import jieba
txt=open("紅樓夢.txt","r",encoding='utf-8').read()
words= jieba.lcut(txt)
counts={}
for word in words:
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(15):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
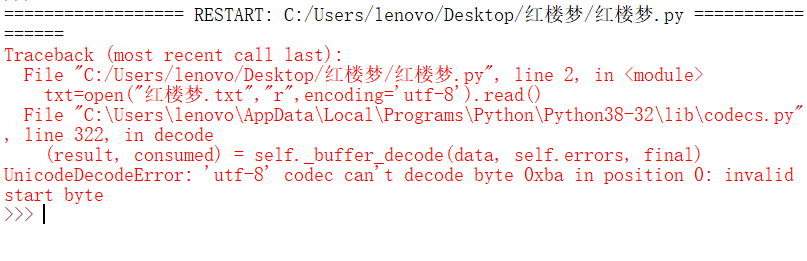
求問這是哪里出現什么問題了呀?
uj5u.com熱心網友回復:
那說明 紅樓夢.txt 不是 utf-8 格式。 兩種解決方法。1、檢查紅樓夢.txt 是什么編碼( 可能是 gbk) , 按編碼修改 encoding= 引數。
2 、 用 UE 或者 notepad ++ 修改為 utf8 編碼。
uj5u.com熱心網友回復:
這個問題解決了,謝謝。還有一個問題:
print("{0:<10}{1:>5}".format(word,count))

為什么王夫人那一行的格式和別的不一樣呢?
uj5u.com熱心網友回復:
想對齊好看, 試試 print('{0}\t{1}'.format(a,b)) 這種形式uj5u.com熱心網友回復:
format{0:<10}中: 號后面帶填充的字符,只能是一個字符,不指定則默認是用空格填充。
解決辦法是:
用中文空格填充就好。中文空格的編碼為chr(12288)
print("{0:{2}<10}{1:<5}".format(word,count,chr(12288)))
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/24864.html