C++為什么叫C plus plus?
這是由于C++相當于繼承C的語法后,增加了各方面的能力,所擴展出的一種新語法,
在軟體領域中 plus 有增加的味道,在這里B +樹也一樣,是B樹的增強版,
在學習B+樹之前,最好是對B樹有一定的了解,不了解的各位也沒有關系,可以花費5分鐘的時間讀我的上一篇文章《資料庫索引的基石----B樹》,
我在上篇文章的最后,專門提到,由于B樹的設計,導致它存在一種天然的劣勢,導致典型的B樹在很多方面受到了限制,
這個劣勢是什么呢?(自問)
先想下,為啥我們在類磁盤的資料查找系統中,并沒有使用高效的平衡二叉查找樹,而設計出了B樹?這是由于B樹是考慮到了加載硬碟資料到記憶體是系統瓶頸,所以讓節點變重,承載更多的關鍵字,但是B樹在設計時,為了查找方便,節點資訊除了包含關鍵字,還包含了data資訊,這就導致每個節點所能包含的最大關鍵字個數被壓縮了,(防盜連接:本文首發自http://www.cnblogs.com/jilodream/ )這就導致最終并沒有達到每次次加載,加載的關鍵字是最大數目的最優方案,(自答)
基于這個原因,有人對B樹進行了改良,提出了B+樹(B plus tree),
也就是下邊這個樣子
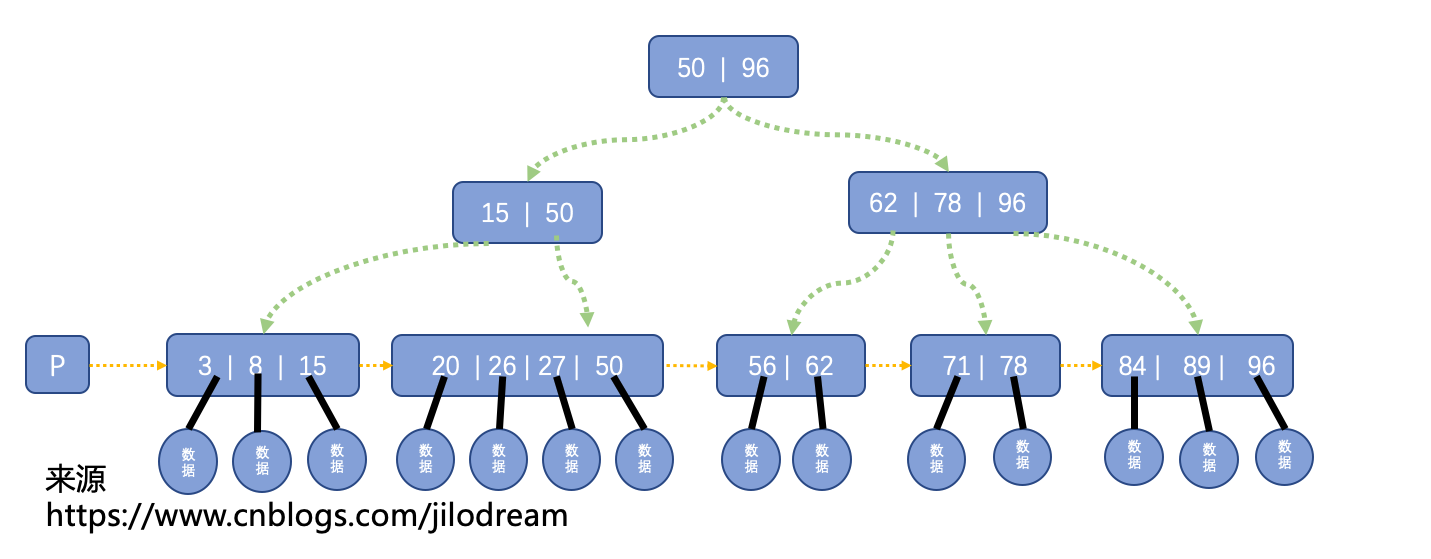
根據B+樹的圖,我們可以輕易總結出以下幾個不同點:
1、 在B+樹中,如果一個節點包含n個關鍵字,那么他就有n個分支,
在B樹中,含有n個關鍵字的節點有n+1個分支,
也就是說B+樹是一個關鍵字對應一個分支,B樹是一個關鍵字的空位置對應一個分支,
2、 B+樹中節點的關鍵字個數范圍比對應的B樹多1,
3、 B+樹的葉子節點包含全部關鍵字,葉子節點的指標指向關鍵字對應的資料,
4、 B+樹的所有非葉子節點僅僅起到一個索引的作用,即節點中的每個索引項只含有對應子樹的最大關鍵字和指向該子樹的指標,不含有該關鍵字的所對應的資料,
在B樹中,每個節點還會額外記錄關鍵字所對應的資料,
5、 B+樹中存在一個額外的指標,這個指標指向于包含最小關鍵字的節點,然后所有的葉子節點從小到大的串聯起來,形成一個線性的鏈表,
最主要的不同點是4、5兩點,這里著重解釋下第4點:
父節點中關鍵字的位置是其子節點中所有的關鍵字中的最大值,
如圖中62是子節點(56,62)的最大值96是子節點(62,78,96)的最大值,
96存在于三個節點中,但是它對應的資料只存盤在葉子節點中,
而B樹如果是相同資料的話,96只會存在一個節點中,而這個節點直接就包含了96對應的資料,
正是由于第4點導致了B+樹的查找,系統每次可以從磁盤中加載的資料量更大,呼叫的IO耗時更少,
而由于第5點的存在,導致B+樹在范圍查找等方面有了極大的優勢,
下邊結合上邊的B+樹,我們來舉幾個例子:
(1) 查找15
首先加載根節點(50,96),依次比較,發現15≤ 50,匹配成功,
加載50對應的子節點(15,50),依次比較,發現15=15,匹配成功,
加載15對應的子節點(3,8,15),依次比較,發現15=15,匹配成功,
由于(3,8,15)是葉子節點,所以可以直接取出對應資料,
(2)查找14
前邊都相同,直至加載葉子節點(3,8,15),
依次比較3,8,不匹配,比較15,發現14<15,并且當前節點是葉子節點,所以匹配失敗,B+樹不包含14關鍵字,
(3)查找滿足14≤x≤57條件的所有x
同(2)場景,發現14不存在,15是滿足條件的最小值,存盤15,
加載下一個葉子節點(20,26,27,50),依次比較發現都滿足,全部存盤,
加載下一個葉子節點(56,62),依次比較發現56滿足條件,62超出范圍,存盤56,
最終得出滿足條件的所有資料是{15,20,26,27,50,56},
由于B+樹的種種優勢,使得其被廣泛應用于各種檔案查找系統中,如mysql、MongoDB,在mysql中,你在建立索引所選取的B樹,其底層的實作正是B+樹,另外值得注意的是,在MongoDB的官方檔案中描述,其索引使用B樹,于是很多文章甚至面試官就想當然的提問,為什么MongoDB沒使用B+樹,而是使用的B樹,其實作者曾經就已作出澄清,底層的實作使用的是B+樹,(防盜連接:本文首發自http://www.cnblogs.com/jilodream/ )而檔案寫為B樹,我們可以理解為B+樹是B樹的一個增強版,(此處可參考https://q.cnblogs.com/q/127244/)所以當有人問你,為什么mysql使用B+樹,而MongoDB使用B樹時,你可以給他一個驚喜,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/251493.html
標籤:其他
上一篇:紅黑樹
下一篇:2021寒假每日一題《字母圖形》