文章目錄
- 引入
- 1 Adam介紹
- 2 具體實作
引入
??用torch的時候,有個老幾出現頻率忒高,讓不了解它的我蠢蠢欲動,這究竟是何方神圣?
1 Adam介紹
??最開始的GD很慢,每次只愛一個樣本,SGD想要改變,又是隨機,又是批量,后來加了自適應,何苦學習率開始基情滿滿,越往后越敷衍,
??RMSprop則不同了,生是讓學習率一個勁往上😘
??Adam則是集大成者

??更新程序如下:
v
t
=
β
1
v
t
?
1
+
(
1
+
β
1
)
g
r
a
d
t
s
t
=
β
2
s
t
?
1
+
(
1
?
β
2
)
g
r
a
d
t
2
\begin{aligned} v_t & = \beta_1 v_{t - 1} + (1 + \beta_1)grad_t\\ s_t & = \beta_2 s_{t - 1} + (1 - \beta_2)grad_t^2 \end{aligned}
vt?st??=β1?vt?1?+(1+β1?)gradt?=β2?st?1?+(1?β2?)gradt2??這里
v
v
v和
s
s
s是不同的動量,前者用于記錄上一次的梯度,后者則保留RMSprop的特長,
??
v
v
v和
s
s
s偏導計算如下:
v
t
′
=
v
t
1
?
β
1
t
s
t
′
=
s
t
1
?
β
2
t
\begin{aligned} v_t' & = \frac{v_t}{1 - \beta_1^t}\\ s_t' & = \frac{s_t}{1-\beta_2^t} \end{aligned}
vt′?st′??=1?β1t?vt??=1?β2t?st?????最終的更新如下:
g
r
a
d
t
′
=
l
r
?
v
t
′
s
t
′
+
?
θ
t
=
θ
t
?
1
?
g
r
a
d
t
′
\begin{aligned} grad_t' & = \frac{lr * v_t'}{\sqrt{s_t'} + \epsilon}\\ \theta_t & = \theta_{t - 1} - grad_t' \end{aligned}
gradt′?θt??=st′?
?+?lr?vt′??=θt?1??gradt′??
2 具體實作
??使用如下例子:
f
(
x
)
=
a
x
+
b
(
y
?
f
(
x
)
)
2
=
(
y
?
(
a
x
+
b
)
)
2
d
y
d
a
=
?
2
x
(
y
?
(
a
x
+
b
)
)
d
y
d
b
=
?
2
(
y
?
(
a
x
+
b
)
)
\begin{aligned} f(x) &= a x+b \\ (y-f(x))^{2} & =(y-(a x+b))^{2} \\ \frac{d y}{d a} &=-2 x(y-(a x+b)) \\ \frac{d y}{d b} &=-2(y-(a x+b)) \end{aligned}
f(x)(y?f(x))2dady?dbdy??=ax+b=(y?(ax+b))2=?2x(y?(ax+b))=?2(y?(ax+b))?
import numpy as np
import matplotlib.pyplot as plt
from sympy import symbols, diff
def get_data():
ret_x = np.linspace(-1, 1, 100)
return ret_x, [(lambda x: 2 * x + 3)(x) for x in ret_x]
def grad():
x, y, a, b = symbols(["x", "y", "a", "b"])
loss = (y - (a * x + b))**2
return diff(loss, a), diff(loss, b)
def test2(n_iter=50, lr=0.1, batch_size=20, beta1=0.9, beta2=0.999, epsilon=1e-6, shuffle=True):
x, y = get_data()
ga, gb = grad()
n = len(x)
idx = np.random.permutation(n)
s, v = 0, 0
a, b = 0, 0
move_a, move_b = [a], [b]
move_lr_a, move_lr_b = [lr], [lr]
t = 1
for _ in range(n_iter):
if shuffle:
np.random.shuffle(idx)
batch_idxes = [idx[k: k + batch_size] for k in range(0, n, batch_size)]
for idxes in batch_idxes:
sum_ga, sum_gb = 0, 0
for j in idxes:
sum_ga += ga.subs({"x": x[j], "y": y[j], "a": a, "b": b})
sum_gb += gb.subs({"x": x[j], "y": y[j], "a": a, "b": b})
sum_ga /= batch_size
sum_gb /= batch_size
g = np.array([sum_ga, sum_gb])
v = beta1 * v + (1 - beta1) * g
s = beta2 * s + (1 - beta2) * g * g
v_norm = v / (1 - np.power(beta1, t))
s_norm = s / (1 - np.power(beta2, t))
t += 1
lr_a, lr_b = lr * v_norm[0], lr * v_norm[1]
move_lr_a.append(lr_a)
move_lr_b.append(lr_b)
g_a_norm = lr_a / (np.sqrt(float(s_norm[0])) + epsilon)
g_b_norm = lr_b / (np.sqrt(float(s_norm[1])) + epsilon)
a -= g_a_norm
b -= g_b_norm
move_a.append(a)
move_b.append(b)
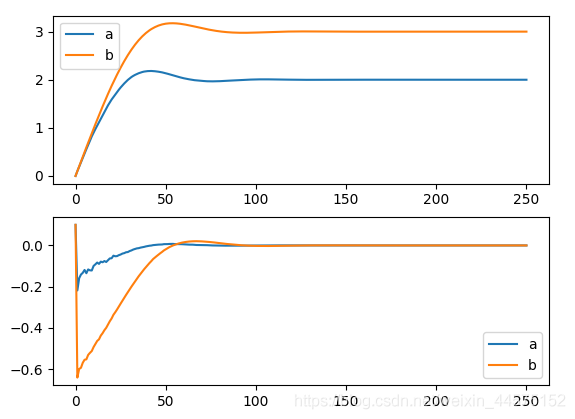
plt.subplot(211)
plt.plot(move_a)
plt.plot(move_b)
plt.legend(["a", "b"])
plt.subplot(212)
plt.plot(move_lr_a)
plt.plot(move_lr_b)
plt.legend(["a", "b"])
plt.show()
if __name__ == '__main__':
test2()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/250219.html
標籤:其他
上一篇:Java學習
下一篇:三分法求函式極值