今天是2020年2月1日星期六,疫情延續,現在確診人數達到了11821例,艱難困苦,玉汝于成,相信國家的力量!大家齊心協力干一件事,疫情會盡早結束的,武漢加油,前幾天整理感知機演算法的內容,發現寫博客這件事情,的確是有利于學習啊,把知識點寫出來,自己心里得對內容十分清楚,動手去做這件事情真的是太重要了,知道做不到等于不知道啊,現在記錄的算是初稿,先把三分之一的內容整理出來,開學再詳細整理,再確認幾遍后,再發表到博客上,反反復復的這幾遍,相當于反反復復的理解知識點,書讀百遍其義自見,知識點想不明白也該明白了,爭取開學前把監督學習部分的原理講解部分弄完,開學一個月左右的時間完成二次學習整理,堅持下來的話,暑假前完成該書的學習,理想很豐滿~加油~
GitHub:https://github.com/wangzycloud/statistical-learning-method
K近鄰演算法
引入
首先K近鄰演算法是一種基本的分類與回歸方法,這里只討論分類問題中的K近鄰法,顧名思義,近鄰演算法要根據某實體點附近的情況,判斷該實體點的類別,也就是找到該實體點附近的幾個實體,看看它們都屬于什么類別,然后確定該實體點所屬的類別,
這是具有實際意義的,舉個感冒病人是否需要輸液的例子,病情嚴重的病人,發熱乏力咳嗽的癥狀是嚴重的,病情嚴重的群體,大家發熱乏力咳嗽的癥狀是類似的,具有體溫高的癥狀,或者具有流鼻涕的癥狀,或者具有咳嗽的癥狀,這部分群體具有相似的特征;同樣,沒有病情的群體,各項癥狀是正常的,不會有體溫高、咳嗽、乏力這些癥狀(在這里不考慮其它疾病是否導致這些癥狀),那么,對于一個新的來診人員B,若具有了上述癥狀,體溫和需要輸液的患者A一樣高,和患者A同樣具有咳嗽、乏力等癥狀,在特征的表現上,B和A具有了非常高的相似性,那么,我們就可以根據這些相似的癥狀,判斷B需要輸液了,對于新的來診人員C,若C不具有體溫高、咳嗽乏力等癥狀,和患者A的相似性差距很大,那么就沒有理由判斷C是一個感冒病人,我們可以通過C具有的病癥特征(和哪些病人情況相似),判斷C患有什么疾病,屬于什么分類,
如何衡量“附近”?如何衡量相似性?這叫距離度量,需要找到多少癥狀相似的患者?這叫K值的選擇,找到了K個癥狀相似的患者,如何判斷新患者的疾病?根據K個病人的癥狀判斷新患者的疾病,這叫分類決策規則,
K近鄰法假設給定一個訓練資料集,其中的實體類別已經確定,將輸入空間的實體點映射到特征空間,用特征向量作為輸入,輸出實體的類別,分類時,根據k個最近鄰的訓練實體的類別,通過多數表決等方式進行預測,
可以看到,K近鄰法不具有顯式的學習程序,實際上是對特征空間的劃分,利用訓練資料,將特征向量空間劃分為不同子區域,新的實體點根據相似性找到所屬區域,作為分類的“模型”,接下來將按照書中講述的次序,學習K近鄰演算法、模型、三要素及kd樹,
K近鄰演算法
K近鄰演算法簡單、直觀,給定一個訓練資料集,對新的輸入實體,在訓練資料集中找到與該實體最鄰近的K個實體,這K個實體的多數屬于哪個類,就把該輸入實體劃分到這個類中,

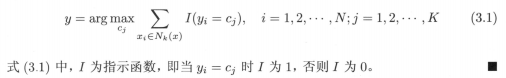
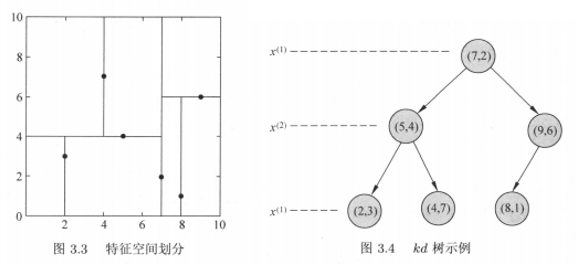
演算法流程圖:
K=1時,稱為最近鄰演算法,對于輸入的實體點x,將訓練集中最近鄰點的類別作為x的類別,
K近鄰模型
上文提到,K近鄰模型實際上對應于特征空間的劃分,由三個基本要素構成,距離度量、K值的選擇和分類決策規則,K近鄰模型對于一個新的輸入實體,它所屬的類別被唯一的確定,這相當于根據該實體的特征表現,將特征空間劃分為一些子空間,確定子空間中每個實體點所屬的類別,
在現實場景中,對于要分類的資料,資料與資料之間具有相似性是被分類的依據,物以類聚是指同樣的東西才能聚在一起,相互關聯關系比較近,才可以被歸為一類,先把輸入實體映射到特征空間,找到可以表征實體的特征向量,對每個訓練實體點x,距離該點比其它點更近的所有點組成一個區域,叫做單元,每個訓練實體點屬于一個單元,所有單元將特征空間劃分為各個子部分,每個單元中實體點的類別都是確定的,
1)距離度量
特征空間中兩個實體點的距離是兩個實體點相似程度的反映,在特征空間中,每個實體點通過特征向量來表示,比如用二維向量(39.9,5)來表示患者A體溫39.9°,其它癥狀明顯,或者四維向量(39.9,是,是,是)來表示患者B體溫39.9°,咳嗽、乏力且打噴嚏,一般情況下,是需要把輸入空間的資料轉換到特征空間中,用特征向量來表示資料,書中提到了Lp距離,這里我們通過公式可以看到,實體點xi與實體點xj之間的LP距離,實際上就是兩個特征向量,各個分量差的絕對值P次方進行求和,再開P次根,

接下來看一下書中的距離度量,

可以從公式中直觀的看出來,歐氏距離將各個分量差異平方之后求和,再開方,相當于把各個分量差異進行混合,雜糅在一起,將各個分量獨立的差異,通過開根方整合到一起,偏向“和緩”的考慮兩個特征向量整體的差異;曼哈頓距離則直接將各個分量的差異進行求和,各分量的差異“野蠻”的直接加在一起作為兩個特征向量之間的距離;當P等于無窮大時,取各個分量差異的最大值,來表示兩個特征向量之間的距離,該距離用分量差異最大值代表兩特征向量距離的方法,提供給我們度量距離的一種思路:無論歐氏距離還是曼哈頓距離,各個分量的重要性是一樣的,在現實場景中,不同的因素是具有不同重要性的,就是說,不同分量的差異,在特征向量距離度量的表示上,應該給不同的分量差異賦予不同的權重,這樣得到的兩個實體之間的距離更符合現實場景,例如體溫過高和其它癥狀的表現,在衡量兩個患者是否相似的距離上,體溫高這個特征分量應該比其它癥狀更重要一些,
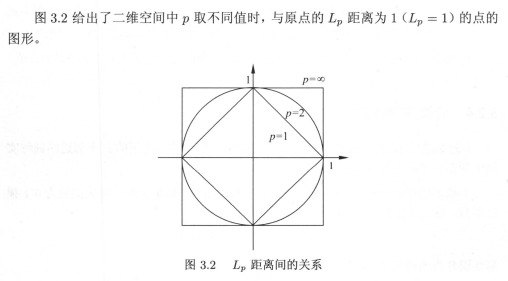
在圖3.2中,可以看到p=1的菱形直線上,橫軸到原點的距離加縱軸到原點的距離,始終為1;在p=2的圓形上,可以發現半徑r=1,其實就是橫軸縱軸勾股定理的斜邊;在p=∞的正方形直線上,要取到橫軸、縱軸差異的最大值,與原點距離為1就要選擇最外的正方形,書中的例3.1說明了由不同的距離度量所確定的最近鄰點是不同的,

2)K值的選擇
K值的選擇會對近鄰法的結果產生重大影響,書中解釋的很詳細,表面上來說,K值的大小決定了多數表決時選取的最近鄰個數,K值小,需要選取的鄰居少,預測實體點僅與少數距離最近的實體點有關,這就會導致預測結果對近鄰的實體點非常敏感,如果鄰近的實體點恰巧是噪點,預測就會出錯,導致過擬合,K=1時為最鄰近法,只取最鄰近的一個實體點進行判斷,預測的結果只取決于一個相近實體點(所有雞蛋都放在了一個籃子里),判斷出錯的幾率非常大,
K值大,就相當于從更多的近鄰實體點中進行多數表決,這就避免了所有雞蛋放在同一個籃子里,減少了噪點對預測的影響,預測結果需要從多個實體中得出,但是,距離較遠差距大的實體點也會對預測起作用,這會間接導致判斷出錯,K=N時,無論輸入實體是什么,都將簡單的預測它屬于訓練集中實體最多的類,
在實際應用中,K值的選擇通常通過交叉驗證法來選取最優的K值,一般是一個比較小的數值,
3)分類決策規則
K近鄰法中的分類決策規則往往是多數表決,即由K個近鄰的訓練實體中的多數類決定輸入實體的類別,也就是說最近鄰10個患者中,需要輸液的有7個人,3個人不需要輸液,那么新的來診人員判斷為需要輸液(取多數的類別),書中對多數表決規則做了簡單的數學解釋,用來說明多數表決規則等價于經驗風險最小化,


這里以0-1損失為例,通過第三個公式,我們可以看出,我們要想讓誤分類率減小,就要選擇多數實體的類作為預測,在公式右端,若選擇少數實體的類別,該值小,左端誤分類率將增大,
K近鄰法的實作:kd樹
通過上述的學習,我們可以發現K近鄰法主要考慮的問題,是如何在訓練資料集中找到距離新實體點最近的K個鄰近實體點,訓練資料量越多,特征向量的維度越大,尋找最近的K個鄰近點就越復雜,最簡單的方法是進行線性掃描,這時要計算每個訓練資料點與輸入實體的距離,資料量大時,計算非常耗時,為了提高K近鄰的搜索效率,可以考慮采用特殊的結構來存盤訓練資料,從而減少計算量,比如說kd樹演算法,
Kd樹是一種對n維空間進行劃分,并將分割超平面上的實體點進行存盤,以便對其進行快速檢索的二叉樹,構造kd樹相當于不斷的用垂直于坐標軸的超平面將n維空間切分,構成一系列包含每個結點的n維超矩形區域,
Kd樹的構造可以結合二叉搜索樹的知識點去理解,既然結合二叉樹的存盤結構,那么就應該是采用二分的思想來方便查找程序,一維的情況下,二叉搜索樹的思想是首先構造根節點,它是近鄰法查找時的第一個實體點,應該具有一定的代表性,在資料的分布上,盡量居中,以根節點為中心分為左右兩個子空間,遞回進行構造,從二叉搜索樹中,我們知道,整個二叉搜索樹方便查找的關鍵是根節點的選取,也就是中間切分點的選擇非常重要,
在kd樹的構造中,同樣是通過遞回的方法,不斷的選取合適的根節點,用超平面將n維空間劃分為左右子空間,區別在于根節點的選取,根節點除了中位數的要求外,還要考慮不同維度的資訊,本書中的演算法,是將各個維度按順序回圈考慮,若有兩個維度,在二叉樹的第一層上,先用第一個維度上各個數值的中位點作為根節點劃分為左右子空間;在遞回的程序中,二叉樹的第二層,是選取左右子樹的根節點,這時的根節點是從第二個維度的各個數值中選取中位點;二叉樹的第三層根節點,按維度順序回圈從第一個維度上選取子樹資料集的中位點;二叉樹的第四層根節點,按維度順序回圈再次從第二個維度上選取,接下來的各層根節點依此類推,
特征空間為二維時,是用直線將特征空間劃分為矩形子區域,特征空間為三維及高維時,用超平面將特征空間劃分為超矩形區域,遞回進行劃分,直到子區域內沒有實體時終止,在演算法3.2中,有兩個地方可以改進:第一點,通過中位點選取切分點構造的kd樹是平衡的,但搜索效率未必是最優的;第二點,按維度順序回圈選取切分點進行劃分未必是最優的,可以依據不同維度上資料的分布規律來決定當前層選取切分點采用哪個維度?可深入,

演算法流程圖:
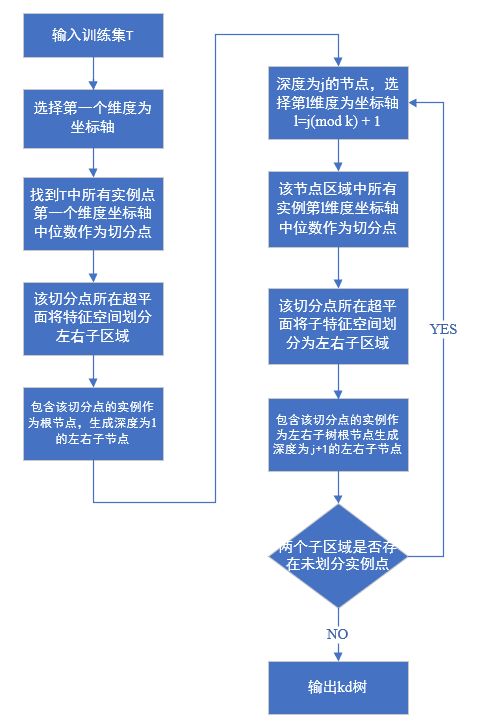
書中以二維特征向量舉例,也就是特征空間是一個二維平面,用直線將各個子空間劃分開,劃分的程序得到存盤實體點的二叉樹結構,二叉樹的每層根節點,按照維度順序回圈作為切分點的選取來源,

搜索kd樹
Kd樹可以省去對大部分資料點的搜索,從而減少搜索的計算量,以最近鄰舉例加以描述,給定一個目標點,搜索其最近的鄰居,首先依次選取維度,按照二分查找的思想找到包含目標點的葉節點;然后從該葉節點出發,逆序退回父節點;在退回路徑上,不斷查找與目標點最鄰近的節點,回退到根節點確定不可能存在更近的節點時終止,
在kd樹搜索演算法中,如果實體點是隨機分布的,kd樹搜索的平均計算復雜度為O(logN),N是訓練實體數,kd樹適用于訓練實體數遠大于空間維數時的k近鄰搜索,當特征向量維度大,也就是特征空間維數接近訓練實體數時,效率迅速下降,

演算法流程圖:
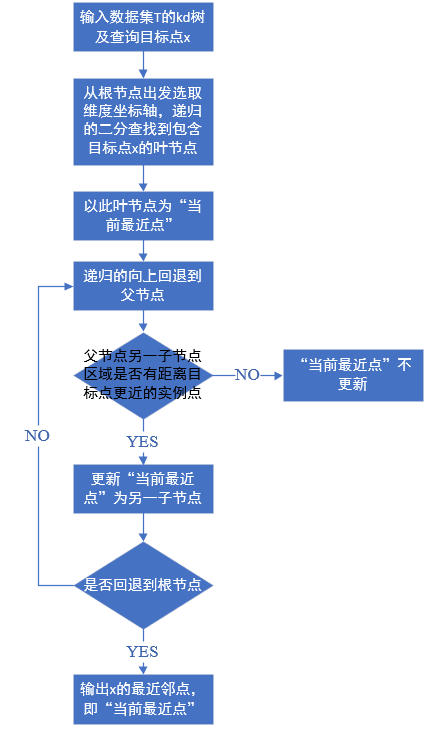
示例:

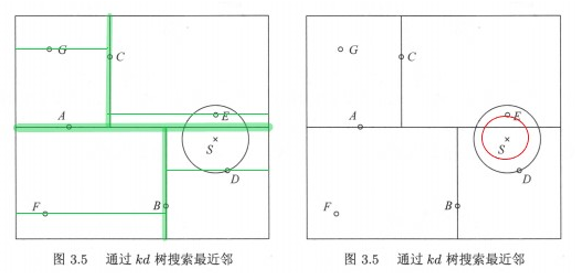
從示例圖中可以看出,包含目標點的葉節點對應包含目標點的矩形區域,以此為葉節點的實體點作為當前最近點,目標點的最近鄰一定在以目標點為中心并通過當前最近點的圓形內部,回退到當前節點的父節點,如果父節點的另一子節點的矩形區域與該圓形相交,那么需要在相交的區域內再次尋找與目標點更近的實體點,如果在相交區域內找到了更近的實體點,則將此點作為新的當前最近點;演算法繼續向更上一級父節點回退,繼續上述程序,直到找到最近的實體點;如果父節點的另一節點的矩形區域與該圓形不相交,那該矩形區域內,肯定不存在更近的實體點;演算法回退到根節點,直到不存在比當前最近點更近的實體點時,停止搜索,
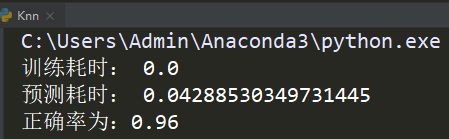
代碼效果
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/24878.html
標籤:其他