《Suggesting Natural Method Names to Check Name Consistencies》論文閱讀總結
”Stay Hungry Stay young“
@lizzy_0323
一、方法的提出
1.1 背景
方法的誤導性名稱在專案或者軟體庫的構建中常常會使開發者不能準確理解程式的功能和API的用法,因此導致API的誤用,
因此本文介紹了MNIRE–一種機器學習的方法來檢查給定的方法名稱及其實作的一致性,它首先生成一個候選名稱來與當前名稱進行對比,如果這兩個名稱足夠相似,就認為該方法是一致的,生成方法名稱的這一程序中發現,方法名稱的標記比例很高,可以在給定方法的三個背景關系(主體,介面,封閉類的名稱)中找到,即使這些識別符號不存在,也可以通過背景關系來預測識別符號,本文的獨特想法就是將名稱生成視為從上述三個背景關系中的程式物體名稱上收集的識別符號上的抽象摘要
1.2 方法的檢驗
通過對14M個方法的資料集上進行檢驗,在檢測不一致方法時,MNIRE在召回率和精度、上分別提高了10.4%和11%,在方法名稱的推薦上,MNIRE在召回率和精度上分別提升了18.2%和11.1%,
二、方法的介紹
2.1 方法的重要性
命名約定和編碼標準是非常重要的,API的誤導性名稱會混淆軟體開發者,研究人員引入了自動工具來驗證方法的名稱和本體的一致性,關鍵思想是:具有相似主體的方法應該具有相似的名稱,但在研究中發現,由于兩種本名稱相似的方法被用于不同的任務,他們本體往往不相似,在資訊檢索(IR)方向上,工具搜索只能搜索具有相似主體的方法的名稱來推薦不同的方法,但卻不能提出一個新的名稱,
2.2 該方法優于其他的點
code2vec方法的關鍵思想是:具有相似的AST結構(抽象語法樹)實作的兩種方法(例如for和while)可以執行相同的任務,因此可以給出相同的名稱,重要的是code2vec不能為方法形成新的名稱,
Allamanis等人采用神經網路模型將方法主體中的所有名稱和方法名稱中的識別符號全部投射進同一個向量空間,他們的模型選擇向量空間中最近的單詞來組織生成一個新名稱,程式物體的名稱和方法名稱本質上不同,物體的名稱具有完全的含義,方法名稱的單個識別符號都各自具有不同的含義,所以并不應該映射在同一空間
通過一系列實驗,可以發現62.9%的方法名都是唯一的,且78.1%的單詞可以在可以在前面看到的方法名中找到,因此方法名稱預測模型應該在方法名稱的各個單詞的層面使用,而不是在方法名這個主題上使用,另外,方法的主題,介面和方法的外圍類中可以找到方法的名稱,當遇到方法的名稱的所有單詞的時候,在35.9%的情況下,我們能在方法的名稱中找到一個單詞,盡管找不到,也可以使用背景關系來預測方法名稱中的單詞,因為這些單詞共同出現的概率很高,介面反映了輸入輸出,包裝類反映了實作該方法的任務的一般背景關系,通過這些自然性原理,證明在大量語料庫上訓練統計模型是合理的,
2.3 方法的簡介
基于以上研究,將方法名稱的生成問題作為抽象文本的摘要問題,每個單獨的句子都是都是文章中的順序表示,方法的名稱被分解為一個標記序列,該標記作為輸入句子的摘要生成,該方法可以創建一個抽象的摘要,
模型的結構上,本文的模型選擇了Encoder-Decoder模型,該模型通過對輸入統計地進行編碼,來總結出句子的含義,這個模型被用來捕捉句子使用的語境,并且用不同的單詞在一個簡短的序列中重新表述他們,這就是預測的方法名
三、用例
3.1 方法名不一致
針對方法不一致問題,提出了兩種典型場景:
1.當一個方法被給予一個混淆的名稱時,不一致問題發生;
2.方法名稱和方法功能之間的不一致問題發生在軟體的不斷更新中,
3.2 根據方法來生成一個較好的名稱
根據方法可以派生出一個較為準確的名稱,這個名稱可以用來檢測當前的名稱是否是一致,也可以在名稱的命名階段提供一個較好的名稱,生成一個好名稱,往往依賴于以下因素:
1.抽象方法的目的的方法名稱和用于實作該方法的程式物體的名稱和方法功能的描述有關,這種關系來源于兩個層面,第一個是方法的名稱和主體中的變數、欄位以及方法的呼叫與方法的功能有一定的聯系,第二個層面是良好的方法的名稱的單詞和主題中程式物體的單詞常常同時出現(前文已經提到),
2.引數的型別,方法的回傳值也是方法宣告的一部分,他們描述了方法的輸入和輸出,并對于其他呼叫該方法的使用產生了巨大影響
3.在面向物件編程中,方法m定義了屬于C類的物件的一種表現,C類的物件o在執行m時,可以被認為是描述這個行動的主體,因此類名也擁有推斷方法名稱的作用
四、實體研究
4.1方法的唯一性和大小特點
在資料集中,有3402,550個唯一的方法名稱和120,303個方法名稱中的唯一單詞,平均每個方法名稱有2.64個單詞,中位數有3個單詞,最長的方法名稱為83個識別符號,同時,方法主體中的識別符號數量是方法名稱的17.3倍,大多數方法名稱比主體短的多,
大多數方法名其實是惟一的,不唯一的情況是因為出現了大量的公共名稱,相反的,組成方法名稱的識別符號往往由以前看到的單詞組成,
4.2 方法名稱和背景關系的聯系
-
方法名稱和背景關系共享的通用識別符號:在三個背景關系中,平均有兩個可以找到方法名稱的3個標記中的大約2個,而方法名稱大概率在正文中找到(62.%)接下來是介面(14.9%),外圍類(6.1%)
-
方法名稱和背景關系共享單詞的普遍性:
84.6%的方法具有33.3%的單詞可以在背景關系之間找到的方法名稱,79.8%的方法中的識別符號至少有一半能被找到,36.7%的方法由全部在背景關系之中的識別符號組成,因此,名稱與物體名稱相同的方法所占百分比很高,
3.方法中的識別符號出現在背景關系之中的條件:
? 對于一種方法,將發生的條件計算為條件概率,計算公式為:
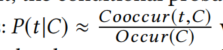
分子為含有t的方法的數目,分母是背景關系和C一致的方法數目,這個概率越高,背景關系預測單詞t的能力就越強
五、模型的特點
5.1模型關鍵理念
1.識別符號名稱的自然性
2.摘要總結
5.2 文本提取
首先提取實作、介面、封閉類的文本, 分別記為IMP,INF,ENC文本,然后將所有背景關系句子鏈接起來,形成三個背景關系的順序表示,他們被"."分割,INF中,輸入和輸出被“,”分割,對于IMP和INF,識別符號的名字和型別被按照代碼中原本的順序排列,隨機順序的實驗發現名稱/型別的順序并不影響結果,
5.3抽象概括模型
MNIRE中使用了基于Seq2Seq的體系結構,該模型基于注意力機制,模型結構如下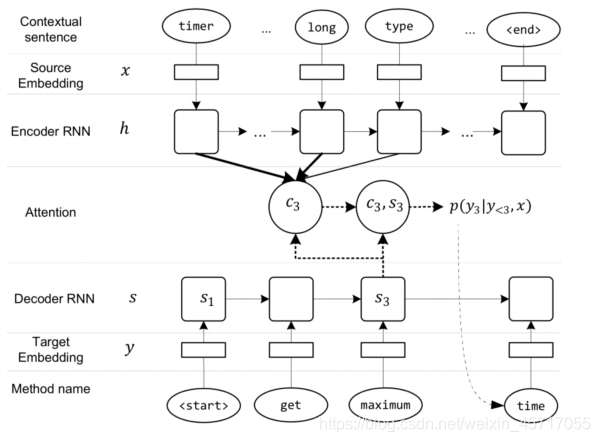
在這個模型中,編碼器的輸入為嵌入的向量x=(x1,x2,…,x m)的文本句子,并將句子編碼為隱藏表示h=(h1,h2,…,hm),解碼器負責通過基于h向量的y = (y1,y2, …,yk )預測方法名稱的概率,每個y的概率是基于回圈神經網路(RNN)的解碼向量s,前一階段預測的y,以及背景關系向量c,計算公式如下:
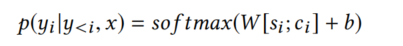
c向量稱之為注意力向量,它是基于s和隱藏層h計算的,計算公式如下: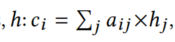 ,
,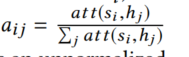
其中,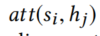
是起一個注意力功能,它用于計算未歸一化的解碼器和編碼器對齊分數,總的來說,背景關系向量c幫助解碼器決定了哪些句子的哪些部分要集中在哪些步驟上生成y,
5.4 方法名稱一致性檢查
為了檢查一致性,我們計算了p和c之間的相似性Sim(p,c),p來自于MNIRE,c為當前階段的方法名稱,這個相似性的值在0到1區間,定義為p和c之間共享的單詞的部分,計算公式如下:
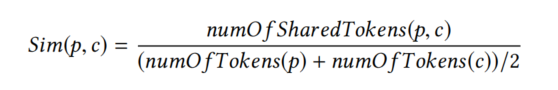
方法m的一致性是用一個不同的閾值T來決定的,如果這個值小于T,MNIRE就可以把c分類為不一致,否則分類為一致的方法實作,
六、 評估設定,程式和度量
比較研究:對于MCC和MNR的每一個應用,用各自的訓練資料集訓練了正在研究的每個模型,然后用相應的測驗資料集對其進行了測驗,
背景分析:對于每個應用程式,為了研究不同背景關系的影響,我們創建了具有不同背景關系組合的MNIRE的不同變體,并測量了性能,
靈敏度分析:對于每個應用程式,研究了以下因素的影響:表示、相似閾值、背景關系和資料大小, 改變它們并測量性能
計量:對于MCC,將預測的案例與作為MCC語料庫一部分提供的一致和不一致的方法名稱進行了比較,,對于MNR,我們將預測的名稱與MNRoracle中的好方法名稱進行了比較,該方法是在code2vec中構建的,為了測量MCC的表現, 使用精確率,召回率,f-score和準確率四種性能度量,對于不一致的方法而言:
準確度的計算公式為: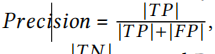
召回率為:
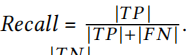
對于一致的方法:
準確度:
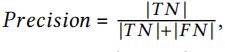
召回率: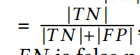
F-score:
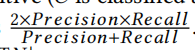
精確度:
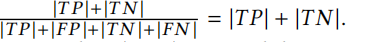
關于這幾個性能度量的具體決議可以去查閱相關資料和博客
對于原名e和預測之后的名字r
準確率的計算公式為:
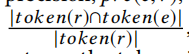
召回率的計算公式為;
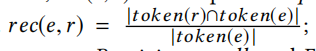
token(n)代表中陳述句n中的單詞數目
七、 經驗結果
7.1準確度比較
1.在方法名檢查(MCC)上的準確度:
對于不一致的方法名:
MNIRE的召回率提高了10.4%,精確度提高了10.8%
MNIRE使用程式物體的名稱,,這個方法的原則是,方法的實作和他們在本體中實作類似的方法時的名字應該類似,反之亦然,
對于一致的方法名:MNIRE探測到比原方法名更一致的方法名,提高了16.6%的召回率,提高了9%的準確度
2.在推薦方法名(MNR)上的準確度:MNIRE方法比code2vec提高了18,2%的召回率,和11.1%的準確度,基于更高的召回率,MNIRE可以有更多的單詞被正確預測,基于更高的準確度,預測出的單詞是正確的單詞的比率更高,原因是因為MNIRE采用了更豐富的文本,例如封閉類的文本,它的名稱和方法名稱具有很強的相關性,
3.生成新方法名層面的準確度:探究MNIRE在推薦的方法名稱上的表現,這些方法名稱并不在訓練資料中,仍然可以很好的預測未知的方法名稱,這表明它學習推薦的方法名稱而不是檢索在語料庫中訓練的內容
4.在測驗集方法大小上的準確度:MNIRE在具有規則尺寸的方法上很有效果,但隨著方法的長度增加,有所下降,
7.2 文本分析結果
使用介面和實作的文本輔助之后,準確度在兩者均有提升,對于MNR問題,精確度和召回顯著提升,對于MCC問題,也有些許提高,
與IMP和INF相比,IMP+ENC的改善程度低于IMP,原因是INF與方法名稱的有更多共同的識別符號,并且INF和ENC中的單詞數量比IMP小得多,因此對IMP的改進較小
7.3 敏感度分析結果
1.在使用seq2seq模型之前決議代碼并構建不同的表示:
- lexeme:所有單詞都被收集
- AST:seq2seq模型的輸入時AST中令牌的序列,使用分隔符對樹結構進行編碼
- Graph:方法主體被構建為PDG,,使用grapg2vec工具將轉化為向量,輸入seq2seq
如果兩種方法具有相同的AST,他們可能不一定有相同的詞匯標記,因此Lexeme模型有更嚴格的相似條件,因此精度較高,召回率較低,然而,Graph模型比Tree模型的相似性條件更低,Tree模型的F-score高于Graph模型
2.背景關系長度對準確度的影響;
背景關系越長,MNIRE模型效果越好
3.背景關系中每個單詞的長度對于準確度的影響:
有意義的單詞越多,準確度越高
4.資料集的大小對準確度的影響:
資料集的大小增加,準確度增加
7.4 時間復雜度
MCC問題上:MNIRE訓練時長遠低于code2vec,這是由于MNIRE不需要構建抽象語法樹節點 ,因此MNIRE效率更高
八、結論
本文介紹了一種機器學習方法-MNIRE,用于預測方法名稱和檢測方法名稱一不一致,得出的結論是:為了預測一個好名字,需要依靠文本中程式物體的自然性,比AST或PDG結構要好,其次,方法名各自是相當獨特的,但各個識別符號卻經常出現,因此,MNIRE利用程式物體中識別符號的規律性來生成預測的方法名稱,最后,生成的方法在預測新名稱方面比基于IR的語料庫搜索方法更有效
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/249882.html
標籤:其他
下一篇:14. vue的插槽