開篇
- 引言
- 為什么會出現分布式系統
- 分布式系統的發展史
- 傳統存盤
- 分布式存盤現狀
- 云存盤
- 分布式系統的現狀
- 云存盤
- 智能化
- 標準化
- 分布式系統的基石——分布式存盤引擎
- 分布式鍵值系統
- 分布式檔案系統
- 分布式表格系統
引言
?隨著互聯網的不斷發展,人類社會的資料量迅速激增,這些資料大部分都是圖片、音視頻這類大檔案,而存放這些資料的存盤可以說是很多系統中最核心、最重要、最關鍵的組成部分,沒有之一,像loT物聯網、AI人工智能,Edge邊緣計算,也無不都是以分布式存盤技術為基石,無疑,誰更好地掌握了分布式存盤技術,誰就更容易在新一輪技術浪潮中獲得主動,
? 如今,各大廠對分布式存盤的求賢若渴,但是面試難度也比較大,原因就是分布式存盤技術概念繁多,知識龐雜,此外,還涉及到很多理論知識和概念,比如資料結構(哈希、數)等,這些內容往往都是偏計算機科學基礎范疇的一些知識,學起來不容易理解和記憶,并且會感覺到理論和實踐之間出現巨大的鴻溝,接下來的篇章中,我們將通過大廠專案實踐遇到的一些問題,講這些問題的解決辦法,同時再這當中貫穿一些知識和原理,通過這樣的方式帶大家體系化地理解分布式存盤的這些概念,
為什么會出現分布式系統
?如果處理的資料有 20T,而你手上的機器只有 500G 的硬碟,怎么辦?
?一種辦法是縱向擴展,換一塊128T 硬碟增加單機的硬體能力;另一種是水平/橫向擴展,增加計算機數量,前者很容易遇到性能到瓶頸,分布式系統則可以根據某一指標進行“線性擴展”,所以按照這個思路,分布式系統的出現其實就是為了解決單機的性能瓶頸成為拖累的問題,單機系統的磁盤 IO、網路帶寬資源畢竟有限,從而它所能支持的并發量就是有限的,比如單機應用只能支持100并發,如果像京東,淘寶這樣的大型電商,在雙十一時候一秒的訂單量就是幾十W,那么單機就完全滿足不了,單機系統還有其他問題-不可靠啊,因為只有一臺機器,壞了就不能用了啊,所以單機模式的核心問題是性能受限,存在單點失效問題,
? 用生活中一個例子就很好的解釋這個問題:養兒防老問題,一對夫婦只有一個兒子,這個兒子就像一個單機系統,這對夫婦中的一個人病了要去醫院,那么兒子可以搞定,如果兩個老人同時都病了要去不同的醫院,那么這個兒子就忙不過來了,如果這個兒子出差了,那么對夫婦就沒人照顧了,這就是單機系統不能解決并發以及故障問題,
分布式系統的發展史
? 磁盤存盤系統經歷了半個多世紀的發展,存盤系統隨著磁盤以及 CPU等介質的發展在不斷的演進,早期的資料存盤一般以磁盤陣列等設備為外設,圍繞服務器通過直連的方式進行存盤,近年來,隨著網路技術的發展,服務器的資料讀取范圍也得到了很大拓展,逐漸實作了現在的網路存盤,相較于傳統存盤來說,網路存盤的優勢更加突出,其不但安裝便捷、成本低廉,并且還能夠大規模的拓展存盤設備,從而有效滿足了海量資料存盤對存盤空間的需求,不過網路存盤對網路資源的消耗極大,這是一項難題,為此,后來又逐漸出現了SAN存盤架構,
傳統存盤
? 目前傳統存盤系統主要的3種架構,包括DAS、NAS和SAN,
- DAS(Direct-AttachedStorage,直連存盤)
? 這是一種通過總線配接器直接將硬碟等存盤介質連接到主機上的存盤方式,在存盤設備和主機之間通常沒有任何網路設備的參與,可以說DAS是最原始、最基本的存盤架構方式,在個人電腦、服務器上也最為常見,DAS的優勢在于架構簡單、成本低廉、讀寫效率高等,但是拓展性、靈活性差, - NAS(Network-AttachedStorage,網路存盤系統)
? NAS是一種基于標準網路協議提供檔案級別訪問介面的網路存盤系統,通常采用NFS、SMB/CIFS等網路檔案共享協議進行檔案存取,NAS支持多客戶端同時訪問,為服務器提供了大容量的集中式存盤,從而也方便了服務期間的資料共享,銀行等機構早期用NAS存盤的很多, - SAN(StorageAreaNetwork,存盤區域網路)
? 通過光纖交換機等高速網路設備在服務器和磁盤陣列等存盤設備間搭設專門的存盤網路,從而提供高性能的存盤系統,SAN與NAS的區別,在于其提供塊(Block)級別的訪問介面,一般并不同時提供一個檔案系統,通常情況下,服務器需要通過SCSI等訪問協議將SAN存盤映射為本地磁盤、在其上創建檔案系統后進行使用,目前主流的企業級NAS或SAN存盤產品一般都可以提供TB級的存盤容量,高端的存盤產品也可以提供高達幾個PB的存盤容量,
分布式存盤現狀
? 隨著互聯網海量資料的爆發式增長,傳統的傳統的集中式存盤(如NAS或SAN)在容量和性能上都無法較好地滿足存盤需求,
? 分布式存盤基于標準硬體和分布式架構,實作千節點/EB級擴展,可同時對塊、物件、檔案等多種型別存盤統一管理,無論是存盤非結構化資料的分布式檔案系統,存盤結構化資料的分布式資料庫,還是半結構化資料的分布式KV,在系統的設計上主要需要滿足以下需求:基本讀寫功能、性能、可擴展性、可靠性、可用性,
? 分布式存盤系統要解決的關鍵技術問題包括諸如可擴展性、資料冗余、資料一致性、全域命名空間快取等,
? 從架構上來講,大體上可以將分布式存盤分為C/S(Client Server)架構和P2P(Peer-to-Peer)架構兩種,當然,也有一些分布式存盤中會同時存在這兩種架構混合的方式,
? 分布式存盤系統面臨的另外一個共同問題,就是如何組織和管理結點,以及如何建立資料與結點之間的映射關系,結點的動態增加或者離開,在分布式系統中基本上可以算是一種常態,
? 下面來講講什么是性能、資源、可用性和可擴展性,
性能
主要用于衡量處理各種任務的能力,常見的性能指標主要包括吞吐量(Throughput)、回應時間(Responce Time)和完成時間(Turnaround Time),
- 吞吐量
在一定時間內系統可以處理的任務數,常見的吞吐量指標有QPS(Queries Per Second)、TPS(Transactions Per Second),
- QPS:表示查詢數每秒,用于衡量一個系統每秒處理的查詢數,這個指標通常用于讀操作,數值越高說明對讀操作的支持越好,
- TPS:表示事務數每秒,用于衡量一個系統每秒處理的事務數,這個指標通常用于寫操作,越高說明寫操作的性能越好,
-
回應時間
系統回應一個請求需要花費的時間,回應時間直接影響到用戶體驗,對于延時敏感的業務來說非常重要, -
完成時間
系統真正完成一個請求或處理需要花費的時間,任務分布式模式出現的其中目的就是縮短任務的完成時間,特別是對海量資料進行計算,用戶完成時間的感受非常明顯,
資源占用
指的是一個系統提供正常能力需要占用的硬體資源,比如CPU、記憶體、硬碟等,系統在滿額負載時的資源占用一般叫做滿負載,體現了這個系統全力運行時占用情況,
可用性
通常指的是系統在各種例外可以正確提供服務的能力,它是一個非常重要的指標,衡量了系統的魯棒性,體現了系統的容錯能力,系統的可用性可以用系統停服務時間與總的時間之比來衡量或者用某功能的失敗次數與總的請求次數之比來衡量,
可靠性
可靠性和可用性非常相似,用來表示一個系統完全不出故障的概率,更多用在硬體方面,而可用性則大多數指在允許部分組件失效的情況下,一個系統對外提供服務的概率,
可擴展性
分布式系統通過擴展集群機器規模提高系統性能(吞吐量、回應時間、完成時間等)
一個分布式存盤系統往往會根據具體業務的不同,在特性設計上有不同的取舍,比如,是否需要快取模塊、是否支持通用的檔案系統介面等,
云存盤
? 云存盤是由第三方運營商提供的在線存盤系統,比如面向個人用戶的在線網盤和面向企業的檔案、塊或物件存盤系統等,云存盤的運營商負責資料中心的部署、運營和維護等作業,將資料存盤包裝成為服務的形式提供給客戶,云存盤作為云計算的延伸和重要組件之一,提供了“按需分配、按量計費”的資料存盤服務,因此,云存盤的用戶不需要搭建自己的資料中心和基礎架構,也不需要關心底層存盤系統的管理和維護等作業,并可以根據其業務需求動態地擴大或減小其對存盤容量的需求,
分布式系統的現狀
云存盤
? 云存盤通過運營商來集中、統一地部署和管理存盤系統,降低了資料存盤的成本,從而也降低了大資料行業的準入門檻,為中小型企業進軍大資料行業提供了可能性,比如,著名的在線檔案存盤服務提供商Dropbox,就是基于AWS(AmazonWeb Services)提供的在線存盤系統S3創立起來的,在云存盤興起之前,創辦類似于Dropbox這樣的初創公司幾乎不太可能,
? 云存盤背后使用的存盤系統其實多采用分布式架構,而云存盤因其更多新的應用場景,在設計上也遇到了新的問題和需求,比如,云存盤在管理系統和訪問介面上大都需要解決如何支持多租戶的訪問方式,而多租戶環境下就無可避免地要解決諸如安全、性能隔離等一系列問題,另外,云存盤和云計算一樣,都需要解決的一個共同難題就是關于信任(Trust)的問題——如何從技術上保證企業的業務資料放在第三方存盤服務提供平臺上的隱私和安全,的確是一個必須解決的技術挑戰,
?將存盤作為服務的形式提供給用戶,云存盤在訪問介面上一般都會秉承簡潔易用的特性,比如,亞馬遜的S3存盤通過標準的HTTP協議、簡單的REST介面進行存取資料,用戶分別通過Get、Put、Delete等HTTP方法進行資料塊的獲取、存放和洗掉等操作,出于操作簡便方面的考慮,亞馬遜S3服務并不提供修改或者重命名等操作;同時,亞馬遜S3服務也并不提供復雜的資料目錄結構而僅僅提供非常簡單的層級關系;用戶可以創建一個自己的資料桶(bucket),而所有的資料則直接存盤在這個bucket中,另外,云存盤還要解決用戶分享的問題,亞馬遜S3存盤中的資料直接通過唯一的URL進行訪問和標識,因此,只要其他用戶經過授權便可以通過資料的URL進行訪問,
?存盤虛擬化是云存盤的一個重要技識訓礎,是通過抽象和封裝底層存盤系統的物理特性,將多個互相隔離的存盤系統統一化為一個抽象的資源池的技術,通過存盤虛擬化技術,云存盤可以實作很多新的特性,比如,用戶資料在邏輯上的隔離、存盤空間的精簡配置等,
智能化
?存盤網路化的發展,同樣伴隨著網路智能化的發展,其結果就是存盤系統能處理更多的事情,而不像以前僅僅是存放資料的物理物體,存盤系統智能化具體體現在:
?存盤系統分擔了原來應用系統承擔的部分功能,比如與某公司資料庫合作,可由該公司提供一些資訊,由存盤設備幫助它做校驗,使資料正確地存放到磁盤里,避免錯誤的出現,充分利用磁盤陣列冗余的計算資源;"隨著磁盤陣列智能化的提高,以前很多服務器上的功能也將部分轉移到存盤網路和存盤設備上,而服務器只集中于應用系統,資料安全、備份等大部分作業都可以放在磁盤陣列和與服務器連接的存盤網路上,比如,對不同格式檔案的互動訪問中,原來都需要服務器檔案系統進行特殊處理后轉化為雙方均可識別的型別才能訪問,而現在某些存盤系統已經可以在存盤微碼級對不同檔案型別進行轉化,使得對不同檔案的訪問對用戶透明,需要指出的是,存盤智能化的趨勢中,大家似乎更傾向于把這部分智能化功能的實作放在存盤網路上,而不是放在存盤設備體中,
標準化
?在傳統存盤系統中,除了廠商為工程師提供存盤系統安裝、配置和維護等必要的簡單管理系統之外,并沒有太多存盤的專門管理系統,隨著存盤系統規模和功能的拓展以及復雜度的提高,存盤管理已經逐步發展成為一個相對獨立的存盤子系統,在傳統存盤系統中,各大存盤廠商分別為各自存盤系統設計的存盤管理企業標準大多互不兼容,在一定程度上嚴重阻礙了存盤系統管理的進一步規范化,
分布式系統的基石——分布式存盤引擎
? 對一輛跑車來說,最重要的部件就是它的發動機,那么對于分布式存盤來說,最重要的組件就是存盤引擎,存盤引擎決定了資料在記憶體和磁盤上如何存盤的,如何在方便地讀取出來,所以說它就像臺發動機一樣決定存盤系統的性能和可以干什么,不可以干什么等問題,
? 如果按照應用場景來分類的話,當前主流的分布式存盤引擎有:
分布式鍵值系統
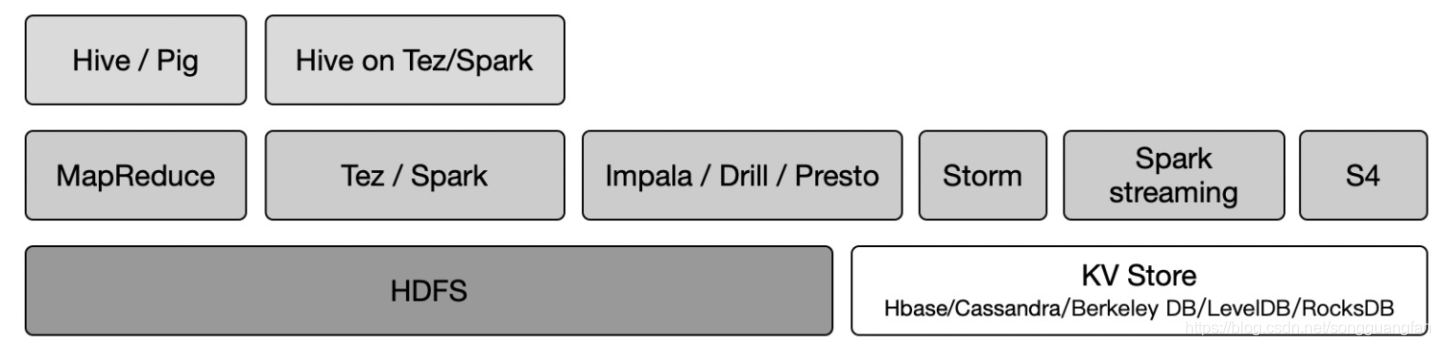
?分布式鍵值系統用于存盤關系簡單的半結構化資料,它只提供基于主鍵的CRUD(Create/Read/Update/delete)功能,即主鍵創建、讀取、更新或者洗掉一條鍵值記錄,比如你可以本篇博客作為一個整體存盤到系統里面,存盤的時候根據單一key 去做hash映射,然后再對資料做增刪改查等操作,key值的生成是要夠隨機(這樣才能保證資料在分布式的節點上是夠均勻分別的,不產生熱點),但分布式KV存盤引擎有個缺點,沒法對資料做檢索,因為Key值是隨機生成的,就不具備內容檢索的的條件,常用的方式是在其之上再加一個索引層,用于對資料的分析檢索,代表性的系統有Dynamo(早期是給S3物件存盤服務用的),以及淘寶的Tair系統,以及華為的早期的UDS系統,kv存盤的資料分布關鍵技術是一致性哈希表(Distributed Hash Table,簡稱DHT),算是比較成熟常用的技術,后續將會展開講解,它用到的地方很多,比如物件存盤,塊存盤服務都是可以基于KV存盤引擎的,典型的使用場景如備份檔案場景,每個部門作為一個桶(Bucket),每天的日期作為檔案名,去依次備份到遠端通過s3物件存盤協議去存盤,
分布式檔案系統
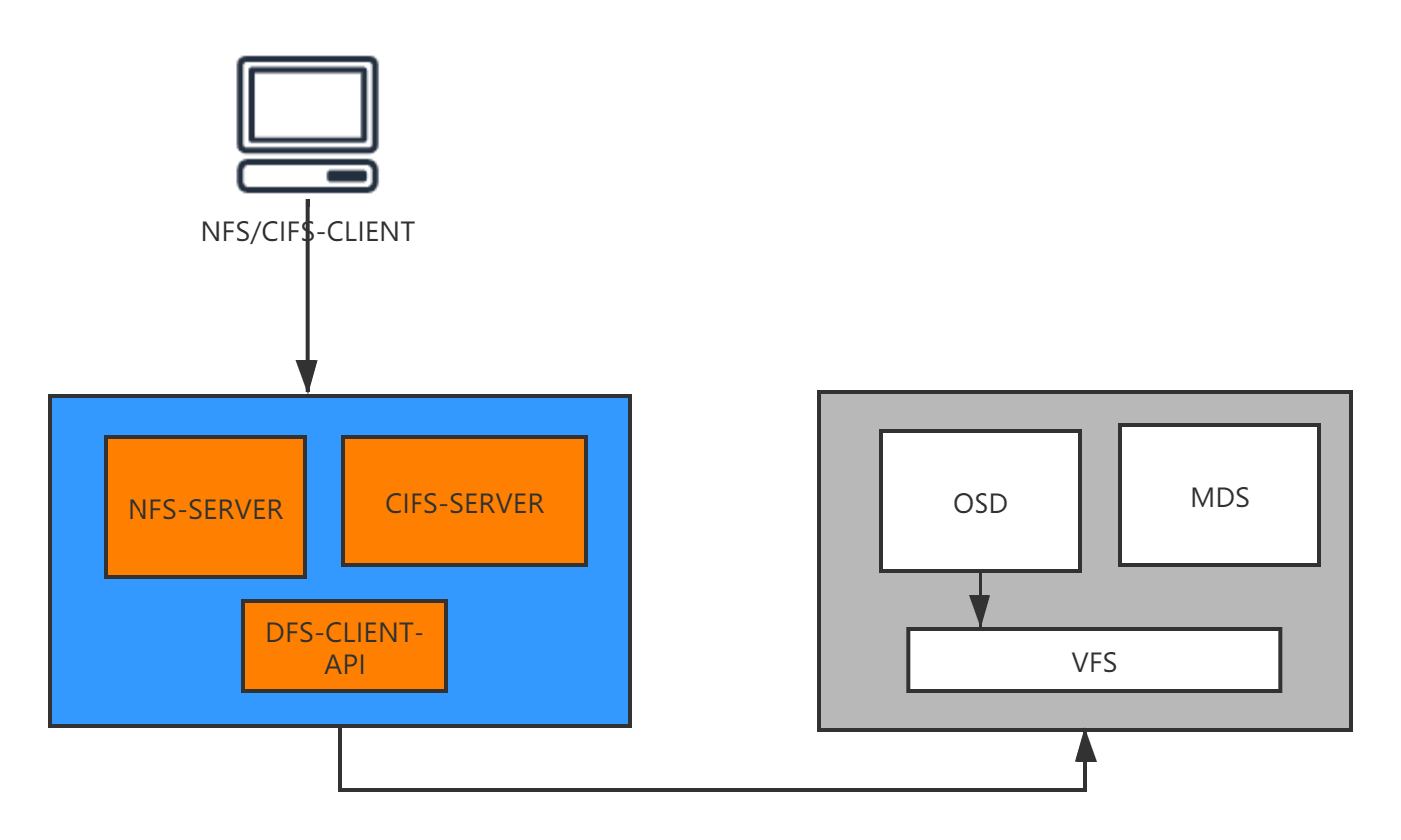
? 在Unix的世界里面,所有設備和大部分行程間通信在檔案系統層級都以檔案或偽檔案的形式查看和管理,「一切皆檔案」的 UNIX 基礎愿景和設計原則,所以,檔案系統的應用就比較廣泛了,隨著技術的不斷發展,作業系統讀寫資料的方式不僅僅限于本地IO,也同時支持通過TCP/IP遠距離獲取的方式,相當于新增一種可以遠距離傳輸的I/O技術,使得分散的存盤設備和用戶作業系統可以通過網路方式接入聯合在一起,形成更大容量,更易于拓展伸縮的存盤系統,即分布式檔案系統,分布式檔案系統架構主要考慮的有讀寫性能,資料容災備份,避免單點故障,以及資料備份,資料容錯恢復等,常見的分布式檔案系統有,GFS、HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS等,各自適用于不同的領域,它們都不是系統級的分布式檔案系統,而是應用級的分布式檔案存盤服務,除此以外,分布式檔案系統還有些企業級特性,比如QUOTA、TIER等特性做企業增強,分布式檔案系統應用場景很多,比如銀行,證券,以及科研機構內部LAN網路內,通過傳統的網路檔案系統協議(NFS/CIFS)訪問分布式檔案系統,如下圖,
分布式表格系統
?表格聽名字就知道是為分析資料而生的,分布式表格系統用于存盤關系比較復雜的半結構化資料,支持按某些維度去掃描分析,分布式表格系統用于存盤關系較為復雜的半結構化資料,與分布式鍵值系統相比,分布式表格系統以表格為單位組織資料,同普通資料庫一樣通過主鍵去標識一行以及范圍查找功能,
?分布式表格系統依賴于底層的分布式檔案系統提供可靠和高效的資料存盤,是分布式檔案系統的主要使用者,典型應用的比如google的三架馬車之一的Bigtable ,它是分布式表格系統的鼻祖,具有很好的伸縮性,可以擴展到用來管理PB級資料和上千臺服務器,用于解決 Google 內部不同產品在對資料存盤的容量和回應時延需求的差異化,力求在確保能夠容納大量資料的同時減少資料的查詢耗時,
? Bigtable使用了很多類似資料庫的實作策略,但是它不支持完整的關系資料模型,與之相反,Bigtable采取的是相對寬泛、稀疏而簡單的資料模型,客戶可以動態控制資料的分布和格式,Bigtable中資料沒有嚴格的Schema,客戶可以自己定義Schema,Bigtable 把資料存盤在若干個 Table 中,其資料特征是一個稀疏的、分布式的、持久化存盤的多維度排序Map由key和value組成,打破了傳統的RDS資料庫的固定資料結構,支持動態擴展,

?下一篇,會對另一大巨頭Amazon的海量鍵值存盤系統Dynamo的原理以及某廠如何對其進行二次開發進行講解,請大家持續關注系列文章,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/249027.html
標籤:AI