從零開始學習PPO演算法編程(pytorch版本)(一)
這幾篇文章介紹了使用Pytorch進行PPO(近端策略優化)演算法編程,這個文章是我從網上進行PPO學習實踐是邊學邊寫的,希望能把整體的流程捋順,
這篇文章首先總體介紹一下撰寫PPO演算法的流程和使用到的檔案,
學習PPO演算法編程的基礎:Python,pytorch,強化學習,策略梯度演算法介紹,PPO的理論知識,以下是一些學習參考的內容:
直觀理解PPO演算法
PPO演算法【理論篇】
PPO演算法通俗理解
PG演算法
策略梯度下降演算法
強化學習知識整理
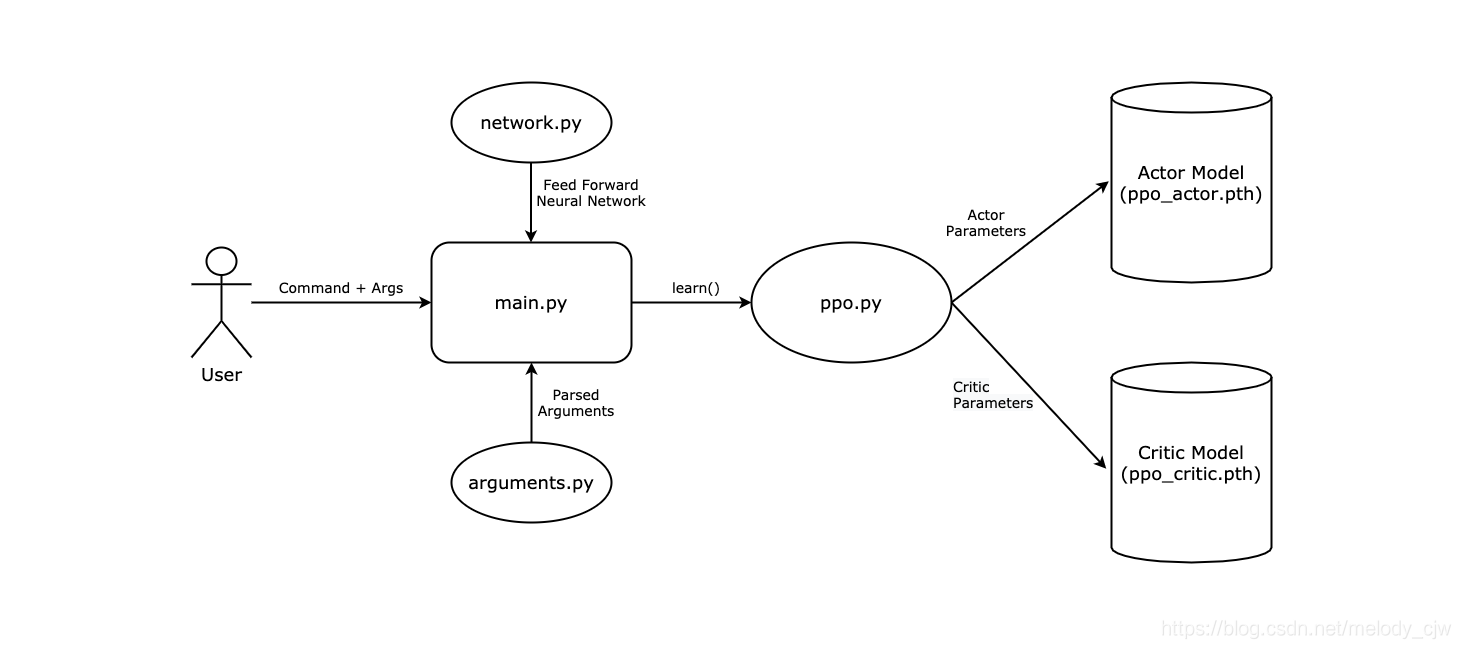
參考網路上的教程進行實踐,首先將訓練代碼分為4個檔案,分別是main.py,ppo.py,network.py和arguments.py,
arguments.py: 決議命令列引數,main函式可以呼叫,
main.py: 可執行檔案,使用arguments.py決議命令列引數,初始化環境和PPO模型,
PPO.py: 保存PPO模型
network.py: 用于在PPO模型中定義Actor-Critic網路的神經網路模塊,包含一個前饋神經網路,
Actor-Critic模型會定期保存到二進制檔案ppo_actor.pth和ppo_critic.pth中,可以在測驗或繼續訓練時加載它們,
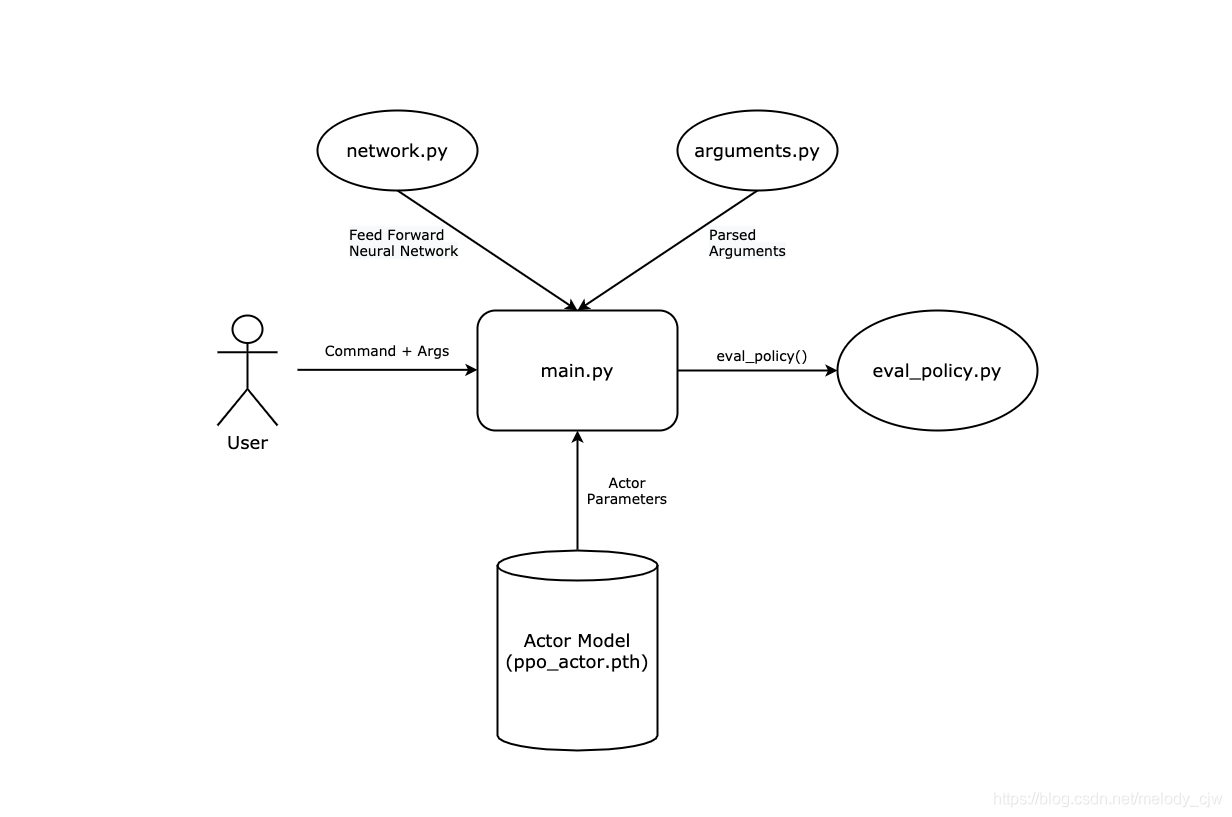
測驗代碼主要位于eval_policy.py中,由main.py呼叫,
eval_policy.py: 在指定的環境中測驗經過訓練的策略,這個模塊完全獨立于其他所有檔案,
參考:
Coding PPO from Scratch with PyTorch
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/251026.html
標籤:AI