
本文將介紹強化學習的基本含義,了解什么是強化學習、強化學習的概念與基本框架以及強化學習中常見的問題型別,
什么是強化學習?
強化學習(Reinforcement Learning, RL),又稱再勵學習、評價學習或增強學習,是機器學習的范式和方法論之一,用于描述和解決智能體(agent)在與環境的互動程序中通過學習策略以達成回報最大化或實作特定目標的問題,
以上是百度百科中對強化學習的描述,從這樣一句話中我們能捕捉到幾點資訊:
- 強化學習是一種機器學習方法
- 強化學習關注智能體與環境之間的互動
- 強化學習的目標一般是追求最大回報
換句話說,強化學習是一種學習如何從狀態映射到行為以使得獲取的獎勵最大的學習機制,這樣的一個agent需要不斷地在環境中進行實驗,通過環境給予的反饋(獎勵)來不斷優化狀態-行為的對應關系,因此,反復實驗(trial and error)和延遲獎勵(delayed reward)是強化學習最重要的兩個特征,
與其他機器學習方法的區別
這里其他機器學習方法主要是監督學習和無監督學習,也是我們在理解強化學習的程序中最容易發生混淆的地方,
監督學習是機器學習領域研究最多的方法,已經十分成熟,在監督學習的訓練集中,每一個樣本都含有一個標簽,在理想情況下,這個標簽通常指代正確的結果,監督學習的任務即是讓系統在訓練集上按照每個樣本所對應的標簽推斷出應有的反饋機制,進而在未知標簽的樣本上能夠計算出一個盡可能正確的結果,例如我們熟悉的分類與回歸問題,在強化學習中的互動問題中卻并不存在這樣一個普適正確的“標簽”,智能體只能從自身的經驗中去學習,
但是強化學習與同樣沒有標簽的無監督學習也不太一樣,無監督學習是從無標簽的資料集中發現隱藏的結構,典型的例子就是聚類問題,但是強化學習的目標是最大化獎勵而非尋找隱藏的資料集結構,盡管用無監督學習的方法尋找資料內在結構可以對強化學習任務起到幫助,但并未從根本上解決最大化獎勵的問題,
因此,強化學習是除了監督學習和無監督學習之外的第三種機器學習范式,
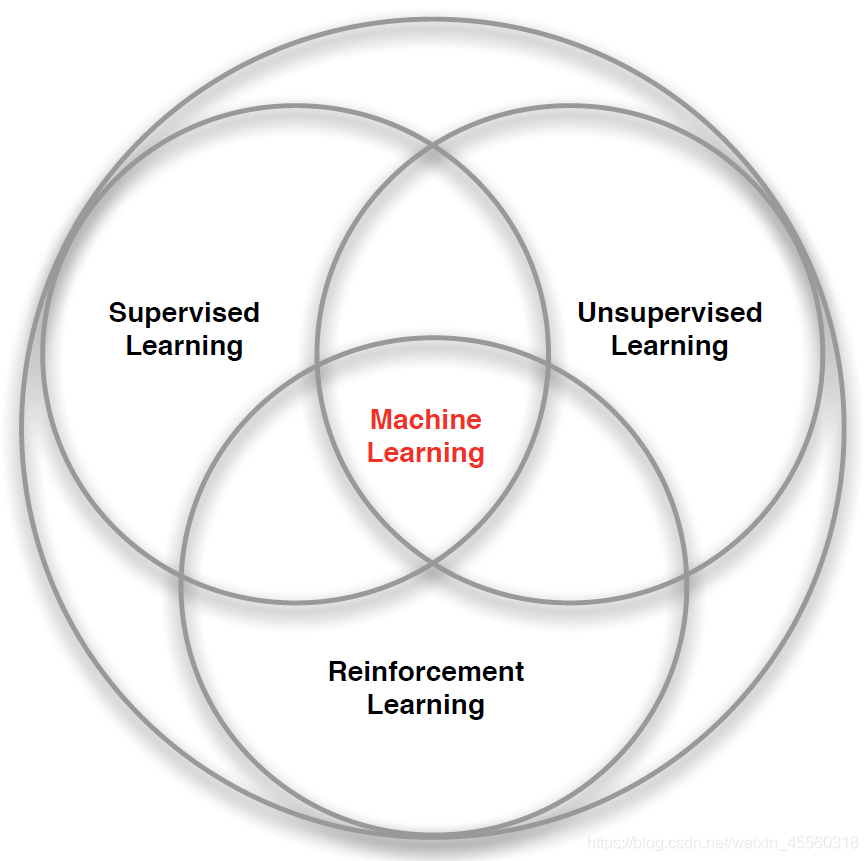
注:當然還有讓學習器不依賴外界互動、自動地利用未標記樣本來提升學習性能的半監督學習,它與強化學習也有著本質的差別,
強化學習特點
基于前面的介紹,我們將強化學習的特點總結為以下四點:
- 沒有監督者,只有一個獎勵信號
- 反饋是延遲的而非即時
- 具有時間序列性質
- 智能體的行為會影響后續的資料
強化學習的要素與架構
四個基本要素
強化學習系統一般包括四個要素:策略(policy),獎勵(reward),價值(value)以及環境或者說是模型(model),接下來我們對這四個要素分別進行介紹,
策略(Policy)
策略定義了智能體對于給定狀態所做出的行為,換句話說,就是一個從狀態到行為的映射,事實上狀態包括了環境狀態和智能體狀態,這里我們是從智能體出發的,也就是指智能體所感知到的狀態,因此我們可以知道策略是強化學習系統的核心,因為我們完全可以通過策略來確定每個狀態下的行為,我們將策略的特點總結為以下三點:
- 策略定義智能體的行為
- 它是從狀態到行為的映射
- 策略本身可以是具體的映射也可以是隨機的分布
獎勵(Reward)
獎勵信號定義了強化學習問題的目標,在每個時間步驟內,環境向強化學習發出的標量值即為獎勵,它能定義智能體表現好壞,類似人類感受到快樂或是痛苦,因此我們可以體會到獎勵信號是影響策略的主要因素,我們將獎勵的特點總結為以下三點:
- 獎勵是一個標量的反饋信號
- 它能表征在某一步智能體的表現如何
- 智能體的任務就是使得一個時段內積累的總獎勵值最大
價值(Value)
接下來說說價值,或者說價值函式,這是強化學習中非常重要的概念,與獎勵的即時性不同,價值函式是對長期收益的衡量,我們常常會說“既要腳踏實地,也要仰望星空”,對價值函式的評估就是“仰望星空”,從一個長期的角度來評判當前行為的收益,而不僅僅盯著眼前的獎勵,結合強化學習的目的,我們能很明確地體會到價值函式的重要性,事實上在很長的一段時間內,強化學習的研究就是集中在對價值的估計,我們將價值函式的特點總結為以下三點:
- 價值函式是對未來獎勵的預測
- 它可以評估狀態的好壞
- 價值函式的計算需要對狀態之間的轉移進行分析
環境(模型)
最后說說外界環境,也就是模型(Model),它是對環境的模擬,舉個例子來理解,當給出了狀態與行為后,有了模型我們就可以預測接下來的狀態和對應的獎勵,但我們要注意的一點是并非所有的強化學習系統都需要有一個模型,因此會有基于模型(Model-based)、不基于模型(Model-free)兩種不同的方法,不基于模型的方法主要是通過對策略和價值函式分析進行學習,我們將模型的特點總結為以下兩點:
- 模型可以預測環境下一步的表現
- 表現具體可由預測的狀態和獎勵來反映
強化學習的架構
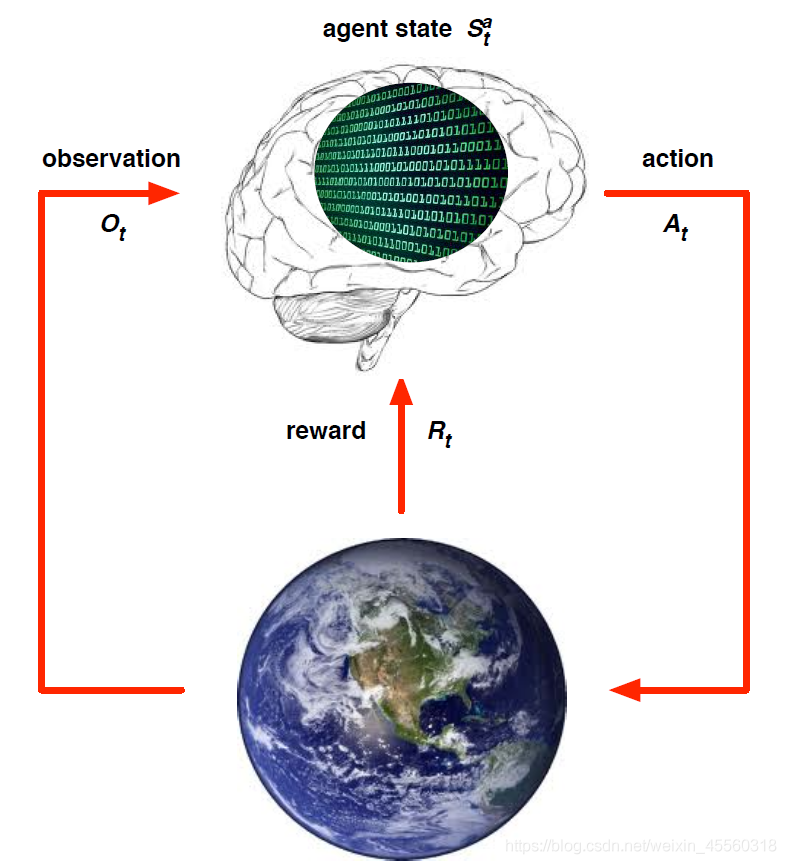
我們用這樣一幅圖來理解一下強化學習的整體架構,大腦指代智能體agent,地球指代環境environment,從當前的狀態
S
t
a
S^a_t
Sta?出發,在做出一個行為
A
t
A_t
At?之后,對環境產生了一些影響,它首先給agent反饋了一個獎勵信號
R
t
R_t
Rt?,接下來我們的agent可以從中發現一些資訊,此處用
O
t
O_t
Ot?表示,進而進入一個新的狀態,再做出新的行為,形成一個回圈,強化學習的基本流程就是遵循這樣一個架構,
強化學習的問題
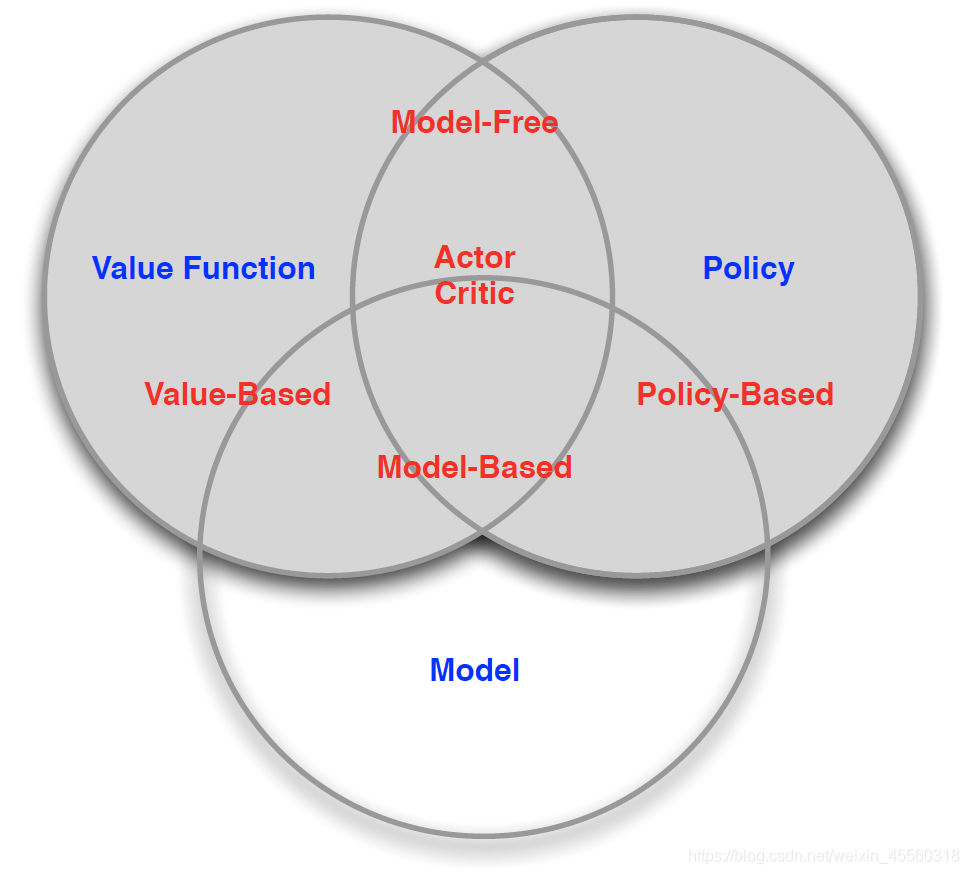
強化學習的基本問題按照兩種原則進行分類,
- 基于策略和價值的分類,分為三類:
- 基于價值的方法(Value Based):沒有策略但是有價值函式
- 基于策略的方法(Policy Based):有策略但是沒有價值函式
- 參與評價方法(Actor Critic):既有策略也有價值函式
- 基于環境的分類,分為兩類:
- 無模型的方法(Model Free):有策略和價值函式,沒有模型
- 基于模型的方法(Model Based):有策略和價值函式,也有模型
我們用下面的韋恩圖來清晰地對這些方法做一個展示:
探索(Exploration)和利用(Exploitation)
最后在強化學習的問題這里談一下探索和利用的問題,強化學習理論受到行為主義心理學啟發,側重在線學習并試圖在探索-利用(exploration-exploitation)間保持平衡,不要求預先給定任何資料,而是通過接識訓境對動作的獎勵(反饋)獲得學習資訊并更新模型引數,
一方面,為了從環境中獲取盡可能多的知識,我們要讓agent進行探索,另一方面,為了獲得較大的獎勵,我們要讓agent對已知的資訊加以利用,魚與熊掌不可兼得,我們不可能同時把探索和利用都做到最優,因此,強化學習問題中存在的一個重要挑戰即是如何權衡探索-利用之間的關系,
總結
強化學習是一種理解和自動化目標導向學習和決策的計算方法,它強調個體通過與環境的直接互動來學習,而不需要監督或是完整的環境模型,
可以認為,強化學習是第一個有效解決從與環境互動中學習以實作長期目標的方法,而這種模式是所有形式的機器學習中最接近人類和其他動物學習的方法,也是目前最符合人工智能發展終極目標的方法,
這是本人寫的第一篇博客,文中錯謬之處在所難免,若蒙讀者諸君不吝告知,將不勝感激,
之后還會繼續分享強化學習的基礎知識以及其他有價值的內容,
轉載或者參考本文內容請注明來源及原作者
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/251683.html
標籤:AI