系統間的耦合高怎么辦,我們如何不讓一個服務過于龐大,一個好的方式就是依據具體的功能模塊拆分服務,降低服務的耦合度,服務間的互動可以通過訊息傳遞資料來實作,除此之外Kafka非常適合在線日志收集等高吞吐場景,kafka有更好的吞吐量,內置磁區,副本和故障轉移,這有利于處理大規模的訊息,所以kafka被各大公司廣泛運用于訊息佇列的構建:
- 訊息佇列模型-生產者消費者模型
- Kafka基本概念和架構模型
- Kafka作業流程和檔案存盤機制
- 生產者策略:磁區策略、ACK機制、故障轉移機制、Kafka可靠高效原因
- 消費者策略:消費方式、磁區分配策略、offset的維護
- Zookeeper管理
- Kafka框架搭建實戰
適合人群:不了解Kafka的新手,對Kafka的實作機制感興趣的技術人員
本文的全部內容來自我個人在Kafka學習程序中整理的博客,是該博客專欄的精華部分,在書寫程序中過濾了流程性的背景關系,例如部署環境、組態檔等,而致力于向讀者講述其中的核心部分,如果讀者有意對程序性內容深入探究,可以移步MaoLinTian的Blog,在這篇索引目錄里找到答案分布式技術相關專欄索引
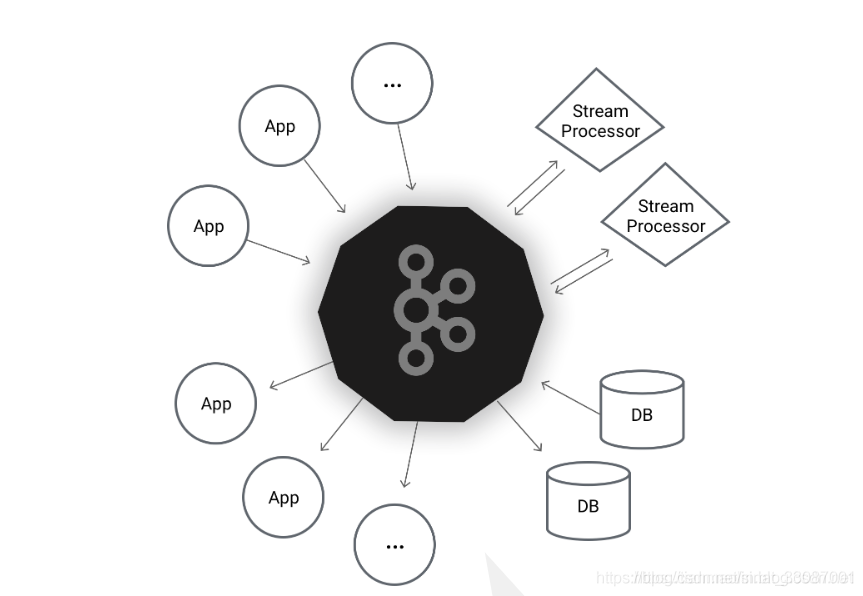
訊息佇列模型-生產者消費者模型
在正式介紹Kafka之前,先來了解下什么是生產者消費者模式,以及什么是訊息佇列,再由訊息佇列聊到Kafka,
生產者消費者模型具體來講,就是在一個系統中,存在生產者和消費者兩種角色,他們通過記憶體緩沖區進行通信,生產者生產消費者需要的資料,消費者把資料做成產品,可以理解為生產者不停的生產饅頭,然后把饅頭扔到筐里,消費者不停的從筐里拿出饅頭吃,具體到訊息系統可以這么理解:
- 生產者:訊息的制造者,生產饅頭的一方
- 管道容器:訊息的傳遞者,也就是放饅頭的筐
- 消費者:訊息的消費者,也就是吃饅頭的一方
其中最重要的環節就是這個管道容器,其實就是一個訊息佇列
訊息佇列的應用場景
訊息佇列具有低耦合、可靠投遞、廣播、流量控制、最終一致性等一系列功能,成為異步RPC的主要手段之一,那么為什么要使用佇列呢?我這么理解:
- 1,在分布式高并發場景下,如何保證系統性能不受影響,請求不會超時中斷并且能讓用戶無感知(削峰、減少回應所需時間),一般網站回應時間超過200ms就難以忍受了,高并發同步向資料庫內寫資料,資料庫會扛不住壓力的,而且回應速度也會明顯減慢,
- 2,不同系統之間的異步通信如何實作( 降低系統耦合性),一個系統必然有很多模塊組成,不同模塊各自有實作,各自有自己的迭代,如果耦合性低,不存在強依賴,那最好了,微服務架構的思想也類似此,降低耦合性,
第一個場景下,例如有個業務:下班打車,企業滴滴,晚上8點半上地這邊爆滿,各種打車訂單同時涌入系統,系統要爆,加上訊息佇列后,訂單進入訊息佇列,然后反饋給用戶訂單在處理,然后按照入隊順序一個個處理該訊息,直到消費到該訊息訂單后才將訂單入庫,當然這個時候才能反饋給用戶說打車成功,這樣有效的抵抗了峰值時間的沖擊,
第二個場景下,系統的不同模塊之間各自有各自的實作,模塊之間不存在直接呼叫,那么新增模塊或者修改模塊就對其他模塊影響較小,所以如果有個訊息系統在中間作為中轉,訊息發送者將訊息發送至分布式訊息佇列即結束對訊息的處理,訊息接受者從分布式訊息佇列獲取該訊息后進行后續處理,并不需要知道該訊息從何而來,對新增業務,只要對該類訊息感興趣,即可訂閱該訊息,對原有系統和業務沒有任何影響,從而實作網站業務的可擴展性設計,
訊息佇列模型
訊息佇列目前有兩種協議:JMS和AMQP,JMS輕量不能跨平臺,AMQP性能強但是復雜,感覺就是美圖秀秀和PS的區別,但是大家用的多的還是美圖秀秀,那么就以JMS為主吧,咱就好好用輪子吧,
1 點到點(P2P)模型
使用佇列(Queue)作為訊息通信載體:滿足生產者與消費者模式,一條訊息只能被一個消費者使用,未被消費的訊息在佇列中保留直到被消費或超時,
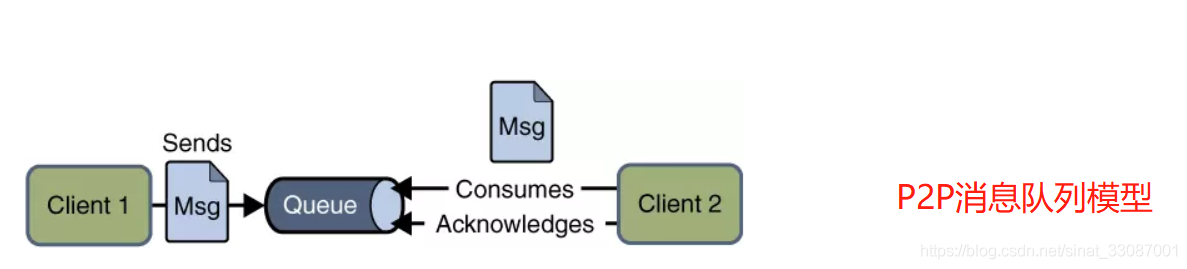
假如我們存在這樣?種情況:我們需要將?產者產?的訊息分發給多個消費者,并且每個消費者都能接收到完全的訊息內容,這種情況,佇列模型就不好解決了
2 發布/訂閱(Pub/Sub)模型
發布訂閱模型(Pub/Sub) 使用主題(Topic)作為訊息通信載體,類似于廣播模式,發布者發布一條訊息,該訊息通過主題傳遞給所有的訂閱者,一條訊息可以被多個消費者使用,
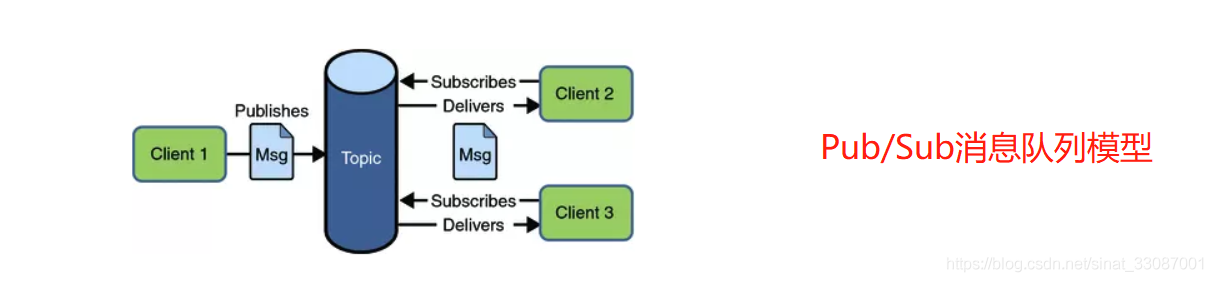
在一條訊息廣播之后才訂閱的用戶則是收不到該條訊息的,在發布 - 訂閱模型中,如果只有?個訂閱者,那它和佇列模型就基本是?樣的了,所以說,發布 - 訂閱模型在功能層?上是可以兼容點到點(P2P)模型的
訊息佇列問題
系統里平白無故加入一個訊息佇列服務器當然會影響系統的整體性能,增加系統的復雜性,還需要擔心異步訊息發送的一致性問,訊息服務器的穩定性等問題:
- 系統可用性降低: 系統可用性在某種程度上降低,在加入MQ之前,不用考慮訊息丟失或者說MQ掛掉等等的情況,但是,引入MQ之后就需要去考慮了
- 系統復雜性提高: 加入MQ之后,需要保證訊息沒有被重復消費、處理訊息丟失的情況、保證訊息傳遞的順序性,訊息服務器有沒有宕機等問題
- 一致性問題: 訊息佇列可以實作異步,異步確實可以提高系統回應速度,但是,萬一訊息的真正消費者并沒有正確消費訊息就會導致資料不一致的情況了,
其實這些問題就是作為一個訊息佇列中間件所要面對的挑戰,這個訊息中間件該如何設計才能解決訊息框架可能遇到的一系列問題:故障轉移恢復、資料一致性保證、資料可靠性保證
Kafka基本概念和架構模型
了解了生產者-消費者模型以及訊息佇列模型后,我們知道如果系統需要解耦、削峰,一定要使用訊息佇列,但是訊息佇列存在諸多問題,所以需要一個功能完備的中間件來解決這些問題,
Kafka 是?個分布式流式處理平臺,與大多數訊息系統比較,kafka有更好的吞吐量,內置磁區,副本和故障轉移,kafka流平臺具有三個關鍵功能:
- 訊息佇列【傳遞訊息】:發布和訂閱訊息流,這個功能類似于訊息佇列,這也是 Kafka 也被歸類為訊息佇列的原因,
- 容錯的持久方式存盤記錄訊息流【存盤訊息】: Kafka 會把訊息持久化到磁盤,有效避免了訊息丟失的?險·,
- 流式處理平臺【處理訊息】: 在訊息發布的時候進?處理,Kafka 提供了?個完整的流式處理類別庫,
所以Kafka 主要有兩?應?場景:首先基于傳遞和存盤訊息的有效和可靠性,kafka可以建?實時流資料管道,以可靠地在系統或應?程式之間獲取資料,其次基于處理訊息資料流的完備能力,kafka可以構建實時的流資料處理程式來轉換或處理資料流,
Kafka架構模型
看了那么多的Kafka的優點,那么相信各位對Kafka的實作架構有了一些好奇,下圖為一個Kafka的基本架構圖,接下來我會對其中的概念分點詳述并舉例說明
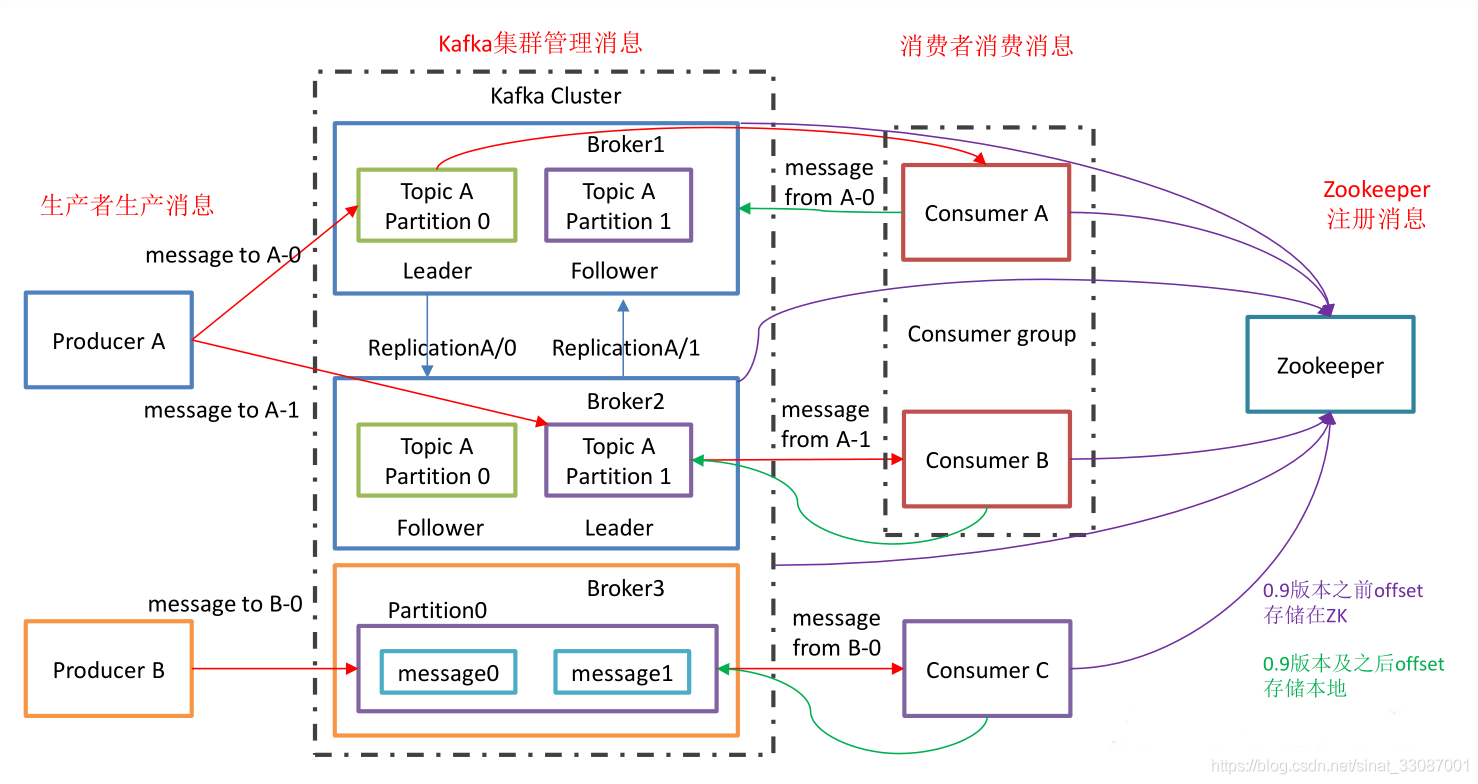
1 Producer(生產者):負責發布訊息到Kafka broker,就是向kafka broker發訊息的客戶端,
2 主題和磁區:一個主題包含一個或多個Partition
- Topics(主題): 屬于特定類別的訊息流稱為主題, 資料存盤在主題中,主題被拆分成磁區, 對于每個主題,Kafka保存一個磁區的資料, 每個這樣的磁區包含不可變有序序列的訊息, 磁區被實作為具有相等大小的一組分段檔案,(物理上不同Topic的訊息分開存盤,邏輯上一個Topic的訊息雖然保存于一個或多個broker上但用戶只需指定訊息的Topic即可生產或消費資料而不必關心資料存于何處),也可以理解為一個佇列,通過對訊息指定主題可以將訊息分類,消費者可以只關注自己需要的Topic中的訊息,
- Partition(磁區),Parition是物理上的概念,每個Topic包含一個或多個Partition,每個Partition包含N個副本,為了實作擴展性,一個非常大的topic可以分布到多個broker(即服務器)上,一個topic可以分為多個partition,每個partition是一個有序的佇列, partition中的每條訊息都會被分配一個有序的id(offset 磁區偏移量),kafka只保證按一個partition中的順序將訊息發給consumer,不保證一個topic的整體(多個partition間)的順序,
- Leader(領導者)【針對某個磁區的Leader副本】: Leader 負責指定磁區的所有讀取和寫入的操作, 每個磁區都有一個服務器充當Leader,
- Follower(追隨者)【針對某個磁區的Follower副本】:跟隨領導者指令的節點被稱為Follower, 如果領導失敗,一個追隨者將自動成為新的領導者, 跟隨者作為正常消費者,拉取訊息并更新其自己的資料存盤, follower從不用來讀取或寫入資料, 它們用于防止資料丟失,
3 Kafka集群和Kafka服務器:一個Kafka集群包含多個Kafka服務器
- Kafka Cluster(Kafka集群):Kafka有多個服務器被稱為Kafka集群, 可以擴展Kafka集群,無需停機, 這些集群用于管理訊息資料的持久性和復制,
- Broker(Kafka服務器):一臺kafka服務器就是一個broker,一個集群由多個broker組成,一個broker可以容納多個topic,
4 Consumer(消費者)和 Consumer Group(消費者集群):一個消費者集群包含多個消費者
- Consumer Group(消費者集群):consumer group是kafka提供的可擴展且具有容錯性的消費者機制,組內可以有多個消費者或消費者實體,它們共享一個公共的group ID,組內的所有消費者協調在一起來共享訂閱主題的所有磁區,
- Consumer(消費者):訊息消費者,向Kafka broker讀取訊息的客戶端,
綜合而言我理解就是,Kafka集群和Kafka服務器屬于物理機器上的概念,而主題和磁區屬于發出去的訊息的分類,一個縱向,一個橫向,一個broker上可以有很多主題的磁區,一個主題也可以在很多broker上放置磁區,是多對多的關系,由于這部分比較難理解,這里我舉個例子:
Kafka概念舉例
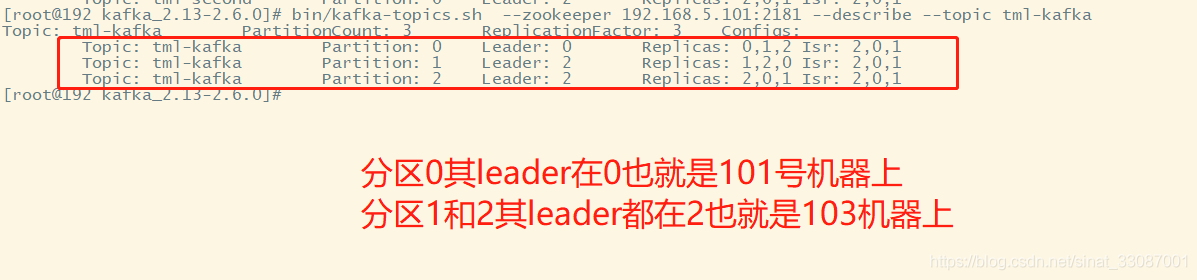
我在有三臺機器【broker的id分別為101、102、103】的Kafka集群上創建了一個主題為tml-kafka的集群,指定副本數為3,查看詳情時第一個行顯示所有partitions的一個總結,以下每一行給出一個partition中的資訊,如果我們只有一個partition,則只顯示一行,
- leader 和follwer都是針對某個磁區的概念,例如對于磁區0,其leader在0也就是broker為101的機器,而對于磁區1和磁區2其leader在2也就是broker為103的機器上
- Replicas 顯示給定partiton所有副本所存盤節點的節點串列,不管該節點是否是leader或者是否存活,這里就是我們的三臺機器、0、1、2,分別對應101、102、103,
- Isr 副本都已同步的的節點集合,這個集合中的所有節點都是存活狀態,并且跟leader同步,這里也是我們的三臺機器、0、1、2,分別對應101、102、103.說明我們三臺機器都在集群里沒有脫機,ISR的概念在后續會提到,
Kafka作業流程和檔案存盤機制
了解了Kafka的基本架構和示例后我們來了解下Kafka到底是怎么作業的,以及訊息是如何在Kafka持久化存盤的,
Kafka的作業流程
通過基礎概念的學習可以知道kafka的訊息分為Topic,而Topic從邏輯上又可以劃分為Partion,關于Topic&Partion需要注意以下幾點:
- 一個 Topic可以認為是一類訊息,每個 topic 將被分成多個 Partion,每個 Partion在存盤層面是 append log 檔案,Kafka 機制中,producer push 來的訊息是追加(append)到 Partion中的,這是一種順序寫磁盤的機制,效率遠高于隨機寫記憶體
- 任何發布到partition 的訊息都會被追加到log檔案的尾部,每條訊息在檔案中的位置稱為 offset(偏移量),offset 為一個 long 型的數字,它唯一標記一條訊息,Kafka只保證Partion內的訊息有序,不能保證全域Topic的訊息有序
- 消費者組中的每個消費者,都會實時記錄自己消費到了哪個 offset,以便出錯恢復時,從上次的位置繼續消費
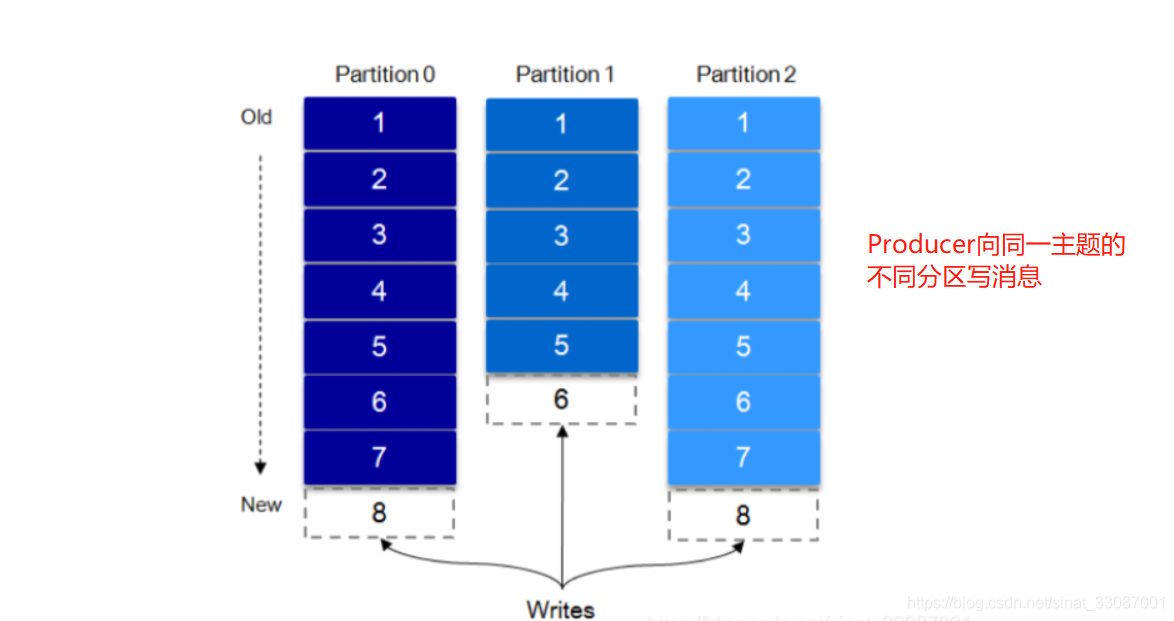
下圖為一個訊息寫入程序,Producer向同一主題的不同磁區寫訊息,也即不停的在各個append log檔案后順序追加訊息,每追加一個append log檔案偏移量加一,只有單append log檔案中有序
整體訊息的生產傳遞和消費的的流程如下圖所示,注意這里偏移量數字從consumer消費的視角來看,無論是生產者還是消費者對訊息的處理都是偏移量從小到大的:
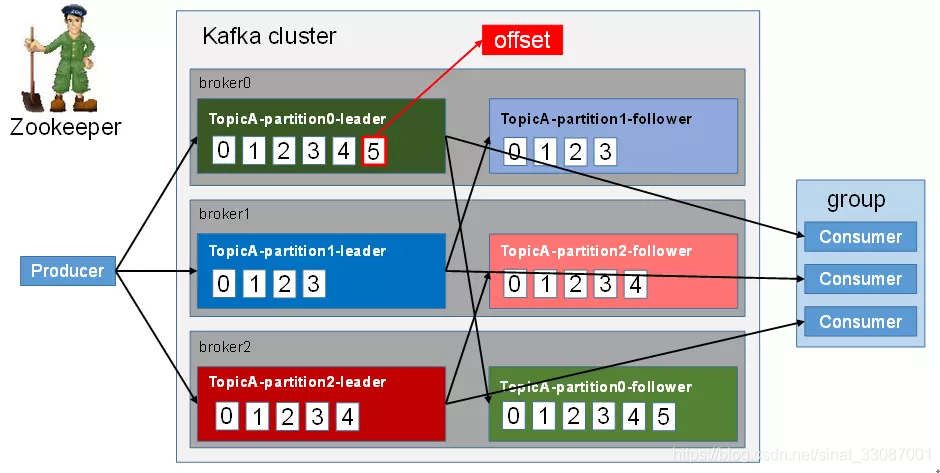
訊息由生產者生產,并發往Kafka集群,Kafka集群獲取到訊息后再發往消費者,以下是Pub-Sub訊息的逐步作業流程 :
- Producer生產者定期向Kafka集群發送訊息,在發送訊息之前,會對訊息進行分類,即Topic, Kafka集群存盤該Topic配置的磁區中的所有訊息, 它確保訊息在磁區之間平等共享, 如果生產者發送兩個訊息并且有兩個磁區,Kafka將在第一磁區中存盤一個訊息,在第二磁區中存盤第二訊息,
- Kafk接收生產者訊息并轉發給消費者,消費者訂閱特定主題,一旦消費者訂閱Topic,Kafka將向消費者提供Topic下磁區的當前offset,并且還將偏移保存在Zookeeper系統中,消費者通過與kafka集群建立長連接的方式,不斷地從集群中拉取訊息,然后可以對這些訊息進行處理,一旦Kafka收到來自生產者的訊息,它將這些訊息轉發給消費者,
- 消費者將收到訊息進行處理,一旦訊息被處理,消費者將向Kafka代理發送確認,消費者需要實時的記錄自己消費到了哪個offset,便于后續發生故障恢復后繼續消費,Kafka 0.9版本之前,consumer默認將offset保存在Zookeeper中,從0.9版本開始,consumer默認將offset保存在Kafka一個內置的topic中 一旦Kafka收到確認,它將offset更改為新值,并在Zookeeper中更新它,
以上流程將重復,直到消費者停止請求,消費者可以隨時回退/跳到所需的主題偏移量,并閱讀所有后續訊息
Kafka檔案存盤機制
我們上文提到每個partion是一個append log 檔案,雖然我們已經把Topic物理上劃分為多個Partion用來負載均衡,但即使是對一個Partition 而言,如果訊息量過大的話也會有堵塞的風險,所以我們需要定期清理訊息,
清理訊息時如果只有一個Partion,那么就得全盤清除,這將對訊息檔案的維護以及已消費的訊息的清理帶來嚴重的影響,所以我們需要在物理上進一步細分Partition
- Kafka以 segment 為單位將 partition 進一步細分,每個 partition(目錄)相當于一個巨型檔案被平均分配到多個大小相等的 segment(段)資料檔案中(每個 segment 檔案中訊息數量不一定相等)
這種特性也方便 old segment 的洗掉,即方便已被消費的訊息的清理,提高磁盤的利用率,每個 partition 只需要支持順序讀寫就行,
Partition&Segment
接下來我們發送一條訊息,看看在物理存盤上是什么樣的,在機器上我們可以看到,一組index和log,這就是一個segment的內容:
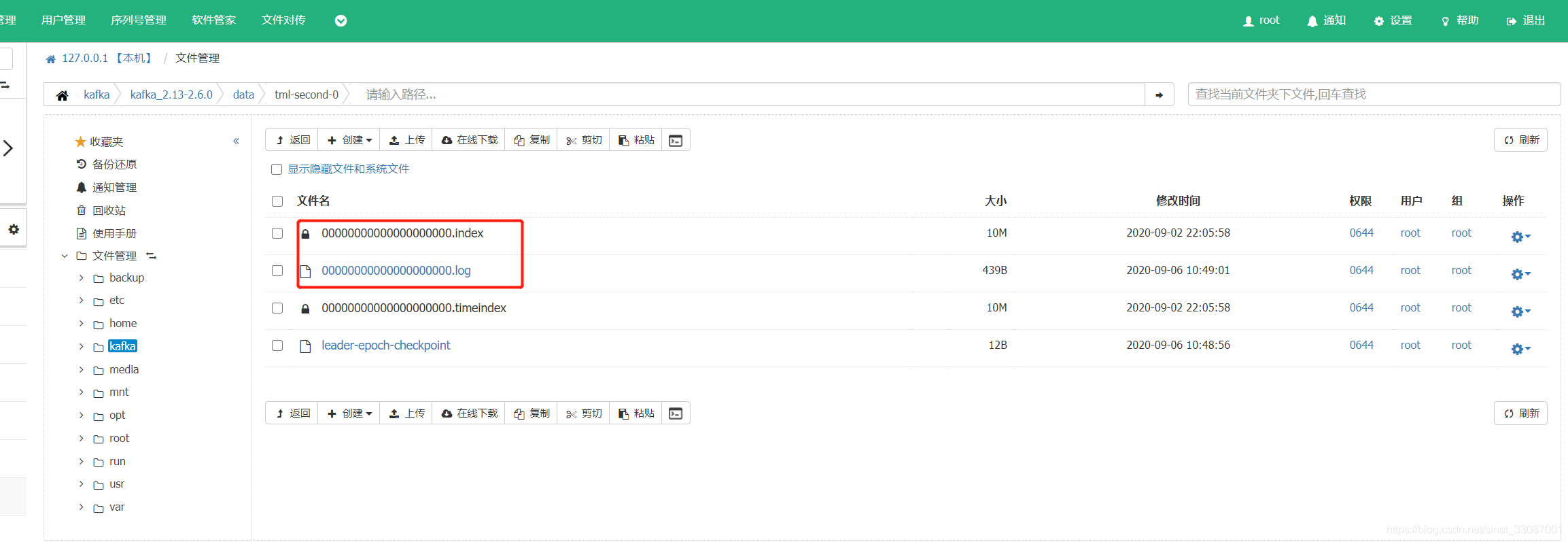
segment 檔案由兩部分組成,分別為 “.index” 檔案和 “.log” 檔案,分別表示為 segment 索引檔案和資料檔案,這兩個檔案的命令規則為:partition 全域的第一個 segment 從 0 開始,后續每個 segment 檔案名為上一個 segment 檔案最后一條訊息的 offset 值,數值大小為 64 位,20 位數字字符長度,沒有數字用 0 填充,我這里只有一條資料,所以是從0開始的,整體的存盤架構如下:
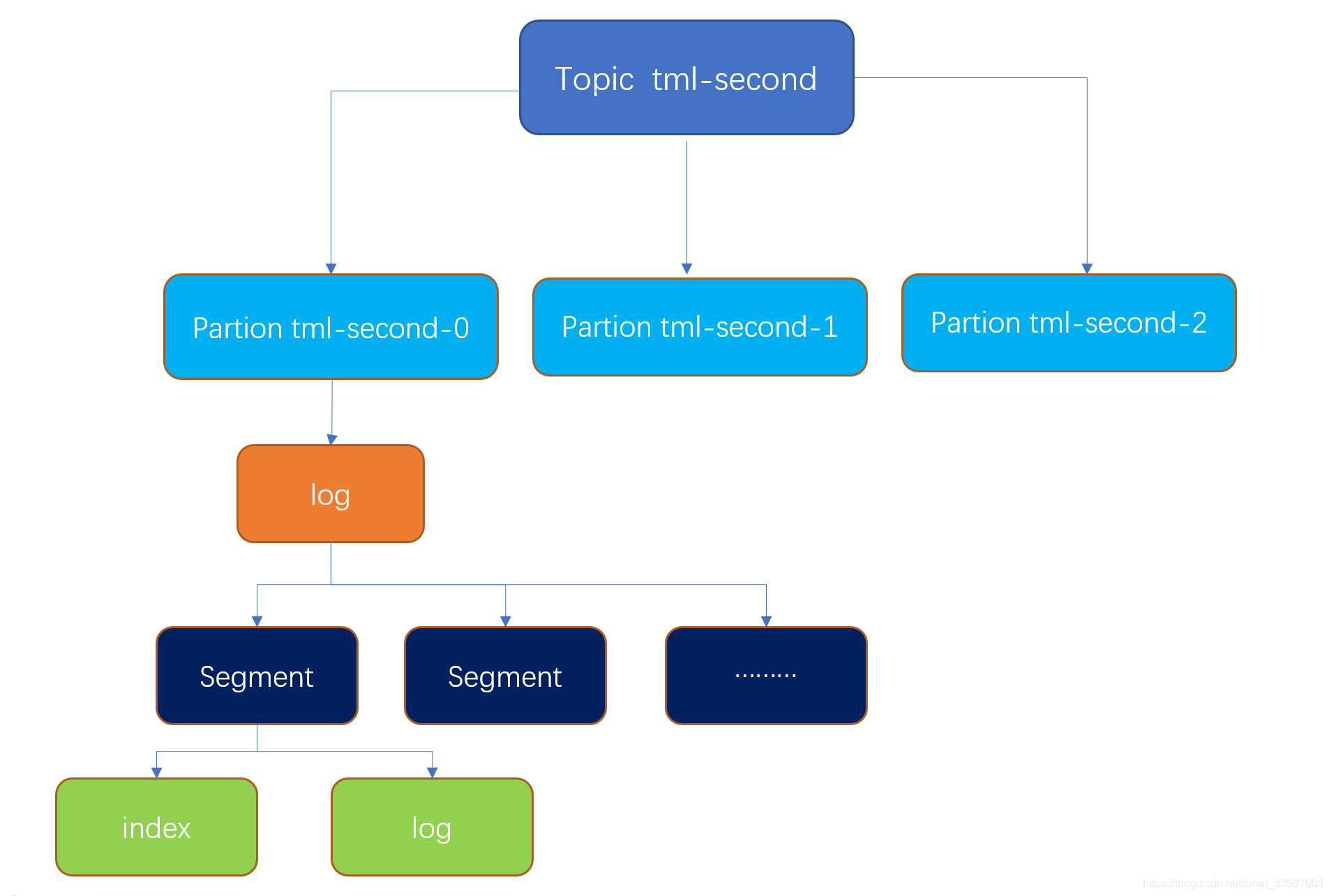
Segment存盤結構
通過以上對Segment落盤檔案的了解,我們基本搞清楚了Segment的結構,當然我這里是單segment,看不出來,這里從網上找了一個大量檔案的示例:
//第一段segment,起始位置為0
00000000000000000000.index
00000000000000000000.log
//第二段segment,起始位置為170410
00000000000000170410.index
00000000000000170410.log
//第三段segment,起始位置為239430
00000000000000239430.index
00000000000000239430.log
以上面的 segment 檔案為例,展示出 segment:00000000000000170410 的 “.index” 檔案和 “.log” 檔案的對應的關系,如下圖: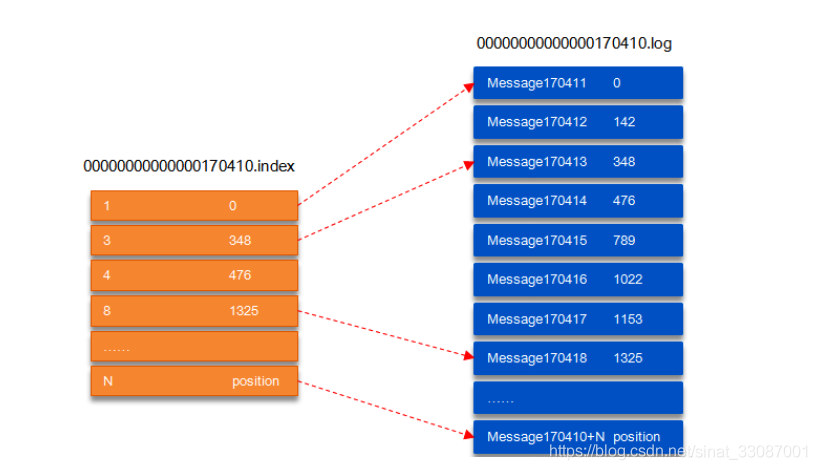
如上圖,“.index” 索引檔案存盤大量的元資料,“.log” 資料檔案存盤大量的訊息,索引檔案中的元資料指向對應資料檔案中 message 的物理偏移地址,其中以 “.index” 索引檔案中的元資料 [3, 348] 為例,在 “.log” 資料檔案表示第 3 個訊息,即在全域 partition 中表示 170410+3=170413 個訊息,該訊息的segementoffset為3,全域offset為170413,物理偏移地址為 348(注意此物理偏移地址不是訊息數量的offset,而是訊息的記憶體存盤偏移量 )
快速定位partion中訊息
既然訊息在Partion中被分為了一段段的segment,那么我們如何快速定位訊息的位置,來精準的對訊息進行操作呢?以上圖為例,讀取 offset=170418 的訊息:
- 首先查找 segment 檔案,其中 00000000000000000000.index 為最開始的檔案,第二個檔案為 00000000000000170410.index(起始偏移為 170410+1=170411),而第三個檔案為 00000000000000239430.index(起始偏移為 239430+1=239431),所以這個 offset=170418 就落到了第二個檔案之中,其它后續檔案依次類推,以其偏移量命名并排列這些檔案,然后根據二分查找法就可以快速定位到具體檔案位置,
- 其次根據 00000000000000170410.index 檔案中的170418 -170410=8,得出是該segment 中的第8個訊息,再次依據二分查找法定位到該索引,得到segment內[訊息偏移量,物理偏移量]坐標 [8,1325] 定位到 00000000000000170410.log 檔案中的 1325 的位置進行讀取,
- 找到1325位置后,順序讀取訊息即可,確定讀完本條訊息【本條訊息讀到哪里結束】由訊息的物理結構解決,訊息都具有固定的物理結構,包括:offset(8 Bytes)、訊息體的大小(4 Bytes)、crc32(4 Bytes)、magic(1 Byte)、attributes(1 Byte)、key length(4 Bytes)、key(K Bytes)、payload(N Bytes)等等欄位,可以確定一條訊息的大小,即讀取到哪里截止,
以上就是定位訊息的詳細方法,通過索引的方式,可以在kafka順序寫磁盤的基礎上仍然能快速的找到對應的訊息,
生產者策略:磁區策略、資料可靠性保證、故障轉移機制
前面提到訊息系統的三大問題: 系統可用性降低,系統復雜性提高,資料一致性問題,為了解決這些問題,Kafka支持一些機制,例如:
- 使用磁區策略來提高系統可用性和進行負載均衡【高可擴展】
- 使用ACK應答機制來保障資料的可靠性【副本同步策略、ISR、Exactly Once語意】保證的一系列策略來解決系統復雜性問題,例如保證訊息的不重不漏【高并發】
- 使用故障轉移機制【HW&LEO概念、故障同步機制、Leader選舉】來保證訊息的資料一致性,防止意外宕機丟資料導致不一致【高可用】
接下來就這三個機制以及其附加的策略來進行詳細的討論,
生產者磁區策略
Kafka 每個 topic 的 partition 有 N 個副本(replicas),其中 N(大于等于 1)是 topic 的復制因子(replica fator)的個數,Kafka 通過多副本機制實作故障自動轉移,當 Kafka 集群中出現 broker 失效時,副本機制可保證服務可用,對于任何一個 partition,它的 N 個 replicas 中,其中一個 replica 為 leader,其他都為 follower,leader 負責處理 partition 的所有讀寫請求,follower 則負責被動地去復制 leader 上的資料,
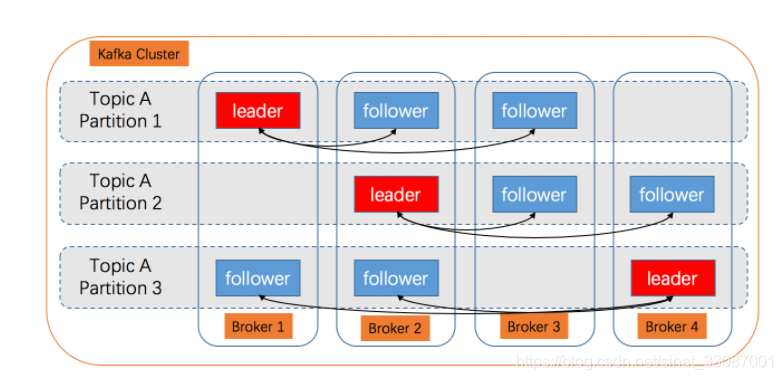
磁區的原因
為什么要磁區呢?對于分布式系統的三高我們已經很熟悉了,我們再來強調一下:
- 高可擴展:方便在集群中擴展,每個 Partition 可以通過調整以適應它所在的機器,而一個 topic,又可以有多個 Partition 組成,因此整個集群就可以適應任意大小的資料了
- 高并發:可以提高并發,因為可以以 Partition 為單位讀寫了,可以并發的往一個Topic的多個Partion中發送訊息
- 高可用:當然有了高可用和高可擴展了,我們還希望整個集群穩定,并發的情況下訊息不會有丟失現象,為了保證資料的可靠性,我們每個磁區都有多個副本來保證不丟訊息,如果 leader 所在的 broker 發生故障或宕機,對應 partition 將因無 leader 而不能處理客戶端請求,這時副本的作用就體現出來了:一個新 leader 將從 follower 中被選舉出來并繼續處理客戶端的請求
如上圖所示展示的,我們分布式集群的特性才能體現出來,其實不光是Kafka,所有的分布式中間件,都需要滿足以上的特性,
磁區的原則
producer 采用 push 模式將訊息發布到 broker,每條訊息都被 append 到 patition 中,屬于順序寫磁盤(順序寫磁盤效率比隨機寫記憶體要高,保障 kafka 吞吐率),producer 發送訊息到 broker 時,既然磁區了,我們怎么知道生產者的訊息該發往哪個磁區呢?producer 會根據磁區演算法選擇將其存盤到哪一個 partition,

從代碼結構里我們可以看到實際上可以歸納為三種方法,也就是三種路由機制,決定訊息被發往哪個磁區,分別是:
- 指明 partition 的情況下,直接將指明的值直接作為 partiton 值;
- 沒有指明 partition 值但有 key 的情況下,將 key 的 hash 值與 topic 的 partition數進行取余得到 partition 值
- 既沒有 partition 值又沒有 key 值的情況下,第一次呼叫時隨機生成一個整數(后面每次呼叫在這個整數上自增),將這個值與 topic 可用的 partition 總數取余得到 partition值,也就是常說的 round-robin 演算法【輪詢演算法】,
可以說磁區策略對于Kafka來說是三高機制的基礎,有了磁區才能實作Kafka的高可擴展,在這樣的構建模型之上我們來看看基于磁區機制,Kafka如何實作資料可靠性【高并發】和故障轉移【高可用】,
ACK應答機制
為保證 producer 發送的資料,能可靠的發送到指定的 topic,topic 的每個 partition 收到producer 發送的資料后,都需要向 producer 發送 ack(acknowledgement 確認收到),如果producer 收到 ack,就會進行下一輪的發送,否則重新發送資料,
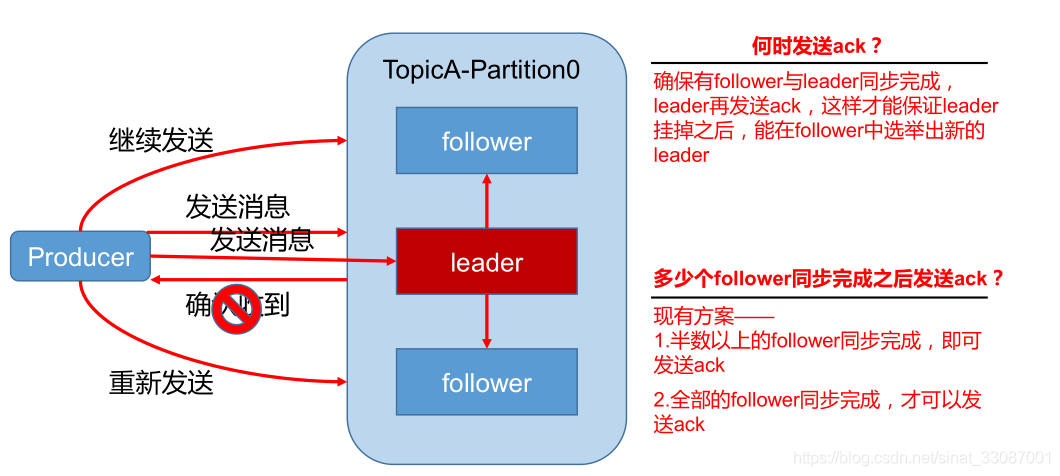
那么基于此,因為在Kafka集群中一個磁區會存在多個副本,leader負責讀寫,但同時需要把訊息可靠的同步,防止訊息丟失和遺漏或者重復,基于性能考慮,同時存在多種ACK應答機制,
Kafka 為用戶提供了三種可靠性級別,用戶根據對可靠性和延遲的要求進行權衡,當 producer 向 leader 發送資料時,可以通過 request.required.acks 引數來設定資料可靠性的級別:
-
request.required.acks = 0,producer 不停向leader發送資料,而不需要 leader 反饋成功訊息,這種情況下資料傳輸效率最高,但是資料可靠性確是最低的,可能在發送程序中丟失資料,可能在 leader 宕機時丟失資料,【傳輸效率最高,可靠性最低】
-
request.required.acks = 1,這是默認情況,即:producer 發送資料到 leader,leader 寫本地日志成功,回傳客戶端成功;此時 ISR 中的其它副本還沒有來得及拉取該訊息,如果此時 leader 宕機了,那么此次發送的訊息就會丟失,【傳輸效率中,可靠性中】
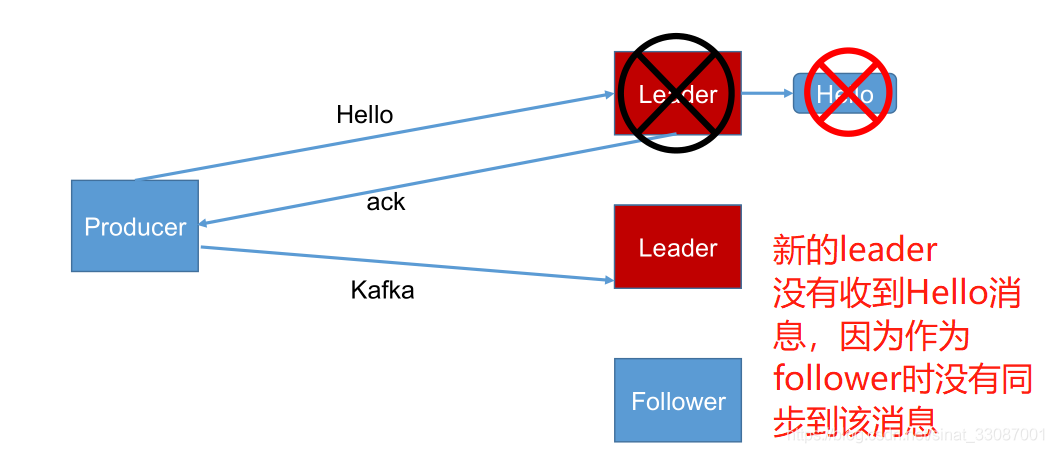
-
request.required.acks = -1(all),producer 發送資料給 leader,leader 收到資料后要等到 ISR 串列中的所有副本都同步資料完成后(強一致性),才向生產者回傳成功訊息,如果一直收不到成功訊息,則認為發送資料失敗會自動重發資料,這是可靠性最高的方案,當然,性能也會受到一定影響,【傳輸效率低,可靠性高】,同時如果在 follower 同步完成后,broker 發送 ack 之前,leader 發生故障,那么會造成資料重復
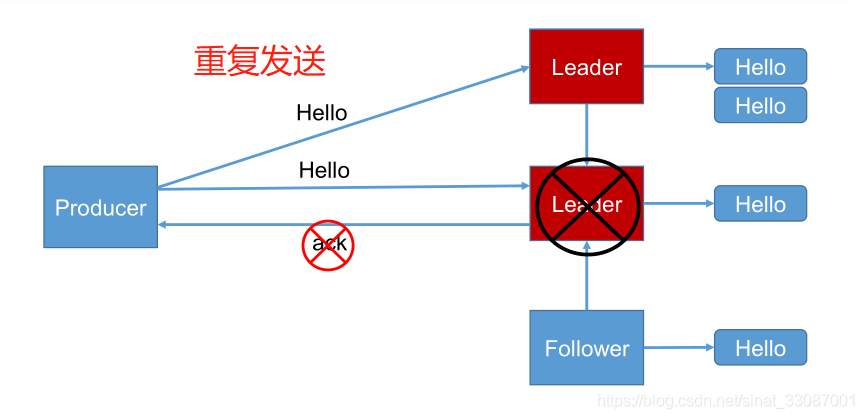
當 request.required.acks = -1時需要注意,如果要提高資料的可靠性,在設定 request.required.acks=-1 的同時,還需引數 min.insync.replicas 配合,如此才能發揮最大的功效,min.insync.replicas 這個引數用于設定 ISR 中的最小副本數,默認值為1,當且僅當 request.required.acks 引數設定為-1時,此引數才生效,當 ISR 中的副本數少于 min.insync.replicas 配置的數量時,客戶端會回傳例外:org.apache.kafka.common.errors.NotEnoughReplicasExceptoin: Messages are rejected since there are fewer in-sync replicas than required,通過將引數 min.insync.replicas 設定為 2,當 ISR 中實際副本數為 1 時(只有leader),將無法保證可靠性,因為如果發送ack后leader宕機,那么此時該條訊息就會被丟失,所以應該拒絕客戶端的寫請求以防止訊息丟失,在-1策略下有三個問題單獨討論一下:
副本同步策略
我們知道當 request.required.acks=-1時需要ISR中的全部副本都同步完成,才回傳ACK,但是其實在最終確定這個方案之前還有一些別的方案,討論核心是那么到底多少foller副本同步完成,才發送ack呢?

現有的兩種方案我們選擇了第二種,第一種占用的機器資源過多,造成了大量的資料冗余,而網路延遲對于Kafka的影響并不大,
ISR選舉策略
采用全量副本同步方案后,我們發送ack的時機確定如下:leader 收到資料,所有 follower 都開始同步資料,但是設想如下情況:有一個 follower,因為某種故障,遲遲不能與 leader 進行同步,那 leader 就要一直等下去,直到它完成同步,才能發送 ack,這個問題怎么解決呢?我們引入ISR的概念
- 所有的副本(replicas)統稱為 Assigned Replicas,即 AR
- ISR 是 AR 中的一個子集,由 leader 維護 ISR串列,follower 從 leader 同步資料有一些延遲(由引數 replica.lag.time.max.ms 設定超時閾值),超過閾值的 follower 將被剔除出 ISR, 存入 OSR(Outof-Sync Replicas)串列,新加入的 follower 也會先存放在 OSR 中
- AR=ISR+OSR,也就是所有副本=可用副本+備用副本,
- ISR串列包括:leader + 與leader保持同步的followers,Leader 發生故障之后,會從 ISR 中選舉新的 leader
在這種機制下,ISR始終是動態保持穩定的集群,訊息來了之后,leader先讀取,然后推送到各個follwer里,保證ISR中各個副本處于同步狀態,只要所有ISR中的follwer都同步完成即可發布ACK,leader掛掉后,立即能從ISR中選舉新的leader來處理訊息,
Exactly Once語意
對于一些非常重要的資訊,消費者要求資料既不重復也不丟失,即 Exactly Once 語意,其實以上討論的三種策略可以如此歸類語意:
- 將服務器 ACK 級別設定為 0,可以保證生產者每條訊息只會被發送一次,即 At Most Once 語意,極容易丟失資料,
- 將服務器 ACK 級別設定為 1,可以理解為碰運氣語意,正常情況下,leader不宕機且剛好宕機前將資料同步給了副本的話不會丟失資料,其它情況就會造成資料的丟失,
- 將服務器的 ACK 級別設定為-1,可以保證 Producer 到 Server 之間不會丟失資料,即 At Least Once 語意,At Least Once 可以保證資料不丟失,但是不能保證資料不重復
顧名思義,我們一定是需要在不丟資料的基礎上去去重,在 0.11 版本以前的 Kafka,對此是無能為力的,只能保證資料不丟失,再在下游消費者對資料做全域去重,對于多個下游應用的情況,每個都需要單獨做全域去重,這就對性能造成了很大影響,
冪等性【partion Exactly Once】
0.11 版本的 Kafka,引入了一項重大特性:冪等性,所謂的冪等性就是指 Producer 不論向 Server 發送多少次重復資料,Server 端都只會持久化一條,冪等性結合 At Least Once 語意,就構成了 Kafka 的 Exactly Once 語意,即:At Least Once + 冪等性 = Exactly Once
要啟用冪等性,只需要將 Producer 的引數中 enable.idompotence 設定為 true 即可,Kafka的冪等性實作其實就是將原來下游需要做的去重放在了資料上游,開啟冪等性的 Producer 在初始化的時候會被分配一個 PID,發往同一 Partition 的訊息會附帶 Sequence Number,而Broker 端會對<PID, Partition, SeqNumber>做快取,當具有相同主鍵的訊息提交時,Broker 只會持久化一條,但是 PID 重啟就會變化,同時不同的 Partition 也具有不同主鍵,所以冪等性無法保證跨磁區跨會話的 Exactly Once,
生產者事務【topic Exactly Once】
為了實作跨磁區跨會話的事務以及防止PID重啟造成的資料重復,需要引入一個Topic全域唯一的 Transaction ID,并將 Producer獲得的PID和Transaction ID系結,這樣當Producer重啟后就可以通過正在進行的TransactionID 獲得原來的 PID,為了管理 Transaction,Kafka 引入了一個新的組件 Transaction Coordinator,Producer 就是通過和 Transaction Coordinator 互動獲得 Transaction ID 對應的任務狀態TransactionCoordinator 還負責將事務所有寫入 Kafka 的一個內部 Topic,這樣即使整個服務重啟,由于事務狀態得到保存,進行中的事務狀態可以得到恢復,從而繼續進行,
故障轉移機制
在資料可靠性保障策略中我們了解到如何通過磁區和副本,以及動態的ISR和ACK機制來確保訊息的可靠,那么接下來深入探討下,故障發生的時候,我們如何將集群恢復正常?首先需要明確兩個概念:LEO和HW:
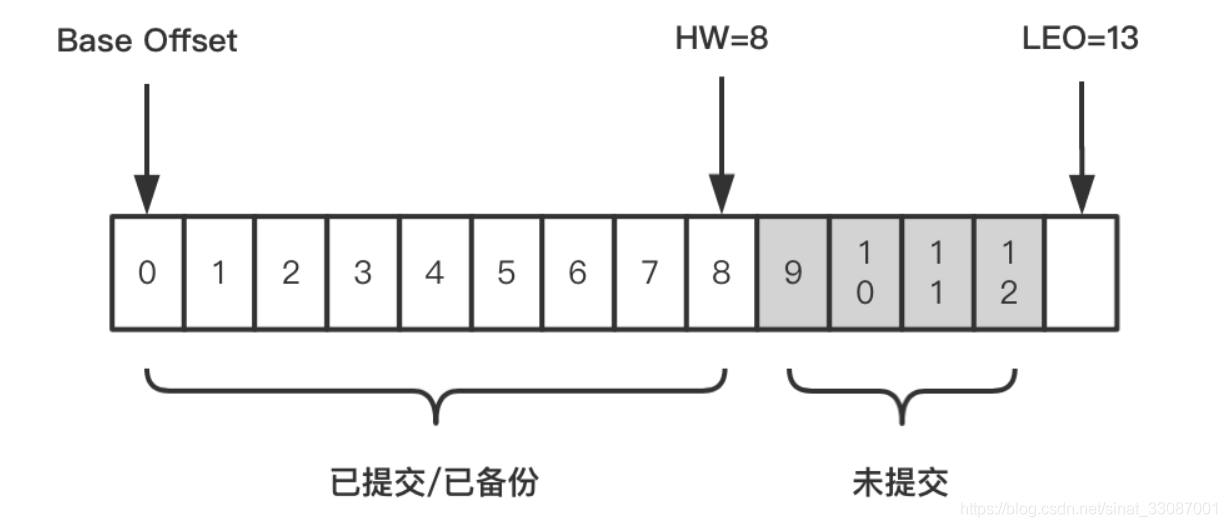
- Base Offset:是起始位移,該副本中第一條訊息的offset,如下圖,這里的起始位移是0,如果一個日志檔案寫滿1G后(默認1G后會log rolling),這個起始位移就不是0開始了,
- HW(high watermark):副本的高水印值,replica中leader副本和follower副本都會有這個值,通過它可以得知副本中已提交或已備份訊息的范圍,leader副本中的HW,決定了消費者能消費的最新訊息能到哪個offset,如下圖所示,HW值為8,代表offset為[0,8]的9條訊息都可以被消費到,它們是對消費者可見的,而[9,12]這4條訊息由于未提交,對消費者是不可見的,注意HW最多達到LEO值時,這時可見范圍不會包含HW值對應的那條訊息了,如下圖如果HW也是13,則消費的訊息范圍就是[0,12],
- LEO(log end offset):日志末端位移,代表日志檔案中下一條待寫入訊息的offset,這個offset上實際是沒有訊息的,不管是leader副本還是follower副本,都有這個值,當leader副本收到生產者的一條訊息,LEO通常會自增1,而follower副本需要從leader副本fetch到資料后,才會增加它的LEO,最后leader副本會比較自己的LEO以及滿足條件的follower副本上的LEO,選取兩者中較小值作為新的HW,來更新自己的HW值,
而leader和副本之間LEO及HW的更新時機如下:
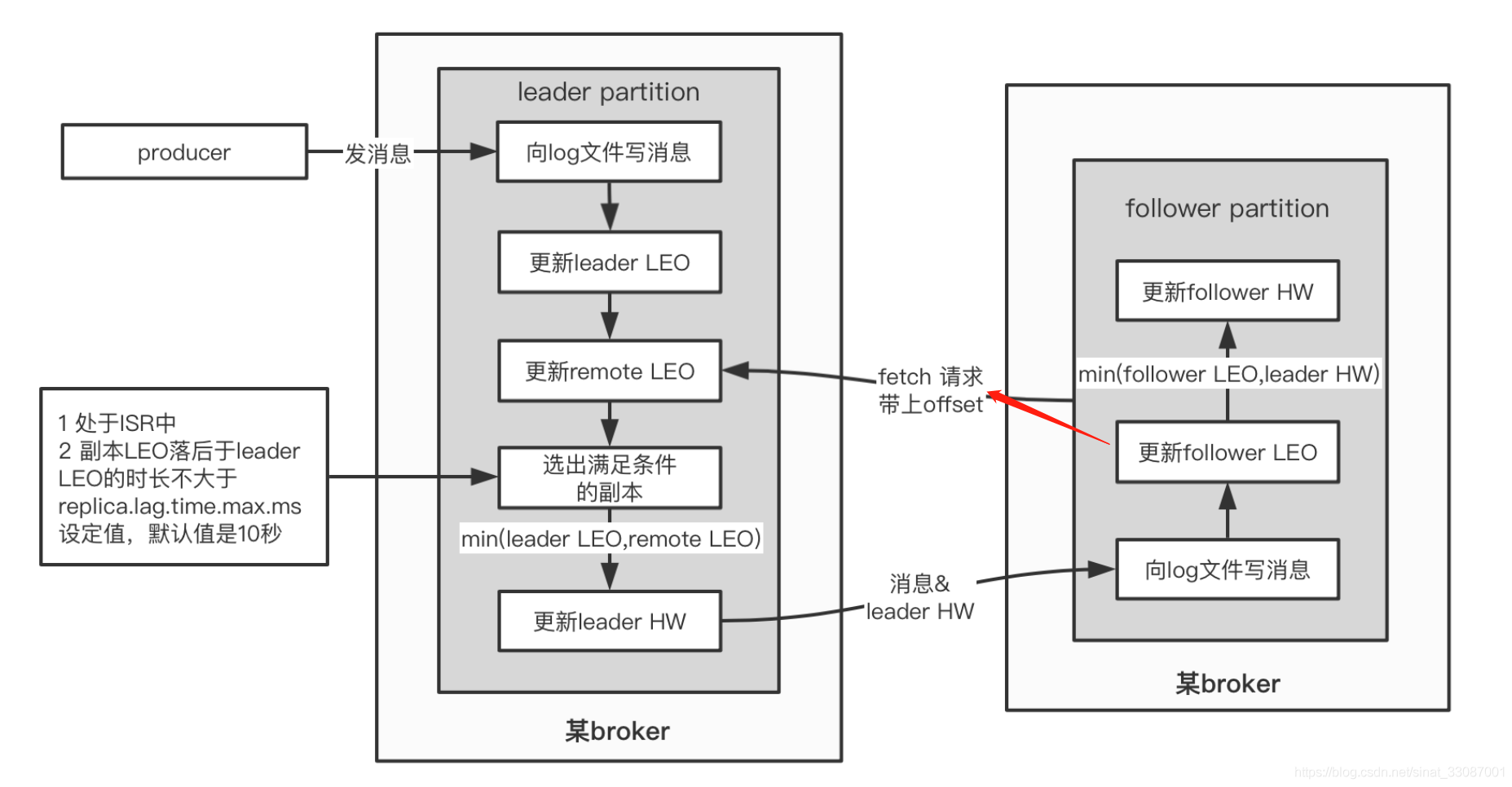
- remote LEO是保存在leader副本上的follower副本的LEO,可以看出leader副本上保存所有副本的LEO,當然也包括自己的,remote LEO是保存在leader副本上的follower副本的LEO,可以看出leader副本上保存所有副本的LEO,當然也包括自己的,
- follower LEO就是follower副本的LEO,它的更新是在follower副本得到leader副本發送的資料并隨后寫入到log檔案,就會更新自己的LEO
HW和LEO在訊息流轉的層面上程序如下,
標準寫入流程
在了解故障轉移機制前,我們先來看看標準的寫入流程是什么樣的,這樣在故障的時候我們可以看到故障發生在哪些節點影響標準寫入流程,以及故障轉移機制如何處理使其恢復正常:
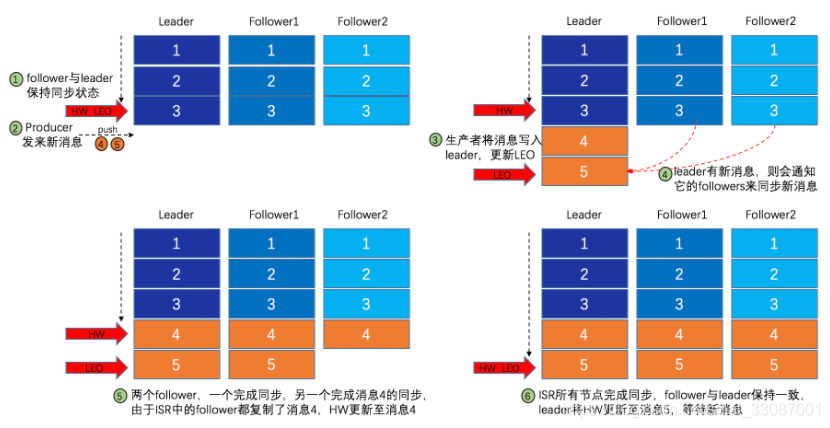
整個程序分為如下幾個步驟
- producer發送訊息4、5給leader【之前提到過只有leader可以讀寫資料】,leader收到后更新自己的LEO為5
- fetch嘗試更新remote LEO,因為此時leader的HW為3,且follower1和follower2的最小LEO也是3,所以remote LEO為3
- leader判讀ISR中哪些副本還和自己保持同步,剔除不能保持同步的follower,得出follower1和follower2都可以
- leader計算自己的HW,取所有磁區LEO的最小值為HW為3
- leader將訊息4、5以及自己的HW發往follower1和follower2,follower1和follower2開始向自己的log寫日志并更新訊息4、5,但是follower1更新的快些,leo為5,而follower2更新的慢些,leo為4
- fetch再次更新remote LEO,取所有follower中的最小LEO為4,然后更新Leader的HW為4
- leader將自己的HW發往follower1和follower2,直到follower2同步完了更新自己的LEO為5,remote LEO為5,leaderHW為5,更新follower2中的HW為5則同步結束
實質上,Leader的HW是所有LEO最短的offset,并且是消費者需要認定的offset,Follower的HW則是Leader的HW和自身LEO取最小值,也就是長度不能超過消費者認定的offsetKafka 的復制機制既不是完全的同步復制,也不是單純的異步復制,
- 同步復制要求所有能作業的 follower 都復制完,這條訊息才會被 commit,這種復制方式受限于復制最慢的 follower,會極大的影響吞吐率,也就是 request.required.acks = -1策略
- 異步復制方式下,follower 異步的從 leader 復制資料,資料只要被 leader 寫入 log 就被認為已經 commit,這種情況下如果 follower 都還沒有復制完,落后于 leader 時,突然 leader 宕機,則會丟失資料,降低可靠性,也就是 request.required.acks = 1策略
而 Kafka 使用request.required.acks = -1 + ISR 的策略則在可靠性和吞吐率方面取得了較好的平衡,同步復制并干掉復制慢的副本,只同步ISR中的Follwer,
故障轉移機制
當不同的機器宕機故障時來看看ISR如何處理集群以及訊息,分為 follower 故障和leader故障:
- follower故障,follower 發生故障后會被臨時踢出 ISR,待該 follower 恢復后,follower 會讀取本地磁盤記錄的上次的 follower HW,并將 log 檔案高于follower HW 的【follower HW一定小于leader HW】部分截取掉,令副本的LEO與故障時的follower HW一致,然后follower LEO 開始從 leader 同步,等該 follower 的 LEO 大于等于該 Partition 的 的 HW【也就是leader的HW】,即 follower 追上 leader 之后,就可以重新加入 ISR 了,你可能會問為什么不從follower的LEO之后開始截呢?試想一下,如果follower故障離場后,leader也故障離場,一個LEO比故障follower的ISR follower當選為新leader,那么故障follower回歸后會比新leader多訊息,這顯然造成了資料不一致,
- leader 故障,leader 發生故障之后,會從 ISR 中選出一個新的 leader之后,為保證多個副本之間的資料一致性,其余的 follower 會先將各自的 log 檔案高于HW【也就是leader的HW】的部分截掉,然后從新的 leader同步資料,如果新leader的LEO就是HW,則直接接收新的訊息即可,如果是其它某個Follower的LEO是HW,則從新Leader同步Leader的LEO-HW之間的訊息給所有副本
總而言之,要以所有副本都同步好的最新的HW為準(這樣可以保證follower的訊息永遠是小于等于leader的),但這只是處理方法,并不能保證資料不重復或者不丟失,我們來看一種資料重復的案例: Leader宕機:考慮這樣一種場景:acks=-1,部分 ISR 副本完成同步,此時leader掛掉,如下圖所示:
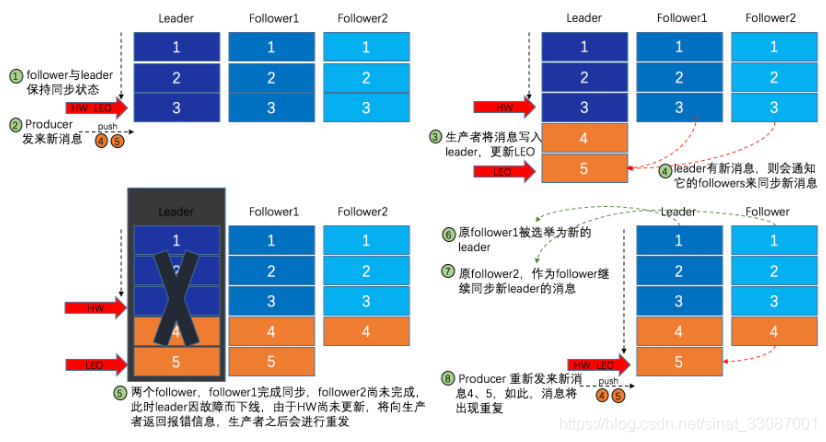
整個程序分為如下幾個步驟
- follower1 同步了訊息 4、5,follower2 同步了訊息 4,HW為4,
- leader宕機,由于還未收到follower2 同步完成的訊息,所以沒有給生產者發送ACK,與此同時 follower1 被選舉為 leader,follower2從follower1開始同步資料,當然如果follower2被選為leader,那么follower就需要截斷自己的訊息5,
- producer未收到ACK,于是重新發送,發送了給了新的leader(老的follower1),但因為follower1其實已經同步了4、5,所以此時來的訊息就是重復訊息,
這樣就出現了資料重復的現象,所以HW&LEO機制只能保證副本之間保持同步,并不能保證資料不重復或不丟失,要想都保證,需要結合ACK機制食用
Leader選舉
在可能發生的故障中,當Leader掛了的時候我們需要選舉新的leader,遵循如下策略:Kafka 在 ZooKeeper 中為每一個 partition 動態的維護了一個 ISR,這個 ISR 里的所有 replica 都與 leader 保持同步,只有 ISR 里的成員才能有被選為 leader 的可能,
當然也有 極端情況:當 ISR 中至少有一個 follower 時(ISR 包括 leader),Kafka 可以確保已經 commit 的訊息不丟失,但如果某一個 partition 的所有 replica 都掛了,自然就無法保證資料不丟失了,這種情況下如何進行 leader 選舉呢?通常有兩種方案:
- 等待 ISR 中任意一個 replica 恢復過來,并且選它作為 leader【高可靠性】,如果一定要等待 ISR 中的 replica 恢復過來,不可用的時間就可能會相對較長,而且如果 ISR 中所有的 replica 都無法恢復了,或者資料丟失了,這個 partition 將永遠不可用,
- 選擇第一個恢復過來的 replica(并不一定是在 ISR 中)作為leader【高可用性】,選擇第一個恢復過來的 replica 作為 leader,如果這個 replica 不是 ISR 中的 replica,那么,它可能并不具備所有已經 commit 的訊息,從而造成訊息丟失,
默認情況下,Kafka 采用第二種策略,即 unclean.leader.election.enable=true,也可以將此引數設定為 false 來啟用第一種策略
Kafka可靠高效原因
Kafka是如何保證高效讀寫資料的呢,有三點支持:分布式讀寫、順序寫磁盤以及零拷貝技術,其實前兩點在之前的blog中也有提到
- 分布式讀寫,我們提到的各種策略都是為了滿足分布式的可靠高效讀寫
- 順序寫磁盤,Kafka 的 producer 生產資料,要寫入到 log 檔案中,寫的程序是一直追加到檔案末端,為順序寫,同樣的磁盤,順序寫能到 600M/s,而隨機寫只有 100K/s,這與磁盤的機械機構有關,順序寫之所以快,是因為其省去了大量磁頭尋址的時間,
- 零拷貝技術,簡單來說就是資料不需要經過用戶態,傳統的檔案讀寫或者網路傳輸,通常需要將資料從內核態轉換為用戶態,應用程式讀取用戶態記憶體資料,寫入檔案 / Socket之前,需要從用戶態轉換為內核態之后才可以寫入檔案或者網卡當中,而Kafka使用零拷貝技術讓資料直接在內核態中進行傳輸,詳細原理可以參照Kafka是如何利用零拷貝提高性能的
通過以上這幾種技術可以實作Kafka的高并發讀寫
消費者策略:消費方式、磁區分配策略、offset的維護
聊完了生產者策略,知道了訊息是如何發送到Kafka集群并且保證不重不漏,以及在故障時如何保證多個副本的資料一致性之后,我們再從消費端來看下,消費者是如何消費訊息的,
兩種消費方式
訊息有兩種方式被投遞,一種是broker推給消費者,一種是消費者從broker拉,這兩種方式各自有優缺點:
- push 模式很難適應消費速率不同的消費者,因為訊息發送速率是由 broker 決定的,它的目標是盡可能以最快速度傳遞訊息,但是這樣很容易造成 consumer 來不及處理訊息,典型的表現就是拒絕服務以及網路擁塞,
- pull 模式則可以根據 consumer 的消費能力以適當的速率消費訊息,pull 模式不足之處是,如果 kafka 沒有資料,消費者可能會陷入回圈中,一直回傳空資料
Kafka 采取的是pull 模式,它可簡化 broker 的設計,consumer 可自主控制消費訊息的速率,同時 consumer 可以自己控制消費:
- 控制消費方式——既可批量消費也可逐條消費,同時還能選擇不同的提交方式從而實作不同的傳輸語意
- 超時回傳機制——Kafka 的消費者在消費資料時會傳入一個時長引數 timeout,如果當前沒有資料可供消費,consumer 會等待一段時間之后再回傳,這段時長即為 timeout
通過pull以及一定的策略可以滿足Kafka的消費訴求,需要注意:
- 如果消費執行緒大于 patition 數量,則有些執行緒將收不到訊息;
- 如果 patition 數量大于消費執行緒數,則有些執行緒多收到多個 patition 的訊息;如果一個執行緒消費多個 patition,則無法保證你收到的topic訊息的順序,而一個 patition 內的訊息是有序的,
這三點需要注意,訊息的消費和磁區個數的關系,
消費者磁區分配策略
一個 consumer group 中有多個 consumer,一個 topic 有多個 partition,所以必然會涉及到 partition 的分配問題,即確定那個 partition 由哪個 consumer 來消費,Kafka 有三種分配策略: RoundRobin, Range,Sticky,,
- 目前我們還不能自定義磁區分配策略,只能通過partition.assignment.strategy引數選擇 range 或 roundrobin,partition.assignment.strategy引數默認的值是range
- 同一個組內同一磁區只能被一個消費者消費,可以理解,如果一個組內多個消費者消費同一個磁區,那么該消費者組如何保證單磁區訊息的順序性呢?
無論是哪種策略,當消費者組里的消費者個數的變化【增多或減少】或者訂閱主題磁區的增加都會觸發重新分配,這種將磁區的所有權從一個消費者移到另一個消費者稱為重新平衡(rebalance)**
Rang策略
Range分配策略是面向每個主題的,首先會對同一個topic里面的磁區按照序號進行排序,并把消費者執行緒按照字母順序進行排序,然后用磁區數除以消費者執行緒數量來判斷每個消費者執行緒消費幾個磁區,如果除不盡,那么前面幾個消費者執行緒將會多消費一個磁區,當然,這樣的缺點就是對每個組內的每個消費者分布不均勻,舉例如下:
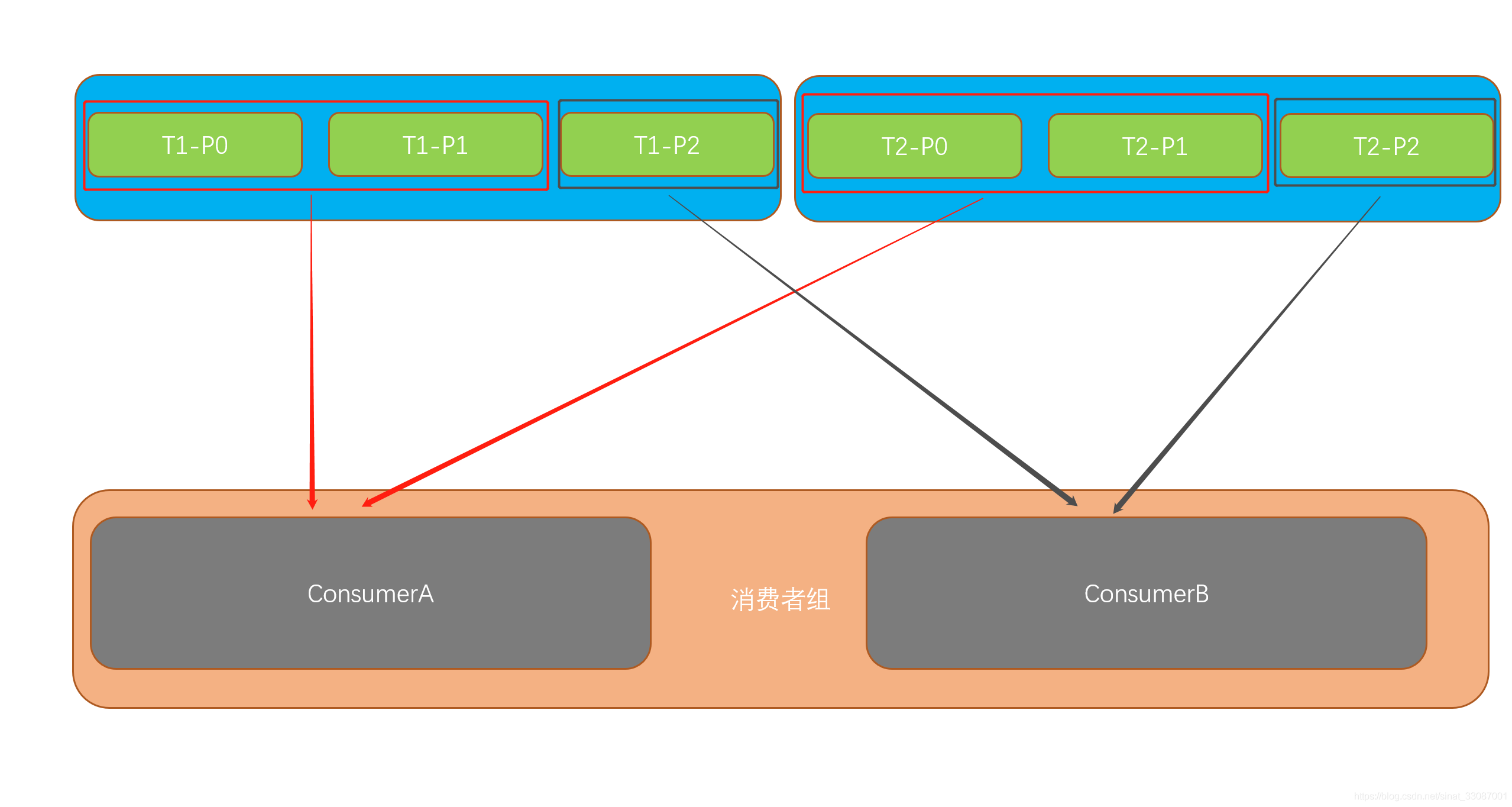
這樣ConsumerA承受的壓力會越來越大,區域打散【計算后順序整體分,不是輪詢分】,每個topic的區域壓力都會壓向消費者組中的某個消費者
RoudRobin策略
RoudRobin策略也即輪詢策略,RoundRobin策略的原理是將消費組內所有消費者以及消費者所訂閱的所有topic的partition按照字典序排序,然后通過輪詢演算法逐個將磁區以此分配給每個消費者:
- 如果同一消費組內,所有的消費者訂閱的訊息都是相同的【也就是所有消費者訂閱的topic數量相同】,那么 RoundRobin 策略的磁區分配會是均勻的,
- 如果同一消費者組內,所訂閱的訊息是不相同的,那么在執行磁區分配的時候,就不是完全的輪詢分配,有可能會導致磁區分配的不均勻,如果某個消費者沒有訂閱消費組內的某個 topic,那么在分配磁區的時候,此消費者將不會分配到這個 topic 的任何磁區,
這樣的好處是,分配較為均衡,
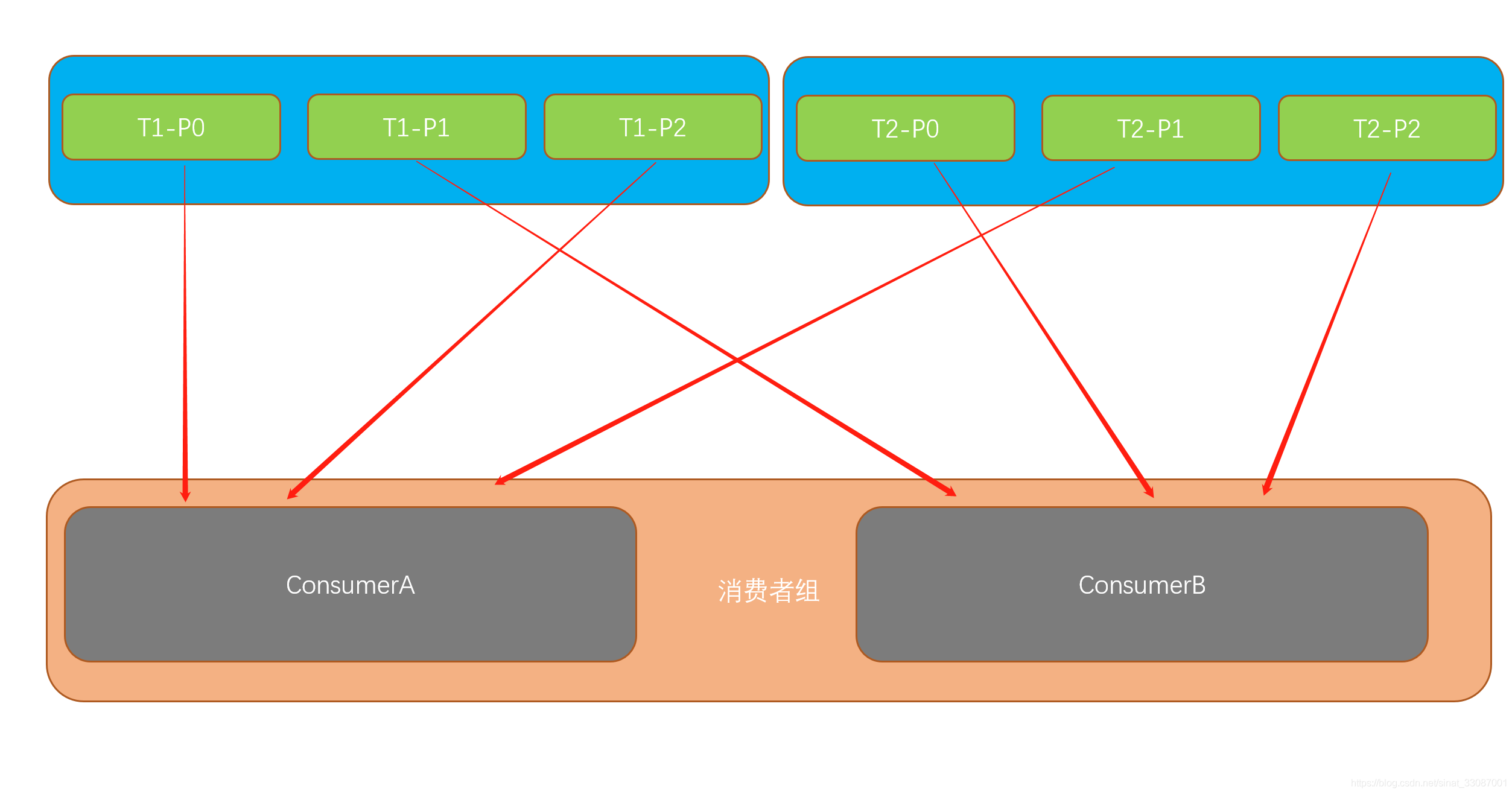
當然前提是同一個消費者組里的每個消費者訂閱的主題必須相同,當然也一定是相同的,如果不同也就沒必要放到一個消費組里了,
Sticky策略
這樣的磁區策略是從0.11版本才開始引入的,它主要有兩個目的
- 磁區的分配要盡可能的均勻,分配給消費者者的主題磁區數最多相差一個
- 磁區的分配要盡可能與上次分配的保持相同
舉例進行分析:比如有3個消費者(C0,C1,C2),都訂閱了2個主題(T0 和 T1)并且每個主題都有 3 個磁區(p0、p1、p2),那么所訂閱的所有磁區可以標識為T0p0、T0p1、T0p2、T1p0、T1p1、T1p2,此時使用Sticky分配策略后,得到的磁區分配結果和RoudRobin相同:

但如果這里假設C2故障退出了消費者組,然后需要對磁區進行再平衡操作,如果使用的是RoundRobin分配策略,它會按照消費者C0和C1進行重新輪詢分配,再平衡后的結果如下:

但是如果使用的是Sticky分配策略,再平衡后的結果會是這樣:

雖然觸發了再分配,但是記憶了上一次C0和C1的分配結果,這樣的好處是發生磁區重分配后,對于同一個磁區而言有可能之前的消費者和新指派的消費者不是同一個,對于之前消費者進行到一半的處理還要在新指派的消費者中再次處理一遍,這時就會浪費系統資源,而使用Sticky策略就可以讓分配策略具備一定的“粘性”,盡可能地讓前后兩次分配相同,進而可以減少系統資源的損耗以及其它例外情況的發生
offset的維護
在現實情況下,消費者在消費資料時可能會出現各種會導致宕機的故障問題,這個時候,如果消費者后續恢復了,它就需要從發生故障前的位置開始繼續消費,而不是從頭開始消費,所以消費者需要實時的記錄自己消費到了哪個offset,便于后續發生故障恢復后繼續消費,Kafka 0.9版本之前,consumer默認將offset保存在Zookeeper中,從0.9版本開始,consumer默認將offset保存在Kafka一個內置的topic中,該topic為 __consumer_offsets :
同一個組里的,當動態擴展磁區分配時新進入的消費者接著消費磁區訊息而不是重新消費,offset是按照:goup+topic+partion來劃分的,這樣保證組內機器有問題時能接著消費
Zookeeper管理
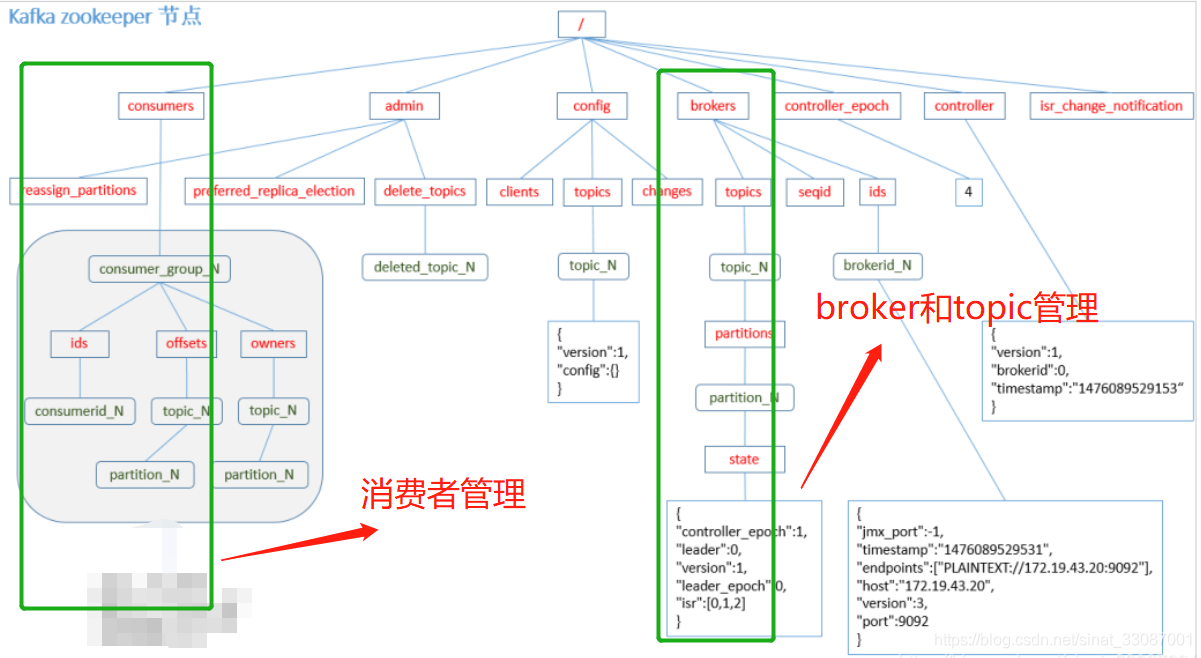
在基于 Kafka 的分布式訊息佇列中,ZooKeeper 的作用有:Producer端注冊及管理、Consumer端注冊及管理以及Kafka集群策略管理 等,
Producer端注冊及管理
在Producer端Zookeeper能夠實作:注冊并動態調整broker,注冊并動態調整topic,Producers負載均衡,
注冊并動態調整Broker
broker是注冊在zookeeper中的,還記得在分布式集群搭建的時候,我們在zk的組態檔中添加的服務節點,就是用來注冊broker的,
- 存放地址:為了記錄 broker 的注冊資訊,在 ZooKeeper 上,專門創建了屬于 Kafka 的一個節點,其路徑為 /brokers
- 創建節點: Kafka 的每個 broker 啟動時,都會到 ZooKeeper 中進行注冊,告訴 ZooKeeper 其 broker.id,在整個集群中,broker.id 應該全域唯一,并在 ZooKeeper 上創建其屬于自己的節點,其節點路徑為
/brokers/ids/{broker.id}; 創建完節點后,Kafka 會將該 broker 的 broker.name 及埠號記錄到該節點; - 洗掉節點:該 broker 節點屬性為臨時節點,當 broker 會話失效時,ZooKeeper 會洗掉該節點,這樣,我們就可以很方便的監控到broker 節點的變化,及時調整負載均衡等,
當然注冊完Broker還需要注冊Topic
注冊并動態調整Topic
在 Kafka 中,所有 topic 與 broker 的對應關系都由 ZooKeeper 進行維護,在 ZooKeeper 中,建立專門的節點來記錄這些資訊,其節點路徑為 /brokers/topics/{topic_name}前面說過,為了保障資料的可靠性,每個 Topic 的 Partitions 實際上是存在備份的,并且備份的數量由 Kafka 機制中的 replicas 來控制,
Producers負載均衡
對于同一個 topic 的不同 partition,Kafka會盡力將這些 partition 分布到不同的 broker 服務器上,這種均衡策略實際上是基于 ZooKeeper 實作的,
- 監聽broker變化,producers 啟動后也要到 ZooKeeper 下注冊,創建一個臨時節點來監聽 broker 服務器串列的變化,由于ZooKeeper 下 broker 創建的也是臨時節點,當 brokers 發生變化時,producers 可以得到相關的通知,從改變自己的 broker list,
- 監聽topic變化,topic 的變化以及broker 和 topic 的關系變化,也是通過 ZooKeeper 的 Watcher 監聽實作的
當broker變化以及topic變化的時候,zookeeper能監聽到,并控制訊息和磁區的分布,
Kafka集群策略管理
除了生產者涉及的管理行為,在我們前面提到的故障轉移機制以及磁區策略等內容中相關的其它管理行為也是由Zookeeper完成的
- 選舉leader,Kafka 為每一個 partition 找一個節點作為 leader,其余備份作為 follower,如果 leader 掛了,follower 們會選舉出一個新的 leader 替代,繼續業務
- 副本同步,當 producer push 的訊息寫入 partition(磁區) 時,作為 leader 的 broker(Kafka 節點) 會將訊息寫入自己的磁區,同時還會將此訊息復制到各個 follower,實作同步,
- 維護ISR,如果某個follower 掛掉,leader 會再找一個替代并同步訊息
所有的這些操作都是Zookeeper做的,
Consumer端注冊及管理
在Consumer端Zookeeper能夠實作:注冊并動態調整Consumer,Consumer負載均衡,
注冊并動態調整Consumer
在消費者端ZooKeeper 做的作業有那些呢?
- 注冊新的消費者分組,當新的消費者組注冊到 ZooKeeper 中時,ZooKeeper 會創建專用的節點來保存相關資訊,其節點路徑為
/consumers/{group_id},其節點下有三個子節點,分別為 [ids, owners, offsets],- ids 節點:記錄該消費組中當前正在消費的消費者,記錄分組下消費者
- owners 節點:記錄該消費組消費的 topic 資訊,
/consumers/[group_id]/owners/[topic]/[broker_id-partition_id],其中,[broker_id-partition_id]就是一個訊息磁區的標識,節點內容就是該 訊息磁區上消費者的Consumer ID,這樣磁區和消費者就能關聯起來了,關聯磁區和消費者 - offsets 節點:記錄每個 topic 的每個磁區offset,在消費者對指定訊息磁區進行訊息消費的程序中,需要定時將磁區訊息的消費進度Offset記錄到Zookeeper上,以便在該消費者進行重啟或者其他消費者重新接管該訊息磁區的訊息消費后,能從之前進度繼續訊息消費,Offset在Zookeeper中由一個專門節點進行記錄,其節點路徑為:
/consumers/[group_id]/offsets/[topic]/[broker_id-partition_id]節點內容就是Offset的值,記錄消費者offset,當然新版本的不記錄在zookeeper中
- 注冊新的消費者,當新的消費者注冊到 Kafka 中時,會在
/consumers/{group_id}/ids節點下創建臨時子節點,并記錄相關資訊, - 監聽消費者分組中消費者的變化,每個消費者都要關注其所屬消費者組中消費者數目的變化,即監聽
/consumers/{group_id}/ids下子節點的變化,一但發現消費者新增或減少,就會觸發消費者的負載均衡,
其實不光是注冊consumer,還包括對消費者策略的管理,例如Consumer負載均衡
Consumer負載均衡
Consumer在啟動時會到 ZooKeeper下以自己的 Consumer-id 創建臨時節點 /consumer/[group-id]/ids/[conusmer-id],并對 /consumer/[group-id]/ids 注冊監聽事件:
- 監聽消費者串列,當消費者發生變化時,同一 group 的其余消費者會得到通知,
- 監聽broker串列,消費者還要監聽 broker 串列的變化,
然后按照我們之前提到的策略進行排序和消費
Kafka框架搭建實戰
好了,在了解了這么多基礎知識以及核心原理之后,我們再來看看真正的實戰場景是如何操作的,我們有如下場景,假設我們要從當前站點發送一個匯出訊息給匯出ESB,由匯出ESB處理業務邏輯來達到解耦的目標該怎么通過Kafka實作呢?
發送訊息
我們發送Kafka訊息的時候,外層的封裝方法如下,需要傳遞一個Kafka的topic、一個用來計算Partition【路由轉發】的標識key【tenantId】,以及需要傳遞的訊息,
public static bool SendKafkaExportData(
string appName,
int tenantId,
int userId,
string metaObjName,
string viewName,
string exportFileName,
SearchCondition condition,
string version = null,
int total = -1,
ExportFileType fileType = ExportFileType.Xlsx,
string applicationContext = null,
string msgTemplate = null)
{
Common.HelperObjects.ArgumentHelper.AssertNotEmpty(appName, nameof (appName));
Common.HelperObjects.ArgumentHelper.AssertNotEmpty(metaObjName, nameof (metaObjName));
Common.HelperObjects.ArgumentHelper.AssertNotEmpty(viewName, nameof (viewName));
Common.HelperObjects.ArgumentHelper.AssertNotEmpty(exportFileName, nameof (exportFileName));
Common.HelperObjects.ArgumentHelper.AssertPositive(tenantId, nameof (tenantId));
Common.HelperObjects.ArgumentHelper.AssertPositive(userId, nameof (userId));
Common.HelperObjects.ArgumentHelper.AssertNotNull<SearchCondition>(condition, nameof (condition));
bool flag = true;
try
{
ExportRequestDataModel exportRequestData = ExportRequestDataModel.GetExportRequestData(appName, tenantId, userId, metaObjName, viewName, exportFileName, condition, version, total, fileType, applicationContext, msgTemplate);
long num = KafkaProducer.Send<ExportRequestDataModel>("TMLSent", tenantId, exportRequestData);
ExportRequestDataModel.logger.Debug((object) string.Format("{0}-{1}-{2}發送Kafka訊息{3}成功", (object) appName, (object) tenantId, (object) userId, (object) num));
}
catch (Exception ex)
{
ExportRequestDataModel.logger.Error((object) string.Format("{0}-{1}-{2}發送Kafka訊息例外", (object) appName, (object) tenantId, (object) userId), ex);
flag = false;
}
return flag;
}
而其中的核心方法: long num = KafkaProducer.Send<ExportRequestDataModel>("TMLSent", tenantId, exportRequestData);的實作邏輯如下,將kafka攜帶的訊息序列化為二進制陣列:
/// <summary>Send a message to a topic.</summary>
/// <param name="topic">The name of the topic to send the message to.</param>
/// <param name="tenant">The id of the tenant the message belongs to.</param>
/// <param name="value">The message content.</param>
/// <returns>The offset of the message.</returns>
public static long Send<T>(string topic, int tenant, T value) where T : IBinarySerializable
{
ArgumentHelper.AssertNotEmpty(topic, nameof (topic));
ArgumentHelper.AssertPositive(tenant, nameof (tenant));
return KafkaProducer.Send(topic, tenant, (object) value == null ? (byte[]) null : BigEndianEncoder.Encode<T>(value));
}
訊息發送機制如下,獲取到需要的topic,用于計算Partition的標識tenantId以及序列化后可以直接發送的二進制字串訊息:
/// <summary>Send a message to a topic.</summary>
/// <param name="topic">The name of the topic to send the message to.</param>
/// <param name="tenant">The id of the tenant the message belongs to.</param>
/// <param name="value">The message content.</param>
/// <returns>The offset of the message.</returns>
public static long Send(string topic, int tenant, byte[] value)
{
ArgumentHelper.AssertNotEmpty(topic, nameof (topic));
ArgumentHelper.AssertPositive(tenant, nameof (tenant));
try
{
return KafkaProtocol.Produce(topic, tenant, value);
}
catch (ConnectionPoolException ex)
{
return KafkaProtocol.Produce(topic, tenant, value);
}
catch (KafkaException ex)
{
if (ex.Error == ErrorCode.NotLeaderForPartition || ex.Error == ErrorCode.LeaderNotAvailable)
return KafkaProtocol.Produce(topic, tenant, value);
throw;
}
}
核心的發送方法為:
public static long Produce(string topic, int tenant, byte[] value)
{
TopicConfig topicConfig = BaseConfig<KafkaMapping>.Instance.GetTopicConfig(topic);
int num = tenant % KafkaProtocol.GetTopicPartitionCount(topic); //計算要發往哪個磁區
int partitionLeader = KafkaProtocol.GetPartitionLeader(topic, num); //獲取磁區leader
try
{
using (KafkaSession kafkaSession = new KafkaSession(topicConfig.Cluster, partitionLeader)) //創建一個kafka訊息發送實體
{
Message message = new Message(value, TimeUtil.CurrentTimestamp);
ProduceRequest request = new ProduceRequest((IDictionary<TopicAndPartition, MessageSet>) new Dictionary<TopicAndPartition, MessageSet>()
{
{
new TopicAndPartition(topic, num), //將設定好的topic和partition傳入引數
new MessageSet(topicConfig.Codecs, (IList<Message>) new List<Message>()
{
message
})
}
}); //設定要發送的訊息
ProduceResponse produceResponse = kafkaSession.Issue<ProduceRequest, ProduceResponse>(request); //發送Kafka訊息并
KafkaProtocol.CheckErrorCode(produceResponse.Error, topic, new int?(num), new int?(tenant));
return produceResponse.Offset;
}
}
catch (Exception ex)
{
KafkaProtocol.RefreshPartitionMetadata(topic);
throw;
}
}
這樣一個我們需要傳遞的訊息就發送到對應的topic和對應的partition上了(不同的partition可以存放在不同 的機器上,這樣取同樣余數的租戶的資料會被放置到相同磁區),無需再自己封裝訊息分發,
消費訊息
在消費者端,機器需要預熱并開啟訊息消費服務,當然也要有關閉訊息服務的方法,開啟消費服務意味著開啟訊息接收和開啟訊息處理執行緒,關閉訊息服務同理表示關閉訊息接收和關閉訊息處理執行緒,
/// <summary>
/// 接識訓出訊息的服務
/// </summary>
public class ReceiveMsgProvider : IReceiveMsgProvider
{
#region 日志、構造方法以及單例
protected static readonly LogWrapper Logger = new LogWrapper();
private ReceiveMsgProvider()
{
}
public static ReceiveMsgProvider Instance { get; } = new ReceiveMsgProvider();
#endregion 日志、構造方法以及單例
#region 開啟訊息接收服務
public bool _ActivateService()
{
// 預熱
Cloud.Plugins.Helper.ESBProxy.WarmUp();
//開啟訊息接收服務
StartMessageService();
//開始處理ExportQueue佇列中的訊息
ExportConsumer.Instance.BeginImportData();
Logger.Debug("_ActivateService was called.");
return true;
}
protected void StartMessageService()
{
try
{
//開始消費訊息
ExportConsumer.Instance.Start();
}
catch (Exception ex)
{
Logger.Error(ex);
}
}
#endregion 開啟訊息接收服務
#region 關閉訊息接收服務
public bool _UnActivateService()
{
//關閉訊息接收服務
StopMessageService();
//關閉處理queue的執行緒
ExportConsumer.CloseQueueThreads();
Logger.Debug("_UnActivateService was called.");
return true;
}
protected void StopMessageService()
{
try
{
//停止消費訊息
ExportConsumer.Instance.Stop();
}
catch (Exception ex)
{
Logger.Error(ex);
}
}
}
其中,開啟和關閉訊息接收服務的核心方法如下:
/// <summary>
/// ESB服務呼叫入口:啟動
/// </summary>
public void Start()
{
_loggging.Debug("ESB服務呼叫入口:啟動");
//開啟一個消費者組實體,這里設定啟用了消費者組來接收訊息,相當于啟動了一個消費者組實體,在OnMessage里去具體寫接收到訊息之后的代碼處理邏輯
_consumer = new KafkaGroupConsumer(ExportKafkaConst.ExportKafkaConsumerGroup, ExportKafkaConst.ExportKafkaTopic, OnMessage);
_consumer .Start();
}
/// <summary>
/// ESB服務呼叫入口:停止
/// </summary>
public void Stop()
{
_loggging.Debug("ESB服務呼叫入口:停止");
if (_consumer != null && _consumer .IsRunning)
{
_consumer .Stop();
}
}
其中消費者的核心實作方法如下:
public KafkaGroupConsumer(string consumerGroup, string topic, Func<Message, bool> handler)
{
ArgumentHelper.AssertNotEmpty(consumerGroup, "consumerGroup"); //消費者組
ArgumentHelper.AssertNotEmpty(topic, "topic"); //消費主題
ArgumentHelper.AssertNotNull(handler, "handler"); //訊息處理函式
_consumerGroup = consumerGroup; //設定消費者組
_topic = topic; //設定topic
_consumerId = GenerateConsumerId(consumerGroup); //按照自定義規則給消費者組內生成一個消費者id
_handler = handler;
ConsumerConfig consumerConfig = BaseConfig<KafkaMapping>.Instance.GetConsumerConfig(consumerGroup);//獲取消費者組配置,例如該組內消費者的重試機制、reblance原則等等消費者組的配置
_context = new ConsumerContext(consumerGroup, topic, _consumerId, consumerConfig, Trace.GetTraceHandler(topic, consumerGroup, handler, newConsumer: true)); //整個消費者的背景關系,包括組的設定,當前id以及呼叫trace鏈路[便于排查問題]
_zooKeeperStateManager = new ZooKeeperStateManager(_context); //將該背景關系注冊到zookeeper中
BaseConfig<KafkaMapping>.ConfigChanged += ReloadConfig; //將消費者變更注冊到Zookeeper,當消費者發生變化時,同一 group 的其余消費者會得到通知
}
使用Kafka實作生產者消費者系統的整體流程就是這樣,
行文至此,已洋洋灑灑3萬5千言,希望能讓你對Kafka有個整體的認知,大家共同進步,與諸君共勉
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/249044.html
標籤:其他