目錄
- 前言
- 文法
- DFA
- NFA
- NFA 轉換為 DFA
- ε-NFA
- 正則運算式
- 圖上作業法
- 泵引理
- 極小化 DFA 演算法
- FA 交集
- CFG,二義性與其化簡
前言
自動機與形式語言通過規范化的文法,邏輯地表示某些字串,此外,通過對串的成分進行分析,同時給出一組狀態與對應的狀態轉移,組成自動機,DFA 和 NFA 是兩種自動機,都能夠判斷某些串是否能夠被接收,走到接收狀態就算接收,
還有三天,,,考完就可以 run 了,好耶!
我只考三門,都覺得復習很吃力,但是別人往往考 10 門,還比我先考,還游刃有余,這令我深刻的認識到:我是啥β
原本打算摸了,但是想到不復習真的可能會掛科,就來更新一下復習筆記了,
注:
因為我上了一學期課,從來沒有認真聽課超過 10 min,作業都是抄別人的
于是這篇復習筆記很可能錯漏百出,并且伴有缺內容,缺重點等等問題
? 請謹慎食用 ?
文法
通過文法可以規范化的表達某種語言(語言就是串的集合),我們通過四元組來表示一個文法:
G = ( V , T , P , S ) G = ( V, T, P, S ) G=(V,T,P,S)
其中 V 是 variable,表示變數,即狀態的集合,
T 是 terminal,終極符,通過一系列的終極符號 T,在不同的變數(V)中進行跳轉,比如 V1 可以通過接收字符 T,從而轉到 V2 狀態,
S 是 start symbol,為文法的開始符號,其中 S 屬于狀態集合 V
P 為 production,即產生式,產生式告訴我們狀態之間的聯系,比如一個狀態 V 可以產生一個字符 0,那么有:
V → 0 V \rightarrow 0 V→0
當然也可以遞回地進行產生,比如產生的結果中,包含自己:
V → 0 V V \rightarrow 0V V→0V
一個規范化的四元組長這樣:
G = ( { A , B } , { 0 , 1 } , { A → 0 , A → 1 A , B → 0 A , B → 1 } , B ) G = (\{A,B\}, \ \{0,1\}, \ \{A\rightarrow0,A\rightarrow1A,B\rightarrow0A,B\rightarrow1\}, \ B) G=({A,B}, {0,1}, {A→0,A→1A,B→0A,B→1}, B)
通過產生式,推出一個字串產生的程序,叫做推導,例子如下,給出文法 G,寫出句子 aaa 的推導程序
G = ( { A } , { a } , { A → a ∣ a A } , A ) G = (\{A\}, \ \{a\}, \ \{A\rightarrow a \mid aA \}, \ A) G=({A}, {a}, {A→a∣aA}, A)
推導的程序如下:
A → a A , 使 用 產 生 式 A → a A a A → a a A , 使 用 產 生 式 A → a A a a A → a a a , 使 用 產 生 式 A → a A \rightarrow aA, \ 使用產生式 A\rightarrow aA \\ aA \rightarrow aaA, \ 使用產生式 A\rightarrow aA \\ aaA \rightarrow aaa, \ 使用產生式 A\rightarrow a A→aA, 使用產生式A→aAaA→aaA, 使用產生式A→aAaaA→aaa, 使用產生式A→a
歸約則是和推導(又稱為派生)相反的程序,通過句子推匯出文法,
DFA
DFA 即為確定的有窮狀體自動機,和文法不同,文法注重描述一個串是如何產生的,而 DFA 則注重于觀察該串是否能被某些文法接收,
通過五元組:
M = ( 狀 態 集 合 , 輸 入 字 母 表 , 轉 移 函 數 , 起 始 狀 態 , 接 收 狀 態 集 合 ) M = ( 狀態集合, \ 輸入字母表, \ 轉移函式, \ 起始狀態, \ 接收狀態集合 ) M=(狀態集合, 輸入字母表, 轉移函數, 起始狀態, 接收狀態集合)
來描述一個 DFA,其中落入接收狀態的串是能夠被 DFA 識別的,比如:
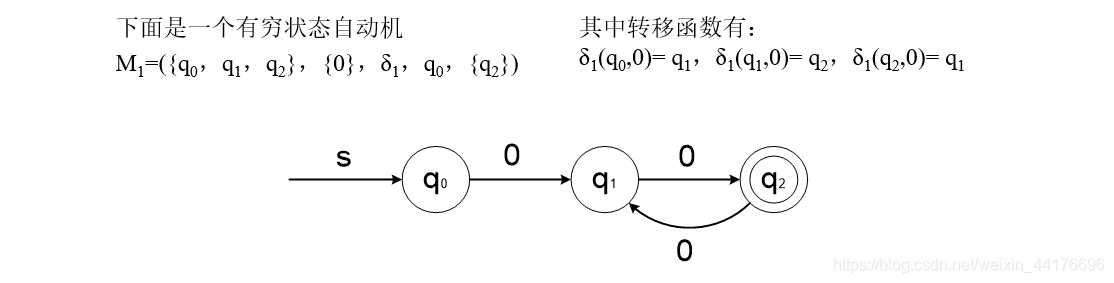
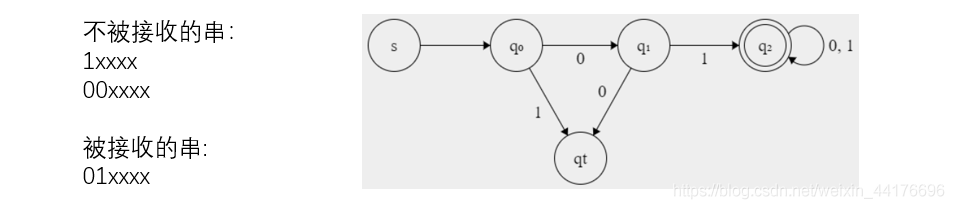
此外,DFA 還應該有陷阱狀態,表示當前串無法被接收時,狀態就落入陷阱狀態,比如有如下的例子,qt 就是陷阱狀態,表示讀取到不被接受的串:
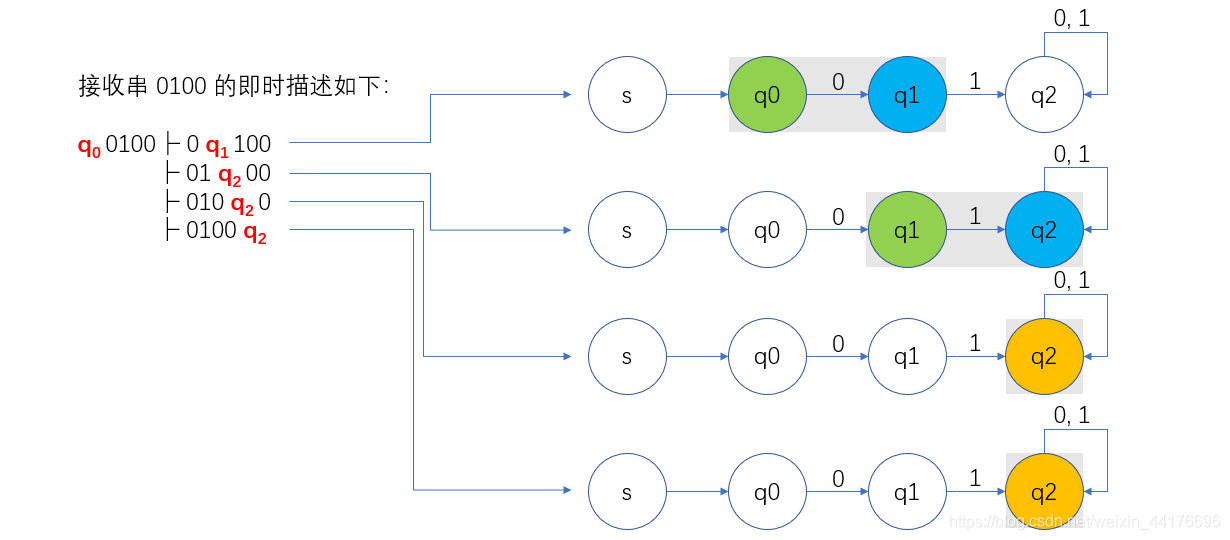
通過【即時描述】來表達一個自動機接收某個串的程序,即時描述通過狀態 q 在串上不停滑動,生動地表示了接收的程序,如下圖:
NFA
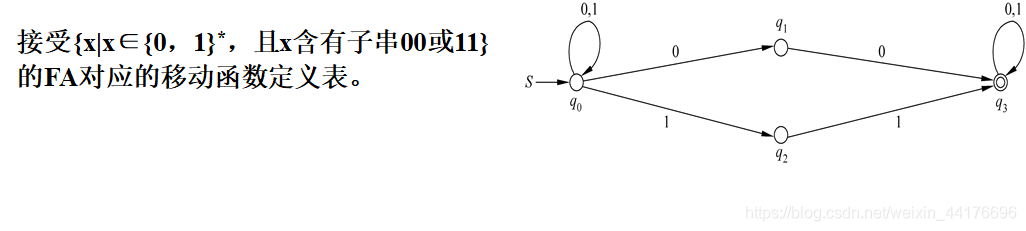
NFA 意為不確定的有窮狀體自動機,DFA 一次只能通過一個輸入的字符,跳轉到一個單獨的狀態,而 NFA 則允許通過一個輸入的字符,跳轉到多個狀態,比如下圖,q0 接收 0 可以跳轉到 q1 或者 q0:
如果說 DFA 是單執行緒的話,NFA 就是多執行緒,如果說 DFA 是 DFS(深搜)的話,NFA 就是 BFS(廣搜),這樣是否容易理解了?
NFA 轉換為 DFA
其實 NFA 和 DFA 是等價的,因為 DFA 是一次跳轉到一個狀態,而 NFA 是一次跳轉到一個狀態的集合,
如果把 NFA 的狀態集合視為 DFA 的一個狀態,那么就能實作 NFA 到 DFA 的轉換,這個思想叫做子集構造,
比如將如下的 NFA 轉為 DFA:
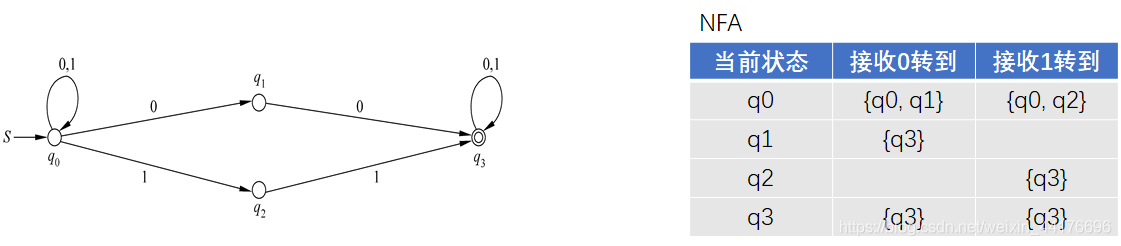
首先根據起始狀態 q0,到達兩個不同的狀態集合,分別是 {q0, q1} 和 {q0, q2}
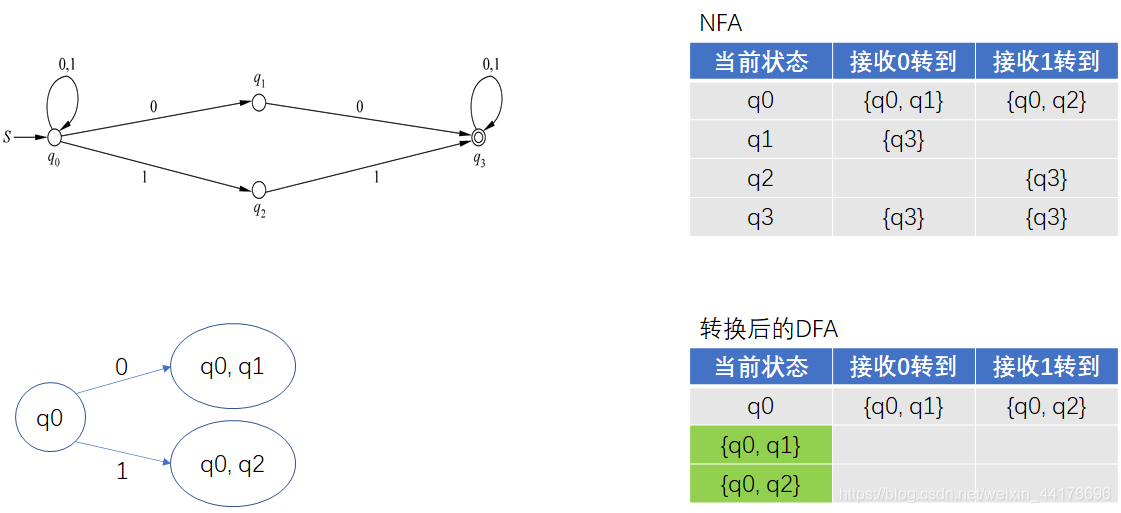
因為把狀態集合看作是 DFA 的狀態,那么我們得到了兩個新狀態,分別是 {q0, q1} 和 {q0, q2},下圖的綠色標記了這兩個新狀態:
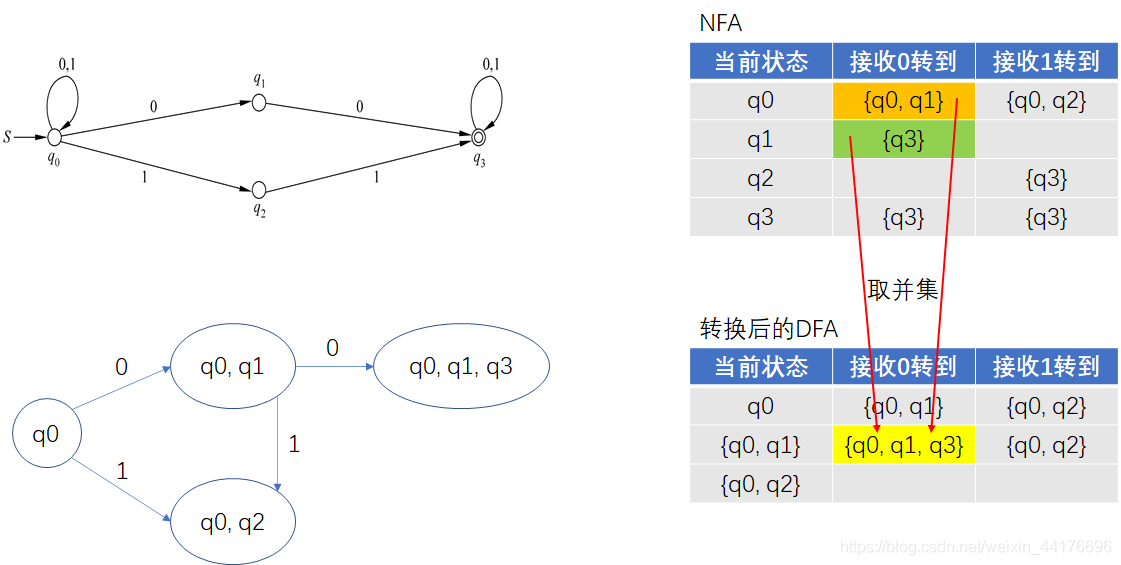
然后來判斷新狀態 {q0, q1} 的狀態轉移,因為組合了狀態 q0 和 q1 的狀態轉移,我們將原 NFA 的狀態轉移結果取并集,作為該狀態的新轉移(下圖紅色箭頭),這里只給出接收 0 的箭頭,1 的同理,于是又產生了新的狀態 {q0, q1, q3} ,如下圖:
同理,對 {q0, q2} 如法炮制,我們取原 NFA 的 q0 和 q2 的狀態轉移結果的并集,產生新狀態 {q0, q2, q3},如下圖:
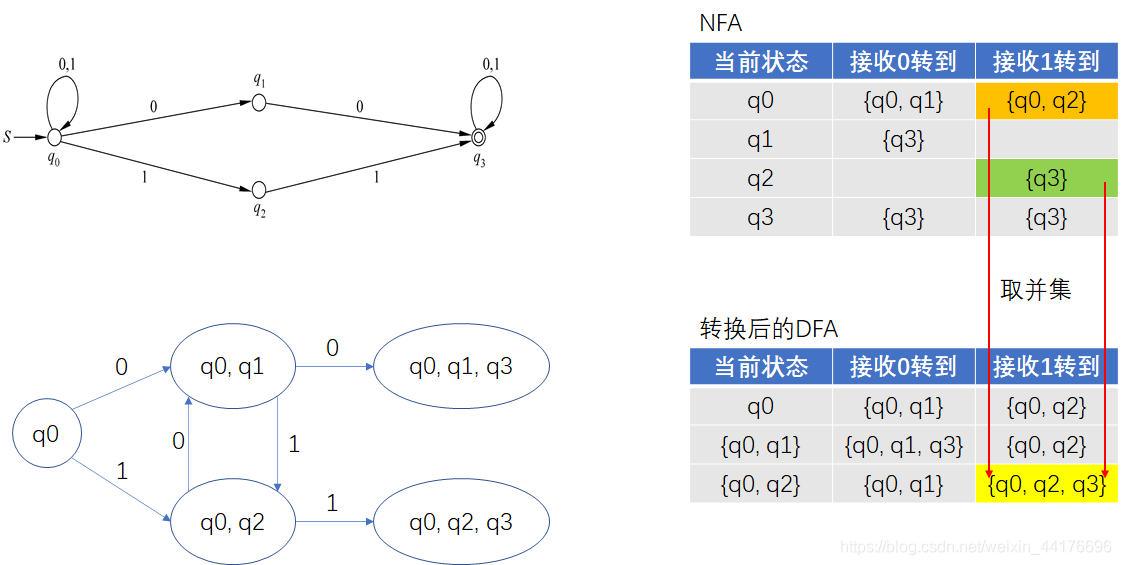
對兩個新狀態也是如法炮制:
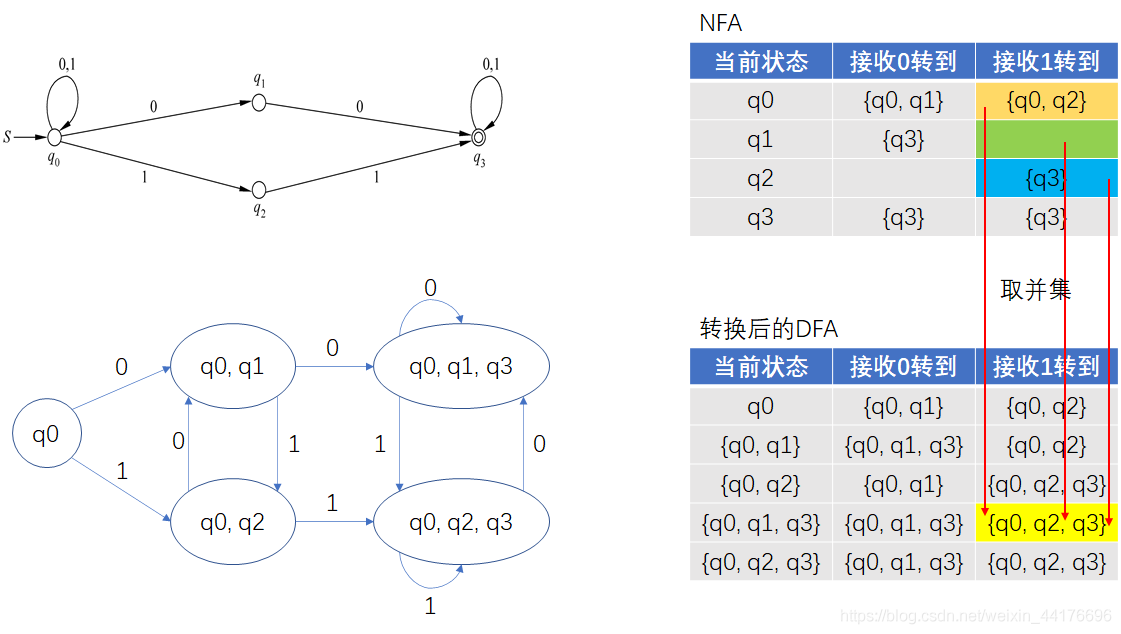
DFA,完成了!
ε-NFA
ε-NFA 允許通過空字符,即 ε 來轉移到新的狀態,
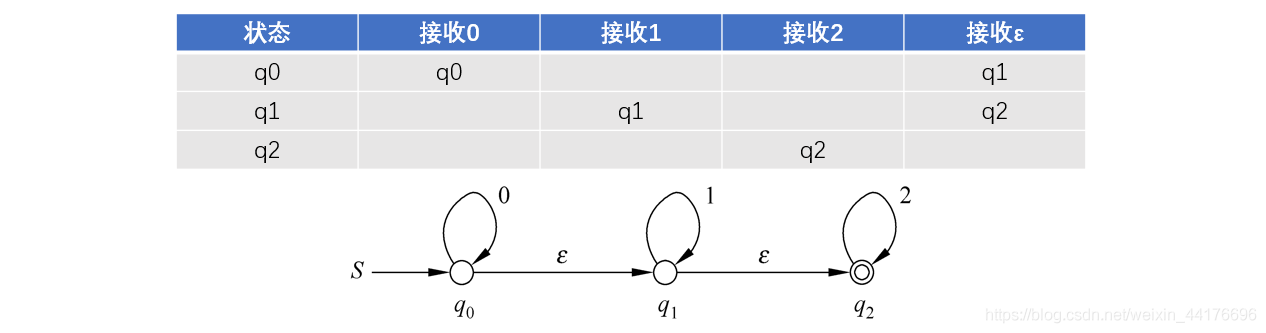
對于 ε-NFA,可以對其進行空拓展,將其轉為一般的 NFA,因為接收到輸入字符 a,也可以認為是接收到 aε,aεε,εεa,εa,即多個空字符!而且空字符可以任意地組合在有效字符 a 的前綴或者后綴,
空拓展可以通過 ε 來轉移到任意狀態,只要 NFA 有對應的邊就允許任意輸入字符沿著這些 ε 的邊進行轉移,最終達到一個閉包(即聯通分量),下圖展示了如何構建一個拓展的空閉包:
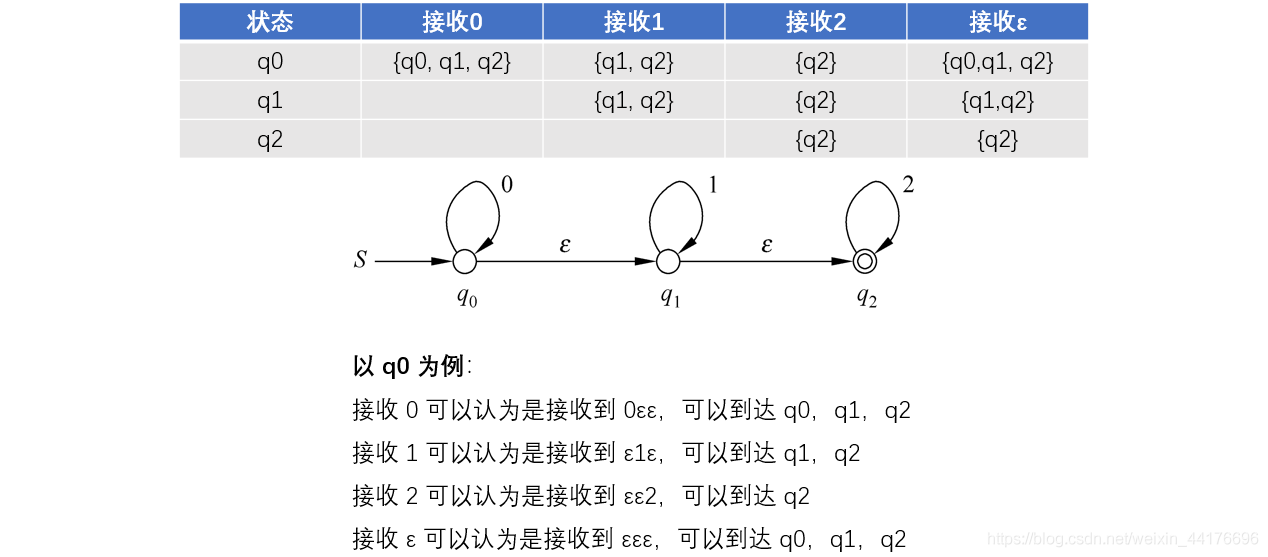
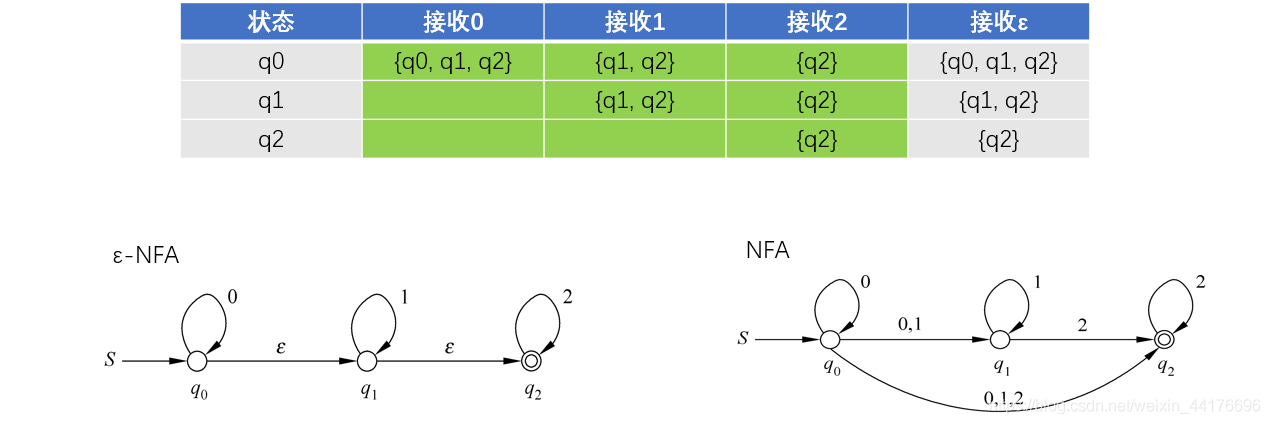
其實就是做了一次特殊的 dfs,只要遇到 ε 邊,都無腦去搜它就好了,至此,ε-NFA 也可以轉為普通的 NFA 了,因為普通 NFA 沒有 ε 輸入,我們只需要考慮正常的輸入,進行 NFA 狀態轉移(邊)的構造,
如下圖綠色部分所示,這些是我們關心的狀態轉移:
正則運算式
注:
這個不是一般編程的正則運算式
正則運算式和文法類似,都是生成串的形式語言,正則運算式主要的操作有三個,分別是加法,連接和閉包,
加法能夠將兩個東西并行地聯系起來,如果用集合來表示,就是并集,比如:
( 0 + 1 ) ? 表 示 的 語 言 為 { 0 , 1 } \ \\ (0+1) \stackrel{表示的語言為}{\longrightarrow} \{0, 1\} \ \\ (0+1)?表示的語言為?{0,1}
通過 0 和 1 取并,生成的語言為 {0, 1},
然后是連接(或者拼接?)連接運算則是按照順序將兩個運算式產生的串拼接起來,比如:
( 01 ) ? 表 示 的 語 言 為 { 01 } \ \\ (01) \stackrel{表示的語言為}{\longrightarrow} \{01\} \ \\ (01)?表示的語言為?{01}
那么最終表示的語言就只有 01 一個串了,注意順序!
最后是閉包運算,閉包運算允許我們任意地將集合內的元素自由組合,比如:
( 01 ) ? ? 表 示 的 語 言 為 { 0 , 1 } ? \ \\ (01)^* \stackrel{表示的語言為}{\longrightarrow} \{0,1\} ^* \ \\ (01)??表示的語言為?{0,1}?
最后貼一張定義:

對應到自動機上,三種規則的構圖如下:
- 如果是 + 運算,那么分為兩個分支進行接收
- 如果是拼接運算,那么按照順序進行接收
- 如果是閉包運算,通過環路進行重復接收
下面來看一個例子:

圖上作業法
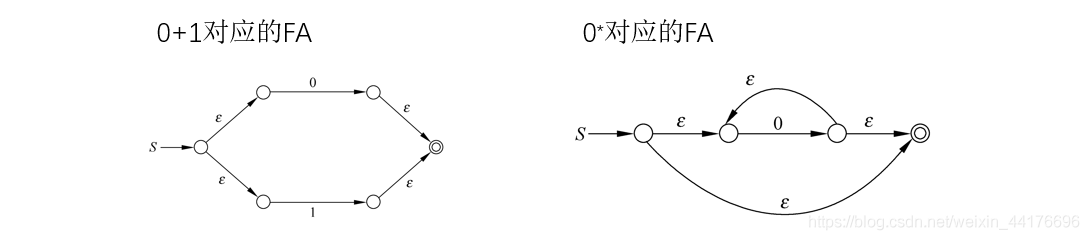
圖上作業法用于將一個自動機轉換為正則運算式,換句話說,可以通過該方法查找出該自動機接收的串的正則運算式,
圖上作業法的核心就算通過消除節點,來產生運算式,比如我們消除下圖的 q2 節點,因為我們可以從 q1 通過正則運算式一步到 q3,
因此 q1 到 q3 的程序被我們描述為正則運算式,并且形成一條邊,我們對 q2 的每個入度節點都要進行同樣的操作(即連接 q2 的入節點和出節點),如下圖:
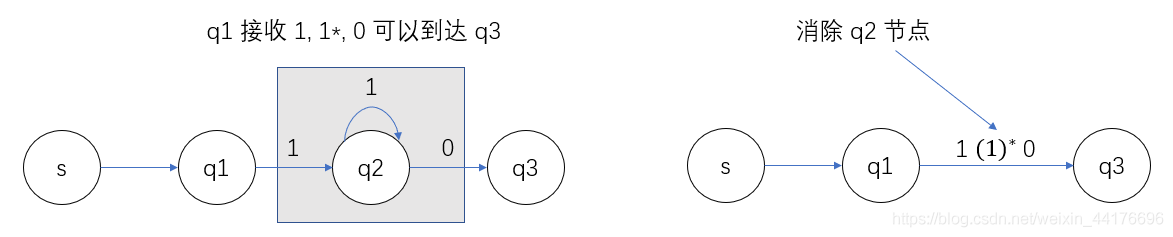
事實上一次完整的圖上作業法,第一步應該是虛擬起點和終點,將一個虛擬原點 X 通過空字符 ε 轉移到初始狀態,此外,將所有的接收狀態通過 ε 引導到虛擬終點 Y,如下圖:
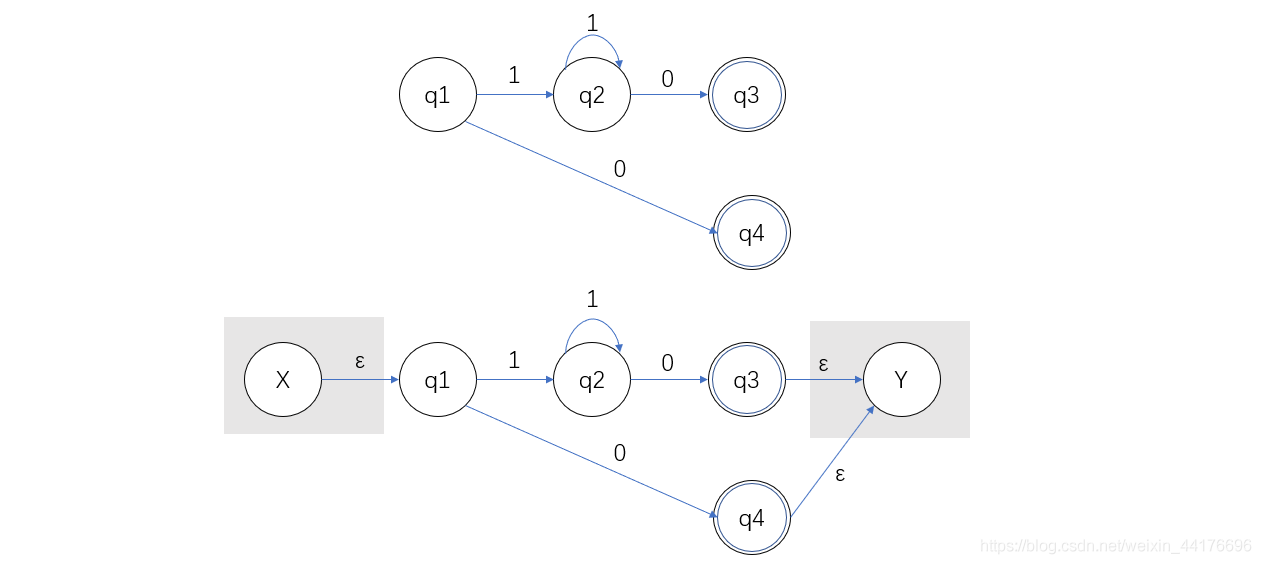
通過消去 q2 節點,我們得到:
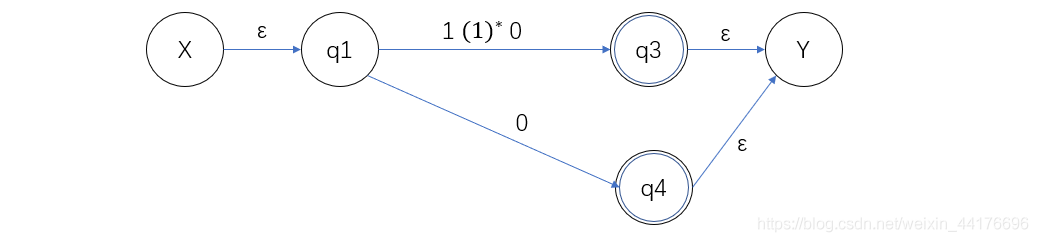
接著消去 q3 和 q4,這里我們得到兩條邊,我們可以通過加法合并他們:
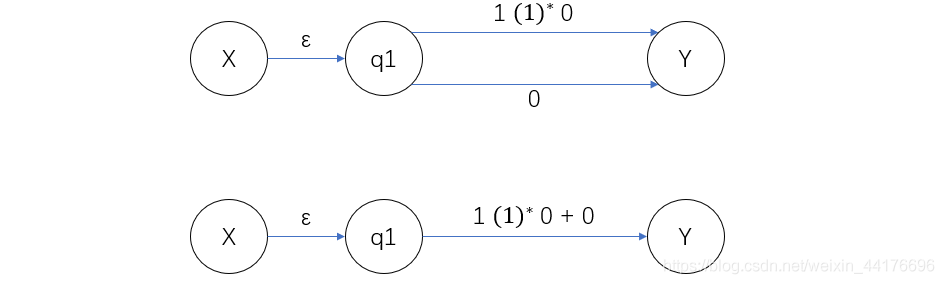
最后消去 q1,得到最終的運算式:

泵引理
通過泵引理判斷一個語言是否是正則語言,思路是反證法,
如果有 n 個狀態,接收的串卻長度大于 n,那么自動機(圖)中必有環路,
先假設它是正則語言,我們沿著環路重復走 i 次,其中 i 可以是任意正整數,如果找到某個 i 使得該語言不被接收,那么就和假設矛盾,該語言就不是正則語言!
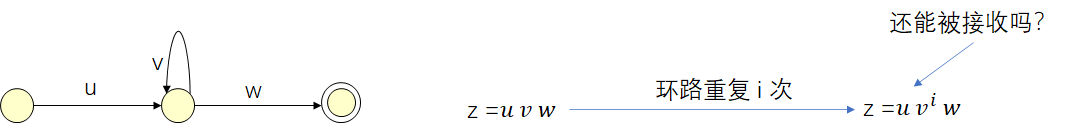
比如證明語言:
{
0
n
1
n
∣
n
≥
1
}
\{0^n1^n \mid n \ge 1 \}
{0n1n∣n≥1}
不是正則語言,通過泵引理的思路如下:
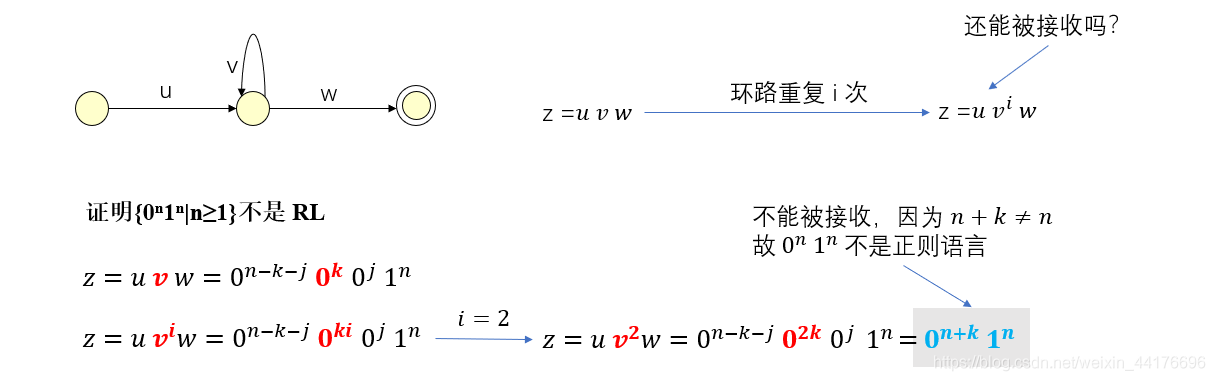
注:泵引理只能判斷某個東西不是正則語言,不能判斷它是正則語言,,,
極小化 DFA 演算法
DFA 中可能存在冗余的狀態,比如:
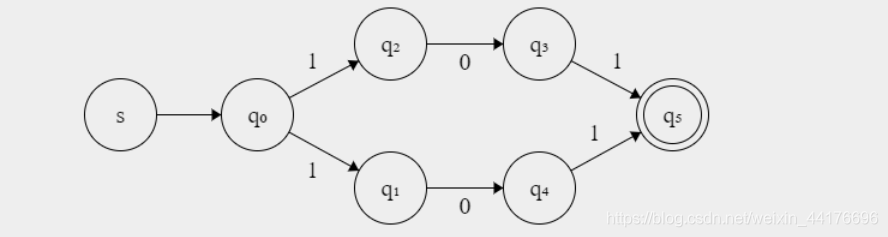
明明都是兩條一樣的路,你偏要分開來,于是 DFA 的極小化演算法就算為了解決冗余的 DFA 而生,
首先定義一種狀態:可區分,什么是可區分呢?接收相同的輸入,卻去到了不同的狀態,
比如下圖,q2 q3 接收 0,一個去到了接收狀態,一個去了非接收狀態,那么 q2,q3 可區分,因為他們有截然不同的特征:
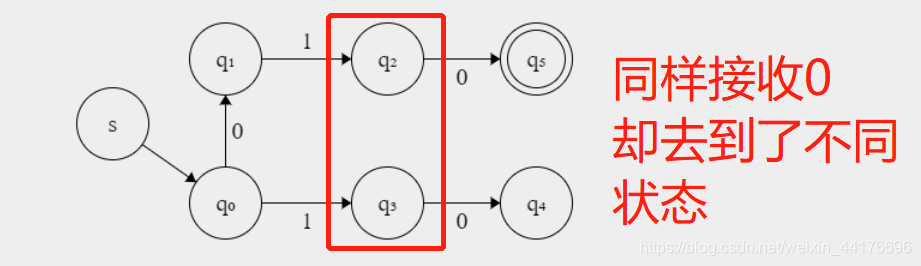
此外,如果接收同樣的輸入,卻去到了兩個【可區分】的狀態,那么這兩個狀態同樣可區分,比如下圖,q0,q1 接收 1,去到了可區分的 q2,q3,那么 q0,q1 同樣是可區分的:
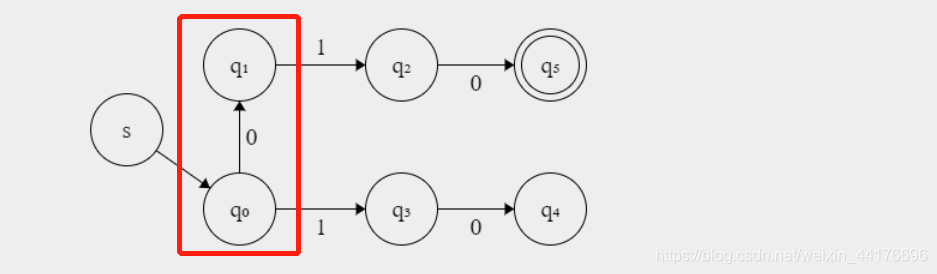
注意對所有的接收字符,都要進行判斷,才能判斷兩個狀態是否可區分,同時這個判斷是遞回進行的,
因為有時接收相同的輸入,獲得一組新的狀態對 qi,qj 我們往往不知道他兩是否可區分,于是問題轉變為求 qi,qj 是否可區分,這就是遞回!
此外,如果接收相同的輸入,去到了相同的狀態,那么他們不可區分,這意味著他們是等價的:
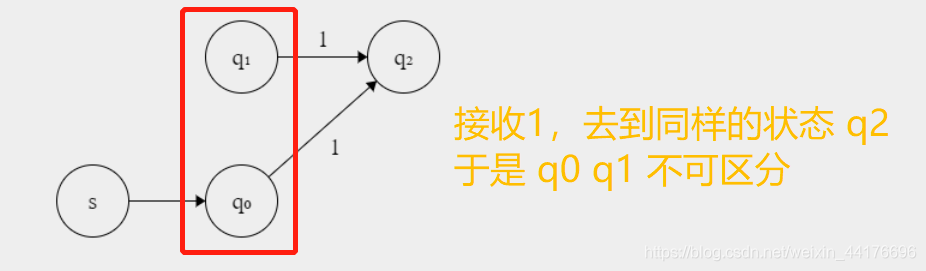
弄明白了啥可區分,不可區分,就可以開始進行演算法了!
演算法如下,首先準備一張可區分表,此外,可區分是相對的,ab 可區分意味著 ba 可區分,所以表的有效部分為上三角:
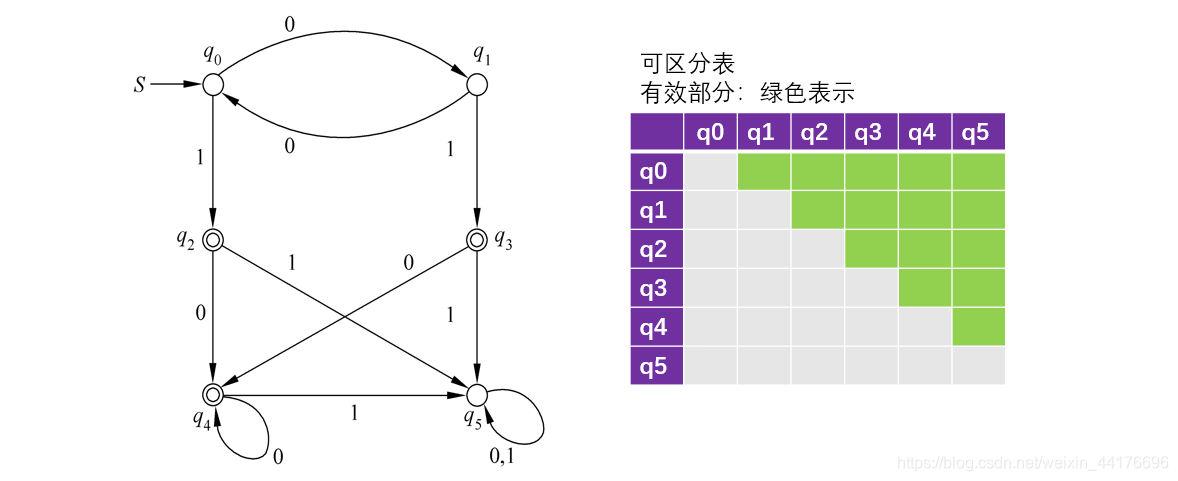
首先進行初始化,已知狀態對 qi,qj 其中 qi 是接收狀態,而 qj 不是接收狀態,那么他們可區分,
- {q0, q1} 接收 1 時,前者去到接收狀態 {q2, q3},而 q5 接收 1 去到非接收狀態 q5,于是 q0, q5 與 q1, q5 可區分
- {q2, q3, q4} 接收 1 時都去到非接受狀態 q5,而 {q0, q1} 接收 1 去到接收狀態 {q2, q3},于是他們的 6 個組合,都可區分
- {q2,q3,q4} 接收 0 去到接收狀態 q4,而 q5 接收 0 去到非接收狀態 q5,于是他們的三種組合都可區分
根據上面三個判斷,我們可以輕易地畫出初始化的表格:
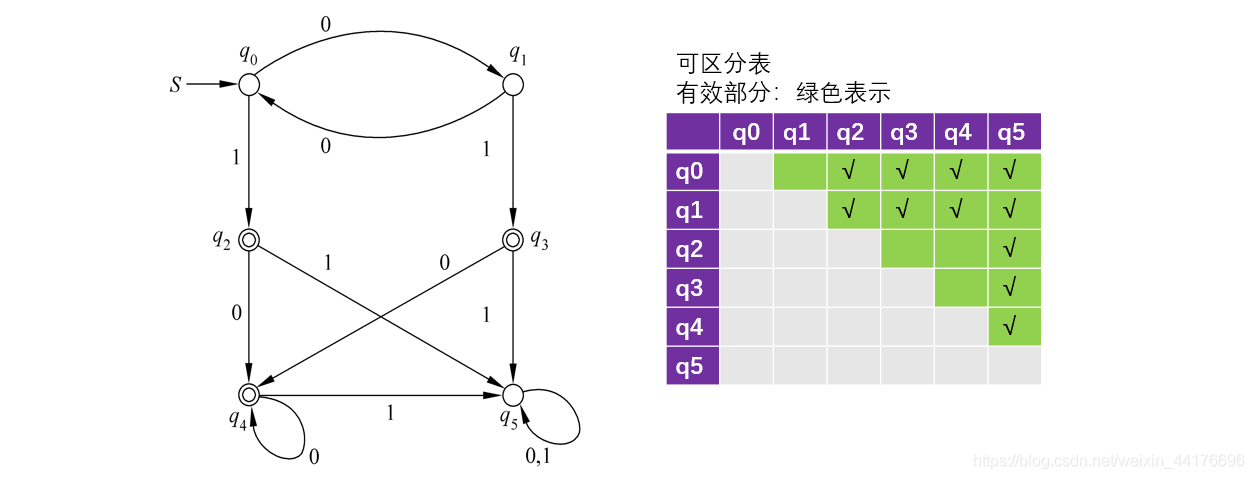
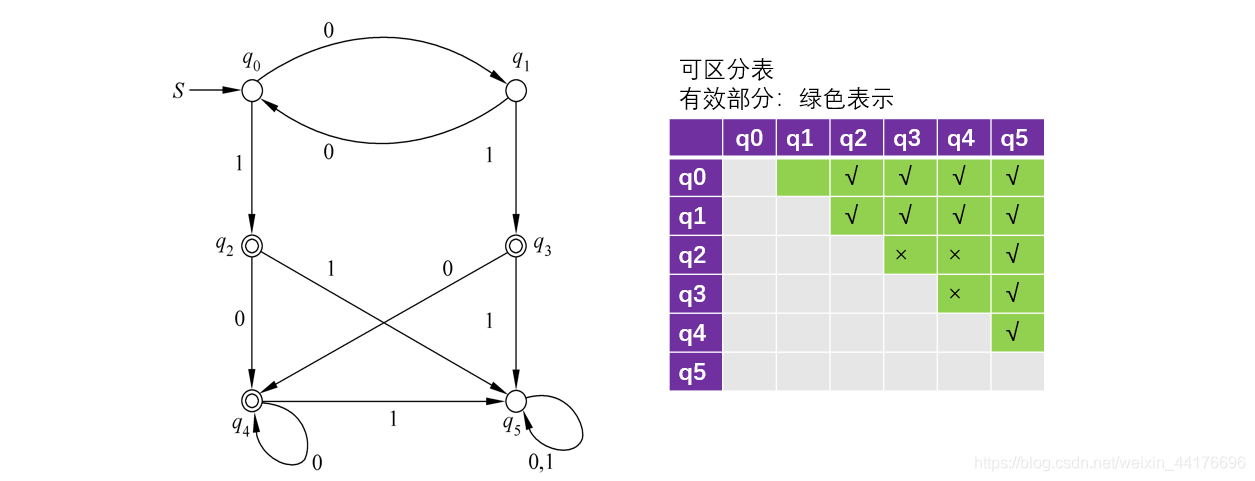
此外,如果接收到同一個輸入,去到了相同的狀態,那么他們不可區分(他們等價),于是有:
- {q2, q3, q4} 接收 0 都去到 q4,接收 1 都去到 q5,于是 q2, q3, q4 都不可區分
通過下圖話 × 部分可以表示他們不可區分:
然后遍歷表的每一項空缺,并且試圖利用遞回法判斷該狀態對是否可區分,這里只用判斷 q0,q1 是否可區分,
因為 q0,q1 接收 1 能夠到達 {q2, q3} 根據遞回,問題轉換為求 q2,q3 是否可區分!從表中看出他們不可區分,于是有:
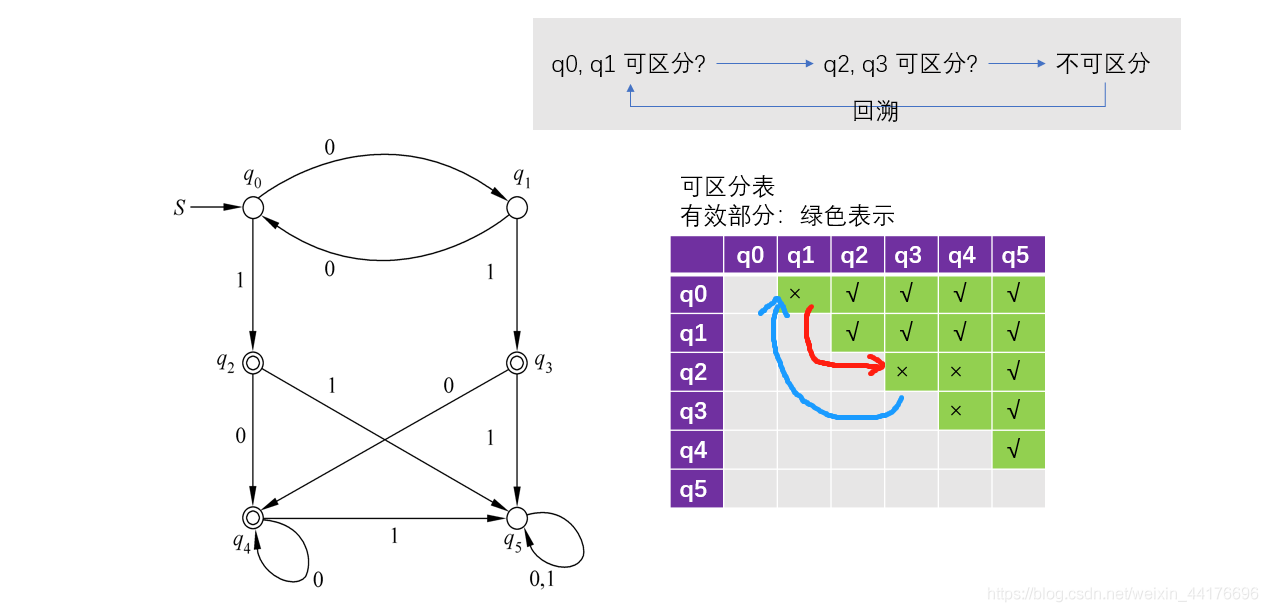
那么有:
- [q0, q1] 不可區分
- [q2, q3, q4] 不可區分
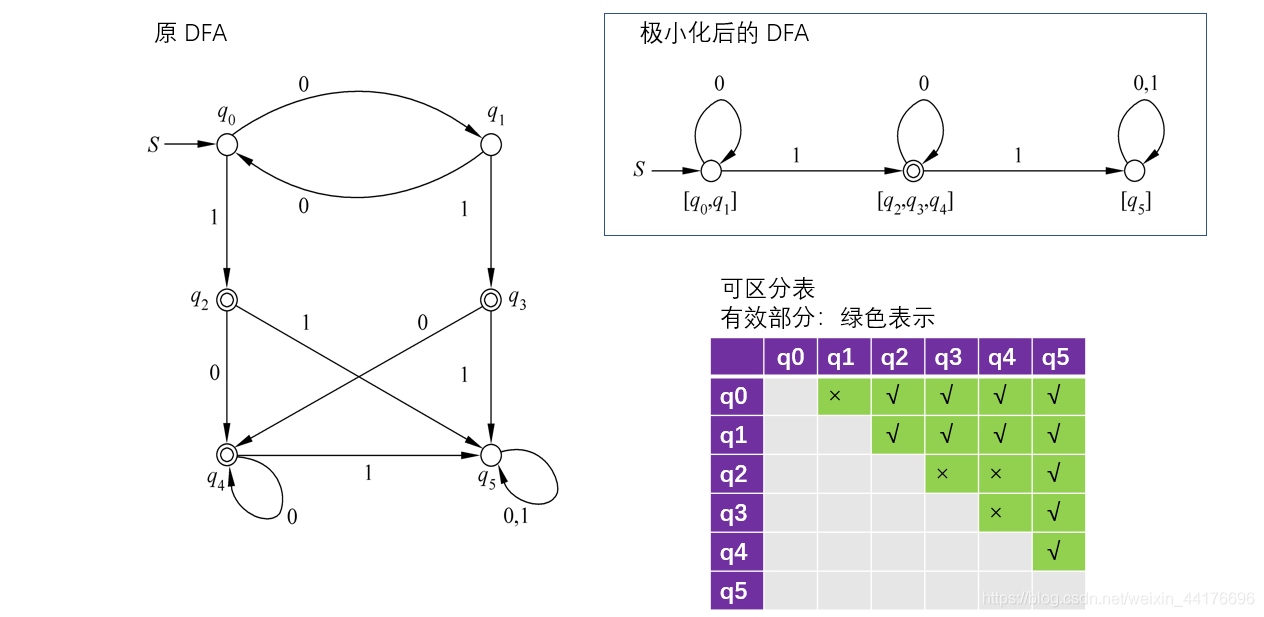
于是將原來的自動機(圖),根據狀態(節點)之間是否可區分,將圖劃分為三個連通分支,分別是:
[ q 0 , q 1 ] , [ q 2 , q 3 , q 4 ] , [ q 5 ] [q_0, q_1], \ [q_2, q_3,q_4], \ [q_5] [q0?,q1?], [q2?,q3?,q4?], [q5?]
極小化后的 DFA 將一個連通分支視為單獨的狀態(或者說節點),根據節點進行轉移,于是可以得出極小化后的 DFA:
FA 交集
前面在提及正則運算式的時候,我們可以通過加法(或者說兩個單獨的分支)來實作 FA 的并操作,這里以一道例題說明如何實作 FA 的交操作:
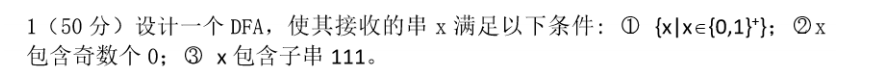
這里其實 1 不用管,因為滿足 2,3 自然滿足 1,根據 DFA 交集,我們首先構造滿足 2 和 3 的 DFA:
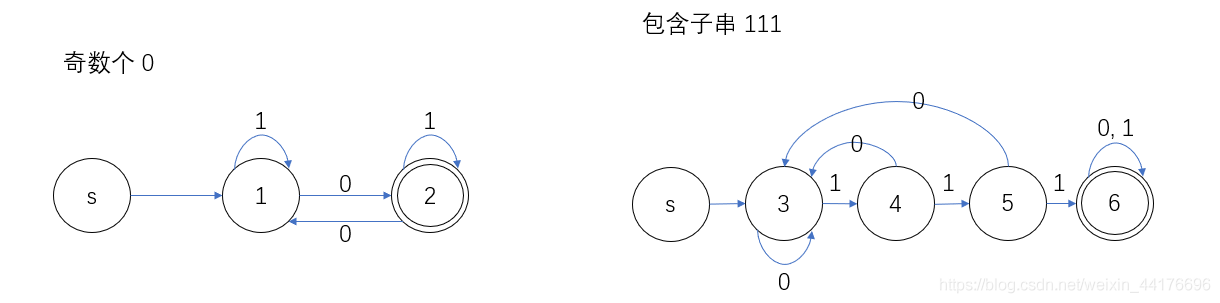
緊接著取交集,從起始狀態開始,我們將 1 和 3 狀態合一,
- 在左邊的自動機中,狀態 1 接收到 1,轉移到狀態 1
- 在右邊的自動機中,狀態 3 接收到 1,轉移到狀態 4
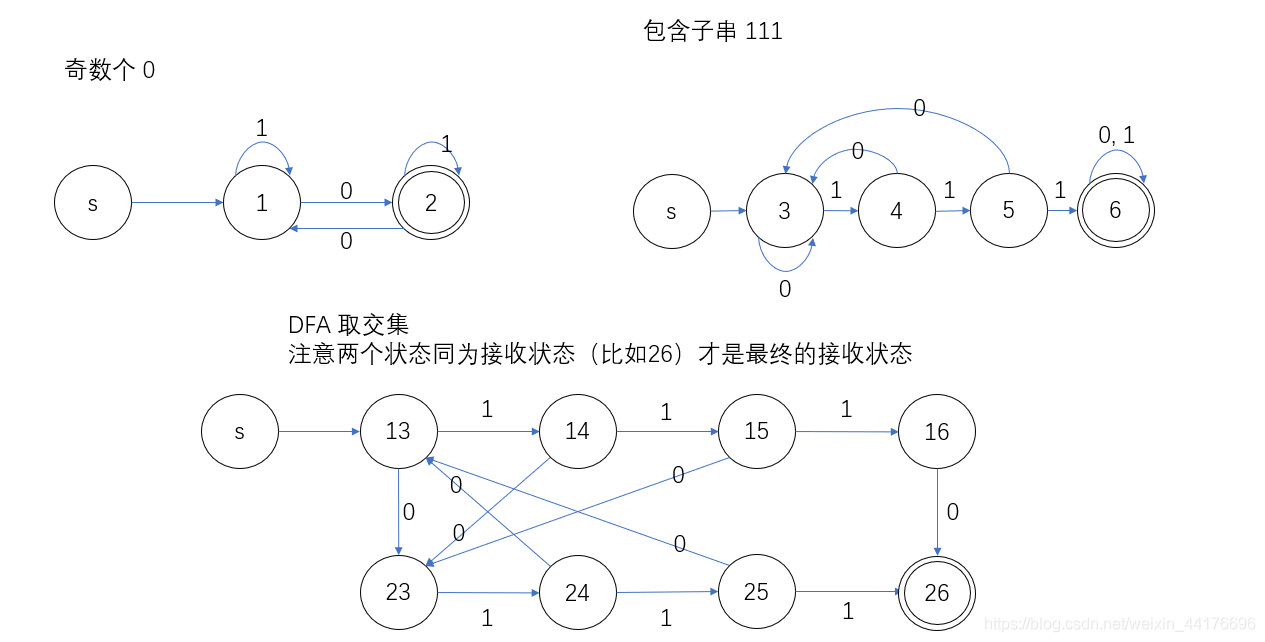
于是我們起始狀態為 13,在接收 1 后,狀態轉變為 14 了!對于其他的狀態組合和輸入組合如法炮制,最終得到如下的 DFA:
CFG,二義性與其化簡
CFG,context-free grammar 又名背景關系 免費 無關文法,是文法的一種特殊,它的定義是這樣的,對于文法:
G = ( V , T , P , S ) G = (V, T, P, S) G=(V,T,P,S)
的產生式 P,除了 A → ε 的這種空產生式之外:
對 于 任 意 產 生 式 : ? α → β 對于任意產生式:\forall \alpha \rightarrow \beta \\ 對于任意產生式:?α→β
產生的結果 β 都有如下規律:
∣ β ∣ ≥ ∣ α ∣ 且 β ∈ V |\beta| \ge |\alpha| \ 且 \ \beta ∈ V ∣β∣≥∣α∣ 且 β∈V
意義就是對于任意的 A ∈ V,如果有產生式 A→B,無論 A 出現在什么位置,都可以通過將 A 替換成 B,而無需考慮 A 的背景關系,
CFG 可以通過派生樹來表示句子的生成程序,

可以看作是一顆樹,生成樹,通過先序遍歷其所有葉子節點以獲取最終生成的句子,此外,一個句子可能有不同的生成樹,這叫做 二義性 ,
CFG 可以被化簡,因為盡管一個文法符合 CFG 的標準,但是其任然存在一些無關的東西,化簡 CFG 的演算法通常分為兩個步驟:
- 去除無法終止的變數
- 去除無法到達的變數
而且這二者的順序不可交換!證明程序略,
演算法聽起來有點抽象,那么什么叫無法終止的變數呢?就是無法派生出終極符的變數,比如下面的文法中的 A 變數:
G = ( { A , B } , { a , b , c } , { A → a A } , A ) G = (\{A,B\}, \{a,b,c\}, \{A \rightarrow aA \}, A) G=({A,B},{a,b,c},{A→aA},A)
可以看到 A 變數能夠生成 aA,但是無法終止,因為無論怎么生成,A 都消不掉,即無限遞回,此外,如果產生式中沒有出現的變數,比如上面文法的 B 變數就沒有產生式,這表示一旦有一個 B,文法就會 ”卡死“,因為找不到 B 的產生式!
值得注意的是,一旦發現一個不可消去的變數 X,就要 “順藤摸瓜” 地回溯,找到所有產生 X 的變數,并且這些產生 X 的變數也是不可消去的,
如圖,還沒消去的情況,因為 B 消除不掉,我們順藤摸瓜,將 S→BB ,S→AB, C→ABa 也標記為無法終結的產生式:
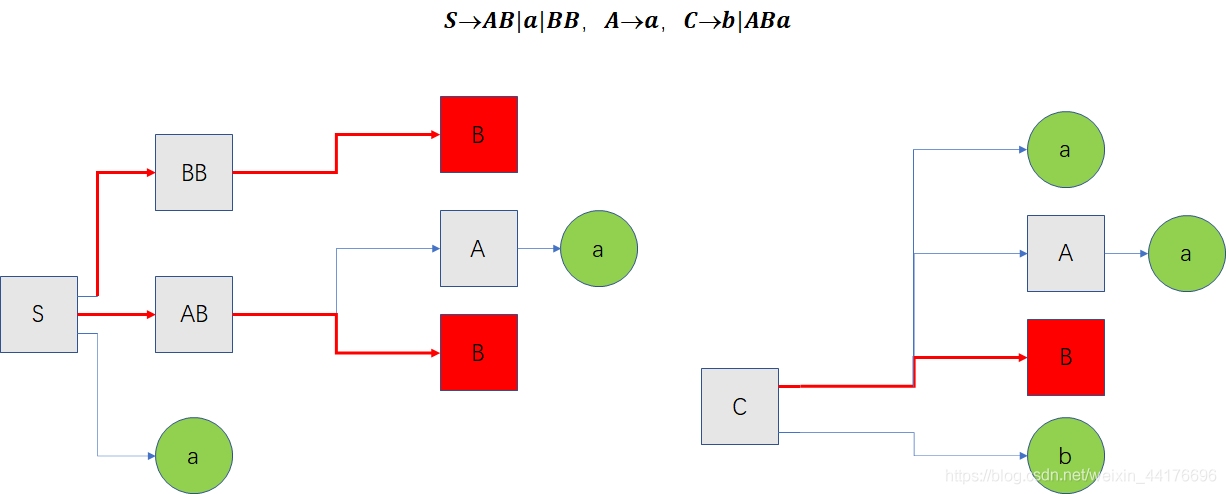
紅色的葉子表示不可終結的變數 B,我們待消去的產生式如下:
S → A B S → B B C → A B a S \rightarrow AB \\ S \rightarrow BB \\ C \rightarrow ABa \\ S→ABS→BBC→ABa
消去無法終結的產生式之后的派生:

這里就來到了第二步:消除到達不了的變數,可以看到從 S 變數除法,無法到達 A,B 所以 A B 要被消去,消去之后的文法如下:

至此,CFG 化簡完成,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/249855.html
標籤:AI
上一篇:【ArcGIS風暴】ArcGIS平臺實作中國地表覆寫資料GlobeLand30預處理(批量投影、拼接、掩膜提取)