深度學習核心的資料結構是標量、向量、矩陣和張量,
“張量”專屬于深度學習TensorFlow框架的名詞,這篇先簡單匯總線性代數范圍內的三種結構及其運算規則:標量、向量、矩陣,以及深度學習領域常用的一個概念:范數
1. 標量
只有數值大小,沒有方向的量,
2. 向量及其運算 (常使用的Python擴展程式庫NumPy來操作)
具有大小和方向的量,表示分別用不同向量的坐標做運算后所得坐標組合,
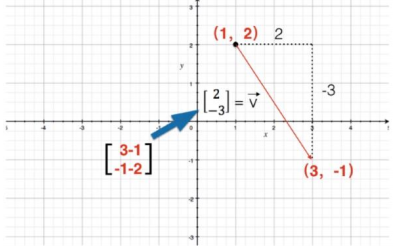
2.1 向量和標量的計算:直角坐標系中向量的數乘,就是向量坐標的分量分別乘該數,
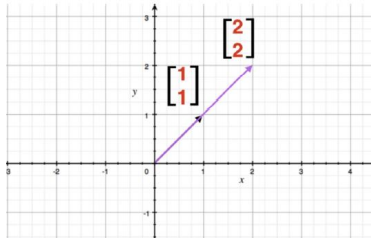
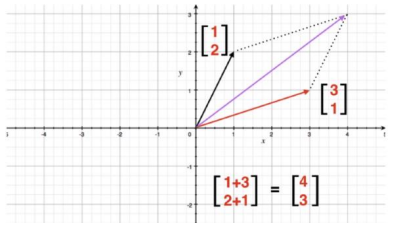
2.2 向量之間的加減操作:直角坐標系中向量的加減就是對應坐標分量的加減,如下展示:加法運算
2.3 向量之間的乘法操作:主要分為點乘(內積)、叉乘(外積)和對應項相乘,
-
- 向量的點乘,也叫向量的內積、數量積,對兩個向量執行點乘運算,就是對這兩個向量對應位一一相乘之后求和的操作,點乘的結果是一個標量,向量的點乘要求兩個向量的長度一致,
- 向量的叉乘,也叫向量的外積、向量積,叉乘的運算結果是一個向量而不是一個標量,叉乘用得較少,
- 對應項相乘,就是兩個向量對應的位置相乘,得到的結果還是原來的形狀,
3. 矩陣及其運算
按照長方陣列排列的復數或實數集合,
3.1 矩陣的加減法:相同"形狀"的矩陣對應元素做加減法,同型矩陣才可以做加減法,

3.2 矩陣的乘運算:結果矩陣的第 i 行第 j 列元素為第一個矩陣的第 i 行元素分別乘第二 個矩陣的第 j 列元素再做加和,
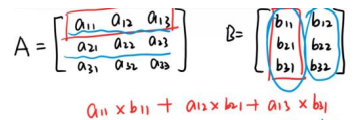
-
- 乘運算也有兩種形式:第一種是兩個形狀一樣的矩陣的對應位置分別相乘,第二種則是矩陣乘法,
- 第一個矩陣的列數等于第二個矩陣的行數,兩個矩陣才可以相乘,
- 矩陣的乘法不滿足交換律,
4. 范數
范數是一種距離的表示,或者說向量的長度,常見的范數有 L0 范數、L1 范數和 L2 范數,
4.1 L0 范數
L0 范數指這個向量中非 0 元素的個數,我們可以通過 L0 范數減少非 0 元素的個數,從而減少參與決策的特征,減少引數,
4.2 L1 范數
L1 范數指的是向量中所有元素的絕對值之和,它是一種距離的表示(曼哈頓距離),也被稱為稀疏規則算子,
4.3 L2 范數
L2 范數是向量中所有元素的平方和的平方根,很常用的一類范數,其實也代表一種距離,即歐式距離,
各類范數的作用:
-
- L0和L1范數的作用:權值稀疏
在設計模型的程序中,我們有時會使用到大量的特征,每個特征都會從不同的角度體現問題的不同資訊,這些特征經過某些方式的組合、變換、映射之后,會按照不同的權重得到最終的結果,但有時候,有一部分特征對于最后結果的貢獻非常小,甚至近乎零,這些用處不大的特征,我們希望能夠將其舍棄,以更方便模型做出決策,這就是權值稀疏的意義,
L0 范數和 L1 范數都能實作權值稀疏,但 L1 范數是 L0 范數的最優凸近似,它比 L0 范數有著更好的優化求解的特性,所以被更廣泛地使用,
-
- L2范數的作用是:防止過擬合
如果我們要避免模型過擬合,就要使 L2 最小,這意味著向量中的每一個元素的平方都要盡量小,且接近于 0,
L1 會趨向于產生少量的特征,而其他的特征都是 0,用于特征選擇和稀疏;L2 會選擇更多的特征,但這些特征都會接近于 0,用于減少過擬合,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/251491.html
標籤:其他
下一篇:紅黑樹