導語
邊緣場景下網路常常不可靠,容易誤觸發 Kubernetes 驅逐機制,引起不符合預期的 Pod 驅逐動作,TKE Edge 首創分布式節點狀態判定機制,該機制可以更好地識別驅逐時機,保障系統在弱網路下正常運轉,避免服務中斷和波動,
邊緣計算情境下,邊緣節點與云端的網路環境十分復雜,網路質量無法保證,容易出現 APIServer 和節點連接中斷的場景,如果不加改造直接使用原生 Kubernetes,節點狀態會經常出現例外,進而引起 Kubernetes 驅逐機制生效,導致 Pod 的驅逐和 Endpoint 的缺失,最終造成服務的中斷和波動,為了解決這個問題,TKE 邊緣容器團隊在邊緣集群弱網環境下提出了邊緣節點分布式節點狀態判定機制,可以更好地識別驅逐時機,
背景
不同于中心云,邊緣場景下,首先要面對云邊弱網路的環境,邊緣設備常常位于邊緣云機房、移動邊緣站點,與云端連接的網路環境十分復雜,不像中心云那么可靠,這其中既包含云端(控制端)和邊緣端的網路環境不可靠,也包含邊緣節點之間的網路環境不可靠,即使是同一區域不同機房之間也無法假設節點之間網路質量良好,
以智慧工廠為例,邊緣節點位于廠房倉庫和車間,控制端 Master 節點在騰訊云的中心機房內,
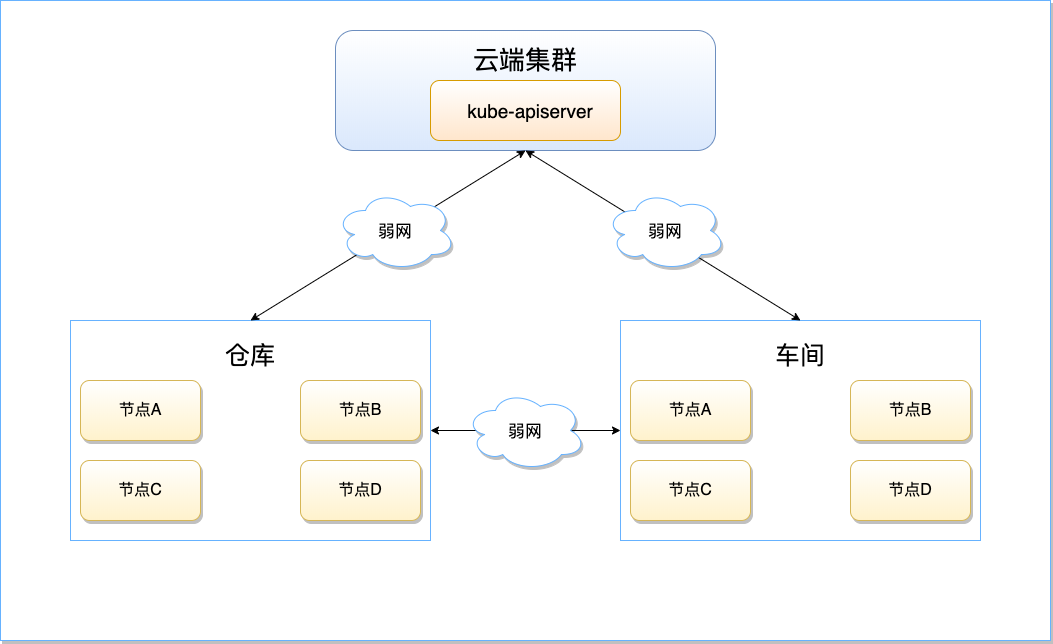
倉庫和車間內的邊緣設備同云端集群之間的網路較復雜,因特網、5G、WIFI 等形態均有可能,網路質量差次不齊沒有保障;但是,相比于和云端的網路環境,由于倉庫和車間內的邊緣設備之間是本地網路,因此網路質量肯定要優于同云端集群之間的連接,相對而言更加可靠,
造成的挑戰
原生 Kubernetes 處理方式
云邊弱網路帶來的問題是影響運行在邊緣節點上的 kubelet 與云端 APIServer 之間通信,云端 APIServer 無法收到 kubelet 的心跳或者續租,無法準確獲取該節點和節點上pod的運行情況,如果持續時間超過設定的閾值,APIServer 會認為該節點不可用,并做出如下一些動作:
- 失聯的節點狀態被置為 NotReady 或者 Unknown 狀態,并被添加 NoSchedule 和 NoExecute 的 taints
- 失聯的節點上的 Pod 被驅逐,并在其他節點上進行重建
- 失聯的節點上的 Pod 從 Service 的 Endpoint 串列中移除
需求場景
再看一個音視頻拉流場景,音視頻服務是邊緣計算的一個重要應用場景,如圖所示:
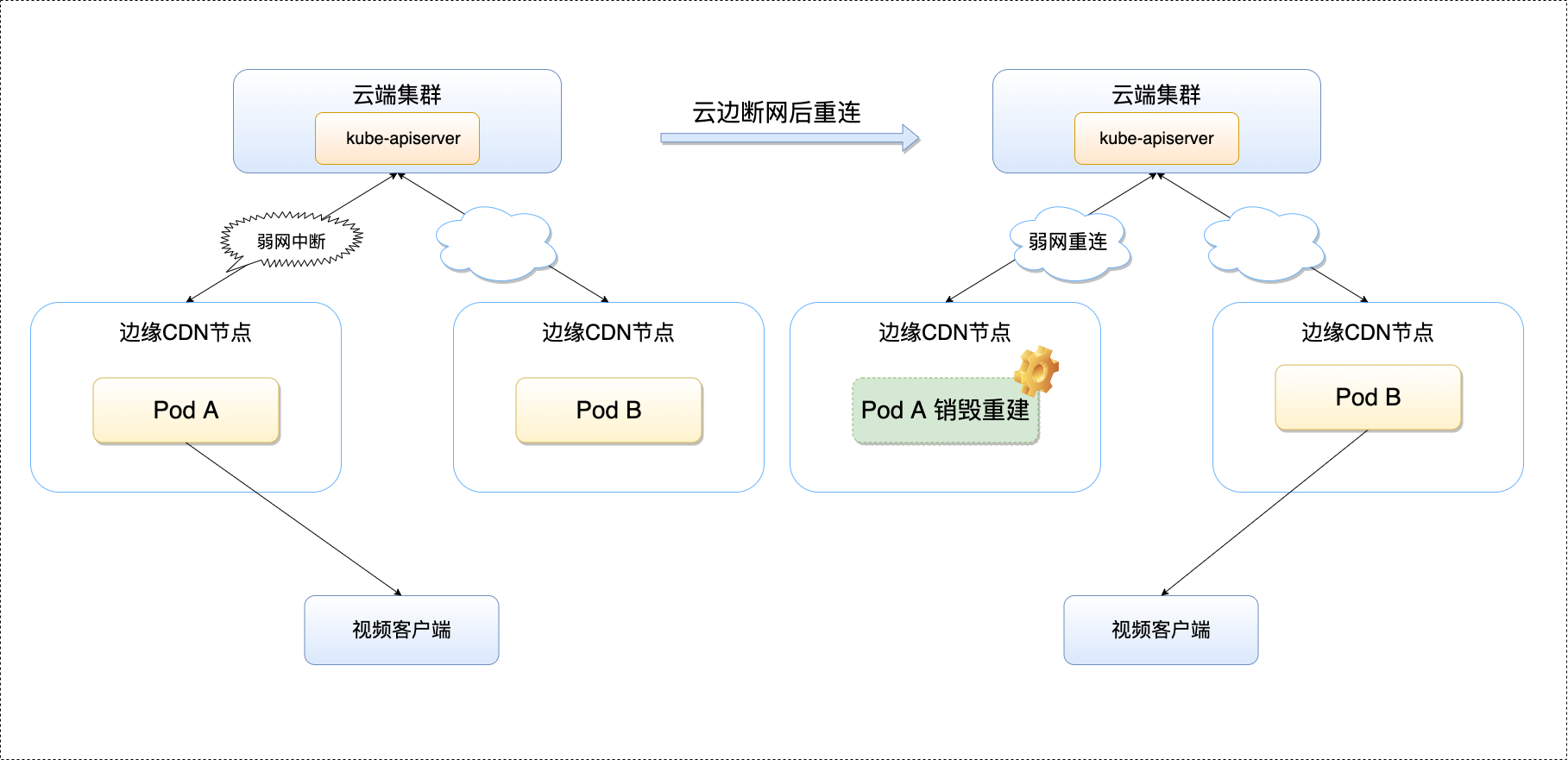
考慮到用戶體驗及公司成本,音視頻拉流經常需要提高邊緣快取命中率減少回源,將用戶請求的同一檔案調度到同一個服務實體以及服務實體快取檔案均是常見的做法,
然而,在原生 Kubernetes 的情況下,如果 Pod 因為網路波動而頻繁重建,一方面會影響服務實體快取效果,另一方面會引起調度系統將用戶請求調度到其他服務實體,無疑,這兩點都會對 CDN 效果造成極大的影響,甚至不能接受,
事實上,邊緣節點完全運行正常,Pod 驅逐或重建其實是完全不必要的,為了克服這個問題,保持服務的持續可用,TKE 邊緣容器團隊提出了分布式節點狀態判定機制,
解決方案
設計原則
顯然,在邊緣計算場景中,僅僅依賴邊緣端和 APIServer 的連接情況來判斷節點是否正常并不合理,為了讓系統更健壯,需要引入額外的判斷機制,
相較于云端和邊緣端,邊緣端節點之間的網路更穩定,如何利用更穩定的基礎設施來提高準確性呢?我們首創了邊緣健康分布式節點狀態判定機制,除了考慮節點與 APIServer 的連接情況,還引入了邊緣節點作為評估因子,以便對節點進行更全面的狀態判斷,經過測驗及大量的實踐證明,該機制在云邊弱網路情況下大大提高系統在節點狀態判斷上的準確性,為服務穩定運行保駕護航,
該機制的主要原理:
- 每個節點定期探測其他節點健康狀態
- 集群內所有節點定期投票決定各節點的狀態
- 云端和邊緣端節點共同決定節點狀態
首先,節點內部之間進行探測和投票,共同決定具體某個節點是否存在狀態例外,保證大多數節點的一致判斷才能決定節點的具體狀態;另外,雖說節點之間的網路狀態一般情況下要優于云邊網路,但同時應該注意到,邊緣節點之間網路情況也十分復雜,它們之間的網路也不是100%可靠,
因此,也不能完全信賴節點之間的網路,節點的狀態不能只由節點自行決定,云邊共同決定才更為可靠,基于這個考慮,我們做出了如下的設計:
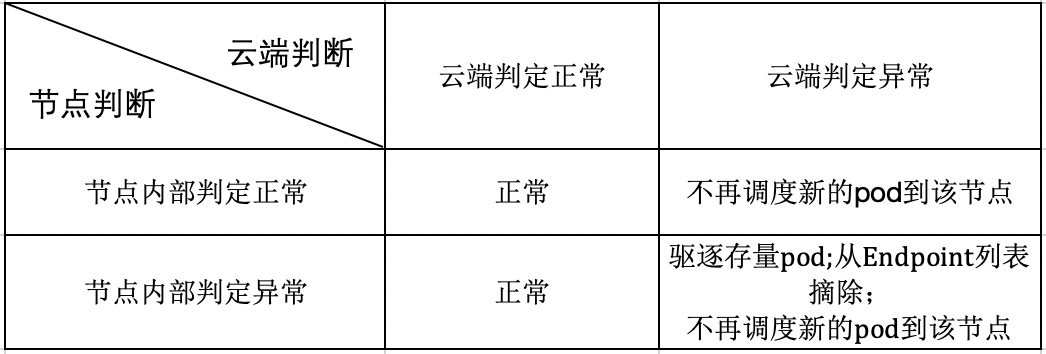
方案特性
需要注意的是,當云端判定節點例外,但是其他節點認為節點正常的時候,雖然不會驅逐已有 Pod,但是為了確保增量服務的穩定性,不會再將新的 Pod 調度到該節點上,存量的正常運行也得益于邊緣集群的邊緣自治能力;
另外,由于邊緣網路和拓撲的特殊性,常常會存在節點組之間網路單點故障的問題,比如廠房的例子中,倉庫和車間雖然都屬于廠房這個地域內,但是可能二者之間的網路連接依靠一條關鍵鏈路,一旦這條鏈路發生中斷,就會造成節點組之間的分裂,我們的方案能夠確保兩個分裂的節點組失聯后互相判定時始終保持多數的一方節點不會被判定為例外,避免被判定為例外造成 Pod 只能被調度到少部分的節點上,造成節點負載過高的情況,
除此之外,邊緣設備很有可能位于不同的地區、相互不通,讓網路不通的節點之間相互檢查顯然就不合適了,為了應對這種情況,我們的方案也支持對節點進行分組,各個分組內的節點之間相互檢測狀態,考慮到有可能對節點重新分組,機制也支持實時對節點變更分組而無需重新部署檢測組件或重新初始化,
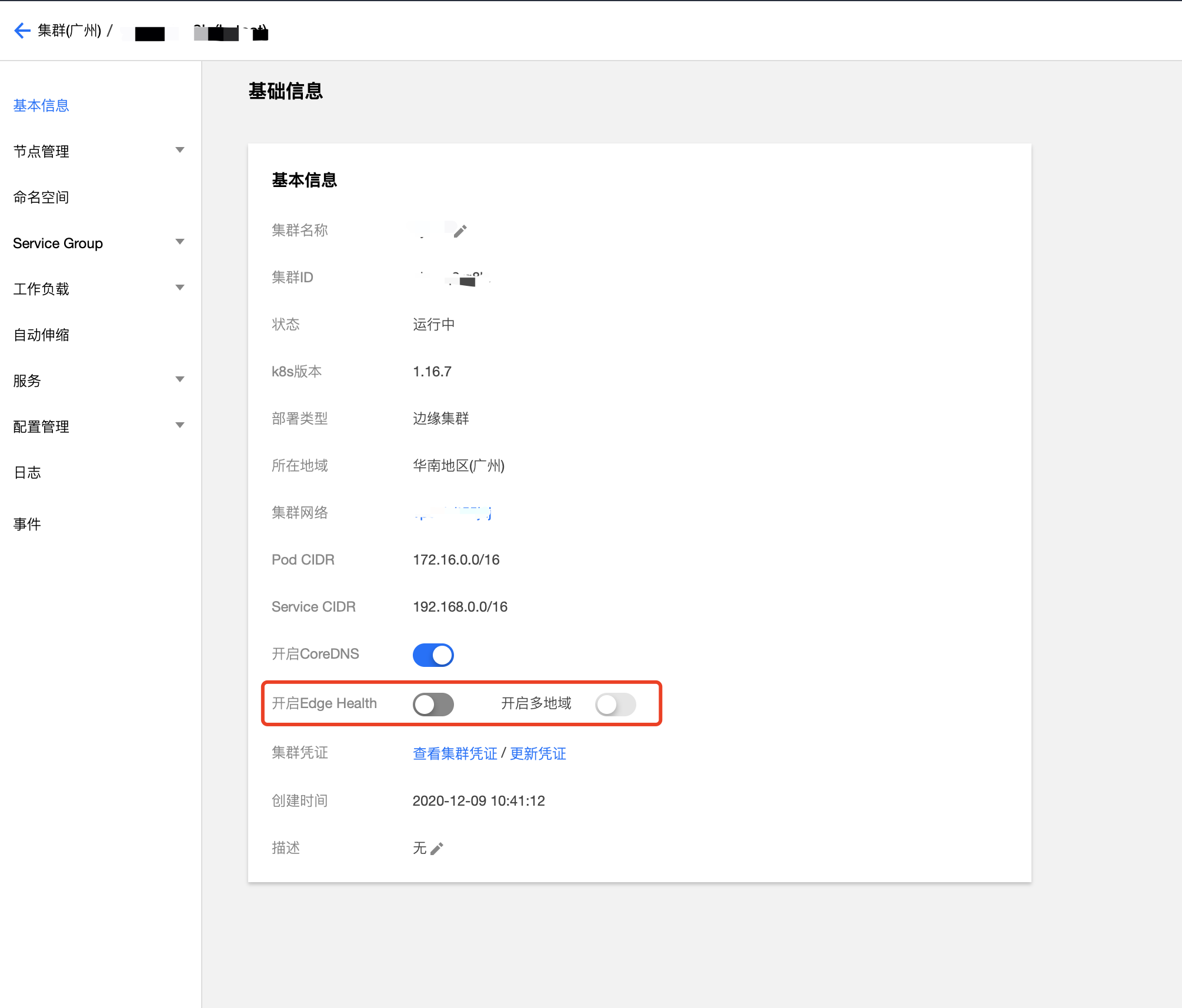
檢測機制默認關閉,如果需要操作可進入基本資訊-開啟 Edge Health(默認關閉),如果需要為節點分組,可以繼續打開“開啟多地域”,然后給節點分組,分組方式為編輯和添加節點相應的標簽;如果開啟多地域檢查后未給節點分組,默認是各個節點自己是一個組,不會檢查其他節點,
在此特性開發程序中,我們也發現了一個 node taint 相關的 Kubernetes 社區 bug 并提出了修復方案,
未來展望
未來我們會支持更多的檢查方式,增強在各種場景下的穩定性;此外,當前開源的一些去中心的集群狀態探測管理專案在一些場景下還不能完全滿足邊緣的場景,如集群分裂情況,后期我們會嘗試融合借鑒滿足我們的需求,
開源專案 SuperEdge
當前該組件作為邊緣容器專案 SuperEdge 的一部分已經對外開源(https://github.com/superedge/superedge),歡迎大家 star,下方是微信群,微信企業微信都可以加入
公有云產品 TKE Edge
目前該產品已經全量開放,歡迎前往 邊緣容器服務控制臺 進行體驗~
邊緣系列往期精彩推薦
- 【從0到1學習邊緣容器系列-1】之 邊緣計算與邊緣容器的起源
- 【從0到1學習邊緣容器系列-2】之 邊緣應用管理
- 【從0到1學習邊緣容器系列-3】應用容災之邊緣自治
- 完爆!用邊緣容器,竟能秒級實作團隊七八人一周的作業量
- 騰訊云聯合多家生態伙伴,重磅開源 SuperEdge 邊緣容器專案
- 云上視頻業務基于邊緣容器的技術實踐
- 一文讀懂 SuperEdge 邊緣容器架構與原理
【騰訊云原生】云說新品、云研新術、云游新活、云賞資訊,掃碼關注同名公眾號,及時獲取更多干貨!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/250505.html
標籤:其他