一.前言:
前段時間想看下最近幾年的閱讀清單,萌生了用Python寫爬蟲程式的想法,于是就有了這篇文章,

起因
兩周前,一位同學問小央,平時有沒有寫過技術類博客,小央大言不慚,隨口就說下次可以嘗試,
這不,自己挖的坑,哭也得填上,正巧,最近要統計自己的閱讀記錄,一個個看多費勁呀,如果能寫個爬蟲程式,自動化獲取資料,豈不美哉,今天一菲就和大家聊一下怎么用python來爬蟲,
二.正文:
1.爬蟲思路
爬蟲是指請求網站并獲取資料的自動化程式,又稱網頁蜘蛛或網路機器,最常用領域是搜索引擎,它的基本流程是明確需求-發送請求-獲取資料-決議資料-存盤資料,
網頁之所以能夠被爬取,主要是有以下三大特征:
網頁都有唯一的URL(統一資源定位符,也就是網址)進行定位
網頁都使用HTML(定位超文本標記語言)來描述頁面資訊
網頁都使用HTTP/HTTPS(超文本傳輸協議)協議來傳輸HTML資料
因此,只要我們能確定需要爬取的網頁 URL地址,通過 HTTP/HTTPS協議來獲取對應的 HTML頁面,就能提取 HTML頁面里有用的資料,
在工具的選擇上,任何支持網路通信的語言都可以寫爬蟲,比如 c++、 java、 go、 node等,而 python則是用的最多最廣的,并且也誕生了很多優秀的庫和框架,如 scrapy、 BeautifulSoup 、 pyquery、 Mechanize等,
在這里推薦一個軟體測驗交流群,qq:642830685,群中會不定期的分享軟體測驗資源,測驗面試題以及測驗行業咨訊,
BeautifulSoup是一個非常流行的 Pyhon 模塊,該模塊可以決議網頁,并提供定位內容的便捷介面,
但是在決議速度上不如 Lxml模塊,因為后者是用C語言撰寫,其中 Xpath可用來在 XML檔案中對元素和屬性進行遍歷,
綜上,我們本次爬取工具選擇 Python,使用的包有 requests、 Lxml、 xlwt、 xlrd,分別用于模擬賬戶登錄、爬取網頁資訊和操作 Excel進行資料存盤等,
2.實戰決議
⑴模擬賬戶登錄
因為要爬取個人賬戶下的讀書串列,我們首先要讓 Python創建用戶會話,用于在跨請求時保存Cookie值,實作從客戶端瀏覽器連接服務器開始,到客戶端瀏覽器與服務器斷開,
其次要處理請求頭 Header,發送附帶賬戶名和密碼的 POST請求,并獲取登陸后的 Cookie值,保存在會話里,
登陸進去之后,我們就可以長驅直入進行爬蟲了;否則,它就會因請求不合法報錯,
代碼示例
# 1. 創建session物件,可以保存Cookie值ssion = requests.session()# 2. 處理 headersuser_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'headers={'User-Agent':user_agent}# 3. 需要登錄的用戶名和密碼data = https://www.cnblogs.com/syf12/p/{"email":"豆瓣賬戶名XX", "password":"豆瓣密碼XX"}# 4. 發送附帶用戶名和密碼的請求,并獲取登錄后的Cookie值,保存在ssion里ssion.post("https://www.douban.com/accounts/login", data = https://www.cnblogs.com/syf12/p/data)respon=ssion.get(url,headers=headers)
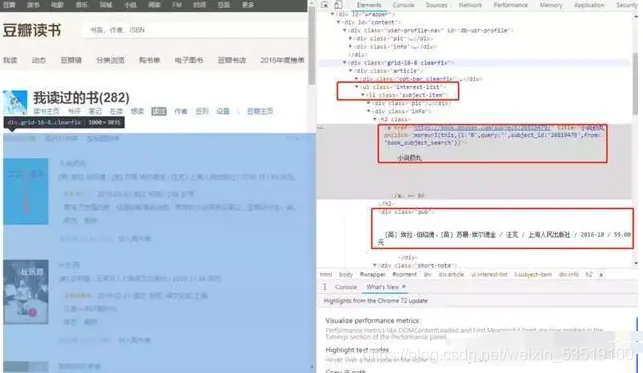
⑵分析網頁結構
進入讀書頁面,右鍵選擇“檢查”,可以看到如下界面:當滑鼠定位在某一行代碼時,就會選中左側對應模塊,
所有圖書內容的標簽,存放在一個類名為 id="content"的div盒子, 的li盒子,
同樣方法,我們也可以找到書名、作者、出版社、何時讀過、評論資訊,分別對應哪些標簽,
最終,我們通過CSS路徑提取來提取對應標簽資料,
代碼示例
#因為每頁有15本書,所以這里做了個回圈for tr in trs: i = 1 while i <= 15: data = https://www.cnblogs.com/syf12/p/[] title = tr.xpath("./ul/li["+str(i)+"]/div[2]/h2/a/text()") info = tr.xpath(’./ul/li[’+str(i)+’]/div[2]/div[1]/text()’) date = tr.xpath(’./ul/li[’+str(i)+’]/div[2]/div[2]/div[1]/span[2]/text()’) comment = tr.xpath(’./ul/li[’+str(i)+’]/div[2]/div[2]/p/text()’)
⑶自動翻頁,回圈爬取
因為要爬取歷史讀書清單,當爬完一頁的時候,需要程式能夠實作自動翻頁功能,
一種方法是讓它自動點擊下一頁,但這個學習成本有點高,吃力不討好;另一種方法,就是尋找網頁之間的規律,做個回圈即可,
以央之姑娘的豆瓣賬戶為例:很容易發現網頁之間的區別僅在于start值不同,第一頁的 start=0,第二頁 start=15,以此類推,最后一頁,即19頁的 start=(19-1)*15=270.
找到這樣的規律就很容易實作Python自動翻頁功能,條條大路通羅馬,適合自己的就是最好的,
代碼示例
def getUrl(self): i = 0 while i < 271: url = (‘https://book.douban.com/people/81099629/collect?start=’+str(i)+’&sort=time&rating=all&filter=all&mode=grid’) self.spiderPage(url) i += 15
⑷資料存盤
資料存盤有很多種方法,因為資料量不大,用Excel即可滿足,具體方法就不在這里贅述了,
代碼示例
def init(self): self.f = xlwt.Workbook() # 創建作業薄 self.sheet1 = self.f.add_sheet(u’央之姑娘’, cell_overwrite_ok=True) # 命名table self.rowsTitle = [u’編號’,u’書名’, u’資訊’, u’讀過日期’, u’評論’] # 創建標題 for i in range(0, len(self.rowsTitle)): # 最后一個引數設定樣式 self.sheet1.write(0, i, self.rowsTitle[i], self.set_style(‘Times new Roman’, 220, True)) # Excel保存位置 self.f.save(‘C://Users//DELL//央之姑娘.xlsx’)
def set_style(self, name, height, bold=False): style = xlwt.XFStyle() # 初始化樣式 font = xlwt.Font() # 為樣式創建字體 font.name = name font.bold = bold font.colour_index = 2 font.height = height style.font = font return style
三、效果演示
前面講了爬蟲的原理和方法,那么接下來我們就展示一下具體效果:
在這里推薦一個軟體測驗交流群,QQ:642830685,群中會不定期的分享軟體測驗資源,測驗面試題以及行業資訊,大家可以在群中積極交流技術,還有技術大佬為你答疑解惑,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/252505.html
標籤:其他
下一篇:軟體測驗還有明天嗎?