零值將被忽略,否則background anchor box 的offset會被計算到Loss中,這是因為:object detection是關于learning查找foreground object的,并且通常僅對foreground 最小化bound box回歸損失(在預測的偏移量和正確的偏移量之間), 換句話說,背景部分不應該對目標檢測的程序產生影響,背景中并不包含物體,所以當然不存在anchor與ground truth之間的offset,
通常 classification Loss 通過使用全部background boxes的子集來處理class imbalance的問題,這是因為對每個點都有6個提議的anchor boxes,總共有384個,那么大部分的box都將是背景,這就造成了class imbalance問題,一種常用的解決方式就是采用hard negative mining方法 —— 根據一個自定義的ratio(通常是1:3,foreground:background)來選擇哪些background box會被使用在Loss計算中,另一種常用的方法是降低易分類物體的權重(down-weighting loss contributions of easily classifiable examples),就像在RetinaNet中所用到的Focal Loss一樣,
未完待續,,
Reference
https://www.wovenware.com/blog/2020/06/anchor-boxes-in-object-detection-when-where-and-how-to-propose-them-for-deep-learning-apps/#.X_6FEOgzZD_
https://d2l.ai/chapter_computer-vision/anchor.html
https://ww2.mathworks.cn/help/vision/ug/anchor-boxes-for-object-detection.html
https://towardsdatascience.com/anchor-boxes-the-key-to-quality-object-detection-ddf9d612d4f9
https://blog.roboflow.com/what-is-an-anchor-box/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/248596.html
標籤:其他