文章目錄
- 概覽
- Spark
- mr問題
- Spark特征
- Spark生態系統對比Hadoop生態系統
- 開發語言及運行環境
- Scala&Maven安裝
- 配置Spark
- 總結
- Flink分布式計算框架(流處理)
- 概述
- 配置環境
- Flink運行
- 檢驗
- Beam
- quickstart-java
概覽
Spark、Flink、Beam
Beam撰寫完適用于Spark、Flink使用
Spark
mr問題
mr->spark?
開發不爽 mr兩個程序
速度不快 m存硬碟r存hdfs
框架多樣性 批處理 流式處理
Spark特征
http://spark.apache.org/
速度快 記憶體和磁盤 都比mr快
易用 支持多語言 命令列直接運行
通用性 同一個應用程式同時參考庫
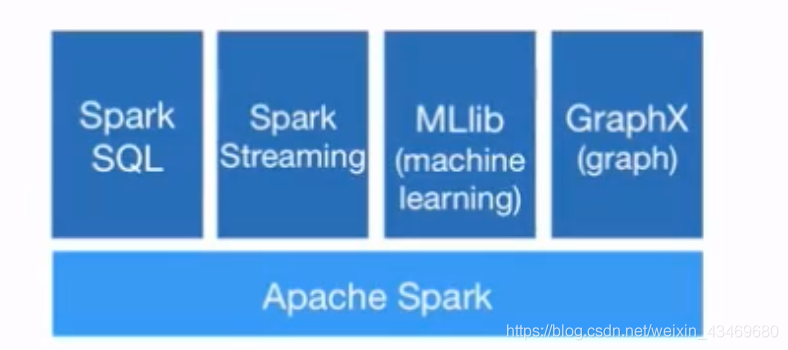 運行 可運行在hdfs之上計算
運行 可運行在hdfs之上計算
Spark生態系統對比Hadoop生態系統
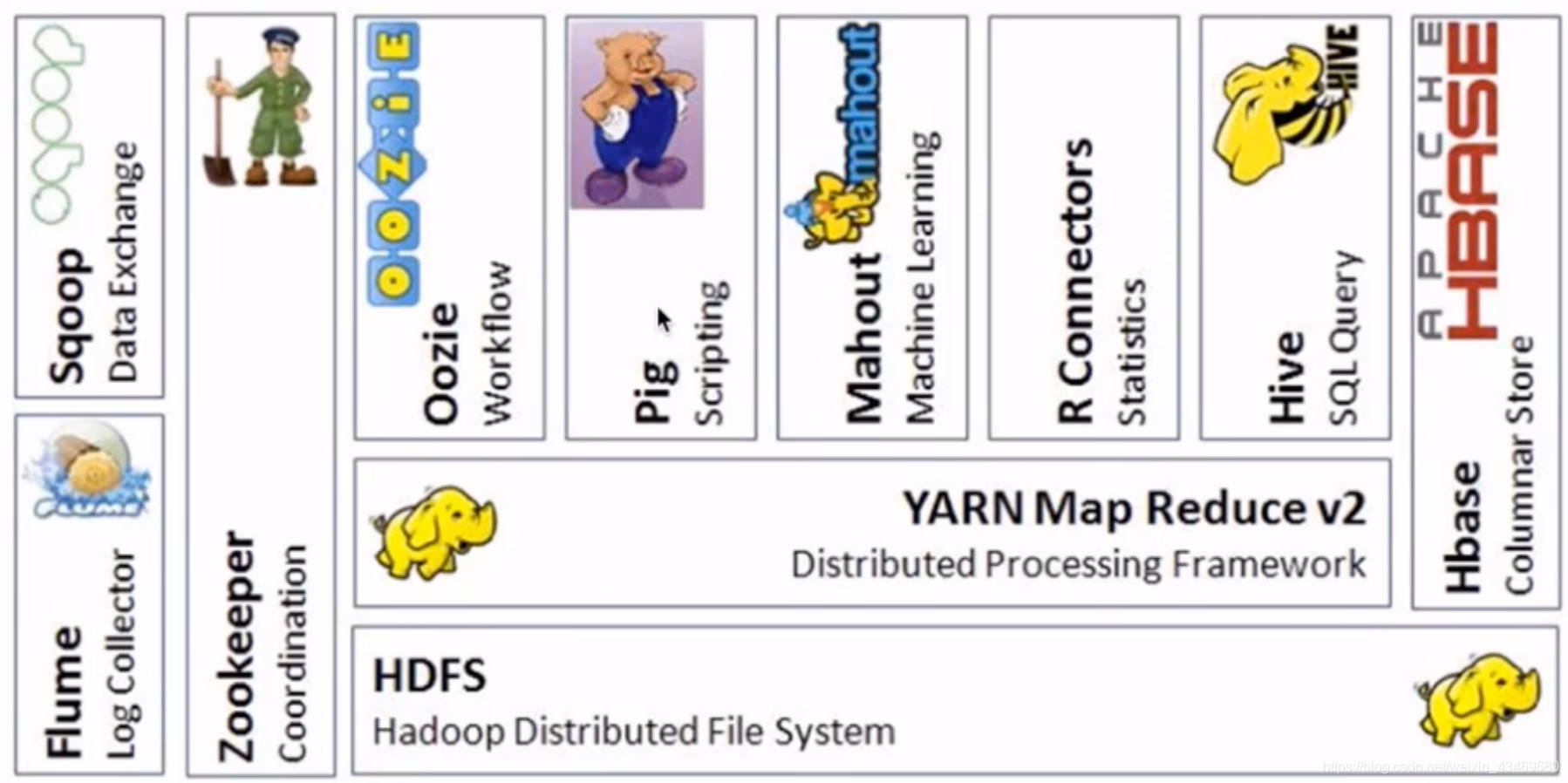

對比
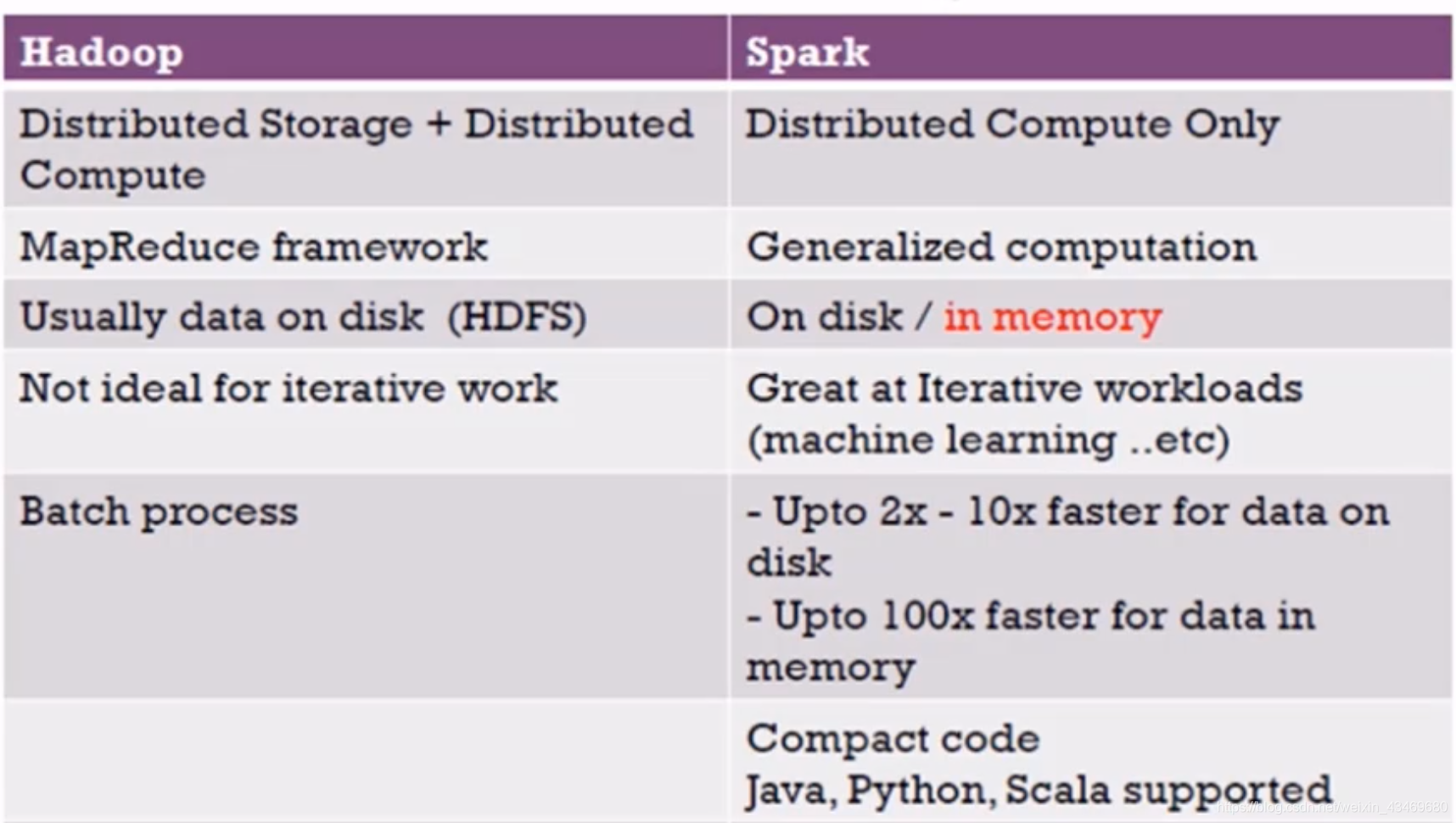 對比mr和spark
對比mr和spark
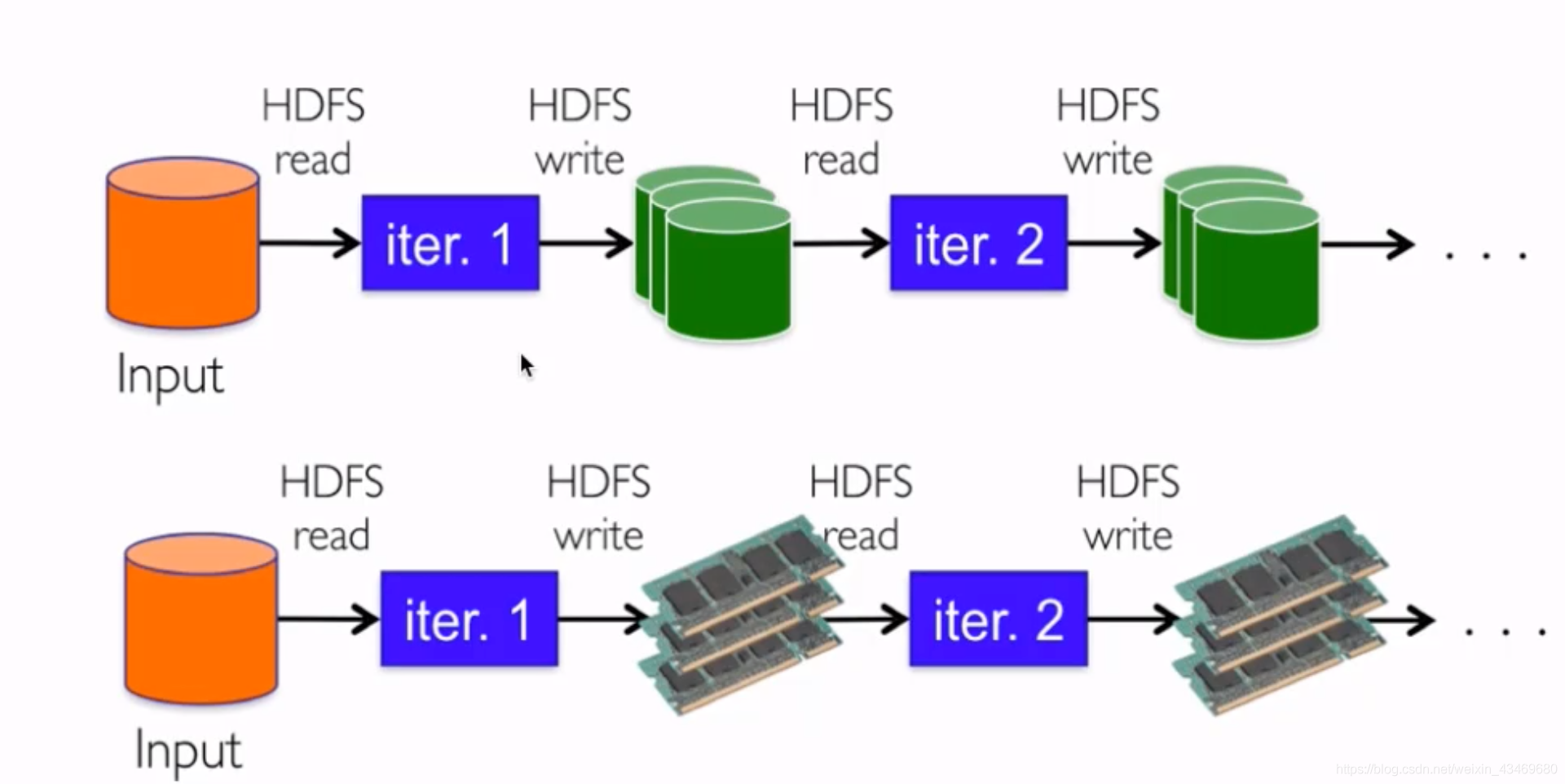
開發語言及運行環境
開發Spark

運行模式
代碼是一樣的提交引數不同 導致運行模式不同

Scala&Maven安裝
解壓檔案
tar -zxf apache-maven-3.6.1-bin.tar.gz -C ./
環境變數配置
export SCALA_HOME=/root/software/scala-2.10.6
export PATH=$SCALA_HOME/bin:$PATH
export MAVEN_HOME=/root/software/apache-maven-3.6.1
export PATH=$MAVEN_HOME/bin:$PATH
//重繪配置
source /etc/profile
驗證
scala
mvn -version
配置Spark
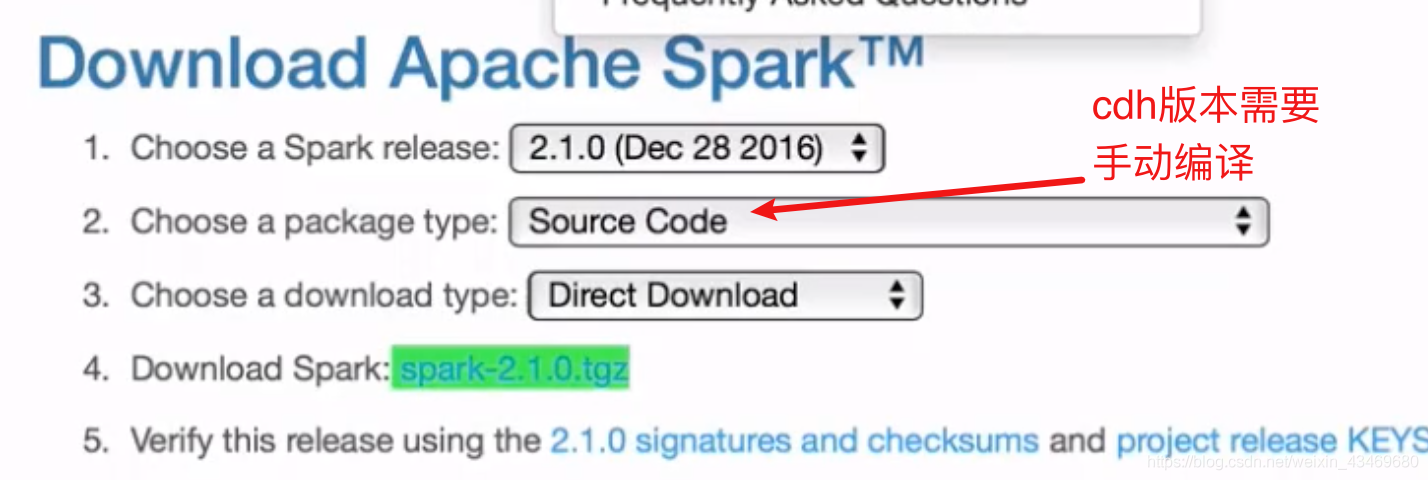
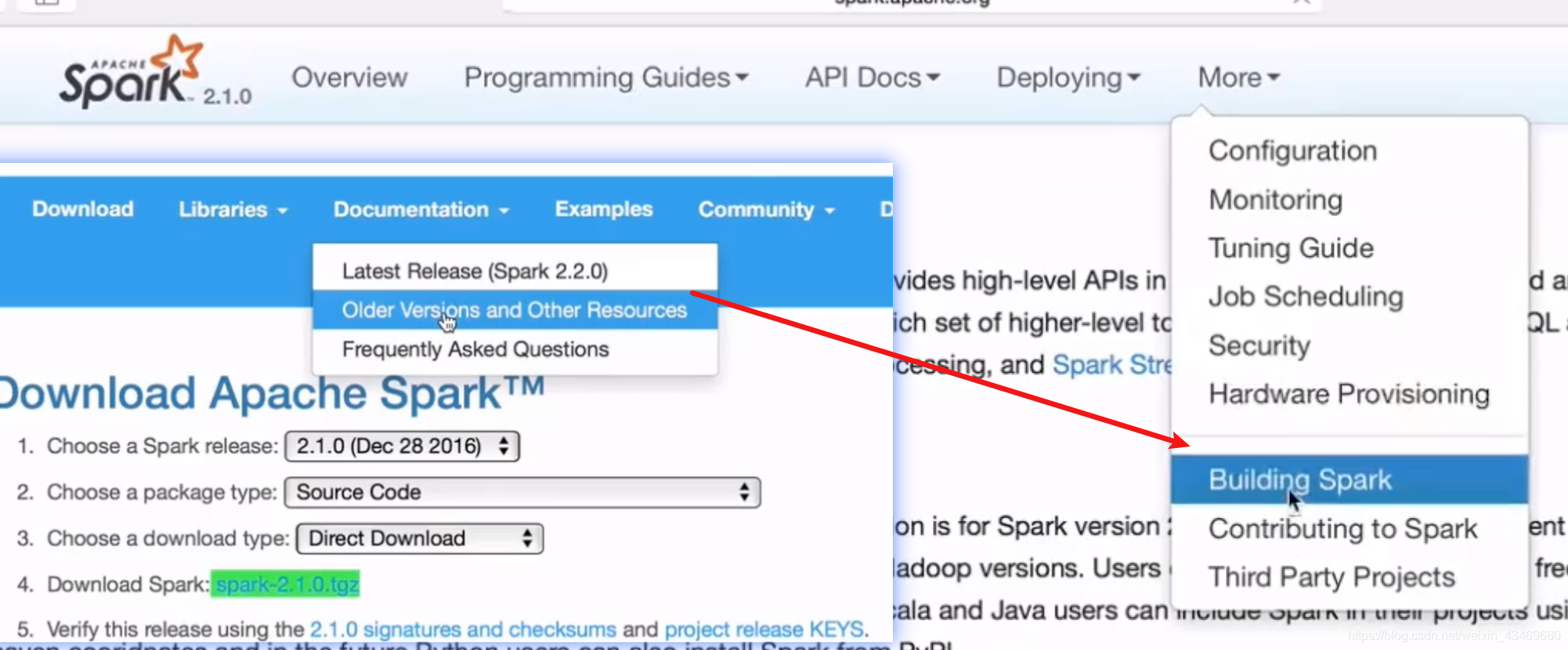
手動編譯適合cdh的壓縮包(注意1.7的jdk可能會過時了)
spark-2.4.3-bin-2.6.0-cdh5.15.1.tgz
進入bin目錄啟動模式(本地測驗local好)
/root/software/spark-2.4.3-bin-2.6.0-cdh5.15.1/bin
master URL
[]兩個執行緒
//啟動spark兩個執行緒
./spark-shell --master local[2]
快速指南
簡單helloworld
注意本地讀取

[root@hadoop01 data]# cat hello.txt
hello world
hello hadoop
hello hdfs
scala
scala> val textFile = spark.read.textFile("/root/data/hello.txt")
scala> textFile.collect
res1: Array[String] = Array(hello world, hello hadoop, hello hdfs, "")
scala> textFile.count
res2: Long = 4
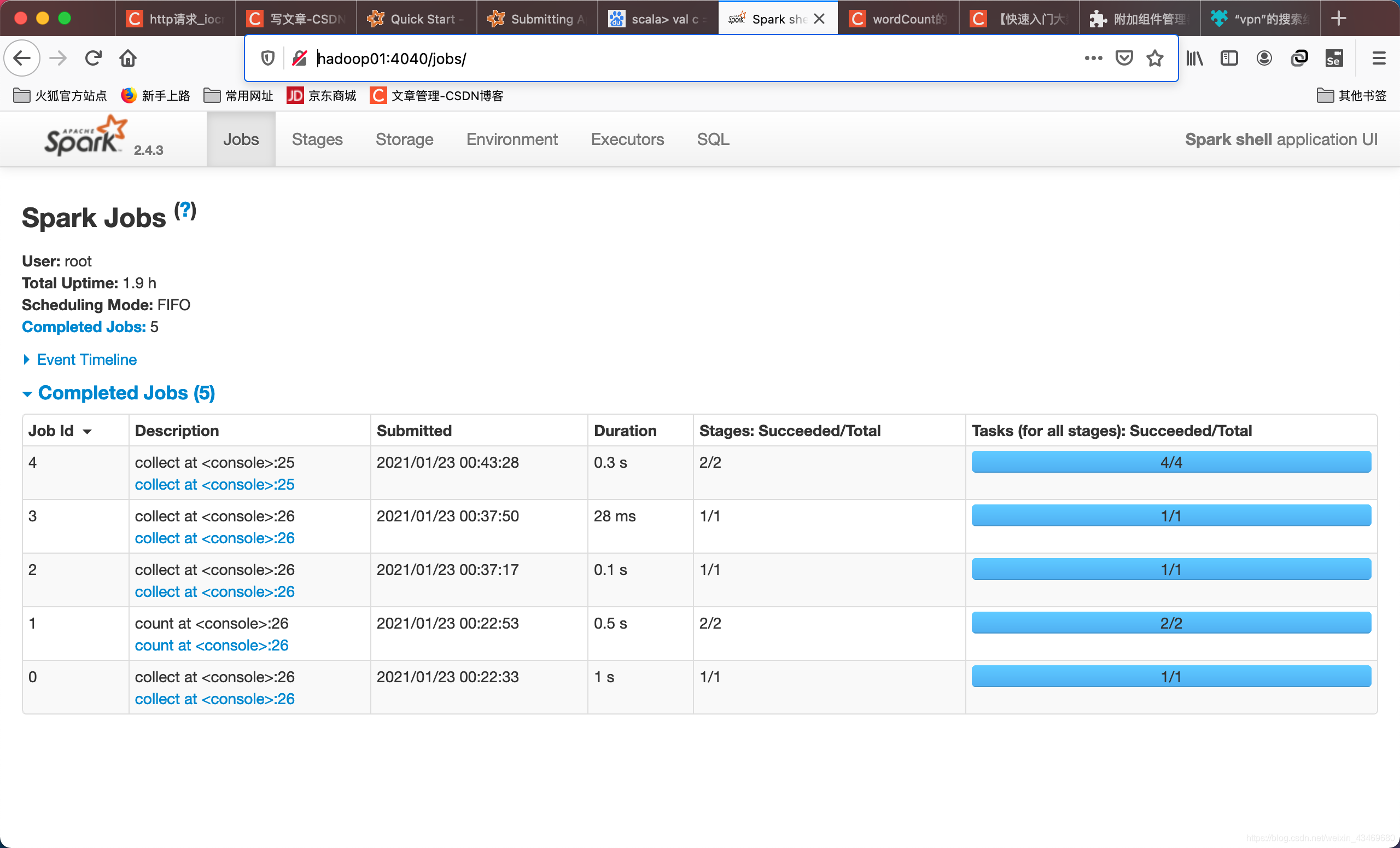
檢驗
http://hadoop01:4040/jobs/
總結
spark啟動:spark-shell --master local[2]
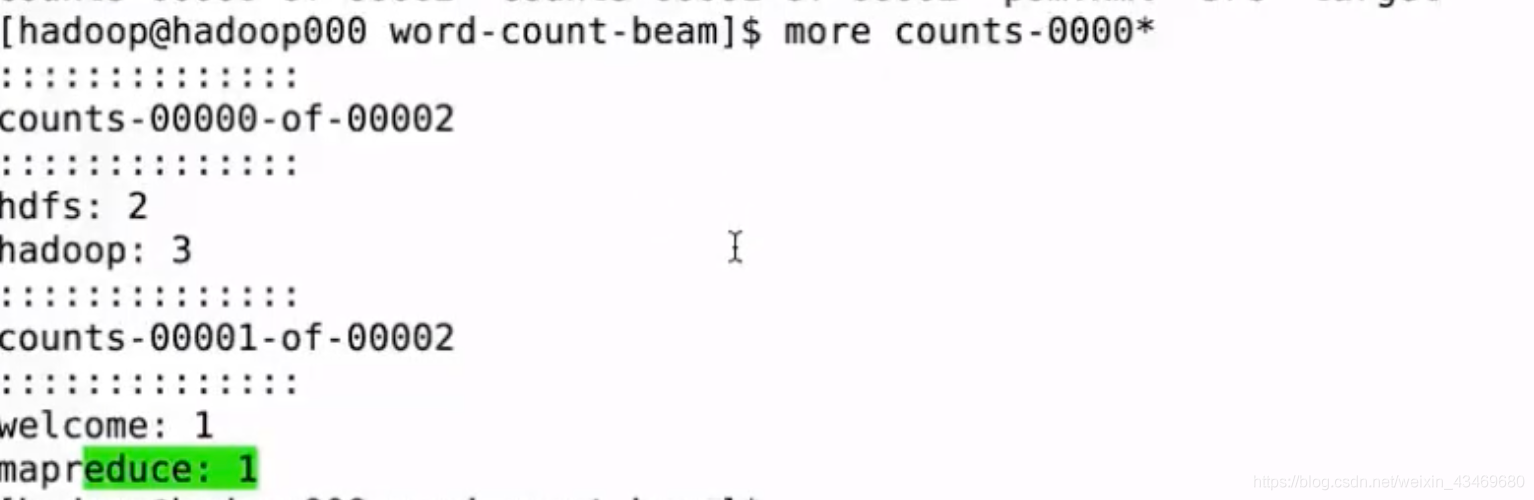
spark實作wc:
val file = sc.textFile("file:///home/hadoop/data/hello.txt")
val a = file.flatMap(line => line.split(" "))
val b = a.map(word => (word,1))
Array((hadoop,1), (welcome,1), (hadoop,1), (hdfs,1), (mapreduce,1), (hadoop,1), (hdfs,1))
val c = b.reduceByKey(_ + _)
Array((mapreduce,1), (welcome,1), (hadoop,3), (hdfs,2))
sc.textFile("file:///home/hadoop/data/hello.txt").flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_ + _).collect
Flink分布式計算框架(流處理)
概述
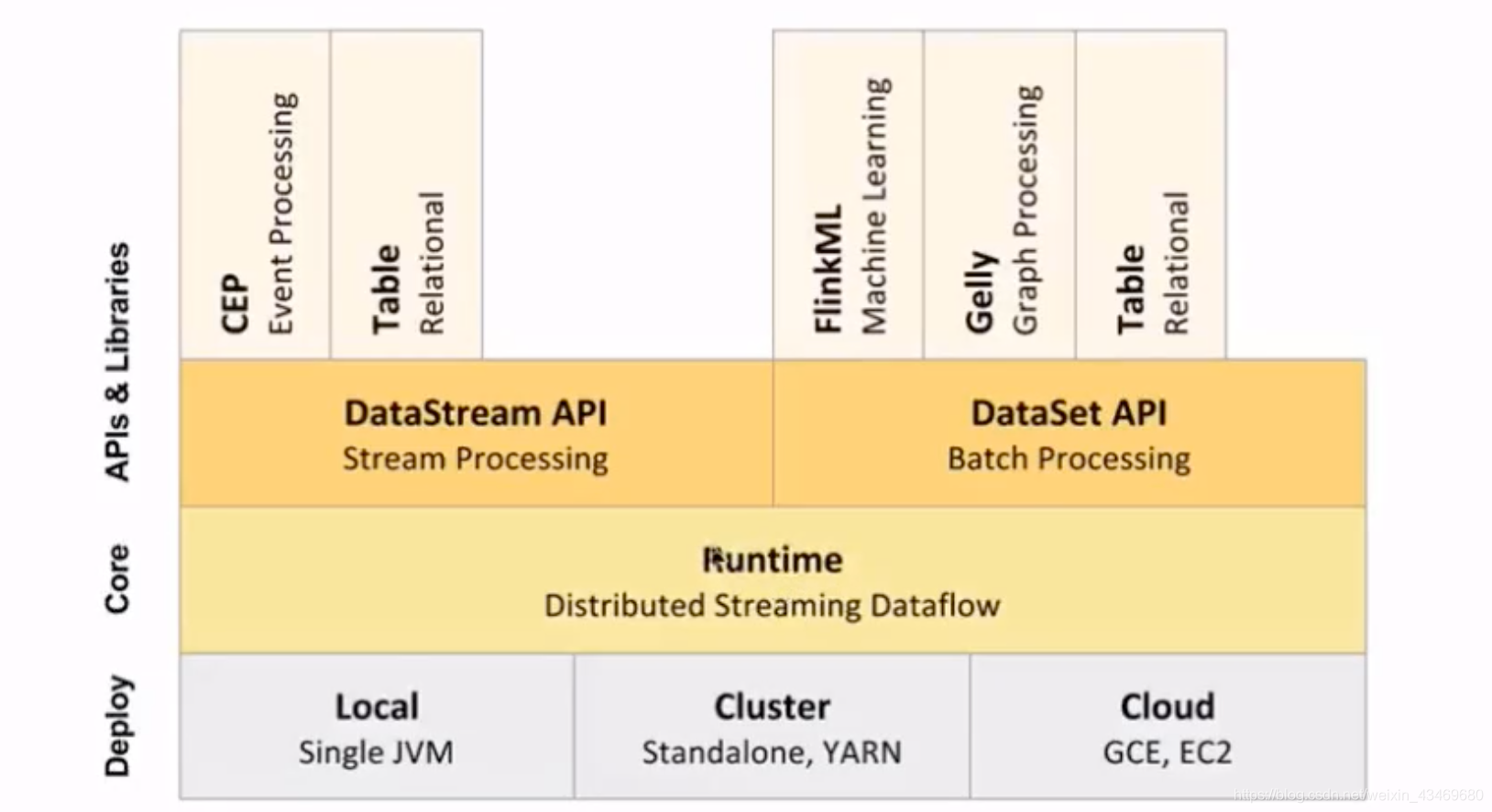

配合使用的框架,流入流出
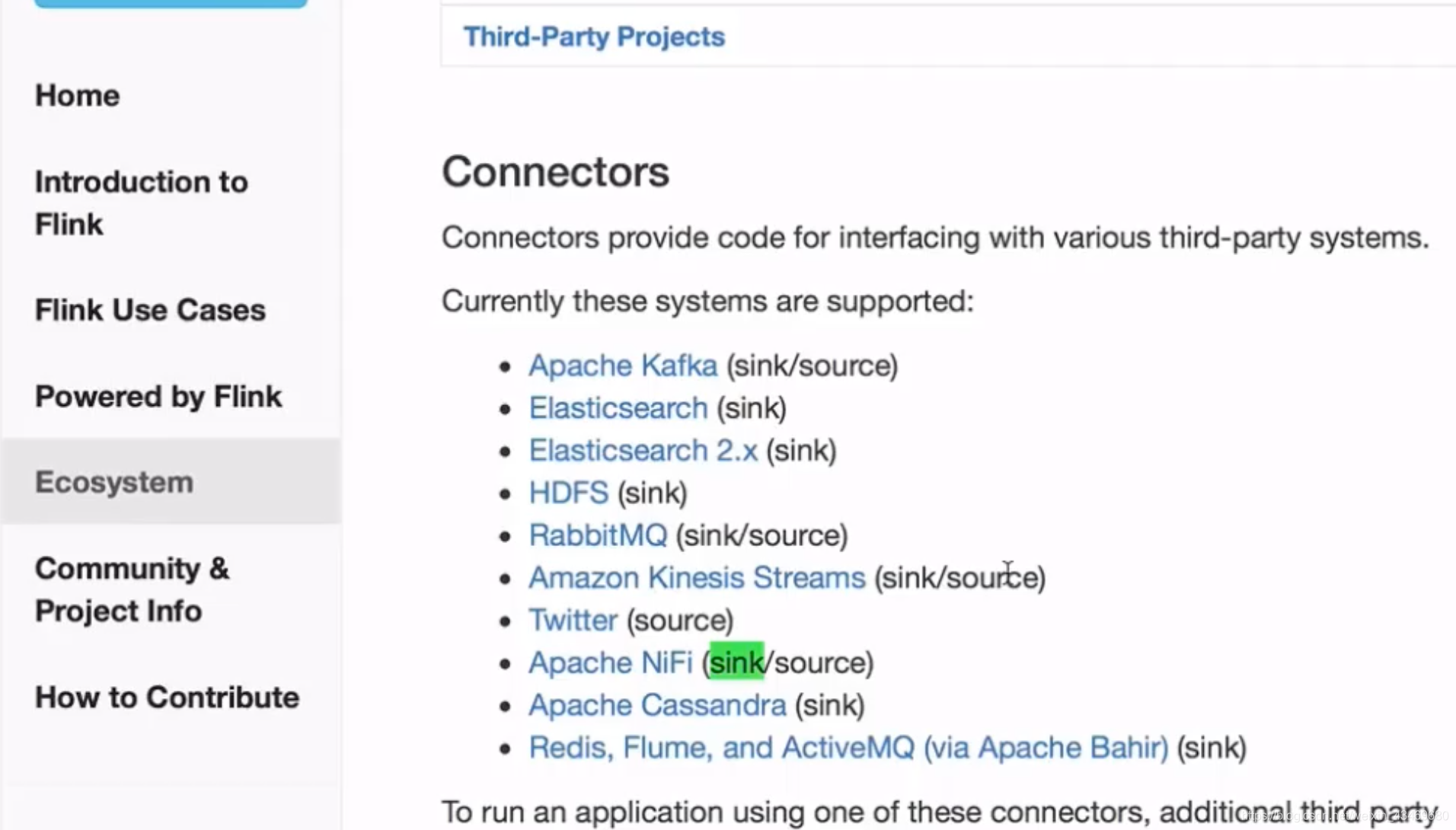
注意hadoop版本和scala版本,新版flink并未細分下載選項
配置環境
flink解壓
tar -zxf flink-1.12.1-bin-scala_2.11.tgz -C ./
wordcount
Flink運行
./bin/flink run ./examples/batch/WordCount.jar \
--input file:///root/data/hello.txt --output file:///root/data/tmp/flink_wc_output
檢驗
[root@hadoop01 tmp]# cat flink_wc_output
hadoop 1
hdfs 1
hello 3
world 1
Beam
java\python撰寫應用于批處理、流處理
 https://beam.apache.org/
https://beam.apache.org/
quickstart-java
jdk1.7之后 和 maven 前置環節
tree
Beam運行:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.beam \
-DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \
-DarchetypeVersion=2.27.0 \
-DgroupId=org.example \
-DartifactId=word-count-beam \
-Dversion="0.1" \
-Dpackage=org.apache.beam.examples \
-DinteractiveMode=false
#direct方式運行
mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--inputFile=/home/hadoop/data/hello.txt --output=counts" \
-Pdirect-runner
#spark方式運行
mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--runner=SparkRunner --inputFile=/home/hadoop/data/hello.txt --output=counts" -Pspark-runner
#flink方式運行
瑞 新
 CSDN認證博客專家
分布式
Java
架構
CSDN認證博客專家
分布式
Java
架構
CSDN認證博客專家
分布式
Java
架構
求職中 ? Java全堆疊養成計劃公眾號 ? 讓我遇見相似的靈魂回復領取:競賽 書籍 專案 面試左手代碼,右手吉他,這就是天下:如果有一天我遇見相似的靈魂 那它肯定是步履艱難 不被理解 喜黑怕光的,如果可以的話 讓我觸摸一下吧 它也一樣孤獨得太久, 不一樣的文藝青年,不一樣的程式猿,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/251717.html
標籤:其他
上一篇:ECharts