(一)認識資料庫
- redis默認埠:6379
- mysql默認埠:3306
什么是資料庫?
資料庫的英文單詞:data base,簡稱DB,
資料庫實際上就是一個檔案集合,是一個存盤資料的倉庫,本質就是一個檔案系統,資料庫是按照特定的格式把資料存盤起來,用戶可以對存盤的資料進行增刪改查操作,
(總而言之,資料庫就是用于存盤和管理資料的倉庫,)
資料庫分為兩大類:
關系型資料庫:是建立在關系模型基礎上的資料庫,(比如:MySQL、Oracle、DB2、SQL Server)非關系型資料庫(NO SQL):通常指資料之間無關系的資料庫,(比如:monggodb、redis(鍵值對的方式存盤))
MySQL簡介
- MySQL是一個關系型資料庫管理系統,由瑞典MySQL AB公司開發,
- 世界上最流行的幾款資料庫之一,
- 優點:是一款輕量級資料庫、免費、開源、適用于中大型網站,
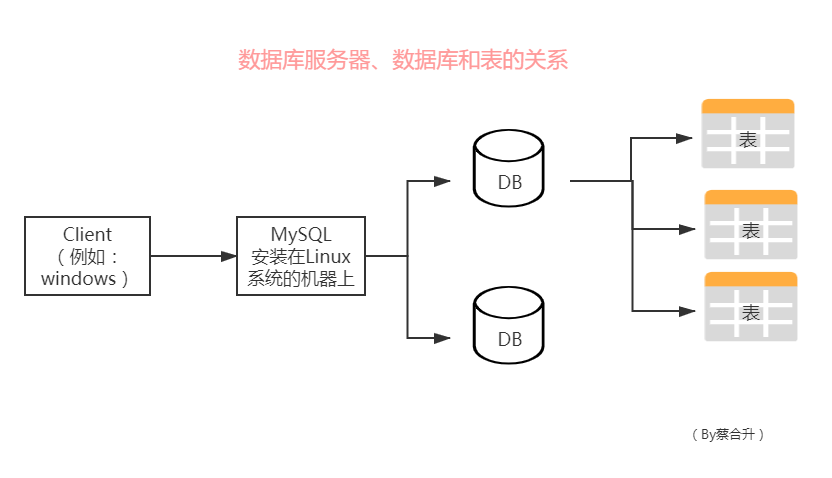
資料庫服務器、資料庫和表的關系:
-
所謂安裝資料庫服務器,只是在機器上裝一個資料庫管理系統(比如: MySQL),用來管理多個資料庫,一般開發人員會針對每一個應用創建一個資料庫,
-
為保存應用中物體的資料,一般會在資料庫創建多個表,以保存程式中物體的資料,
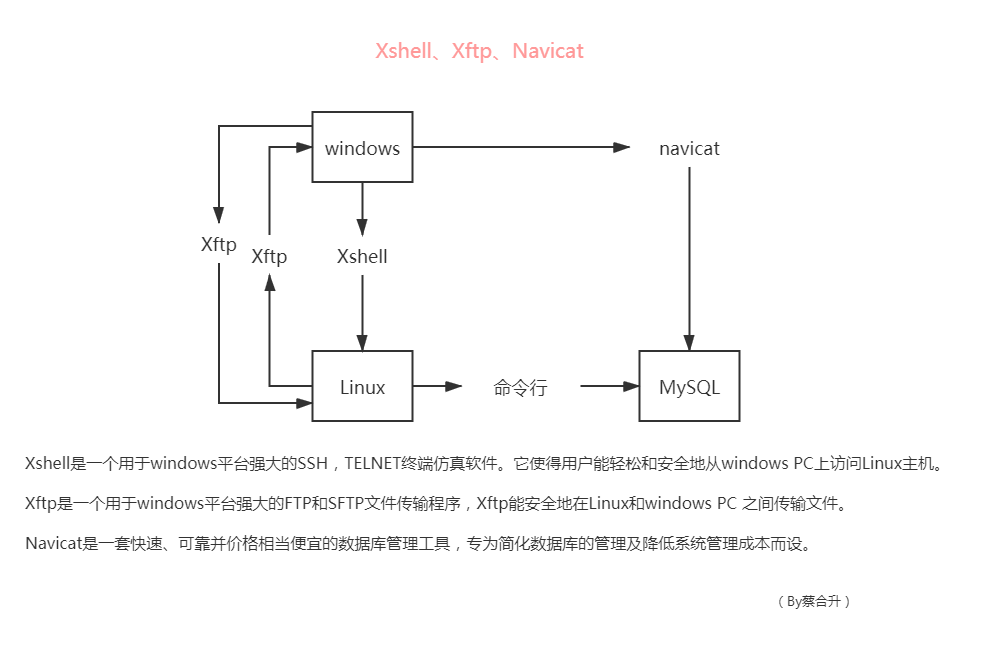
Xshell、Xftp、Navicat:
SQL介紹
Structured Query Language:結構化查詢語言,
SQL是專門為資料庫而建立的操作命令集,是一種功能齊全的資料庫語言,在使用它時,只需要發出“做什么”命令,“怎么做”是不用使用者考慮的,
SQL語法特點
- 不區分大小寫,
- 關鍵字、欄位名、表名需要用空格或逗號隔開,
- 每一個SQL陳述句是用分號結尾,
- 陳述句可以寫一行也可以分開寫多行,
(二)資料庫常用操作命令
1.MySQL登錄
-
mysql -uroot -p密碼
-
mysql -uroot -p(回車)
Enter password: (輸入密碼)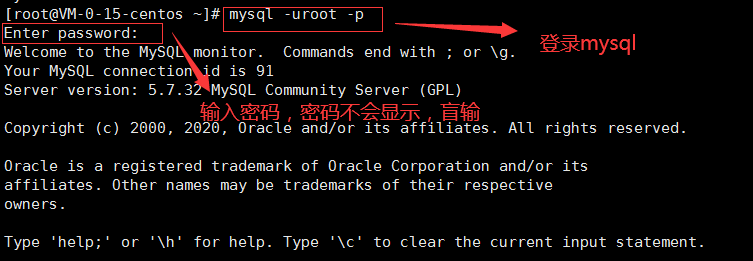
-
mysql -hip -P埠 -uroot -p
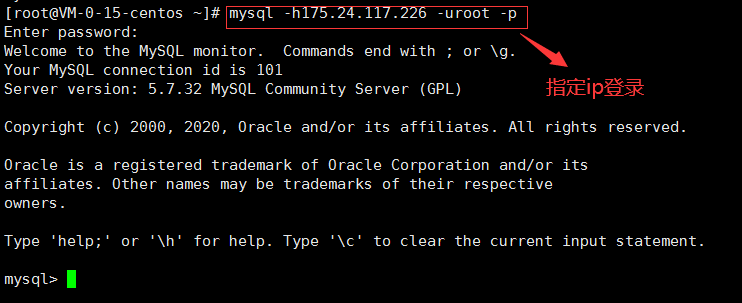
-
mysql --host=ip --user=root --password=密碼
2.MySQL退出
-
exit
-
quit

3.創建、查看、洗掉、使用資料庫
-
創建資料庫命令
-
創建資料庫:
格式:
create database [資料庫名稱];例如:create database chs;
-
創建資料庫,并指定字符集:
格式:
create database [資料庫名稱] character set [字符集名];例如:create database chs character set utf8;
-
創建資料庫,并指定字符集、排序規則:
格式:
create database [資料庫名稱] character set [字符集名] collate [排序規則];例如:create database chs character set utf8 collate utf8_general_ci;
-
-
顯示資料庫命令
-
顯示資料庫:
show databases;
-
模糊查詢資料庫:
show databases like '%heshen%';
-
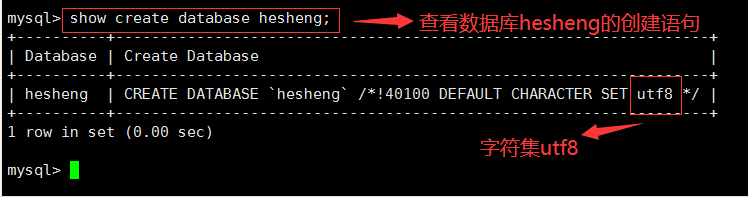
查看查詢某個資料庫的創建陳述句、字符集:
格式:
show create database [資料庫名稱];例如:show create database hesheng;
-
-
洗掉資料庫命令
格式:
drop database [資料庫名稱];例如:drop database chs;

-
選中某個資料庫
格式:
use [資料庫名稱];例如:use hesheng;
PS:這個命令可以不加分號,

4.創建、查看、洗掉、修改資料表
資料在資料庫中的存盤方式:
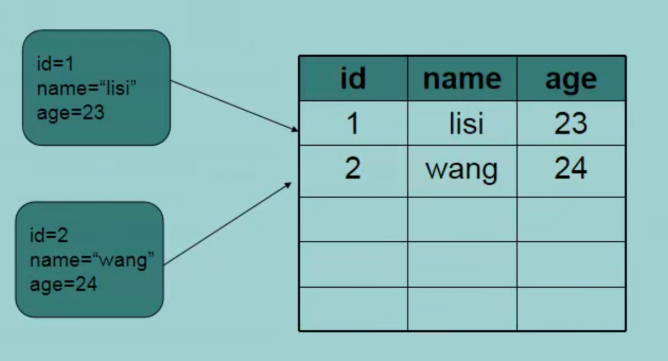
表中列的資料型別——
數值型
| 型別 | 大小 | 范圍(有符號) | 范圍(無符號) | 用途 |
|---|---|---|---|---|
| TINYINT | 1位元組 | (-128,127) | (0,255) | 小整數值 |
| SMALLINT | 2位元組 | 大整數值 | ||
| MEDIUMINT | 3位元組 | 大整數值 | ||
| INT或INTEGER | 4位元組 | 大整數值 | ||
| BIGINT | 8位元組 | 極大整數值 | ||
| FLOAT | 4位元組 | 單精度浮點數值 | ||
| DOUBLE | 8位元組 | 雙精度浮點數值 | ||
| DECIMAL | 對于DECIMAL(M,D),如果M>D則為M+2,否則為D+2 | 依賴于M和D的值 | 依賴于M和D的值 | 小數值 |
有符號和無符號(UNSIGNED)
在計算機中,可以區分正負的型別,稱為有符號型別,
無正負的型別,稱為無符號型別,
簡單的理解為就是,有符號值可以表示負數、0、正數,無符號值只能為0或者正數,
FLOAT、DOUBLE、DECIMAL
FLOAT(10,2):總長度為10,小數點后有2位,
DOUBLE和DECIMAL也類似,
超出范圍會四舍五入,
表中列的資料型別——
字符型
- CHAR:定長字串,CHAR(4) --
' d' - VARCHAR:變長字串,VARCHAR(4) --
'd' - CHAR的查詢效率要高于VARCHAR,
表中列的資料型別——
日期型
| 型別 | 大小(位元組) | 范圍 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | ||||
| TIME | ||||
| YEAR | ||||
| DATETIME | ||||
| TIMESTAMP | 1970-01-01 00:00:00 結束時間是第2147483647秒,北京時間2038-1-19 11:14:07,格林尼治時間2038年1月19日 凌晨03:14:07 |
TIMESTAMP和DATETIME的異同:
- 相同點:兩者都可以用來表示YYYY-MM-DD HH:MM:SS型別的日期,
- 不同點:
- 兩者的存盤方式不一樣:
- 對于TIMESTAMP,它把客戶端插入的時間從當前時區轉化為UTC(世界標準時間)進行存盤,查詢時,又將其轉化為客戶端當前時區進行回傳,(PS:中國時區為+8區)
- 而對于DATETIME,不做任何改變,基本上是原樣輸入和輸出,
- 兩者所能存盤的時間范圍不一樣:
- TIMESTAMP所能存盤的時間范圍為:'1970-01-01 00:00:01.000000'到'2038-01-19 03:14:07.999999'
- DATETIME所能存盤的時間范圍為:'1000-01-01 00:00:00.000000'到'9999-12-31 23:59:59.999999'
- 兩者的存盤方式不一樣:
操作命令:
-
創建表
-
創建表基礎命令-- 格式: CREATE TABLE [表名] ([列名 1 ] [列型別],[列名 2 ] [列型別],[列名 3 ] [列型別] ); -- 例如: CREATE TABLE STU (ID INT,NAME VARCHAR ( 20 );AGE INT );注意:
- 創建表前,要先選中某個資料庫(use [資料庫名稱]);
- 列和列之間用逗號隔開,列內用空格隔開;
- 創建表時,要根據需保存的資料創建相應的列,并根據要存盤資料的型別定義相應的列型別,
-
約束條件
約束條件就是給列加一些約束,使該欄位存盤的值更加符合我們的預期,
約束條件 含義 UNSIGNED 無符號,值從0開始,無負數 ZEROFILL 零填充,當資料的顯示長度不夠的時候可以使用填補0的效果填充至指定長度,欄位會自動添加UNSIGNED NOT NULL 非空約束,表示該欄位的值不能為空 DEFAULT 表示如果插入資料時沒有給該欄位賦值,那么就使用默認值 PRIMARY KEY 主鍵約束,表示唯一標識,不能為空,且一個表只能有一個主鍵 AUTO_INCREMENT 自增長,只能用于數值列,默認起始值從1開始,每次增長1 UNITQUE KEY 唯一值,表示該欄位下的值不能重復,可以為空,可以有多個 COMMENT 描述 注意:
如果一列同時有UNSIGNED、ZEROFILL、NOT NULL這幾個約束,
UNSIGNED、ZEROFILL必須在NOT NULL前面,否則會報錯,例子:
create table user_info_tab( user_id int not null auto_increment, user_name char(10), password varchar(10), user_nick varchar(10), card_num bigint, primary key(user_id) );
-
-
查看表
-
顯示當前資料庫中所有表的名字
格式:
show tables; -
顯示某張表每一列的屬性(列名、資料型別、約束)
格式:
desc [資料表名稱];例如:
desc user_info_tab;
-
-
洗掉表
格式:
drop table [資料表名稱];例如:
drop table hesheng; -
修改表
-
向資料表中添加一列
格式:
ALTER TABLE [資料表名稱] ADD [列名] [列的資料格式] [約束];例如:
ALTER TABLE user_info_tab ADD phone VARCHAR(11);PS:
-
默認自動添加到資料表欄位的末尾;
-
如果要加在第一列在最后加個FIRST;
-
如果要加在某一列的后面,在最后面加個AFTER某一列列名,
-
-
洗掉資料表的某一列
格式:
ALTER TABLE [資料表名稱] DROP [列名]; -
修改列的型別和名稱
ALTER TABLE [表名] MODIFY [列名] [資料格式];(列名不變,其他要變)ALTER TABLE [表名] CHANGE [舊列名] [新列名] [資料格式];(列名也要改變)
-
5.資料表的增刪改查
增(insert)
-- 插入資料
INSERT INTO user_info ( user_id, user_name, PASSWORD, user_nick, card_num )
VALUES
( 1, 'zhangsan', 'abc123', 'zhangsanfeng', 124567894651329785 ),
( 2, 'lisi', '122bbb', 'limochou', 124567894651324567 ),
( 3, 'wangwu', '123aaa', 'wangbaiwan', 214567894651324567 ),
( 4, 'liuqi', '12aaa', 'liuchuanfeng', 214563356651324567 ),
( 5, 'zhangliu', '12aaa', 'zhangwuji', 214563356658966567 );
刪(delete)
語法:
- delete from 表名 where 條件
- delete陳述句不能洗掉某一列的值,(可以使用
update 表名 set username = "" where userid = 1) - 使用delete陳述句僅洗掉符合where條件的行的資料,不洗掉表中其他行和表本身,
- truncate user_info_table(直接把資料清空掉)
drop和delete的區別?(面試題)
- drop是洗掉資料庫、資料表、資料表中的某一列,
- delete是洗掉某一行資料,
改(update)
語法:
- update 表名 set 列名=新值 where 列名=某值;
- update語法可以新增、更新原有表行中的各列,
- set子句指示要修改哪些列和要給予哪些值,
- where子句指定應更新哪些行,如果沒有where子句,則更新所有的行,
update user_info set username = "poopoo" where userid = 1;
查(select)
具體詳情查看后面實踐
6.資料表的排序、聚合命令、分組
-
排序(order by)
-
使用order by子句,對查詢結果進行排序,
-
order by 指定排序的列 asc(升序)/desc(降序),
-
order by 子句一般位于select陳述句的結尾,
SELECT product_name,weight FROM products_info ORDER BY weight DESC; -
-
聚合命令
-
distinct:對某一列資料去重,陳述句:select distinct 列名 from 表名; -- 顯示此列不重復的資料
-
count:統計總行數,- count(*):包括所有列,回傳表中的總行數,在統計結果的時候,不會忽略值為Null的行數,
- count(1):包括所有列,1表示一個固定值,沒有實際含義,在統計結果的時候,不會忽略列值為Null的行數,和count(*)的區別是執行效率不同,
- count(列名):只包括列名指定列,回傳指定列的行數,在統計結果的時候,不統計列值為Null,即列值為Null的行數不統計在內,
- count(distinct 列名):回傳指定列的不重復的行數,在統計結果的時候,會忽略列值為NULL的行數(不包括空字符和0),即列值為NULL的行數不統計在內,
- count(*)、count(1)、count(列名)執行效率比較:
- 如果列為主鍵,count(列名)優于count(1)
- 如果列不為主鍵,count(1)優于count(列名)
- 如果表中存在主鍵,count(主鍵列名)效率最優
- 如果表中只有一列,則count(*)效率最優
- 如果表中有多列,且不存在主鍵,則count(1)效率優于count(*)
-
MAX:最大值 -
MIN:最小值 -
AVG:平均值 -
SUM:求和select max(列名) from 表名; select min(列名) from 表名; select avg(列名) from 表名; select sum(列名) from 表名; - 也可以跟where子句 -
limit:語法:
-
select * from 表名 limit m,n;
-
其中m是指從哪行開始,m從0取值,0表示第一行,
-
n是指從第m+1條開始,取n條,
-
select * from 表名 limit 0,2(從第一行開始,顯示兩行結果)
-
如果只給定一個引數,它表示回傳最大的行數目:
select * from table limit 5;查詢前5行
-
limit n 等價于 limit 0,n
-
-
-
分組
GROUP BY-
使用group by子句對列進行分組,
-
然后還可以使用having子句過濾,having通常跟在group by后,它作用于組,
-
不加having過濾:
select 列名,聚合函式 from 表名 where 子句 group by 列名;
-
加上having過濾:
select 列名,聚合函式 from 表名 where 子句 group by 列名 having 聚合函式 過濾條件;
-
注意:使用group by后只能展示分組的列名+聚合函式結果,因為其余列已經基于分組這一列合并,
select sum(price), count(user_id), product_id from order_info_table group by product_id having count(user_id) > 2; -
7.資料表的連接查詢、子查詢
-
兩張表連接查詢
INNER JOIN(內連接):獲取兩個表中欄位匹配關系的行的所有資訊,語法:SELECT * FROM [表名] a INNER JOIN [表名] b ON a.[列名] = b.[列名];
例如:
SELECT * FROM user_info_table a INNER JOIN order_info_table b ON a.user_id = b.user_id; SELECT * FROM user_info_table a INNER JOIN order_info_table b ON a.user_id = b.user_id WHERE b.user_id IS NULL;LEFT JOIN(左連接):獲取左表所有行的資訊,即使右表沒有對應匹配的行的資訊,右表沒有匹配的部分用NULL代替,語法:SELECT * FROM [表名] a LEFT JOIN [表名] b ON a.[列名] = b.[列名];
SELECT * FROM products_info a LEFT JOIN suppliers_info b ON a.supplier_id = b.supplier_id;RIGHT JOIN(右連接):與左連接相反,用于獲取右表所有記錄,及時左表沒有對應匹配的行的所有資訊,左表沒有匹配的部分用NULL代替,語法:SELECT * FROM [表名] a RIGHT JOIN [表名] b ON a.[列名] = b.[列名];
SELECT * FROM products_info a RIGHT JOIN suppliers_info b ON a.supplier_id = b.supplier_id; -
子查詢(嵌套查詢)
- 嵌套在其他查詢中的查詢,
- 陳述句:select 列名1 from 表1 where 列名2 in (select 列名2 from 表2 where 列名3 = 某某某);
- 注意:一般在子查詢中,程式先運行嵌套在最內層的陳述句,再運行外層,因此在寫子查詢陳述句時,可以先測驗一下內層的子查詢陳述句是否輸出了想要的內容,再一層一層往外測驗,增加子查詢的正確率,
??補充:
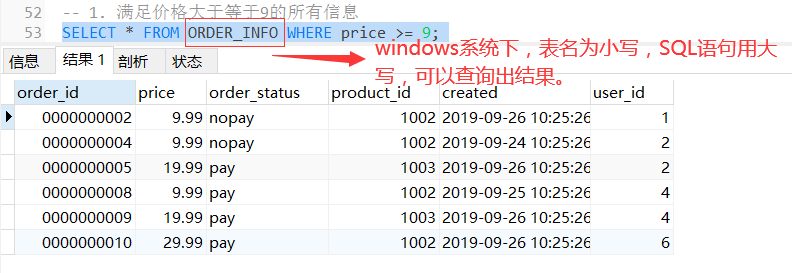
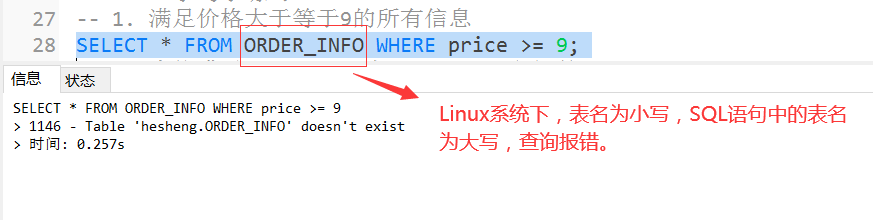
資料庫名和表名在windows中是大小寫不敏感的,而在大多數型別的UNIX系統中大小寫是敏感的,
練習題:
一、創建如下要求的表格,并完成相應的題目,
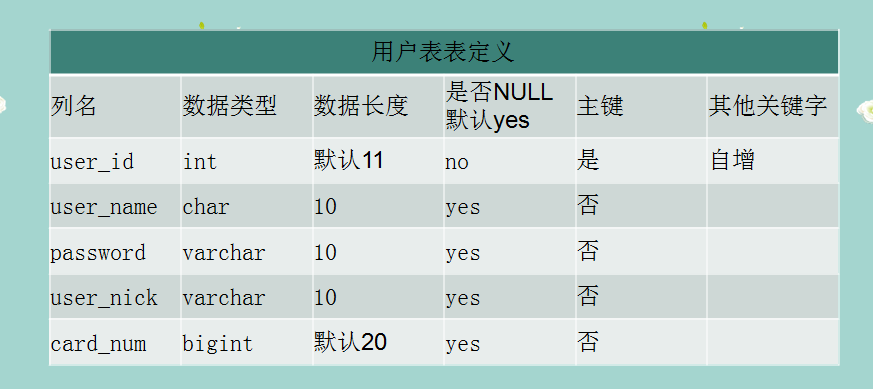
-- 創建表
CREATE TABLE user_info (
user_id INT NOT NULL AUTO_INCREMENT,
user_name CHAR ( 10 ),
password VARCHAR ( 10 ),
user_nick VARCHAR ( 10 ),
card_num BIGINT,
PRIMARY KEY ( user_id )
);
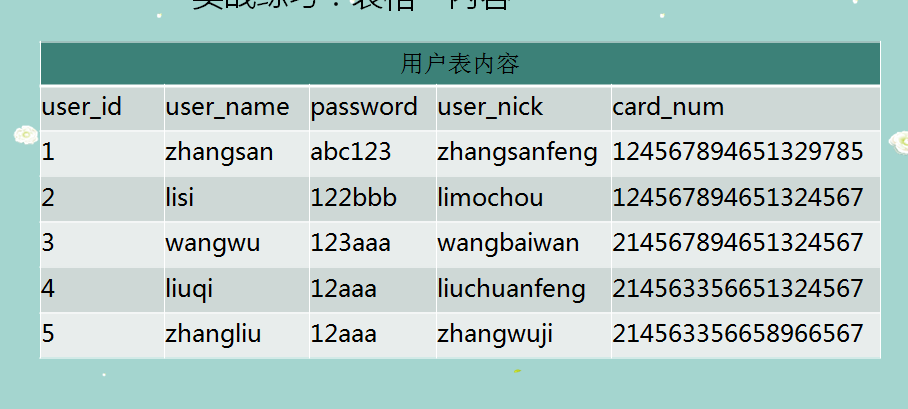
-- 插入資料
INSERT INTO user_info ( user_id, user_name, PASSWORD, user_nick, card_num )
VALUES
( 1, 'zhangsan', 'abc123', 'zhangsanfeng', 124567894651329785 ),
( 2, 'lisi', '122bbb', 'limochou', 124567894651324567 ),
( 3, 'wangwu', '123aaa', 'wangbaiwan', 214567894651324567 ),
( 4, 'liuqi', '12aaa', 'liuchuanfeng', 214563356651324567 ),
( 5, 'zhangliu', '12aaa', 'zhangwuji', 214563356658966567 );
-- user_nick長度不夠,修改user_nick的長度再重新插入資料
ALTER TABLE user_info MODIFY user_nick VARCHAR ( 20 );
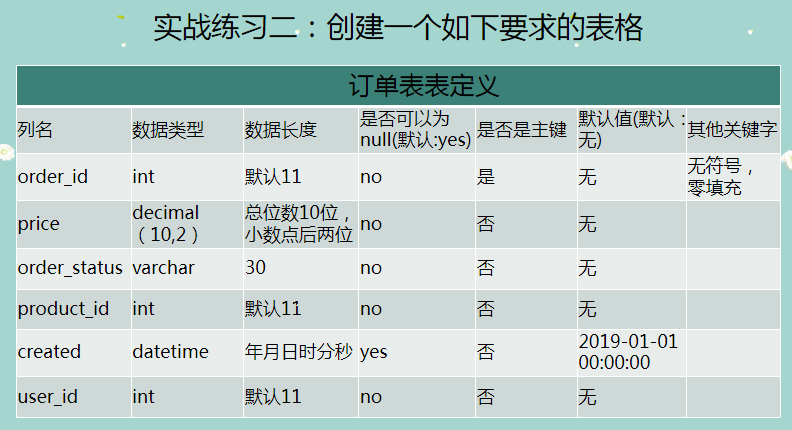
-- 創建訂單表
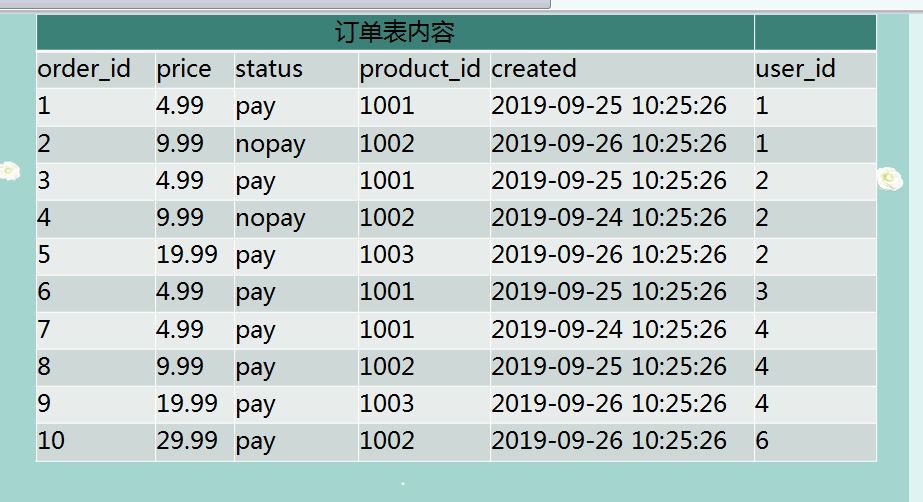
CREATE TABLE order_info (
order_id INT UNSIGNED ZEROFILL NOT NULL,
price DECIMAL ( 10, 2 ) NOT NULL,
order_status VARCHAR ( 30 ) NOT NULL,
product_id INT NOT NULL,
created datetime DEFAULT "2019-01-01 00:00:00",
user_id INT NOT NULL,
PRIMARY KEY ( order_id )
);
-- 插入資料
INSERT INTO order_info
VALUES
( 1, 4.99, 'pay', 1001, '2019-09-25 10:25:26', 1 ),
( 2, 9.99, 'nopay', 1002, '2019-09-26 10:25:26', 1 ),
( 3, 4.99, 'pay', 1001, '2019-09-25 10:25:26', 2 ),
( 4, 9.99, 'nopay', 1002, '2019-09-24 10:25:26', 2 ),
( 5, 19.99, 'pay', 1003, '2019-09-26 10:25:26', 2 ),
( 6, 4.99, 'pay', 1001, '2019-09-25 10:25:26', 3 ),
( 7, 4.99, 'pay', 1001, '2019-09-25 10:25:26', 4 ),
( 8, 9.99, 'pay', 1002, '2019-09-25 10:25:26', 4 ),
( 9, 19.99, 'pay', 1003, '2019-09-26 10:25:26', 4 ),
( 10, 29.99, 'pay', 1002, '2019-09-26 10:25:26', 6 );
-- where子句小練習
-- 1. 滿足價格大于等于9的所有資訊
SELECT * FROM order_info WHERE price >= 9;
-- 2. 查找滿足product_id在1002和1003之間的
SELECT * FROM order_info WHERE product_id BETWEEN 1002 AND 1003;
-- 3. 查找user_id在1、3、5這三個數內的資訊
SELECT * FROM order_info WHERE user_id IN (1,3,5);
-- 4. 查找訂單狀態是已支付的資訊
SELECT * FROM order_info WHERE order_status = 'pay';
-- 5. 查找用戶名類似于已li開頭的資訊
SELECT * FROM user_info WHERE user_name LIKE 'li%';
-- 6. 查找用戶名中第二個字母是h的資訊
SELECT * FROM user_info WHERE user_name LIKE '_h%';
-- 7. 查找用戶名中第二個字母不是h的資訊
SELECT * FROM user_info WHERE user_name NOT LIKE '_h%';
-- 8. 查找用戶名中最后一個字母以i結尾的資訊
SELECT * FROM user_info WHERE user_name LIKE '%i';
-- 9. 查找價格大于8,并且訂單狀態是已支付的所有資訊
SELECT * FROM order_info WHERE price > 8 AND order_status = 'pay';
-- 10.查找用戶表中user_nick為null的資訊
SELECT * FROM user_info WHERE user_nick IS NULL;
-- 11.查找用戶表中user_nick為 not null的資訊
SELECT * FROM user_info WHERE user_nick IS NOT NULL;
-- 聚合函式練習
-- 1. 查找訂單表中最大的價格,查找訂單表中最小的價格
SELECT MAX(price),MIN(price) FROM order_info;
-- 2. 查找訂單表中user_id=2的最小價格
SELECT MIN(price) FROM order_info WHERE user_id = 2;
-- 3. 分別列出訂單表中user_id=2的最小價格和最大價格
SELECT MIN(price),MAX(price) FROM order_info WHERE user_id = 2;
-- 4. 分別列出訂單表中user_id=2的最小價格和最大價格,并把最小價格的展示結果的列名改為"min_price"
SELECT MIN(price) AS min_price,MAX(price) FROM order_info WHERE user_id = 2;
-- 5. 求訂單表的價格的平均值,求訂單表中user_id=2的價格的平均值
SELECT AVG(price) FROM order_info;
SELECT AVG(price) FROM order_info WHERE user_id = 2;
-- 6. 分別列出訂單表中user_id=2的價格的平均值、最小值、最大值
SELECT AVG(price),MIN(price),MAX(price) FROM order_info WHERE user_id = 2;
-- 7. 求訂單表中user_id=1的價格的總和
SELECT SUM(price) FROM order_info WHERE user_id = 1;
-- 8. 求訂單表中user_id=1或者user_id=3的價格總和
SELECT SUM(price) FROM order_info WHERE user_id = 1 OR user_id = 3;
-- 分組練習
-- 1.首先篩選狀態為已支付的訂單,然后按照user_id分組,分組后每一組對支付金額進行求和,最終展示user_id和對應組求和金額
SELECT user_id,SUM(price) FROM order_info WHERE order_status = 'pay' GROUP BY user_id;
-- 2.首先篩選狀態為支付的訂單,然后按照user_id分組,分組后每一組對支付金額進行求和,再過濾求和金額大于10的,最終展示user_id和對應組的求和金額
SELECT user_id,SUM(price) FROM order_info WHERE order_status = 'pay' GROUP BY user_id HAVING SUM(price) > 10;
-- 資料表連接查詢和子查詢練習
-- 1.查詢訂單表中的價格大于10元的用戶的昵稱(小提示:用戶昵稱在用戶表中,訂單價格在訂單表中)
SELECT a.user_nick FROM user_info a INNER JOIN order_info b ON a.user_id = b.user_id WHERE b.price > 10;
SELECT user_nick FROM user_info WHERE user_id IN (SELECT user_id FROM order_info WHERE price > 10);
-- 2.查詢用戶名以l開頭的用戶買過的所有訂單id和對應價格(小提示:訂單id和對應價格在訂單表中,用戶名在用戶表中)
SELECT o.order_id,o.price FROM order_info o WHERE o.user_id IN (SELECT user_id FROM user_info u WHERE u.user_name LIKE 'l%');
二、創建如下要求的表格,并完成相應的題目,
-- 1.按照表定義創建商品表+供應商表
-- 2.按照表資料插入所有資料
-- 創建商品表
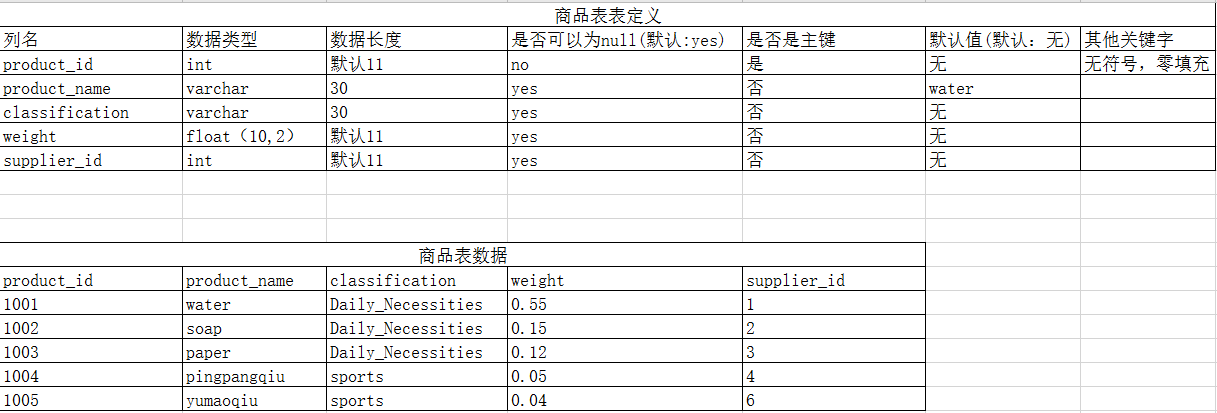
CREATE TABLE products_info (
product_id INT UNSIGNED ZEROFILL NOT NULL,
product_name VARCHAR ( 30 ) DEFAULT 'water',
classification VARCHAR ( 30 ),
weight FLOAT ( 10, 2 ),
supplier_id INT,
PRIMARY KEY ( product_id )
);
-- 向商品表插入資料
INSERT INTO products_info
VALUES
( 1001, 'water', 'Daily_Necessities', 0.55, 1 ),
( 1002, 'soap', 'Daily_Necessities', 0.15, 2 ),
( 1003, 'paper', 'Daily_Necessities', 0.12, 3 ),
( 1004, 'pingpangqiu', 'sports', 0.05, 4 ),
( 1005, 'yumaoqiu', 'sports', 0.04, 6 );
-- 創建供應商表
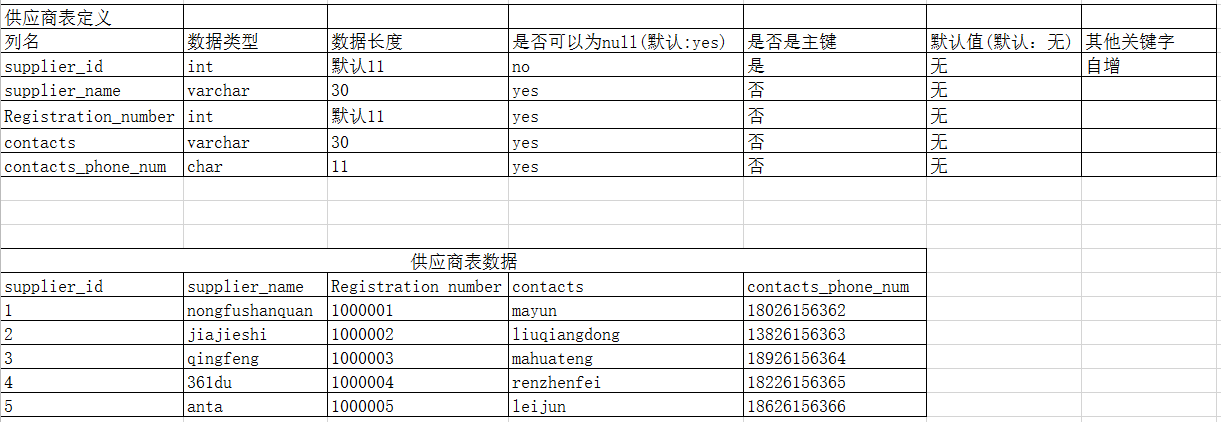
CREATE TABLE suppliers_info (
supplier_id INT NOT NULL AUTO_INCREMENT,
supplier_name VARCHAR ( 30 ),
Registration_number INT,
contacts VARCHAR ( 30 ),
contacts_phone_num CHAR ( 11 ),
PRIMARY KEY ( supplier_id )
);
-- 向供應商表插入資料
INSERT INTO suppliers_info
VALUES
( 1, 'nongfushanquan', 1000001, 'mayun', '18026156362' ),
( 2, 'jiajieshi', 1000002, 'liuqiangdong', '13826156363' ),
( 3, 'qingfeng', 1000003, 'mahuateng', '18926156364' ),
( 4, '361du', 1000004, 'renzhenfei', '18226156365' ),
( 5, 'anta', 1000005, 'leijun', '18626156366' );
-- 3.修改供應商id為4的供應商名稱為‘hongshuangxi’
UPDATE suppliers_info SET supplier_name = 'hongshuangxi' WHERE supplier_id = 4;
-- 4.查詢商品重量大于0.10的商品的名稱
SELECT product_name FROM products_info WHERE weight > 0.10;
-- 5.查詢商品名稱以字母p開頭的商品的所有資訊
SELECT * FROM products_info WHERE product_name like 'p%';
-- 6.查詢商品重量大于0.10,小于0.20的商品名稱
SELECT product_name FROM products_info WHERE weight > 0.10 AND weight < 0.20;
-- 7.按照商品分類統計各自的商品總個數,顯示每個分類和其對應的商品總個數
SELECT classification,COUNT(classification) FROM products_info GROUP BY classification;
-- 8.將所有商品的名稱按照商品重量由高到低顯示
SELECT product_name,weight FROM products_info ORDER BY weight DESC;
-- 9.顯示所有商品的資訊,在右邊顯示有供應商的商品對應的供應商資訊
SELECT * FROM products_info a LEFT JOIN suppliers_info b ON a.supplier_id = b.supplier_id;
-- 10.顯示重量大于等于0.15的商品的供應商的聯系人和手機號
SELECT s.contacts,s.contacts_phone_num FROM suppliers_info s INNER JOIN products_info p ON s.supplier_id = p.supplier_id and p.weight >= 0.15;
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/250070.html
標籤:其他
上一篇:網路攻防實訓 第七天