文章目錄
- 《機器學習》筆記——決策樹與隨機森林
- 1. 簡介
- 2. ID3演算法
- 2.1 資訊熵(Information Entropy)
- 2.2 條件熵(Conditional Entropy)
- 2.3 KL散度與資訊增益(Kullback-Leibler Divergence & Information Gain)
- 2.4 ID3決策樹
- 2.5 C4.5演算法
- 2.5.1 簡介
- 2.5.2 資訊增益率
- 2.5 CART演算法
- 2.5.1 簡介
- 2.5.2 Gini指數
- 2.5.3 CART樹的回歸問題
- 后記
- 參考文獻
決策樹是傳統機器學習中很重要的基本演算法之一,決策樹所需要的訓練樣本少,構建思路簡單,訓練所得的模型也可以通過graphviz和matplotlib等工具進行可視化操作,因此我們可以非常直觀的對其進行解釋,
《機器學習》筆記——決策樹與隨機森林
1. 簡介
說到底,決策樹還不是樹,是樹就是if-else陳述句,(bushi)
??決策樹是很典型的判別模型,常用的決策樹有三種,分別是ID3樹,C4.5樹,CART樹,三種型別的樹的目標函式分別為互資訊(Mutual Information),互資訊率(Mutual Information Ratio)和Gini系數(Gini Coefficient),其中互資訊在決策樹中也常被成為資訊增益,其實后者是前者的無偏估計,二者在決策樹演算法中是等效的,
2. ID3演算法
2.1 資訊熵(Information Entropy)
話不多說直接上定義式
H
(
x
)
=
?
∑
i
=
1
n
p
i
log
?
p
i
H(\boldsymbol{x}) = -\sum\limits_{i=1}^{n}p_i\log p_i
H(x)=?i=1∑n?pi?logpi?
??資訊熵越大,說明該事件包含的資訊量越多,也就越難發生,舉個不太恰當的例子,比如美國突然亡了,這件事情包含的資訊量很大,所以短時間內不太容易發生;又比如你看完這篇文章會點個贊,這件事情包含的資訊量比較小,所以很容易發生(doge),
2.2 條件熵(Conditional Entropy)
條件熵可以類比條件概率來理解,其定義式為:
H
(
Y
∣
X
)
=
H
(
X
,
Y
)
?
H
(
X
)
=
?
∑
x
,
y
p
(
x
,
y
)
log
?
(
y
∣
x
)
H(Y|X) = H(X,Y)-H(X) = -\sum\limits_{x,y}p(x,y)\log(y|x)
H(Y∣X)=H(X,Y)?H(X)=?x,y∑?p(x,y)log(y∣x)
??條件熵是推匯出互資訊的重要手段之一,關于熵的詳細來源和推導可以參見香農著名的論文《A Mathematical Theory of Communication》
2.3 KL散度與資訊增益(Kullback-Leibler Divergence & Information Gain)
??KL散度又叫相對熵,是度量兩個概率分布之間距離的指標,設有兩個概率分布P(X), Q(X), 則KL散度的定義式為
D
(
P
∣
∣
Q
)
=
∑
x
p
(
x
)
log
?
p
(
x
)
q
(
x
)
D(P||Q) = \sum\limits_xp(x)\log\frac{p(x)}{q(x)}
D(P∣∣Q)=x∑?p(x)logq(x)p(x)?
顯然當P(X) = Q(X)時D(P||Q) = 0,因為此時P(X)和Q(X)為同一分布,距離為0,
??資訊增益的定義為兩個隨機變數X,Y的聯合分布和邊緣分布的KL散度,定義式如下
I
(
X
,
Y
)
=
∑
x
,
y
p
(
x
,
y
)
log
?
p
(
x
,
y
)
p
(
x
)
p
(
y
)
I(X,Y) = \sum\limits_{x,y}p(x,y)\log\frac{p(x,y)}{p(x)p(y)}
I(X,Y)=x,y∑?p(x,y)logp(x)p(y)p(x,y)?
當且僅當P(X),Q(X)相互獨立時I(X,Y) = 0,另外,資訊增益還可以根據資訊熵和條件熵得出,其定義式為
I
(
X
,
Y
)
=
H
(
X
)
+
H
(
Y
)
?
H
(
X
,
Y
)
=
H
(
X
)
?
H
(
X
∣
Y
)
I(X,Y) = H(X)+H(Y)-H(X,Y) = H(X)-H(X|Y)
I(X,Y)=H(X)+H(Y)?H(X,Y)=H(X)?H(X∣Y)
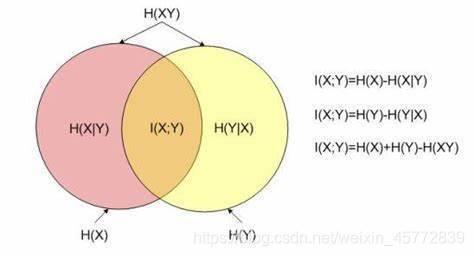
跟條件概率一樣,用一張圖能更好理解資訊增益
2.4 ID3決策樹
??ID3決策樹的葉節點就是根據資訊增益來確定的,每一層對所有未被選擇所有屬性計算資訊增益,選出最大的一個作為該層的葉節點,以西瓜資料集2.0為例
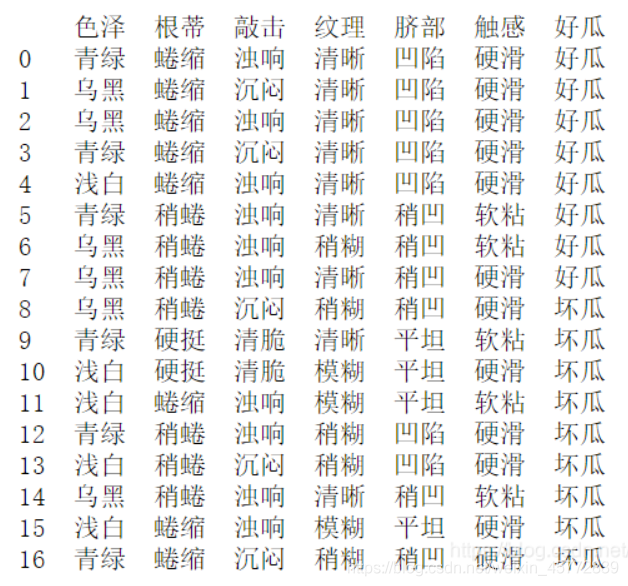
顯然,開始時分為正例和反例,其中正例
p
1
=
8
17
p_1 = \frac{8}{17}
p1?=178?,反例
p
2
=
9
17
p_2 = \frac{9}{17}
p2?=179?,則資訊熵
H
(
X
)
=
?
(
8
17
log
?
8
17
+
9
17
log
?
9
17
)
=
0.998
H(X) = -(\frac{8}{17}\log\frac{8}{17}+\frac{9}{17}\log\frac{9}{17}) = 0.998
H(X)=?(178?log178?+179?log179?)=0.998
要計算資訊增益則還需要計算每個屬性的資訊熵,以色澤為例,色澤為青綠的瓜有6個,其中好瓜3個,則令色澤青綠為
D
1
D_1
D1?
H
(
D
1
)
=
?
(
3
6
log
?
3
6
+
3
6
log
?
3
6
)
=
1
H(D_1) = -(\frac{3}{6}\log\frac{3}{6}+\frac{3}{6}\log\frac{3}{6}) = 1
H(D1?)=?(63?log63?+63?log63?)=1
同理可得色澤烏黑(
D
2
D_2
D2?),色澤淺白(
D
3
D_3
D3?)的資訊熵為
H
(
D
2
)
=
0.918
H
(
D
3
)
=
0.722
\begin{aligned} H(D_2) = 0.918\\ H(D_3) = 0.722 \end{aligned}
H(D2?)=0.918H(D3?)=0.722?
根據資訊增益定義式有
I
(
X
,
D
)
=
H
(
X
)
?
H
(
X
∣
Y
)
=
0.998
?
(
6
17
×
1
+
6
17
×
0.918
+
5
17
×
0.722
)
=
0.109
\begin{aligned} I(X,D) = H(X)-H(X|Y) = 0.998-(\frac{6}{17}\times1+\frac{6}{17}\times0.918+\\\frac{5}{17}\times0.722) = 0.109 \end{aligned}
I(X,D)=H(X)?H(X∣Y)=0.998?(176?×1+176?×0.918+175?×0.722)=0.109?
??同理可以計算根蒂的資訊增益為0.143,敲聲為0.141,紋理為0.381,臍部為0.289,觸感為0.006,其中屬性“紋理”的資訊增益最大,故將“紋理”作為節點,下一層的計算,將在“紋理=清晰,模糊和稍糊”的三種情況下分別計算剩余屬性的條件熵,再利用資訊增益的定義式計算每個屬性的資訊增益,如此往復,直至到達迭代次數或者所有特征全部被選擇完畢,
??從上面的例子中我們可以總結出一條規律:互資訊=上一層的資訊熵-下一層的資訊熵,不過需要注意的是,除了根節點,每一層的資訊熵都要當成條件熵進行計算,而決策樹的任務就是需要找到最大資訊熵來選取中間節點或者葉節點,因此,決策樹或者由決策樹構成的隨機森林可以用來篩選特征并輸出特征重要性,
思考:若是多分類問題且類別較多,ID3決策樹模型的效果將會大幅削弱,因為此時資訊增益將趨近于0
2.5 C4.5演算法
2.5.1 簡介
??由于ID3演算法對于連續值的處理無能為力,我們需要另一種改進的演算法來實作對連續值的分類,C4.5作為ID3的改進演算法,引入資訊增益率作為其標準,結合資訊增益本身來選擇分裂子節點,
2.5.2 資訊增益率
??凡是加了個“率”字的名詞,就是在其原來的基礎上從變化量變為變化量除以原來的值,那么資訊增益率的式子也很容易得出
I
(
X
,
Y
)
R
a
t
i
o
=
I
(
X
,
Y
)
H
(
Y
)
I(X,Y)_{Ratio} = \frac{I(X,Y)}{H(Y)}
I(X,Y)Ratio?=H(Y)I(X,Y)?
根據資訊熵的定義不難看出,資訊增益率對取值數目少的特征由“偏好性”,即該特征取值數量越少,H(Y)往往會越小,反之越大,因此C4.5并不是暴力地取資訊增益率最大的一項特征作為子節點,而是首先要選出高于所有特征的平均資訊增益的幾項,再從這幾項中選出資訊增益率最大的特征,
總而言之,C4.5演算法執行程序大概可以總結為:
??1. 計算所有未被選取的特征的資訊增益;
??2. 計算這些資訊增益的平均值;
??3. 選取資訊增益大于平均值的特征;
??4. 比較第3步中選出來的特征的資訊增益率并選取最大的那一個,反回第一步,直至達到要求迭代次數或選擇完畢,
2.5 CART演算法
2.5.1 簡介
??CART演算法全稱是Classification and Regression Tree,顧名思義,這種演算法既可以做分類也可以做回歸,無論是在sklearn.tree的
DecisionTreeClassifier/DecisionTreeRegressor,還是在sklearn.ensemble中的RandomForestClassifier/RandomForestRegressor都是用CART樹作為默認引數輸入(當然也可以手動修改為ID3或C4.5),
2.5.2 Gini指數
Gini指數本來是國際上通用的、用以衡量一個國家或地區居民收入差距的常用指標,但也可以作為機器學習決策樹的目標函式,其定義式如下:
G
i
n
i
=
∑
k
=
1
K
p
k
(
1
?
p
k
)
=
1
?
∑
k
=
1
K
p
k
2
Gini = \sum\limits_{k=1}^{K}p_k(1-p_k) = 1-\sum\limits_{k=1}^{K}p_k^2
Gini=k=1∑K?pk?(1?pk?)=1?k=1∑K?pk2?
其中
p
k
p_k
pk?為某一特征的某一取值在該特征中所有取值中出現的概率,
??類比Gini指數本身的作用,我們常常希望一個國家或地區的收入差距越小越好,因此我們就選用Gini指數最小的特征作為最優劃分項,
2.5.3 CART樹的回歸問題
??CART樹在解決分類問題時選用Gini指數作為節點分裂標準,而在解決回歸問題的時候則會選擇傳統的均方誤差作為分類函式,不過回歸樹模型與一般的回歸模型有所不同,
??我們知道樹的最后會生成若干個葉節點作為結果,那么類比線性回歸就可以得到CART目標函式
a
=
arg?min
?
a
1
n
∑
i
=
1
n
(
f
(
x
i
)
?
y
)
2
a = \argmin\limits_a \frac{1}{n}\sum\limits_{i = 1}^n(f(\boldsymbol{x}_i)-y)^2
a=aargmin?n1?i=1∑n?(f(xi?)?y)2
當然這只是第一步,回歸樹面臨的還有一個重大問題:如何選取劃分點?
??有一個最簡單的方法——二分法,即選定一個閾值t,將樣本分為大于t的部分和小于t的部分,這兩個部分分別擁有自己的均方誤差值,而CART回歸樹要做的就是使得這兩個回歸樹的均方誤差之和最小,t值的選取也很容易,顯然我們可以知道t值是位于分界點處兩個樣本取值之間的一個值,常常是這兩個樣本取值正中間的值,即
t
=
a
i
+
a
i
+
1
2
t = \frac{a_i+a_{i+1}}{2}
t=2ai?+ai+1??
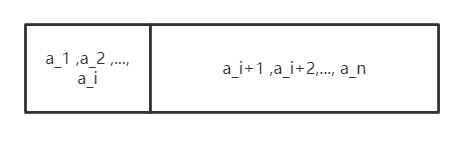
我們可以遍歷所有的樣本來選取t值,譬如最開始t是
a
i
a_i
ai?和
a
i
+
1
a_{i+1}
ai+1?之間的值,即小于t的樣本有
a
1
,
a
2
a_1,a_2
a1?,a2?…
a
i
a_i
ai?,大于t的樣本有
a
i
+
1
,
a
i
+
2
.
.
.
a
n
a_{i+1},a_{i+2}...a_n
ai+1?,ai+2?...an?,可以用一張圖來表示
對于左邊,回歸樹可以給出預測值
c
1
c_1
c1?,對于右邊,同樣有預測值
c
2
c_2
c2?,現在只要遍歷i的所有取值,求出均方誤差值之和最小的那一個,即
i
=
arg?min
?
i
[
min
?
c
1
∑
k
=
1
i
(
c
1
?
y
)
2
+
min
?
c
2
∑
k
=
i
+
1
n
(
c
2
?
y
)
2
]
i = \argmin_i[\min\limits_{c_1}\sum\limits_{k=1}^i(c_1-y)^2+\min\limits_{c_2}\sum\limits_{k=i+1}^n(c_2-y)^2]
i=iargmin?[c1?min?k=1∑i?(c1??y)2+c2?min?k=i+1∑n?(c2??y)2]
這就是第一次選取分裂節點的程序,此后只需對左右兩邊的樣本分別再次執行同樣的操作,直到達到迭代次數,
后記
這篇筆記真的憋了很久,寫的時候才發現之前學的很多細節性的東西都忘光了,如果文中有錯誤歡迎提出指正,另外復習真的很重要呀!!
參考文獻
[1]周志華.機器學習[M].清華大學出版社:北京,2016.
[2]Jeremy Liang.機器學習演算法筆記--------建立西瓜資料集[EB/OL].https://blog.csdn.net/qq_35654046/article/details/84783638
2018-12-04.
[3]wuliytTaotao.[EB/OL]. https://www.cnblogs.com/wuliytTaotao/p/10724118.html.2019-4-1在這里插入圖片描述
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/252621.html
標籤:AI