Python的垃圾回識訓制到底是什么回事?
從網上找到一大堆的檔案,看的也是一知半解,最終就學會了一句話:參考計數器為主、分代碼回收和標記清除為輔,
就這么一知半解地去忽悠面試官了,如果面試官恰好也只會這幾句話,那便達成和解了,如果不是,那"今天暫時先這樣,你回去等訊息吧",

本篇文章從C語言原始碼底層來聊聊Python記憶體管理和垃圾回識訓制到底是個啥?讓你能夠真正了解記憶體管理&垃圾回收,
用通俗的語言解釋記憶體管理和垃圾回收的程序,搞懂這一部分就可以去面試、去裝B了,

在Python的C原始碼中有一個名為refchain的環狀雙向鏈表,這個鏈表比較牛逼了,因為Python程式中一旦創建物件都會把這個物件添加到refchain這個鏈表中,也就是說他保存著所有的物件,例如:

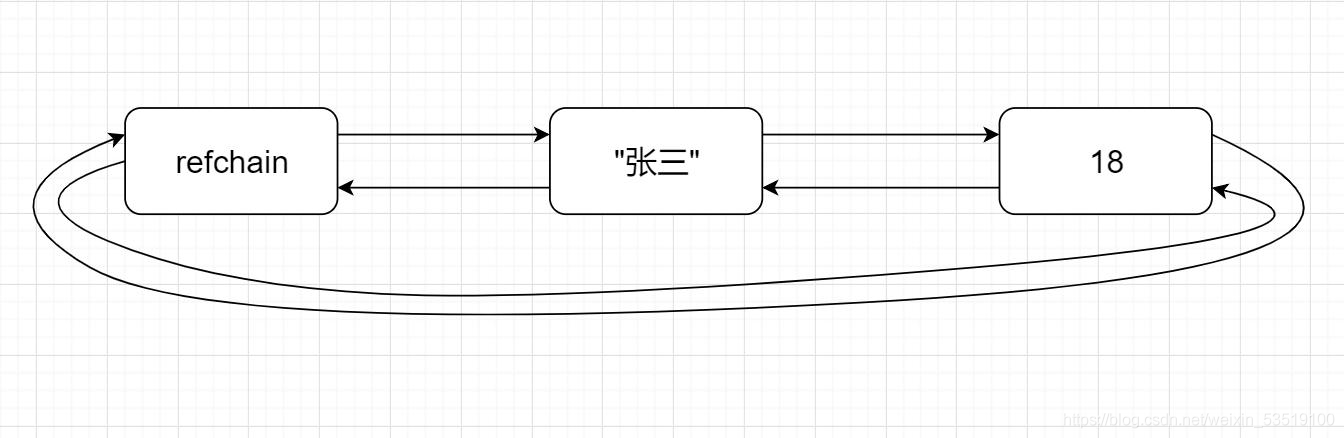
 在refchain中的所有物件內部都有一個ob_refcnt用來保存當前物件的參考計數器,顧名思義就是自己被參考的次數,例如:
在refchain中的所有物件內部都有一個ob_refcnt用來保存當前物件的參考計數器,顧名思義就是自己被參考的次數,例如:
 上述代碼表示記憶體中有 18 和 “張三” 兩個值,他們的參考計數器分別為:1、2 ,
上述代碼表示記憶體中有 18 和 “張三” 兩個值,他們的參考計數器分別為:1、2 ,
 當值被多次參考時候,不會在記憶體中重復創建資料,而是參考計數器+1 , 當物件被銷毀時候同時會讓參考計數器-1,如果參考計數器為0,則將物件從refchain鏈表中摘除,同時在記憶體中進行銷毀(暫不考慮快取等特殊情況),
當值被多次參考時候,不會在記憶體中重復創建資料,而是參考計數器+1 , 當物件被銷毀時候同時會讓參考計數器-1,如果參考計數器為0,則將物件從refchain鏈表中摘除,同時在記憶體中進行銷毀(暫不考慮快取等特殊情況),

 基于參考計數器進行垃圾回收非常方便和簡單,但他還是存在回圈參考的問題,導致無法正常地回收一些資料,例如:
基于參考計數器進行垃圾回收非常方便和簡單,但他還是存在回圈參考的問題,導致無法正常地回收一些資料,例如:
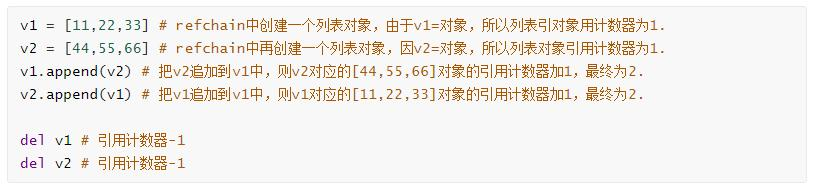 對于上述代碼會發現,執行del操作之后,沒有變數再會去使用那兩個串列物件,但由于回圈參考的問題,他們的參考計數器不為0,所以他們的狀態:永遠不會被使用、也不會被銷毀,專案中如果這種代碼太多,就會導致記憶體一直被消耗,直到記憶體被耗盡,程式崩潰,
對于上述代碼會發現,執行del操作之后,沒有變數再會去使用那兩個串列物件,但由于回圈參考的問題,他們的參考計數器不為0,所以他們的狀態:永遠不會被使用、也不會被銷毀,專案中如果這種代碼太多,就會導致記憶體一直被消耗,直到記憶體被耗盡,程式崩潰,
為了解決回圈參考的問題,引入了標記清除技術,專門針對那些可能存在回圈參考的物件進行特殊處理,可能存在回圈應用的型別有:串列、元組、字典、集合、自定義類等那些能進行資料嵌套的型別,
1.標記清除:創建特殊鏈表專門用于保存 串列、元組、字典、集合、自定義類等物件,之后再去檢查這個鏈表中的物件是否存在回圈參考,如果存在則讓雙方的參考計數器均 - 1 ,
2.分代回收:對標記清除中的鏈表進行優化,將那些可能存在循參考的物件拆分到3個鏈表,鏈表稱為:0/1/2三代,每代都可以存盤物件和閾值,當達到閾值時,就會對相應的鏈表中的每個物件做一次掃描,除回圈參考各自減1并且銷毀參考計數器為0的物件,
 3.特別注意:0代和1、2代的threshold和count表示的意義不同,
3.特別注意:0代和1、2代的threshold和count表示的意義不同,
0代,count表示0代鏈表中物件的數量,threshold表示0代鏈表物件個數閾值,超過則執行一次0代掃描檢查,
1代,count表示0代鏈表掃描的次數,threshold表示0代鏈表掃描的次數閾值,超過則執行一次1代掃描檢查,
2代,count表示1代鏈表掃描的次數,threshold表示1代鏈表掃描的次數閾值,超過則執行一2代掃描檢查,
 根據C語言底層并結合圖來講解記憶體管理和垃圾回收的詳細程序,
根據C語言底層并結合圖來講解記憶體管理和垃圾回收的詳細程序,
**一:**當創建物件age=19時,會將物件添加到refchain鏈表中,
 **二:**當創建物件num_list = [11,22]時,會將串列物件添加到 refchain 和 generations 0代中,
**二:**當創建物件num_list = [11,22]時,會將串列物件添加到 refchain 和 generations 0代中,
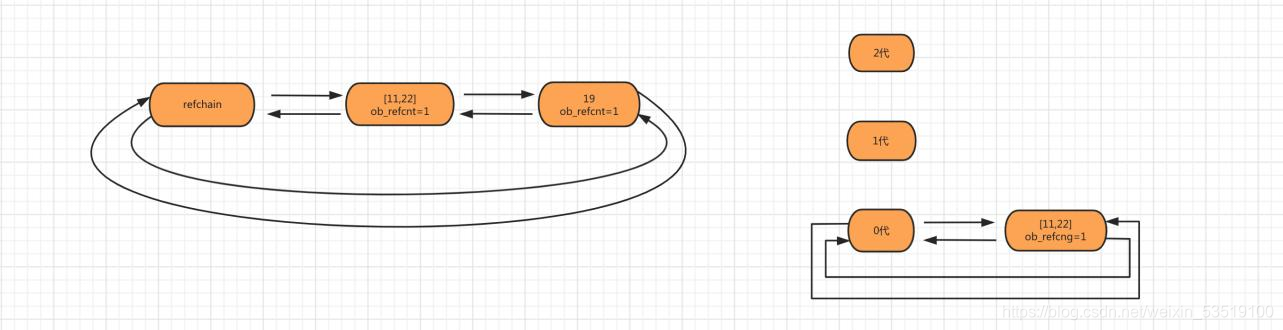
**三:**新創建物件使generations的0代鏈表上的物件數量大于閾值700時,要對鏈表上的物件進行掃描檢查,當0代大于閾值后,底層不是直接掃描0代,而是先判斷2、1是否也超過了閾值,
1.如果2、1代未達到閾值,則掃描0代,并讓1代的 count + 1
2.如果2代已達到閾值,則將2、1、0三個鏈表拼接起來進行全掃描,并將2、1、0代的count重置為0
3.如果1代已達到閾值,則將1、0兩個鏈表拼接起來進行掃描,并將所有1、0代的count重置為0
對拼接起來的鏈表在進行掃描時,主要就是剔除回圈參考和銷毀垃圾,詳細程序為:
掃描鏈表,把每個物件的參考計數器拷貝一份并保存到 gc_refs中,保護原參考計數器,
再次掃描鏈表中的每個物件,并檢查是否存在回圈參考,如果存在則讓各自的gc_refs減 1
再次掃描鏈表,將 gc_refs 為 0 的物件移動到unreachable鏈表中;不為0的物件直接升級到下一代鏈表中
處理unreachable鏈表中的物件的 解構式 和 弱參考,不能被銷毀的物件升級到下一代鏈表,能銷毀的保留在此鏈表
解構式,指的就是那些定義了__del__方法的物件,需要執行之后再進行銷毀處理
弱參考
最后將 unreachable 中的每個物件銷毀并在refchain鏈表中移除(不考慮快取機制)
至此,垃圾回收的程序結束,
 從上文大家可以了解到當物件的參考計數器為0時,就會被銷毀并釋放記憶體,而實際上他不是這么的簡單粗暴,因為反復的創建和銷毀會使程式的執行效率變低,Python中引入了"快取機制"機制,
從上文大家可以了解到當物件的參考計數器為0時,就會被銷毀并釋放記憶體,而實際上他不是這么的簡單粗暴,因為反復的創建和銷毀會使程式的執行效率變低,Python中引入了"快取機制"機制,
例如:參考計數器為0時,不會真正銷毀物件,而是將他放到一個名為 free_list 的鏈表中,之后會再創建物件時不會在重新開辟記憶體,而是在free_list中將之前的物件來并重置內部的值來使用,
float型別,維護的free_list鏈表最多可快取100個float物件,
 · int型別,不是基于freelist,而是維護一個smallints鏈表保存常見資料(小資料池),小資料池范圍:-5 <= value < 257,即:重復使用這個范圍的整數時,不會重新開辟記憶體,
· int型別,不是基于freelist,而是維護一個smallints鏈表保存常見資料(小資料池),小資料池范圍:-5 <= value < 257,即:重復使用這個范圍的整數時,不會重新開辟記憶體,
 str型別,維護unicode_latin1[256]鏈表,內部將所有的ascii字符快取起來,以后使用時就不再反復創建
str型別,維護unicode_latin1[256]鏈表,內部將所有的ascii字符快取起來,以后使用時就不再反復創建
 ·
除此之外,Python內部還對字串做了駐留機制,針對那么只含有字母、數字、下劃線的字串(見原始碼Objects/codeobject.c),如果記憶體中已存在則不會重新再創建而是使用原來的地址里(不會像free_list那樣一直在記憶體存活,只有記憶體中有才能被重復利用),
·
除此之外,Python內部還對字串做了駐留機制,針對那么只含有字母、數字、下劃線的字串(見原始碼Objects/codeobject.c),如果記憶體中已存在則不會重新再創建而是使用原來的地址里(不會像free_list那樣一直在記憶體存活,只有記憶體中有才能被重復利用),
 · list型別,維護的free_list陣列最多可快取80個list物件,
· list型別,維護的free_list陣列最多可快取80個list物件,
 tuple型別,維護一個freelist陣列且陣列容量20,陣列中元素可以是鏈表且每個鏈表最多可以容納2000個元組物件,元組的freelist陣列在存盤資料時,是按照元組可以容納的個數為索引找到free_list陣列中對應的鏈表,并添加到鏈表中,
tuple型別,維護一個freelist陣列且陣列容量20,陣列中元素可以是鏈表且每個鏈表最多可以容納2000個元組物件,元組的freelist陣列在存盤資料時,是按照元組可以容納的個數為索引找到free_list陣列中對應的鏈表,并添加到鏈表中,
 dict型別,維護的free_list陣列最多可快取80個dict物件,
dict型別,維護的free_list陣列最多可快取80個dict物件,
 上文對Python的記憶體管理和垃圾回收進行了快速講解,
上文對Python的記憶體管理和垃圾回收進行了快速講解,
在這里推薦一個軟體測驗交流群,QQ:642830685,群中會不定期的分享軟體測驗資源,測驗面試題以及測驗行業資訊,小伙伴們可以在群中積極交流,探討技術,還有對于Python的記憶體管理和垃圾回收,你有什么想說的嗎?歡迎留言交流呀,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/250489.html
標籤:其他